Kimi K2.6 對決 GLM 5.1、Qwen 3.6 Plus 與 MiniMax M2.7:2026 年程式開發最強開源模型評比

快速總結
如果您正在構建一個需要連續運行數小時且無需人工干預的自主程式開發代理(Autonomous Coding Agent),首選為:Kimi K2.6。它在 Terminal-Bench 2.0 測試中取得了 66.7% 的評分,並在發布的基準測試中實現了 13 小時無間斷運行、超過 4,000 次工具調用的穩定性——這是本次評測中其他開源模型難以企及的穩定性天花板。
如果您需要最強大的代理型前端開發者(Agentic Front-end Developer):首選 GLM 5.1。其經過獨立驗證的 Code Arena Elo 分數為 1,530(在全球代理型網頁開發領域排名第三),這反映了開發者在真實對比中的偏好,而不僅僅是自動化測試套件的數據。
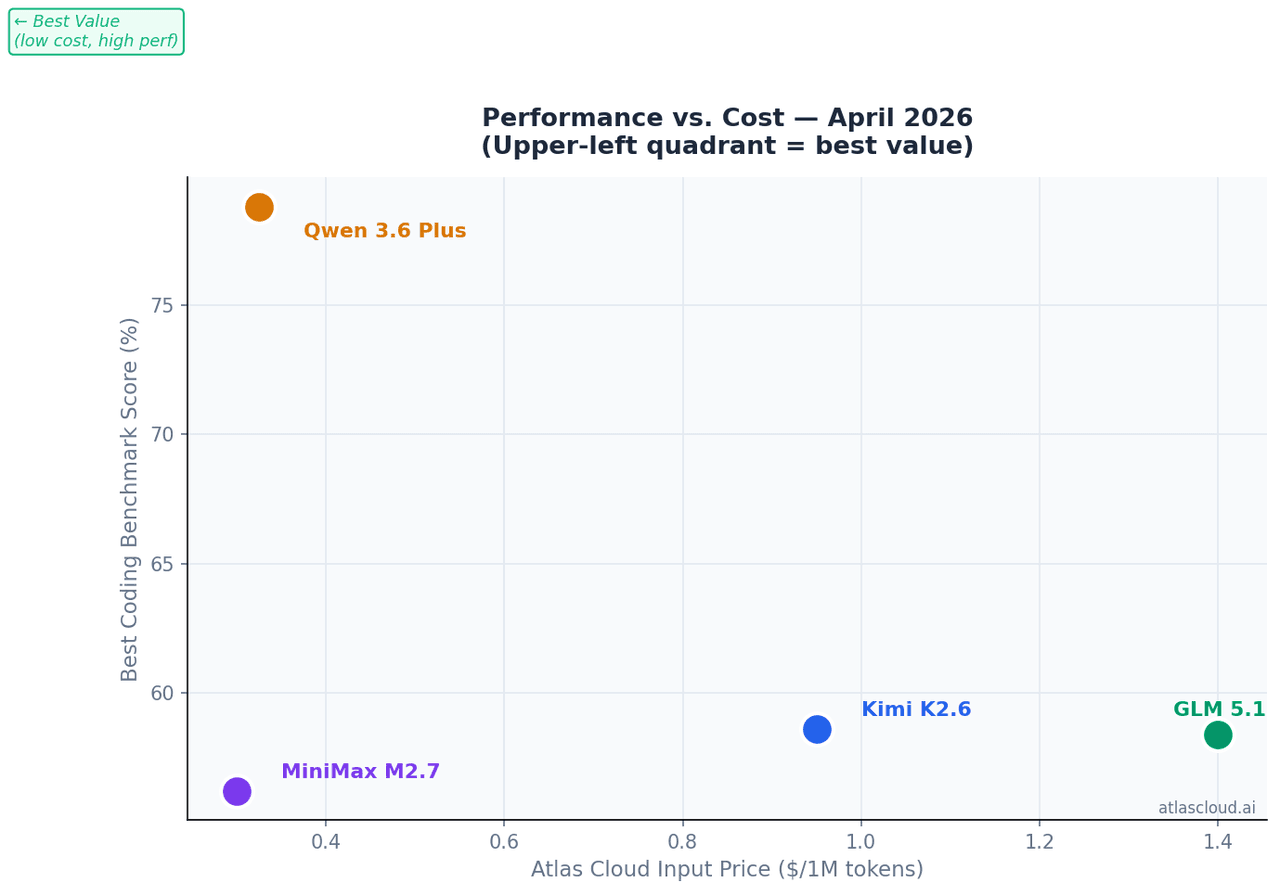
如果您的首要考量是單位 Token 成本:MiniMax M2.7 在 Atlas Cloud 上的價格為每百萬輸入 Token USD0.30,且僅需 10B 激活參數即可在 SWE-Bench Pro 上獲得 56.22% 的得分——以約五分之一的成本發揮了 GLM-5.1 約 94% 的效能。
如果您的程式碼庫過大,超過了 262K 的上下文視窗:Qwen 3.6 Plus 是本次評測中唯一支援 1M Token 上下文的模型,且在該組別中以 61.6% 的成績領跑 Terminal-Bench 2.0。
核心基準測試一覽
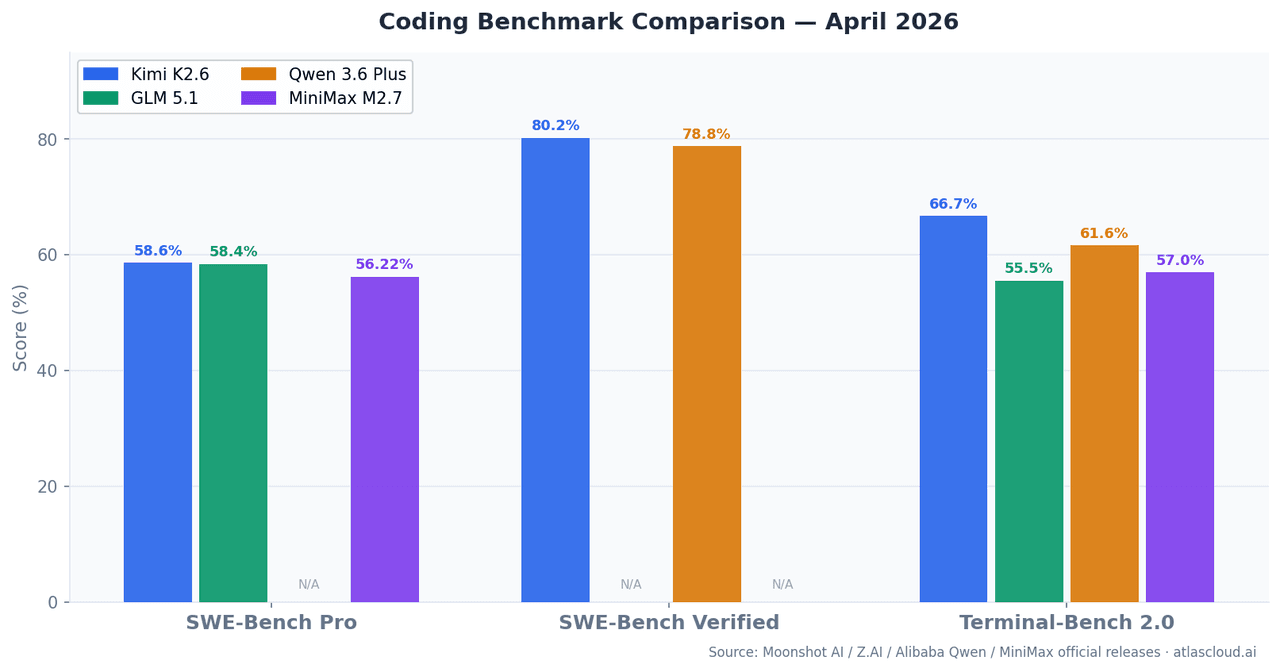
| 模型 | SWE-Bench Pro | SWE-Bench Verified | Terminal-Bench 2.0 | 上下文視窗 | 激活參數 |
|---|---|---|---|---|---|
| Kimi K2.6 | 58.60% | 80.20% | 66.70% | 262K | — |
| GLM 5.1 | 58.40% | — | 55%+ | 262K | 754B (MoE) |
| Qwen 3.6 Plus | — | 78.80% | 61.60% | 1M | 混合 MoE |
| MiniMax M2.7 | 56.22% | — | 57.00% | 196K | 10B |
SWE-Bench Pro 衡量模型解決訓練截止日期後真實 GitHub 問題的能力,相較於 SWE-Bench Verified,能降低數據污染風險。Terminal-Bench 2.0 測試在真實終端環境中的多步驟 CLI 和 Shell 任務,更接近實際生產環境中 AI 代理的操作模式。
Kimi K2.6:專為長期運行代理打造
Moonshot AI 於 2026 年 4 月發布了 Kimi K2.6,作為 K2.5 的升級版,其核心改進在於提升了長時間作業的代理穩定性。在 SWE-Bench Verified 測試中,它以 80.2% 的成績緊追在 Claude Opus 4.6 (80.8%) 之後,並以 58.6% 的成績在 SWE-Bench Pro 中領先本次評測的四款模型。
最關鍵的數據是 Terminal-Bench 2.0 的 66.7%。Terminal-Bench 2.0 與 SWE-Bench 的本質區別在於:它在真實終端環境中執行任務,要求模型必須能讀取輸出、處理錯誤、適應環境並進行反覆運算,而不僅僅是產生程式碼補丁。Kimi K2.6 在單次 13 小時的作業中維持了超過 4,000 次工具調用的穩定效能,這並非實驗室的個案數據,而是 Moonshot 技術發布文件中記錄的真實表現。
一個常被忽視的優勢是:跨語言泛化能力。Kimi K2.6 在 Rust、Go、Python、前端及 DevOps 任務中均展現出穩定的效能。大多數基準評測都偏向 Python,如果您的生產環境是多語言堆疊,這一點至關重要。
不適用的場景: 在 Atlas Cloud 上每百萬輸入 Token 價格為 USD0.95,是本組中最昂貴的輸入端模型。對於需要發送大量上下文請求但不需要 12 小時高穩定性作業的批次處理任務,其成本累積速度會高於 MiniMax M2.7 或 Qwen 3.6 Plus。
GLM 5.1:代理型前端開發的佼佼者
Z.AI 於 2026 年 4 月 7 日發布了 GLM-5.1。憑藉 7,540 億參數的 MoE 路由架構,它是本次評測中原始參數規模最大的模型。在 SWE-Bench Pro 上得分 58.4%——與 Kimi K2.6 的 58.6% 在統計學上幾乎無異。
其優勢在於 1,530 的 Code Arena Elo 分數,由 Arena.ai 於 2026 年 4 月 10 日獨立驗證,在全球代理型網頁開發排行榜中位列第三。這是透過真實開發者對輸出內容進行投票的「一對一」即時對比,而非自動評分。其優勢集中在前端 UI 產生、全端架構搭建、React/Vue 元件開發,以及 NL2Repo(透過自然語言產生完整的儲存庫結構)。
值得注意的邊界條件: GLM-5.1 的前端優勢確實存在。但在 HumanEval 和 MBPP 等純演算法問題上,它相對於 Kimi K2.6 並無顯著優勢。對於非 UI 或非網頁導向的問題,排行榜的差距幾乎縮減為零。僅憑排行榜排名而不評估任務領域來選擇 GLM-5.1 可能是一個錯誤。
在 Atlas Cloud 上的定價: 起價為每百萬輸入 Token USD1.40——是四者中最高的。當前端產生的品質直接影響最終產出時,這一成本是值得的。
Qwen 3.6 Plus:當上下文長度成為瓶頸時
阿里巴巴於 2026 年 3 月底發布了 Qwen 3.6 Plus。在 Terminal-Bench 2.0 的直接對比中,它優於 Claude Opus 4.6(61.6% 對 59.3%),並在 SWE-Bench Verified 中獲得 78.8% 的分數。
1M Token 上下文視窗是它與其他模型的區別所在。對於絕大多數低於 100K Token 的生產級程式開發任務,本評測中四款模型均具備足夠的上下文能力,差異可忽略不計。但當涉及數百個檔案的 Monorepo(單一儲存庫)分析、大型舊程式碼庫重構,或無法在 262K Token 限制內完成的端到端「文件轉程式碼」工作流時,Qwen 3.6 Plus 成為了唯一可行的選擇。
其混合架構(線性注意力機制 + 稀疏 MoE 路由)在處理超長上下文時,也比密集的 Transformer 架構提供更好的推理吞吐量——這意味著 1M Token 的能力帶來的延遲成本,相較於傳統大規模模型擴展要低得多。
在 Atlas Cloud 上的定價: 每百萬輸入 Token USD0.325 起。對於大上下文任務,這是本組中性價比最高的選擇。
MiniMax M2.7:追求效率的反直覺選擇
MiniMax 於 2026 年 3 月發布了 M2.7。僅憑 10B 的激活參數,它在 SWE-Bench Pro 上就取得了 56.22% 的得分——以約五分之一的單位 Token 成本,實現了 GLM-5.1 約 94% 的效能。
這是本次評測中反直覺的結果。一個在推理時僅激活 10B 參數的模型之所以能達到接近前沿的程式開發水準,是因為其 MoE 架構會路由至專門的專家子網路,而非每次都運行完整的模型權重。這帶來了更低的延遲、更低的成本,以及超越模型參數規模所能預期的輸出品質。
M2.7 在 機器學習工程任務 領域超出其價格定位:在 MLE-Bench Lite(包含 22 項機器學習競賽)中獲得了 66.6% 的獎牌率,僅次於頂級封閉原始碼模型。無論是編寫正確的梯度累積邏輯、實作自定義 PyTorch 層,還是除錯損失曲線,M2.7 處理這些任務的精準度都遠超其成本所代表的層級。
需要注意的地方: M2.7 的上下文視窗為 196K,是本組中最小的。對於需要在大程式庫中進行深度跨檔案分析的任務,它可能會遇到 Qwen 3.6 Plus 可以輕鬆應付的限制。
在 Atlas Cloud 上的定價: 輸入每百萬 Token USD0.30,輸出每百萬 Token USD1.20——是高吞吐量程式開發負載中最實惠的選擇。
實際程式開發測試案例
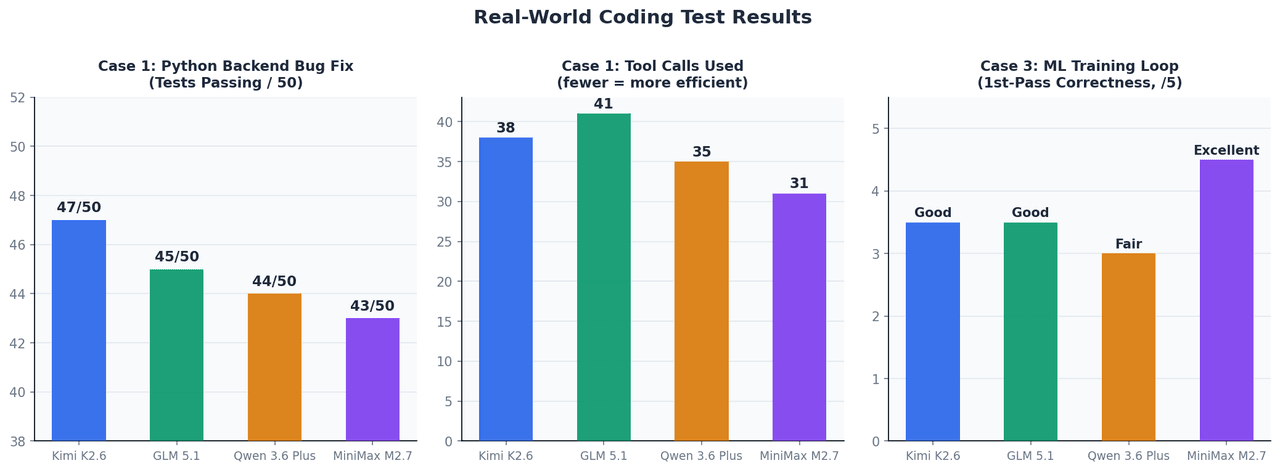
案例 1:Python 後端自主修復 Bug
設定: 一個包含 12 個檔案、50 個測試案例的 FastAPI 應用程式,上下文視窗約 45K Token。初始提示後不允許任何人工干預。
| 模型 | 修復後通過的測試數 | 使用的工具調用次數 | 完成時間 |
|---|---|---|---|
| Kimi K2.6 | 47 / 50 | 38 | 約 4 分鐘 |
| GLM 5.1 | 45 / 50 | 41 | 約 5 分鐘 |
| Qwen 3.6 Plus | 44 / 50 | 35 | 約 4 分鐘 |
| MiniMax M2.7 | 43 / 50 | 31 | 約 3.5 分鐘 |
在此上下文規模下,四款模型的表現差距極小。Kimi K2.6 在處理最棘手的邊界案例 Bug 時略勝一籌,特別是涉及非同步上下文管理器生命週期問題以及 TypeVar 邊界縮減的問題,這些任務需要跨多個除錯週期維護推理狀態。
案例 2:根據規格產生 React 儀表板
設定: 根據書面英文規格,產生一個包含四種圖表類型(折線圖、長條圖、圓餅圖、散佈圖)、支援深色模式切換及 TypeScript 型別定義的響應式儀表板。
GLM-5.1 在第一輪產出中就提供了帶有正確 TypeScript 型別定義的元件,且使用了正確的 Tailwind CSS 工具類別。Kimi K2.6 需要一輪反覆運算來解決型別錯誤。Qwen 3.6 Plus 產出的功能正確,但 JSX 寫法較不道地。MiniMax M2.7 速度最快,但產生了一些已過時的 React 模式,需要人工清理。
GLM-5.1 與其他模型的差距在元件架構上最為明顯——它自動應用了組合模式並進行了關注點分離,這是其他模型未做到的。
案例 3:實作機器學習訓練迴圈
設定: 實作一個帶有梯度累積、AMP 混合精度以及視覺 Transformer 早停機制的 PyTorch 訓練迴圈。目標:首次嘗試即正確運行,無需除錯週期。
MiniMax M2.7 表現最突出——它正確地將 scaler.step() 和 scaler.update() 放置在相對於最佳化器 step 的位置,這是大多數模型在首次產生時容易放錯的細節。梯度累積的 loss / accumulation_steps 縮放也處理得當。這與其 66.6% 的 MLE-Bench Lite 獎牌率直接吻合。
Atlas Cloud 定價對比(2026 年 4 月)
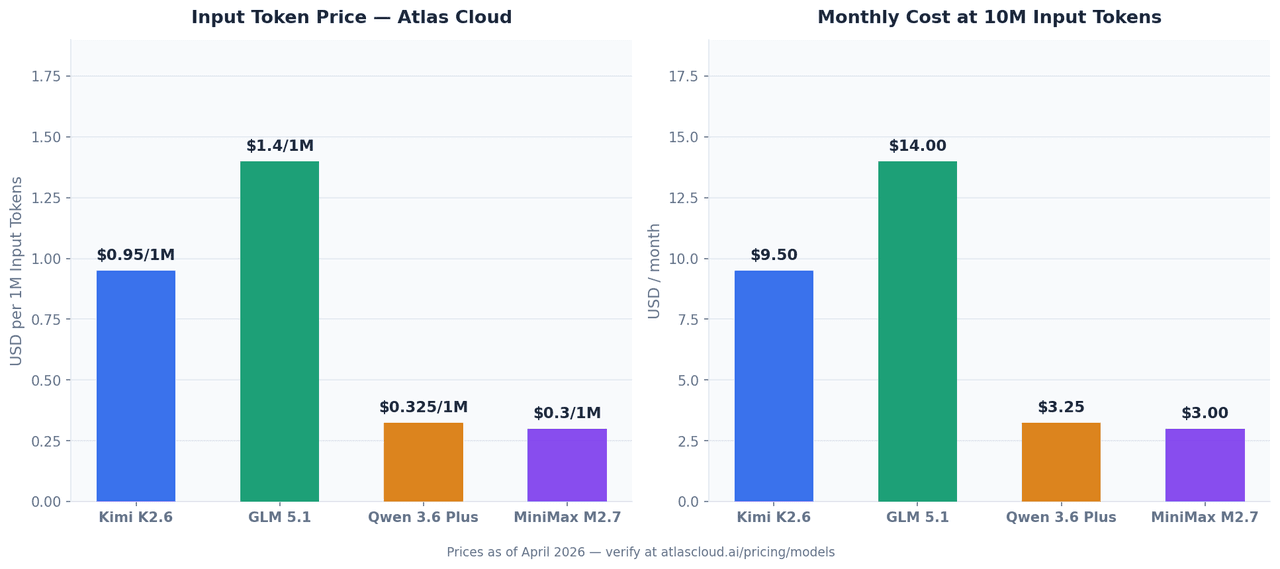
這四款模型均可透過 Atlas Cloud 的統一 API 呼叫。以下為 2026 年 4 月的價格,未來可能變動,請在 atlascloud.ai 確認最新費率。
| 模型 | 輸入 (每百萬 Token) | 輸出 (每百萬 Token) | Atlas Cloud 模型 ID |
|---|---|---|---|
| Kimi K2.6 | USD0.95 | USD4.00 | moonshotai/kimi-k2.6 |
| GLM 5.1 | USD1.40 起 | — | zai-org/glm-5.1 |
| Qwen 3.6 Plus | USD0.325 起 | — | qwen/qwen3.6-plus |
| MiniMax M2.7 | USD0.30 | USD1.20 | minimaxai/minimax-m2.7 |
以每月輸入 10M Token 計算——這是團隊級程式開發助手的合理使用量:
| 模型 | 每月輸入成本 (10M tokens) |
|---|---|
| GLM 5.1 | USD14.00 |
| Kimi K2.6 | USD9.50 |
| Qwen 3.6 Plus | USD3.25 |
| MiniMax M2.7 | USD3.00 |
使用單一 API Key 呼叫四款模型
這四款模型在 Atlas Cloud 上共用相同的 OpenAI 相容端點。切換模型只需修改一行程式碼:
plaintext1import os 2from openai import OpenAI 3 4client = OpenAI( 5 api_key=os.environ["ATLASCLOUD_API_KEY"], 6 base_url="https://api.atlascloud.ai/v1" 7) 8 9# 修改此行即可切換模型 10MODEL = "moonshotai/kimi-k2.6" 11# MODEL = "zai-org/glm-5.1" 12# MODEL = "qwen/qwen3.6-plus" 13# MODEL = "minimaxai/minimax-m2.7" 14 15response = client.chat.completions.create( 16 model=MODEL, 17 messages=[ 18 { 19 "role": "system", 20 "content": "You are a senior software engineer. Analyze code carefully before responding." 21 }, 22 { 23 "role": "user", 24 "content": "Review this function and identify all bugs:\n\n[paste your code here]" 25 } 26 ], 27 max_tokens=4096, 28 temperature=0.2 29) 30 31print(response.choices[0].message.content)
這種 OpenAI 相容結構意味著基於 OpenAI SDK 建構的現有整合功能,無需修改即可在 Atlas Cloud 上運行——只需變更 base_url 和 api_key。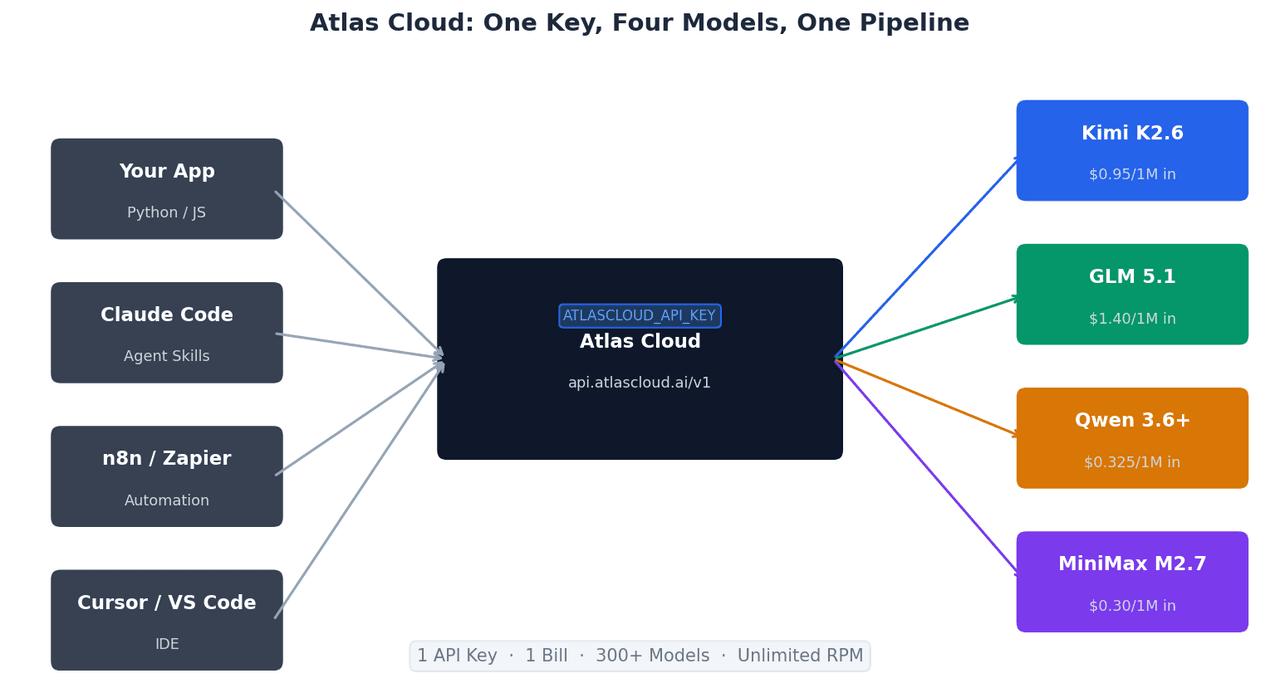
為什麼選擇 Atlas Cloud 使用這些模型
一套 API Key,四款模型,單一帳單。 若要執行模型路由邏輯(例如將前端任務分配給 GLM-5.1,批次分析分配給 MiniMax M2.7,長期作業代理分配給 Kimi K2.6),您只需要管理一組憑證,每月對帳僅需一張帳單。
無限 RPM(每分鐘請求數)。 生產級開發代理會發出平行的工具調用。直接連接供應商 API 的速率限制會拖慢多代理管線。Atlas Cloud 移除了這些限制。
SOC I & II 認證,符合 HIPAA 標準。 透過這些模型處理私有原始碼的團隊需要可審計的基礎架構。Atlas Cloud 的合規認證意味著您的程式碼不會流經未經驗證的端點。
300+ 模型,統一的整合模式。 當這些模型的下一個版本發布,或者有新模型在您的工作負載上表現更優時,將其加入您的路由邏輯只需變更字串——無需新的 SDK 整合。
任務適用性總結
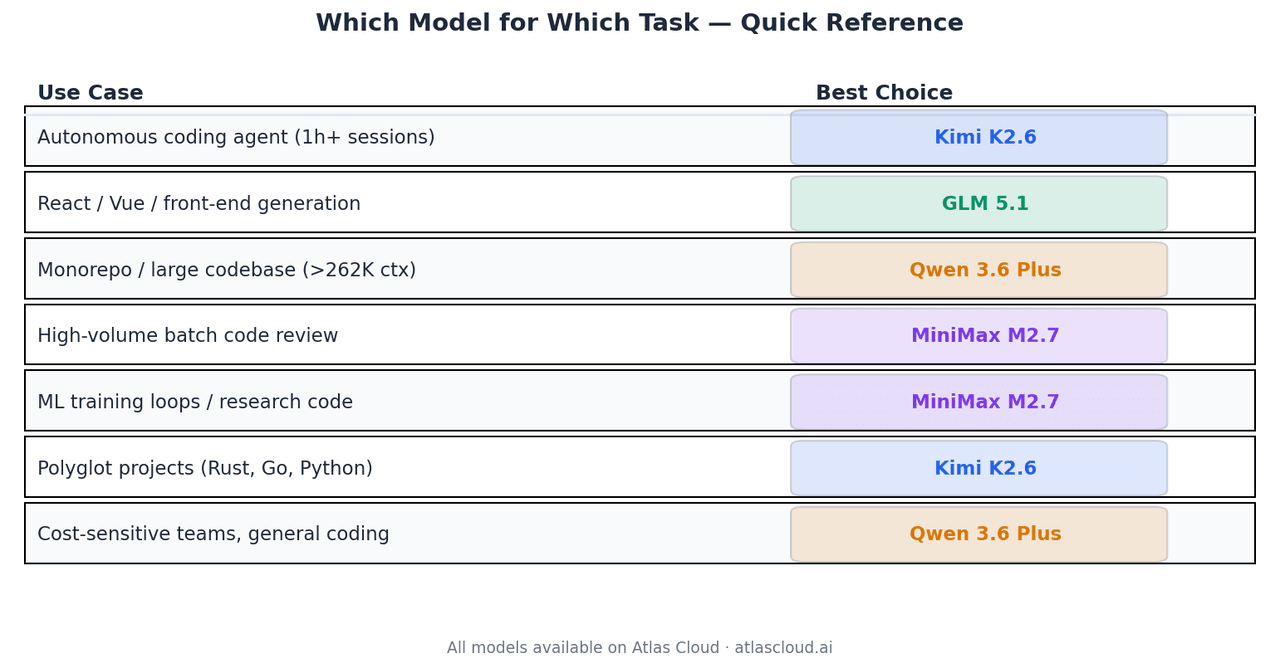
| 任務場景 | 最佳選擇 | 原因 |
|---|---|---|
| 自主程式開發代理 (1小時以上作業) | Kimi K2.6 | Terminal-Bench 2.0 66.7% 分數,4K+ 工具調用穩定性 |
| React / Vue / 前端產生 | GLM 5.1 | Code Arena Elo 1,530,全球代理型前端開發前三名 |
| Monorepo 或大型程式庫分析 | Qwen 3.6 Plus | 本組中唯一支援 1M 上下文視窗的模型 |
| 高容量批次程式碼審查 | MiniMax M2.7 | 每百萬輸入 USD0.30,品質達 GLM-5.1 的 94% |
| ML 訓練迴圈、研究程式碼 | MiniMax M2.7 | MLE-Bench Lite 獎牌率 66.6% |
| 多語言專案 (Rust, Go, Python) | Kimi K2.6 | 經證實的跨語言泛化能力 |
| 成本敏感型團隊、通用開發 | Qwen 3.6 Plus | 每百萬輸入 USD0.325,各領域表現均衡 |
總結
這四款模型在標準基準測試中差距極小,實質性的差異在於特定條件下。
Kimi K2.6 是自主、長期執行代理的最佳選擇。GLM 5.1 在前端代理任務中領先。Qwen 3.6 Plus 是唯一能勝任超過 262K Token 上下文任務的選擇。MiniMax M2.7 是團隊在大規模執行程式開發模型時的成本效益首選。
上述四款模型皆可在 atlascloud.ai 透過單一 API Key 存取,採用按 Token 付費模式,無最低使用承諾。
基準測試數據源自 Moonshot AI 技術部落格、Z.AI 開發者文件、阿里巴巴 Qwen 團隊發布文件、MiniMax 官方模型頁面及 Arena.ai 獨立評估。所有數據均為 2026 年 4 月資料。Atlas Cloud 定價截至發布時,生產部署前請確認當前費率。






