
大多數團隊開始進行 AI 影片生成時,都是透過一次性的 API 呼叫來進行——產生單支影片、下載,然後繼續下一個。這種方式適合用來進行實驗。
*最後更新日期:2026 年 2 月 28 日*
查看這些模型的實際運作效果:
管線架構 (Pipeline Architecture)
在編寫程式碼之前,我們先看看我們即將建構的架構概覽:
plaintext1``` 2+-------------------+ +--------------------+ +------------------+ 3| 提示詞配置 (Prompt) | | Atlas Cloud API | | 輸出儲存空間 | 4| (JSON/YAML) | | | | | 5| - prompts +---->+ /generateImage +---->+ /images/ | 6| - models | | /generateVideo | | /videos/ | 7| - parameters | | /prediction/get | | /manifest.json | 8+-------------------+ +--------------------+ +------------------+ 9 | | | 10 v v v 11+-------------------+ +--------------------+ +------------------+ 12| 管線引擎 (Pipeline) | | 輪詢與重試 (Polling) | | 成本追蹤 | 13| | | | | | 14| - batch_generate | | - 指數退避策略 | | - 單次請求 | 15| - concurrency | | (Backoff) | | - 累計成本 | 16| - model routing | | - 最大重試次數 | | - 模型別成本 | 17+-------------------+ +--------------------+ +------------------+ 18```
這個管線遵循一個簡單的流程:
- 從結構化輸入檔案讀取提示詞配置。
- 將每個提示詞路由至適當的模型與端點(圖片或影片)。
- 在受控併發數下,將所有請求提交至 Atlas Cloud API。
- 使用指數退避(Exponential Backoff)與重試邏輯輪詢結果。
- 下載已完成的輸出並存入結構化的目錄。
- 追蹤成本並產生摘要清單(Manifest)。
入門指南:API 存取
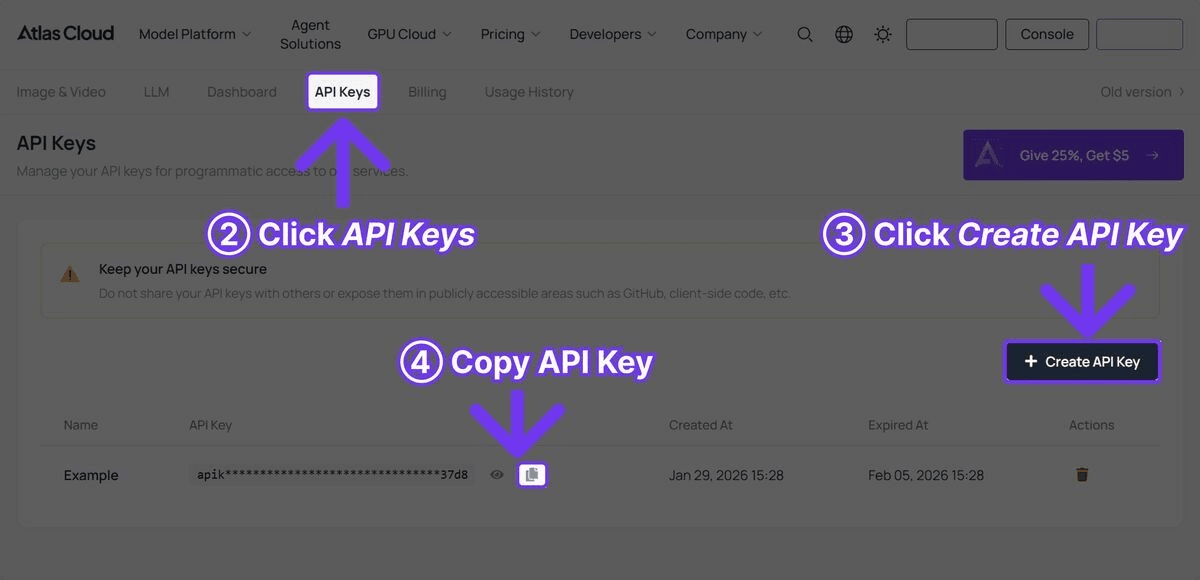
步驟 1:取得您的 API 金鑰
在 Atlas Cloud 註冊並從儀表板建立 API 金鑰。
步驟 2:安裝相依套件
plaintext1```bash 2pip install requests pyyaml 3```
無需複雜的框架。此管線僅使用 requests 進行 HTTP 呼叫、pyyaml 用於配置檔,以及 Python 標準函式庫處理併發與檔案作業。
完整管線程式碼
以下是完整的運作管線。每個部分都會在程式碼區塊後進行說明。
plaintext1```python 2import requests 3import time 4import json 5import os 6import logging 7from concurrent.futures import ThreadPoolExecutor, as_completed 8from dataclasses import dataclass, field 9from typing import Optional 10from datetime import datetime 11 12# 設定日誌 13logging.basicConfig( 14 level=logging.INFO, 15 format="%(asctime)s [%(levelname)s] %(message)s", 16 datefmt="%Y-%m-%d %H:%M:%S" 17) 18logger = logging.getLogger("atlas_pipeline") 19 20@dataclass 21class GenerationResult: 22 """儲存單次生成請求的結果。""" 23 name: str 24 model: str 25 media_type: str # "image" 或 "video" 26 status: str # "success", "failed", "error" 27 output_url: Optional[str] = None 28 local_path: Optional[str] = None 29 cost_estimate: float = 0.0 30 duration_seconds: float = 0.0 31 error_message: Optional[str] = None 32 33class AtlasCloudClient: 34 """Atlas Cloud API 的用戶端封裝。""" 35 36 BASE_URL = "https://api.atlascloud.ai/api/v1" 37 38 # 模型定價(估計值) 39 PRICING = { 40 "black-forest-labs/flux-2-pro/text-to-image": 0.04, # 每張圖片 41 "google/imagen4-ultra/text-to-image": 0.06, # 每張圖片 42 "bytedance/seedance-v1.5-pro/text-to-video": 0.022, # 每秒 43 "google/veo3.1/text-to-video": 0.03, # 每秒 44 "openai/sora-v2/text-to-video": 0.15, # 每秒 45 } 46 47 def __init__(self, api_key: str): 48 self.api_key = api_key 49 self.session = requests.Session() 50 self.session.headers.update({ 51 "Authorization": f"Bearer {api_key}", 52 "Content-Type": "application/json" 53 }) 54 55 def generate_image( 56 self, 57 model: str, 58 prompt: str, 59 width: int = 1024, 60 height: int = 1024 61 ) -> dict: 62 """提交圖片生成請求。""" 63 response = self.session.post( 64 f"{self.BASE_URL}/model/generateImage", 65 json={ 66 "model": model, 67 "prompt": prompt, 68 "width": width, 69 "height": height 70 } 71 ) 72 response.raise_for_status() 73 return response.json() 74 75 def generate_video( 76 self, 77 model: str, 78 prompt: str, 79 duration: int = 5, 80 resolution: str = "1080p" 81 ) -> dict: 82 """提交影片生成請求。""" 83 response = self.session.post( 84 f"{self.BASE_URL}/model/generateVideo", 85 json={ 86 "model": model, 87 "prompt": prompt, 88 "duration": duration, 89 "resolution": resolution 90 } 91 ) 92 response.raise_for_status() 93 return response.json() 94 95 def poll_result( 96 self, 97 request_id: str, 98 max_wait: int = 300, 99 initial_interval: int = 5, 100 max_interval: int = 30 101 ) -> Optional[dict]: 102 """以指數退避策略輪詢生成結果。""" 103 start_time = time.time() 104 interval = initial_interval 105 106 while time.time() - start_time < max_wait: 107 try: 108 response = self.session.get( 109 f"{self.BASE_URL}/model/prediction/{request_id}/get" 110 ) 111 data = response.json() 112 113 if data["status"] == "completed": 114 return data 115 elif data["status"] == "failed": 116 logger.error(f"生成失敗: {data.get('error', '未知錯誤')}") 117 return None 118 119 logger.debug(f"狀態: {data['status']}, 等待 {interval}秒...") 120 time.sleep(interval) 121 interval = min(interval * 1.5, max_interval) 122 123 except requests.RequestException as e: 124 logger.warning(f"輪詢請求失敗: {e}, 將於 {interval}秒後重試") 125 time.sleep(interval) 126 127 logger.error(f"超過 {max_wait}秒 超時,等待 {request_id} 失敗") 128 return None 129 130 def estimate_cost(self, model: str, duration: int = 0) -> float: 131 """估算生成請求的成本。""" 132 base_price = self.PRICING.get(model, 0.05) 133 if "text-to-video" in model and duration > 0: 134 return base_price * duration 135 return base_price 136 137class VideoPipeline: 138 """管理圖片與影片的批次生成排程。""" 139 140 def __init__(self, api_key: str, output_dir: str = "pipeline_output"): 141 self.client = AtlasCloudClient(api_key) 142 self.output_dir = output_dir 143 self.results: list[GenerationResult] = [] 144 self.total_cost = 0.0 145 146 # 建立輸出目錄 147 os.makedirs(os.path.join(output_dir, "images"), exist_ok=True) 148 os.makedirs(os.path.join(output_dir, "videos"), exist_ok=True) 149 150 def _download_file(self, url: str, filepath: str) -> bool: 151 """從 URL 下載檔案到本地路徑。""" 152 try: 153 response = requests.get(url, timeout=60) 154 response.raise_for_status() 155 with open(filepath, "wb") as f: 156 f.write(response.content) 157 return True 158 except Exception as e: 159 logger.error(f"下載失敗 {url}: {e}") 160 return False 161 162 def _safe_filename(self, name: str, extension: str) -> str: 163 """轉換為安全的檔案名稱。""" 164 safe = name.lower().replace(" ", "_") 165 safe = "".join(c for c in safe if c.isalnum() or c == "_") 166 return f"{safe}.{extension}" 167 168 def _process_image(self, name: str, model: str, prompt: str, 169 width: int = 1024, height: int = 1024, 170 retries: int = 2) -> GenerationResult: 171 """帶重試邏輯的單張圖片生成。""" 172 start = time.time() 173 cost = self.client.estimate_cost(model) 174 175 for attempt in range(retries + 1): 176 try: 177 logger.info(f"[圖片] 產生中 '{name}' (嘗試 {attempt + 1})") 178 result = self.client.generate_image(model, prompt, width, height) 179 request_id = result["request_id"] 180 181 data = self.client.poll_result(request_id) 182 if data and data["status"] == "completed": 183 image_url = data["output"]["image_url"] 184 filename = self._safe_filename(name, "png") 185 filepath = os.path.join(self.output_dir, "images", filename) 186 self._download_file(image_url, filepath) 187 188 return GenerationResult( 189 name=name, model=model, media_type="image", 190 status="success", output_url=image_url, 191 local_path=filepath, cost_estimate=cost, 192 duration_seconds=time.time() - start 193 ) 194 except requests.HTTPError as e: 195 if e.response.status_code == 429: 196 wait = 2 ** (attempt + 2) 197 logger.warning(f"觸發速率限制,等待 {wait}秒") 198 time.sleep(wait) 199 continue 200 logger.error(f"HTTP 錯誤生成 '{name}': {e}") 201 except Exception as e: 202 logger.error(f"生成錯誤 '{name}': {e}") 203 204 if attempt < retries: 205 time.sleep(2 ** attempt) 206 207 return GenerationResult( 208 name=name, model=model, media_type="image", 209 status="failed", cost_estimate=0, 210 duration_seconds=time.time() - start, 211 error_message="超過最大重試次數" 212 ) 213 214 def _process_video(self, name: str, model: str, prompt: str, 215 duration: int = 5, resolution: str = "1080p", 216 retries: int = 2) -> GenerationResult: 217 """帶重試邏輯的單支影片生成。""" 218 start = time.time() 219 cost = self.client.estimate_cost(model, duration) 220 221 for attempt in range(retries + 1): 222 try: 223 logger.info(f"[影片] 產生中 '{name}' (嘗試 {attempt + 1})") 224 result = self.client.generate_video(model, prompt, duration, resolution) 225 request_id = result["request_id"] 226 227 data = self.client.poll_result(request_id, max_wait=600) 228 if data and data["status"] == "completed": 229 video_url = data["output"]["video_url"] 230 filename = self._safe_filename(name, "mp4") 231 filepath = os.path.join(self.output_dir, "videos", filename) 232 self._download_file(video_url, filepath) 233 234 return GenerationResult( 235 name=name, model=model, media_type="video", 236 status="success", output_url=video_url, 237 local_path=filepath, cost_estimate=cost, 238 duration_seconds=time.time() - start 239 ) 240 except requests.HTTPError as e: 241 if e.response.status_code == 429: 242 wait = 2 ** (attempt + 2) 243 logger.warning(f"觸發速率限制,等待 {wait}秒") 244 time.sleep(wait) 245 continue 246 logger.error(f"HTTP 錯誤生成 '{name}': {e}") 247 except Exception as e: 248 logger.error(f"生成錯誤 '{name}': {e}") 249 250 if attempt < retries: 251 time.sleep(2 ** (attempt + 1)) 252 253 return GenerationResult( 254 name=name, model=model, media_type="video", 255 status="failed", cost_estimate=0, 256 duration_seconds=time.time() - start, 257 error_message="超過最大重試次數" 258 ) 259 260 def batch_generate(self, jobs: list[dict], max_workers: int = 3): 261 """併發處理批次生成工作。""" 262 logger.info(f"開始批次處理 {len(jobs)} 個工作,使用 {max_workers} 個執行緒") 263 start_time = time.time() 264 265 with ThreadPoolExecutor(max_workers=max_workers) as executor: 266 futures = {} 267 for job in jobs: 268 if job["type"] == "image": 269 future = executor.submit( 270 self._process_image, 271 name=job["name"], 272 model=job["model"], 273 prompt=job["prompt"], 274 width=job.get("width", 1024), 275 height=job.get("height", 1024) 276 ) 277 elif job["type"] == "video": 278 future = executor.submit( 279 self._process_video, 280 name=job["name"], 281 model=job["model"], 282 prompt=job["prompt"], 283 duration=job.get("duration", 5), 284 resolution=job.get("resolution", "1080p") 285 ) 286 else: 287 logger.warning(f"未知工作類型: {job['type']}") 288 continue 289 futures[future] = job["name"] 290 291 for future in as_completed(futures): 292 result = future.result() 293 self.results.append(result) 294 self.total_cost += result.cost_estimate 295 status_icon = "OK" if result.status == "success" else "FAIL" 296 logger.info( 297 f"[{status_icon}] {result.name} -- " 298 f"USD{result.cost_estimate:.3f} -- " 299 f"{result.duration_seconds:.1f}s" 300 ) 301 302 elapsed = time.time() - start_time 303 self._save_manifest() 304 self._print_summary(elapsed) 305 306 def _save_manifest(self): 307 """將結果清單儲存為 JSON。""" 308 manifest = { 309 "generated_at": datetime.now().isoformat(), 310 "total_cost": round(self.total_cost, 4), 311 "total_jobs": len(self.results), 312 "successful": sum(1 for r in self.results if r.status == "success"), 313 "failed": sum(1 for r in self.results if r.status != "success"), 314 "results": [ 315 { 316 "name": r.name, 317 "model": r.model, 318 "type": r.media_type, 319 "status": r.status, 320 "output_url": r.output_url, 321 "local_path": r.local_path, 322 "cost": round(r.cost_estimate, 4), 323 "generation_time": round(r.duration_seconds, 1), 324 "error": r.error_message 325 } 326 for r in self.results 327 ] 328 } 329 manifest_path = os.path.join(self.output_dir, "manifest.json") 330 with open(manifest_path, "w") as f: 331 json.dump(manifest, f, indent=2) 332 logger.info(f"清單已儲存至 {manifest_path}") 333 334 def _print_summary(self, elapsed: float): 335 """印出批次執行摘要。""" 336 success = sum(1 for r in self.results if r.status == "success") 337 failed = len(self.results) - success 338 cost_by_model = {} 339 for r in self.results: 340 cost_by_model[r.model] = cost_by_model.get(r.model, 0) + r.cost_estimate 341 342 print("\n" + "=" * 60) 343 print("管線摘要 (PIPELINE SUMMARY)") 344 print("=" * 60) 345 print(f"總工作數: {len(self.results)}") 346 print(f"成功數: {success}") 347 print(f"失敗數: {failed}") 348 print(f"總成本: USD{self.total_cost:.4f}") 349 print(f"總耗時: {elapsed:.1f}s") 350 print(f"\n模型成本分析:") 351 for model, cost in sorted(cost_by_model.items()): 352 short_name = model.split("/")[1] 353 print(f" {short_name}: USD{cost:.4f}") 354 print("=" * 60) 355```
使用管線
定義完 AtlasCloudClient 與 VideoPipeline 類別後,以下是如何在標準內容生產工作流程中使用它們的方法。
基本用法:縮圖 + 影片
plaintext1```python 2API_KEY = "您的-atlas-cloud-api-key" 3 4pipeline = VideoPipeline(api_key=API_KEY, output_dir="weekly_content") 5 6jobs = [ 7 # 使用 Flux 2 Pro 生成縮圖 8 { 9 "name": "產品發布縮圖", 10 "type": "image", 11 "model": "black-forest-labs/flux-2-pro/text-to-image", 12 "prompt": "引人注目的 YouTube 縮圖,粗體字 'NEW LAUNCH'," 13 "深色漸層背景下的產品焦點,鮮豔的強調色," 14 "專業設計,4K" 15 }, 16 { 17 "name": "教學縮圖", 18 "type": "image", 19 "model": "black-forest-labs/flux-2-pro/text-to-image", 20 "prompt": "用於程式教學的 YouTube 縮圖,分割畫面" 21 "展示程式碼編輯器與最終成果,科技美學," 22 "簡潔現代設計,粗體易讀文字" 23 }, 24 25 # 使用 Seedance 2.0 生成影片(具經濟效益) 26 { 27 "name": "產品展示 Seedance", 28 "type": "video", 29 "model": "bytedance/seedance-v1.5-pro/text-to-video", 30 "prompt": "流暢的產品展示動畫,現代裝置在柔光中浮現," 31 "緩慢旋轉以顯示所有角度,極簡白色背景," 32 "電影級燈光", 33 "duration": 10 34 }, 35 { 36 "name": "品牌開場 Seedance", 37 "type": "video", 38 "model": "bytedance/seedance-v1.5-pro/text-to-video", 39 "prompt": "動態品牌開場序列,抽象幾何形狀組合成標誌," 40 "粒子與光線軌跡,專業動態圖形風格,深色背景", 41 "duration": 5 42 }, 43 44 # 使用 Veo 3.1 生成電影級影片(含音訊) 45 { 46 "name": "英雄影片 Veo", 47 "type": "video", 48 "model": "google/veo3.1/text-to-video", 49 "prompt": "黃金時刻現代城市天際線的電影級空拍鏡頭," 50 "鏡頭緩慢前推,夕陽耀斑,城市環境音,膠卷顆粒感," 51 "專業調色", 52 "duration": 8 53 }, 54] 55 56pipeline.batch_generate(jobs, max_workers=3) 57```
以配置檔為導向的方法
針對定期管線,請將工作定義在 YAML 配置檔中:
plaintext1```yaml 2# pipeline_config.yaml 3output_dir: weekly_content 4max_workers: 3 5 6jobs: 7 - name: 產品主視覺圖 8 type: image 9 model: google/imagen4-ultra/text-to-image 10 prompt: > 11 高級無線耳機充電盒的產品攝影, 12 深色反射表面,戲劇性燈光,奢華科技美學, 13 8K 解析度,商業廣告品質 14 width: 2048 15 height: 2048 16 17 - name: 社群媒體影片 18 type: video 19 model: bytedance/seedance-v1.5-pro/text-to-video 20 prompt: > 21 潮流社群內容,雙手開箱高級科技產品, 22 令人滿足的開箱瞬間,細節特寫,明亮自然光, 23 垂直格式 24 duration: 10 25 resolution: 1080p 26 27 - name: 電影級廣告 28 type: video 29 model: google/veo3.1/text-to-video 30 prompt: > 31 高級耳機的電影級商業廣告,一人在繁忙的咖啡店戴上耳機, 32 世界靜了下來,淺景深,暖色調,咖啡廳背景音淡入寂靜 33 duration: 8 34 resolution: 1080p 35```
載入並執行:
plaintext1```python 2import yaml 3 4with open("pipeline_config.yaml") as f: 5 config = yaml.safe_load(f) 6 7pipeline = VideoPipeline( 8 api_key=API_KEY, 9 output_dir=config["output_dir"] 10) 11pipeline.batch_generate( 12 config["jobs"], 13 max_workers=config.get("max_workers", 3) 14) 15```
關鍵實作細節
指數退避輪詢 (Exponential Backoff)
影片生成時間取決於模型與長度,約需 30 秒到 5 分鐘不等。管線使用指數退避策略來高效輪詢,而不會過度打擾 API:
plaintext1```python 2interval = initial_interval # 從 5 秒開始 3while time.time() - start_time < max_wait: 4 # ... 檢查狀態 ... 5 time.sleep(interval) 6 interval = min(interval * 1.5, max_interval) # 增加到最大 30 秒 7```
這意味著前幾次輪詢以 5 秒間隔進行,隨後逐漸拉長至 30 秒間隔以應對較長的生成。與固定間隔輪詢相比,此舉約可減少 60% 不必要的 API 呼叫。
速率限制處理 (Rate Limit)
當 API 回傳 429 (速率限制) 狀態時,管線會自動進行指數退避,而非立即失敗:
plaintext1```python 2except requests.HTTPError as e: 3 if e.response.status_code == 429: 4 wait = 2 ** (attempt + 2) # 4秒, 8秒, 16秒 5 logger.warning(f"觸發速率限制,等待 {wait}秒") 6 time.sleep(wait) 7 continue 8```
這對於批次作業至關重要,因為多個併發請求可能會暫時超過速率限制。
併發控制
ThreadPoolExecutor 限制了併發的 API 請求數量,防止拖垮 API 或您的網路連線:
plaintext1```python 2with ThreadPoolExecutor(max_workers=3) as executor: 3 futures = {executor.submit(process, job): job for job in jobs} 4```
建議從 max_workers=3 開始,若您的 Atlas Cloud 帳戶支援更高併發,則可增加至 5-8。超過 10 個併發請求通常邊際效用會遞減,且增加觸發速率限制的風險。
成本追蹤
每項生成請求都會根據模型定價表進行估算:
plaintext1```python 2PRICING = { 3 "black-forest-labs/flux-2-pro/text-to-image": 0.04, 4 "bytedance/seedance-v1.5-pro/text-to-video": 0.022, # 每秒 5 "google/veo3.1/text-to-video": 0.03, # 每秒 6} 7```
針對影片模型,成本會隨長度增加:10 秒的 Seedance 2.0 影片成本為 USD0.22,而 10 秒的 Veo 3.1 為 USD0.30。清單檔案會追蹤單次請求與累計成本,方便預算監控。
管道執行成本估算
以下是典型的管線執行成本:
| 管線場景 | 工作內容 | 使用模型 | 估計成本 | 估計時間 |
|---|---|---|---|---|
| 每週社群包 | 10 張圖片 + 5 支影片 (每支 5s) | Flux 2 Pro + Seedance 2.0 | USD0.95 | ~10 分鐘 |
| 產品發布活動 | 20 張圖片 + 10 支影片 (每支 10s) | Flux 2 Pro + Imagen 4 Ultra + Seedance 2.0 | USD3.80 | ~25 分鐘 |
| 每月內容庫 | 50 張圖片 + 20 支影片 (每支 8s) | 混合模型 | USD7.50 | ~45 分鐘 |
| 電商目錄 (500 SKU) | 500 張圖片 | Flux 2 Pro | USD20.00 | ~30 分鐘 |
| 電影級廣告系列 | 5 張圖片 + 5 支影片 (每支 8s) | Imagen 4 Ultra + Veo 3.1 | USD1.50 | ~20 分鐘 |
Seedance 2.0 與 Veo 3.1 在相同影片長度下的成本比較:
| 模型 | 5s 影片 | 10s 影片 | 15s 影片 |
|---|---|---|---|
| Seedance 2.0 (快速) | USD0.11 | USD0.22 | USD0.33 |
| Veo 3.1 | USD0.15 | USD0.30 | N/A (最多 8s) |
| Sora 2 | USD0.75 | USD1.50 | USD2.25 |
Seedance 2.0 是高產量影片生成的最佳經濟選擇。Veo 3.1 在短篇電影級剪輯中提供了品質與成本的完美平衡。Sora 2 成本較高,但提供了無與倫比的物理模擬效果。
部署技巧
使用 Cron Jobs 進行排程生成
使用 cron 排程執行管線:
plaintext1```bash 2# 每週一上午 6 點執行 30 6 * * 1 cd /path/to/project && python run_pipeline.py --config weekly.yaml 4```
建立一個簡單的入口執行腳本:
plaintext1```python 2# run_pipeline.py 3import os 4import argparse 5import yaml 6from pipeline import VideoPipeline 7 8parser = argparse.ArgumentParser() 9parser.add_argument("--config", required=True) 10args = parser.parse_args() 11 12with open(args.config) as f: 13 config = yaml.safe_load(f) 14 15API_KEY = os.environ["ATLAS_CLOUD_API_KEY"] 16pipeline = VideoPipeline(api_key=API_KEY, output_dir=config["output_dir"]) 17pipeline.batch_generate(config["jobs"], max_workers=config.get("max_workers", 3)) 18```
基於佇列的架構 (Queue-Based)
針對較大規模的部署,使用如 Celery 或 Redis Queue 的任務佇列,將工作提交與處理解耦:
plaintext1```python 2# tasks.py (Celery 範例) 3import os 4from celery import Celery 5from pipeline import AtlasCloudClient 6 7app = Celery("video_tasks", broker="redis://localhost:6379") 8client = AtlasCloudClient(os.environ["ATLAS_CLOUD_API_KEY"]) 9 10@app.task(bind=True, max_retries=3) 11def generate_video_task(self, prompt, model, duration): 12 try: 13 result = client.generate_video(model, prompt, duration) 14 data = client.poll_result(result["request_id"]) 15 if data and data["status"] == "completed": 16 return {"url": data["output"]["video_url"], "status": "success"} 17 return {"status": "failed"} 18 except Exception as e: 19 self.retry(countdown=60, exc=e) 20```
此架構適用於影片生成請求來自 Web 應用程式或 API,且結果需透過 Webhook 或輪詢非同步遞送的生產系統。
環境變數管理
永遠不要將 API 金鑰寫死在程式碼中。使用環境變數:
plaintext1```python 2import os 3 4API_KEY = os.environ.get("ATLAS_CLOUD_API_KEY") 5if not API_KEY: 6 raise ValueError("ATLAS_CLOUD_API_KEY 環境變數未設定") 7```
針對本地開發,使用 python-dotenv 搭配 .env 檔案:
plaintext1```bash 2# .env 3ATLAS_CLOUD_API_KEY=您的金鑰 4```
plaintext1```python 2from dotenv import load_dotenv 3load_dotenv() 4```
錯誤監控
針對生產管線,請整合錯誤監控服務。本管線的日誌輸出結構化,易於被日誌聚合工具解析:
plaintext1```python 2logger.info(f"[OK] {result.name} -- USD{result.cost_estimate:.3f} -- {result.duration_seconds:.1f}s") 3logger.error(f"[FAIL] {result.name} -- {result.error_message}") 4```
將這些日誌路由至監控堆疊(Datadog, CloudWatch, Grafana)以追蹤成功率、成本與生成耗時。
擴充管線功能
加入 Image-to-Video 生成
部分模型支援將生成的圖片作為影片創作的輸入。請擴充管線以連結圖片與影片的生成流程:
plaintext1```python 2def generate_image_then_video(self, name, image_prompt, video_prompt, 3 image_model, video_model, duration=5): 4 """產生一張圖片,然後將其作為輸入進行影片生成。""" 5 # 步驟 1: 生成基礎圖片 6 image_result = self._process_image( 7 f"{name}_base", image_model, image_prompt 8 ) 9 if image_result.status != "success": 10 return image_result 11 12 # 步驟 2: 使用圖片 URL 作為影片生成的輸入 13 response = self.client.session.post( 14 f"{self.client.BASE_URL}/model/generateVideo", 15 json={ 16 "model": video_model, 17 "prompt": video_prompt, 18 "image_url": image_result.output_url, 19 "duration": duration 20 } 21 ) 22 # ... 按慣例進行輪詢與下載 23```
加入 Webhook 通知
針對長時作業的批次任務,可在工作完成時發送 Webhook 通知:
plaintext1```python 2def _notify_webhook(self, result: GenerationResult, webhook_url: str): 3 """將完成通知發送到 Webhook。""" 4 requests.post(webhook_url, json={ 5 "name": result.name, 6 "status": result.status, 7 "url": result.output_url, 8 "cost": result.cost_estimate 9 }) 10```
常見問題 (FAQ)
我可以進行多少併發請求?
Atlas Cloud 支援每個 API 金鑰進行多項併發請求。建議從 3 個 Worker 開始,並根據帳戶等級增加至 5-8 個。若超過限制,管線會自動以指數退避處理速率限制。
同一個批次可以混合圖片與影片任務嗎?
可以。管線會根據 type 欄位將每個工作路由到正確的端點 (/generateImage 或 /generateVideo)。圖片與影片工作會在相同的執行緒池中併發執行。
影片生成需要多久?
生成時間因模型而異:Seedance 2.0 通常在 30-90 秒內完成,Veo 3.1 為 60-120 秒,Sora 2 為 60-180 秒。管線的輪詢機制會自動處理這些時間差。
如果批次執行期間發生生成失敗怎麼辦?
失敗的工作會被記錄並留在清單中,並附帶錯誤訊息。管線會繼續處理其餘工作。每次執行後請檢查清單以識別並重新嘗試失敗的任務。
如何將新模型加入管線?
將模型 ID 與定價加入 AtlasCloudClient 的 PRICING 字典中,然後在工作配置中引用它即可。無需變更其他程式碼 —— 管線透過相同的 API 端點處理所有模型。
結論
建構 AI 影片管線的核心在於擁有可靠的基礎設施,以處理 API 整合的瑣碎現實:速率限制、超時、錯誤、成本追蹤以及併發執行。本指南中的管線涵蓋了以上所有面向。你可以直接複製使用、針對你的需求調整提示詞與模型,並部署在排程中或放在佇列後方。
Flux 2 Pro 的快速圖片生成、Seedance 2.0 在 USD0.022/sec 的高 CP 值,以及 Veo 3.1 在 USD0.03/sec 下提供原生音訊的電影級剪輯,讓你能夠滿足所有內容生產需求。這三款模型皆可透過單一 Atlas Cloud API 金鑰存取,意即一次整合、單一帳單關係,且只需管理一套憑證。
────────────────────────────────────────────────────────────






