影像轉影片(Image-to-video, I2V)生成已成為 AI 影片技術中最具實用性的應用之一。您無需完全透過文字描述場景,而是從現有的影像(如產品照片、插畫、角色設計或風景圖)開始,讓 AI 模型將其轉化為動畫影片。原始影像提供了視覺基礎,而模型則在其之上生成動態、鏡頭運鏡以及時序連貫性。
對於開發者、內容創作者和製作團隊而言,I2V 提供了單靠文字轉影片(Text-to-video)所無法比擬的創意掌控力。您可以精確控制首幀畫面,而後續發生的所有內容皆由模型負責處理。本指南將比較 2026 年透過 Atlas Cloud API 可用的領先 I2V 模型:Seedance v1.5 Pro、Kling 3.0、Kling O3、Wan 2.6、Hailuo 2.3 以及 Vidu Q3。
*最後更新日期:2026 年 2 月 28 日*
查看 I2V 的實際應用效果:
I2V 模型概覽
| 模型 | 開發者 | 最大時長 | I2V 價格 (Atlas Cloud) | 風格保留度 | 動作品質 | 適用場景 |
|---|---|---|---|---|---|---|
| Seedance v1.5 Pro | ByteDance | 15秒 | USD0.047/秒 | 極佳 | 極佳 | 多參考圖、創意控制 |
| Kling 3.0 Std | 快手 | 15秒 | USD0.071/秒 | 極佳 | 極佳 | 高一致性、高性價比 |
| Kling 3.0 Pro | 快手 | 15秒 | USD0.095/秒 | 極佳 | 極佳 | 高一致性、1080p 輸出 |
| Kling O3 Std | 快手 | 15秒 | USD0.071/秒 | 極佳 | 極佳 | 推理驅動、標準品質 |
| Kling O3 Pro | 快手 | 15秒 | USD0.095/秒 | 極佳 | 極佳 | 進階品質、推理驅動 |
| Wan 2.6 Flash | 阿里巴巴 | 10秒 | USD0.018/秒 | 良好 | 良好 | 低預算製作 |
| Hailuo 2.3 | MiniMax | 10秒 | USD0.28/秒 | 良好 | 非常好 | 品質與價格平衡 |
| Vidu Q3 Pro | 生數 | 8秒 | USD0.06/秒 | 良好 | 良好 | 原生音訊 + I2V |
| Vidu Q3 Turbo | 生數 | 8秒 | USD0.034/秒 | 良好 | 良好 | 帶音訊的經濟型 I2V |
什麼是影像轉影片 (I2V) 生成?
I2V 生成是指以一張靜態影像為起點,生成一段影片片段。模型會分析原始影像的內容——包括物件、角色、光影、構圖與風格——並生成後續影格,使場景以視覺上連貫的方式動起來。
I2V 與文字轉影片 (T2V) 的關鍵區別:
- T2V:模型根據文字提示詞從零開始生成視覺內容與動作,您無法直接控制初始的視覺外觀。
- I2V:您提供視覺起點。模型會從您的影像中繼承顏色、構圖、風格與主體外觀,隨後您可以使用文字提示詞來引導動作、鏡頭運鏡與行為。
這種區別非常重要,因為 I2V 提供了對輸出視覺身份的決定性控制。如果您有特定的產品照片、角色插畫或品牌素材,I2V 可以確保影片與您的原始素材精確匹配。
為什麼 I2V 對製作至關重要
- 品牌一致性:產品照片、品牌資產與設計元素在生成的影片中能維持精確的外觀。
- 角色動畫:插畫師與動畫師可以將靜態角色藝術轉為動態,無需逐格重繪。
- 產品行銷:電商團隊可以將產品攝影轉化為動態影片廣告,無需進行實地拍攝。
- 分鏡腳本:將概念藝術或分鏡圖轉為動畫預覽,用於前期製作審核。
- 社群媒體內容:將任何靜態影像轉為引人入勝的影片內容,迎合演算法對影片的優先推薦。
模型深度解析
Seedance v1.5 Pro:多參考圖專家
來自 ByteDance 的 Seedance v1.5 Pro 是需要複雜創意控制的專案首選。大多數 I2V 模型僅接受單一參考圖,而 Seedance v1.5 Pro 最多可接受 9 張參考圖、3 段影片及 3 個音訊檔作為參考素材,這種多模態輸入能力在目前的領域中無人能及。
I2V 優勢:
- 支援多達 9 張參考圖,提供全面的風格與內容指引
- 最大長度 15 秒——目前市面上最長
- 卓越的源影像風格保留能力
- 動作品質強悍,運動自然
- 價格親民,僅 USD0.047/秒
I2V 限制:
- 內容審核嚴格
- 複雜的多參考圖設定需要更高階的提示詞工程能力
適用場景:包含多個參考點的複雜場景、角色一致性要求高的動畫、長篇 I2V 片段、預算敏感型製作。
Kling 3.0:高一致性與解析度
Kling 3.0 提供強大的 I2V 輸出,Pro 版本更支援 1080p 輸出。其角色一致性技術在 I2V 應用中表現優異——當您提供角色源影像時,模型能在生成的影片中高保真地維持面部特徵、服裝細節與比例。
I2V 優勢:
- 支援 1080p 輸出,確保視覺清晰度
- 源影像的角色一致性極佳
- 15 秒長度,支援 30fps
- 文字保留力強——品牌名稱與產品標籤保持清晰可讀
I2V 限制:
- Std 版本為 USD0.071/秒,Pro 版本為 USD0.095/秒
- 內容篩選極為嚴格
- 限制為 1-2 張參考圖
適用場景:高解析度產品影片、需要極高一致性的角色動畫、包含文字的電商內容。
Kling O3:推理驅動的 I2V
Kling O3 是快手的旗艦推理模型,將更深入的場景理解引入 I2V 生成。它能更全面地分析源影像,在生成動作前理解空間關係、物理特性與物體互動。
I2V 優勢:
- 優越的場景理解與物理感知能力
- 根據影像內容做出智慧化的動作決策
- 與源素材高度一致
- 支援 15 秒長度
I2V 限制:
- 定價較高——Std 為 USD0.071/秒,Pro 為 USD0.095/秒
- 因推理步驟增加,生成時間稍長
適用場景:動作邏輯至關重要的複雜場景、具備真實物理效果的產品展示、高預算製作。
Wan 2.6 Flash:經濟實惠的 I2V 工作機
阿里巴巴的 Wan 2.6 Flash 是大規模 I2V 製作的經濟型選擇。其定價為 USD0.018/秒,是清單中最實惠的模型。品質表現良好,雖非頂尖,但足以勝任社群媒體、網頁內容及內部製作需求。
I2V 優勢:
- 最低價格 USD0.018/秒
- 以價格點而言品質良好
- 10 秒長度
- 輸出穩定可靠
I2V 限制:
- 風格保留度良好但不如 Seedance 或 Kling 精確
- 動作品質落後於旗艦模型
- 解析度上限較低
適用場景:預算有限的大規模 I2V 製作、社群媒體內容、原型開發與測試、內部行銷資產。
Hailuo 2.3:品質與價格的平衡點
來自 MiniMax 的 Hailuo 2.3 提供極為流暢的動作品質,且源影像的風格保留度可靠。定價為 USD0.28/秒,定位於高階選項。
I2V 優勢:
- 動作品質非常好,運動流暢自然
- 風格保留穩定
- 10 秒長度
- 攝影棚等級的輸出品質
I2V 限制:
- 一致性水準尚未達到 Seedance 或 Kling 的高度
- 進階功能相較旗艦模型較少
適用場景:一般用途 I2V 製作、行銷內容、社群媒體影片、追求品質但希望控制成本的團隊。
Vidu Q3:結合原生音訊的 I2V
Vidu Q3 是清單中唯一將 I2V 能力與原生音訊生成相結合的模型。上傳源影像,即可獲得一段包含情境適切音訊(環境音、背景雜訊或基礎語音)的影片片段。提供 Pro (USD0.06/秒) 與 Turbo (USD0.034/秒) 版本。
I2V 優勢:
- 生成 I2V 輸出的同時生成原生音訊
- 風格保留度良好
- 輸出乾淨且一致
- Turbo 版本提供極具競爭力的價格
I2V 限制:
- 最大長度 8 秒——清單中最短
- 音訊品質增加了附加價值,但視覺品質稍遜於頂級模型
- 音訊主要以英語為主
適用場景:單次 API 呼叫即需同時生成動畫與音訊的內容、Vlog 風格內容、快速促銷短片。
I2V 程式碼範例
所有模型均使用相同的 Atlas Cloud API,並透過 image_url 參數指定源影像。以下是熱門 I2V 模型的運作範例。
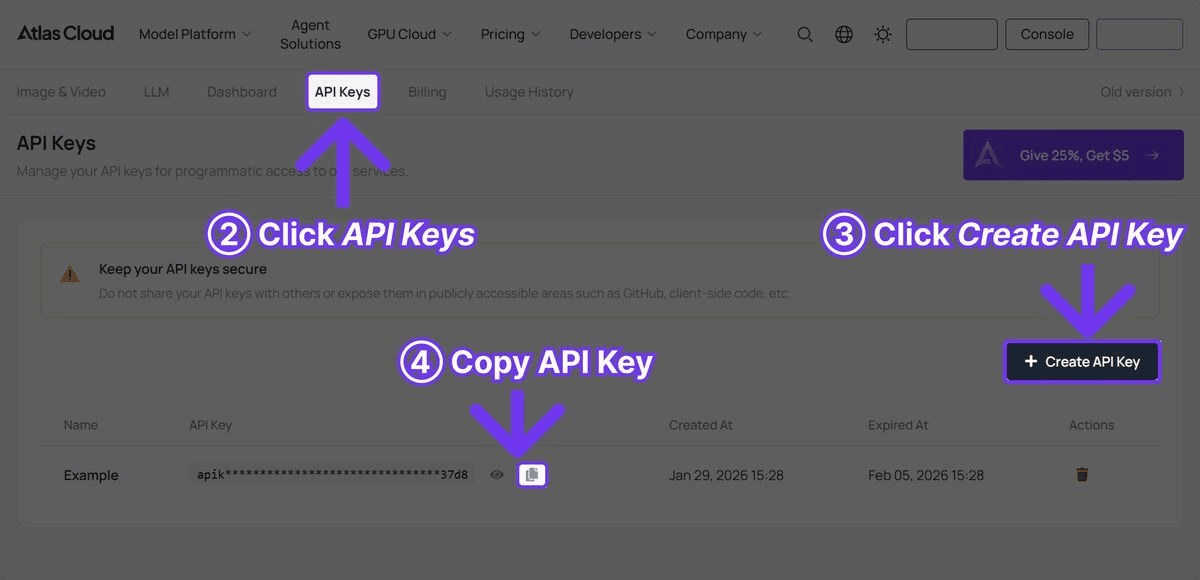
第一步:取得 API 金鑰
在 Atlas Cloud 註冊並從控制台取得您的 API 金鑰。
Seedance v1.5 Pro I2V
plaintext1```python 2import requests 3import time 4 5API_KEY = "your-atlas-cloud-api-key" 6BASE_URL = "https://api.atlascloud.ai/api/v1" 7 8response = requests.post( 9 f"{BASE_URL}/model/generateVideo", 10 headers={ 11 "Authorization": f"Bearer {API_KEY}", 12 "Content-Type": "application/json" 13 }, 14 json={ 15 "model": "bytedance/seedance-v1.5-pro/image-to-video", 16 "prompt": "The character begins walking forward confidently, " 17 "hair moving naturally in a gentle breeze, " 18 "cinematic camera slowly tracking alongside", 19 "image_url": "https://example.com/your-source-image.jpg", 20 "duration": 10, 21 "resolution": "1080p" 22 } 23) 24 25result = response.json() 26 27while True: 28 status = requests.get( 29 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 30 headers={"Authorization": f"Bearer {API_KEY}"} 31 ).json() 32 if status["status"] == "completed": 33 print(f"Video: {status['output']['video_url']}") 34 break 35 time.sleep(5) 36```
Kling 3.0 I2V
plaintext1```python 2response = requests.post( 3 f"{BASE_URL}/model/generateVideo", 4 headers={ 5 "Authorization": f"Bearer {API_KEY}", 6 "Content-Type": "application/json" 7 }, 8 json={ 9 "model": "kwaivgi/kling-v3.0-pro/image-to-video", 10 "prompt": "The product slowly rotates on the display surface, " 11 "studio lighting creates dynamic reflections, " 12 "premium commercial style", 13 "image_url": "https://example.com/product-photo.jpg", 14 "duration": 10, 15 "resolution": "1080p" 16 } 17) 18 19result = response.json() 20```
Wan 2.6 Flash I2V (經濟選項)
plaintext1```python 2response = requests.post( 3 f"{BASE_URL}/model/generateVideo", 4 headers={ 5 "Authorization": f"Bearer {API_KEY}", 6 "Content-Type": "application/json" 7 }, 8 json={ 9 "model": "alibaba/wan-2.6/image-to-video", 10 "prompt": "Gentle motion with natural swaying, soft ambient " 11 "lighting, peaceful and calm atmosphere", 12 "image_url": "https://example.com/source-image.jpg", 13 "duration": 10, 14 "resolution": "1080p" 15 } 16) 17 18result = response.json() 19```
源影像的最佳實踐
I2V 輸出的品質很大程度上取決於源影像的品質與特性。以下是在各模型中產生最佳結果的實踐建議:
影像品質
- 使用高解析度源影像: 建議 1024x1024 或更高。低解析度輸入會導致模糊或充滿偽影的輸出。
- 避免過度壓縮的影像: 源影像中的 JPEG 偽影會在影片輸出中被放大。請使用 PNG 或高品質 JPEG。
- 確保對焦清晰: 模糊的源影像會產生模糊的影片。模型會保留輸入的對焦特性。
構圖
- 置中主體: 模型處理置中構圖比邊緣偏移的構圖更為可靠。
- 留出動作空間: 如果您希望角色走動,請確保影格中有足夠的移動空間。過度裁切的影像會限制模型生成令人信服的動作。
- 考量長寬比: 源影像的長寬比應與預期的輸出匹配。16:9 用於橫向、9:16 用於垂直/手機、1:1 用於正方形。
風格一致性
- 光線一致: 光線清晰且一致的源影像能轉化為更好的影片輸出。混合或混亂的光源條件可能導致結果不一致。
- 簡單背景效果最佳: 純色、攝影棚環境或模糊的背景,比雜亂複雜的背景產生更穩定的結果。
- 保持風格一致: 若源影像具有特定藝術風格(水彩、插畫、寫實),提示詞應強化該風格而非與之矛盾。
針對產品攝影
- 使用棚拍等級的產品照: 背景乾淨、專業打光且焦點精確的產品照。
- 包含完整產品: 被裁切或僅部分可見的產品會導致動畫不一致。
- 移除干擾元素: 畫面中的道具、手或其他物件可能會產生無法預測的動畫效果。
針對角色動畫
- 使用正面或四分之三角度: 這些角度比極端角度更自然地轉化為動畫。
- 確保面部特徵清晰: 若角色需要面部運動,眼睛、嘴巴與表情的清晰可見度將顯著提升效果。
- 保持角色設計一致: 若跨影片使用多張影像,請確保角色設計保持視覺連續性。
I2V 使用案例
動畫化插畫
藝術家與插畫師無需逐幀動畫即可將靜態作品變得栩栩如生。上傳角色插畫,Seedance v1.5 Pro 等模型即可生成流暢且保留風格的動畫。此工作流尤其適合:
- 兒童繪本插畫變身動畫故事
- 漫畫分鏡變身短篇動畫片段
- 概念藝術變身用於客戶簡報的動畫預覽
產品攝影轉影片
電商團隊可將既有的產品攝影庫轉為影片內容。無需為每個產品安排影片拍攝,現有的產品照即可作為動態影片廣告的素材。Kling 3.0 的動作控制使其表現特別出色——您可以指定圍繞產品緩慢轉動、推軌鏡頭強調細節,或橫跨產品系列進行平移。
角色動畫
遊戲工作室、動畫製作公司與內容創作者可使用 I2V 將角色設計動畫化。上傳角色設定集或姿勢插畫,模型即可生成維持角色視覺身份的動畫。Seedance v1.5 Pro 的多參考圖能力在此展現價值——提供同一角色的多個視角,模型即可在生成的片段中保持高度一致。
分鏡腳本動畫
製作團隊可將分鏡腳本影格轉為 rough 版本的動畫用於審核。這能比單純的靜態分鏡提供導演與利害關係人更好的節奏感、動作動態與視覺流程體驗。
大規模價格比較
對於大量生產 I2V 內容的團隊而言,定價差異會迅速累積:
| 產量 (每月) | Wan 2.6 Flash | Vidu Q3 Turbo | Seedance v1.5 Pro | Kling 3.0 Std | Hailuo 2.3 |
|---|---|---|---|---|---|
| 50 支 (8秒) | USD7.20 | USD13.60 | USD18.80 | USD28.40 | USD112.00 |
| 200 支 (8秒) | USD28.80 | USD54.40 | USD75.20 | USD113.60 | USD448.00 |
| 500 支 (8秒) | USD72.00 | USD136.00 | USD188.00 | USD284.00 | USD1,120.00 |
| 1,000 支 (8秒) | USD144.00 | USD272.00 | USD376.00 | USD568.00 | USD2,240.00 |
每月 1,000 支影片時,Wan 2.6 Flash (USD144) 與 Hailuo 2.3 (USD2,240) 的價差高達 15 倍以上。品質差異確實存在,但預算影響同樣顯著。許多製作團隊採取分層策略——使用 Wan 2.6 進行草稿疊代與內部內容製作,使用 Seedance v1.5 Pro 或 Kling 3.0 製作最終客戶交付成果。
常見問題 (FAQ)
哪款 I2V 模型的風格保留度最好?
Seedance v1.5 Pro 與 Kling 3.0 在風格保留方面處於領先地位。兩者皆能高保真地維持源影像的顏色、紋理與視覺身份。在複雜的多參考圖場景中,Seedance v1.5 Pro 因其能攝入多達 9 張參考圖,略佔優勢。
我可以使用任何影像格式作為輸入嗎?
JPEG 與 PNG 為普遍支援格式,WebP 適用於大多數模型。為獲得最佳效果,建議使用 1024x1024 或更高解析度的高品質 PNG 或 JPEG。影像必須透過公開連結存取以供 API 呼叫。
如果我的源影像中有文字怎麼辦?
Kling 3.0 是保存源影像中可讀文字效果最好的模型——品牌名稱、標籤與路標通常能保持清晰。其他模型在動畫過程中可能會導致文字變形或模糊。若文字保留至關重要,建議選擇 Kling 3.0。
我可以將 I2V 與原生音訊結合嗎?
可以。Vidu Q3 是唯一在生成 I2V 輸出的同時生成原生音訊的模型。針對其他模型,您需要先生成 I2V 影片後再額外添加音訊,或為最終版本選擇具備原生音訊能力的影片生成模型。
在 Seedance v1.5 Pro 與 Kling 3.0 之間該如何選擇?
如果您需要更低的成本 (USD0.047/秒 vs USD0.071-0.095/秒) 或多參考圖輸入,請選擇 Seedance v1.5 Pro。如果您需要高品質的 1080p 輸出或文字保留,請選擇 Kling 3.0。兩者皆支援長達 15 秒的影片。
總結
2026 年的 I2V 市場在各個價格區間都有強大的選項。Seedance v1.5 Pro 是綜合價值的領跑者——結合了最長時長、多參考圖輸入、卓越品質與極具競爭力的單價。Kling 3.0 是追求最高解析度與文字保留的優質選擇。Wan 2.6 Flash 則是適合追求產量而非精緻度的團隊的預算方案。Vidu Q3 為 I2V 增添了原生音訊,這是其他模型所不具備的獨特能力。
最有效的方法是透過單一 Atlas Cloud API 金鑰使用多種模型:使用 Wan 2.6 Flash 進行草稿製作,使用 Seedance v1.5 Pro 進行疊代,並使用 Kling 3.0 進行精緻化——一切皆可在同一個帳戶、同一個餘額與同一個整合中完成。能根據專案要求與預算匹配合適模型的靈活性,遠比綁定單一工具更有價值。
────────────────────────────────────────────────────────────






