
幾個月前,我們為自己設下了一個看似簡單的目標:在單顆 GPU 上,以遠低於 60 秒的實際執行時間(wall-clock time),產出超過 15 秒且高品質、連貫的影片。目前像 Wan2.2 這類影片擴散模型(video diffusion models)在處理 3–5 秒的片段時表現出色,但要將其拉長到 10 秒、30 秒甚至一分鐘,才是挑戰真正的開始。
這篇文章記錄了我們實際採取的路徑。我們評估了近期論文與技術報告中出現的六種方法——TTT、LoL、Self Forcing、Self Forcing++、Infinite Talk 以及 Helios,測量了它們的權衡指標,最終選擇了 SVI (Stable Video Infinity),並將其整合至我們 DiffSynth Engine 中的 TurboWan。我們將一一探討這些路徑,並說明 SVI 的運作原理及最終的效能數據。
為什麼長影片很難做
當影片長度超過五秒時,有三個關鍵問題會浮現。
VRAM 的瓶頸
Wan2.2 使用了 Full Attention,其計算成本隨潛在標記(latent tokens)數量的增加呈 O(n²) 成長。數學是殘酷的:
**5 秒(81 幀):**約 32.7k 個標記,注意力矩陣約 10 GB。
**10 秒(165 幀):**約 65.5k 個標記,注意力矩陣約 40 GB——單顆 GPU 已無法負擔。
**30 秒(約 500 幀):**約 200k 個標記,無法執行。
在實務上,僅僅是 Self Forcing 的 KV 快取(KV cache)在 165 幀時就會填滿 H200 的 129 GB VRAM。
時間軸漂移(Temporal drift)
即便記憶體足夠,也會出現三種漂移模式。Helios 論文將其命名為:位置偏移(position shift,主體在畫面中漫遊)、色彩偏移(color shift,色調與亮度逐漸改變),以及修復偏移(restoration shift,模型過度修正導致明顯的不連續)。
因果一致性(Causal consistency)
標準影片擴散模型使用雙向 Full Attention,即每一幀都會關注其他所有幀。這意味著無法實現串流輸出:在第 N 幀完成前,你無法顯示第 1 幀。
我們設定的具體目標很務實:影片長度 ≥15 秒、流暢的視覺連貫性、整個片段內主體穩定、總等待時間低於 60 秒、訓練需求極小,並強烈傾向於重複使用現有的權重。
技術盤點
我們研究了六個系列的方法。名稱大多來自論文標題,分類對後續討論至關重要。
路徑 1 · TTT (Test-Time Training)
論文:One-Minute Video Generation with Test-Time Training (arXiv 2504.05298, 2025年4月)。
核心概念是在推論過程中微調模型,使其記住已生成的內容。每個 Transformer Block 的 Attention 之後都會插入一個小的 TTT 層(包含一個 2 層 MLP、一個 Gate 和一個局部注意力),並透過從短片段推進到完整一分鐘的課程進行訓練。
**逐層插入:**在標準注意力之後,拼接一個 Gate、一個 TTT 層與局部注意力,最後加上 LayerNorm。
**課程設計:**在逐步增加的視窗長度上訓練——3s → 9s → 18s → 30s → 60s。
**成本:**256 顆 H100 訓練約 50 小時。
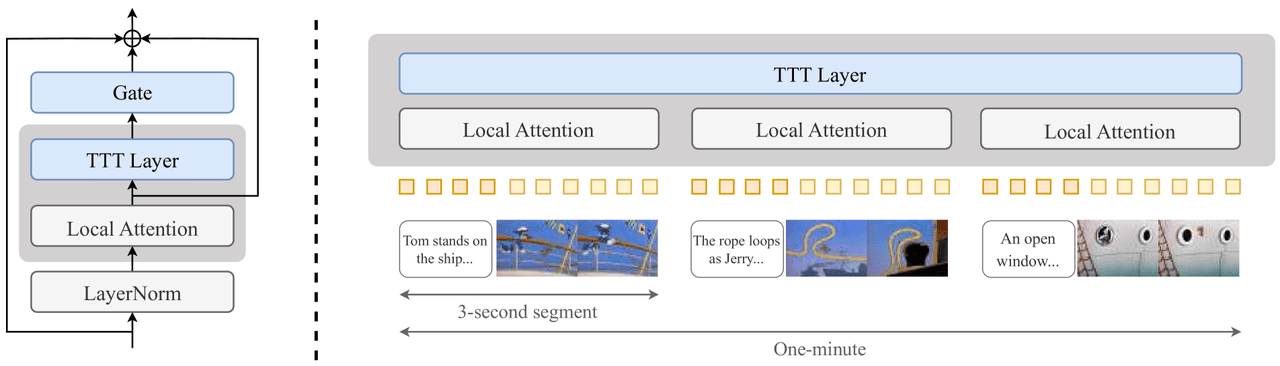
TTT — 左:插入點(Gate + TTT 層 + 局部注意力 + LayerNorm,透過殘差連接附著在標準 Attention 之後)。右:影片被分割為 3 秒的片段,每個片段內部由局部注意力處理,而 TTT 層負責跨片段的全局記憶。
它確實可行,論文實現了一分鐘的生成。但訓練成本極高,實驗僅涵蓋 CogVideoX 5B(轉移至 Wan2.2 14B 的能力尚未證實),且插入的 TTT 層會與我們依賴的核心最佳化機制衝突。結論:未入選。
路徑 2 · LoL (Longer than Longer)
論文:LoL: Longer than Longer, Scaling Video Generation to Hour (arXiv 2601.16914, 2026年1月)。
LoL 針對的是自回歸長影片中的特定故障模式——槽坍塌(sink-collapse),即多頭注意力全部收斂到錨定幀,導致影片週期性地重置為初始狀態。解決方法是 Multi-Head RoPE Jitter:透過每頭不同的隨機相位擾動來打破頭與頭之間的同質性。無需訓練,直接插拔使用。
**故障模式:**槽坍塌——在自回歸 RoPE 下,遠處幀的位置相位會週期性地與錨定幀重新對齊,注意力過度集中,內容會跳回到錨定幀。
**修正:**給每個注意力頭分配各自的小型隨機相位偏移。這樣注意力頭就不會坍塌到同一列。無需重新訓練,可直接套用現有模型。
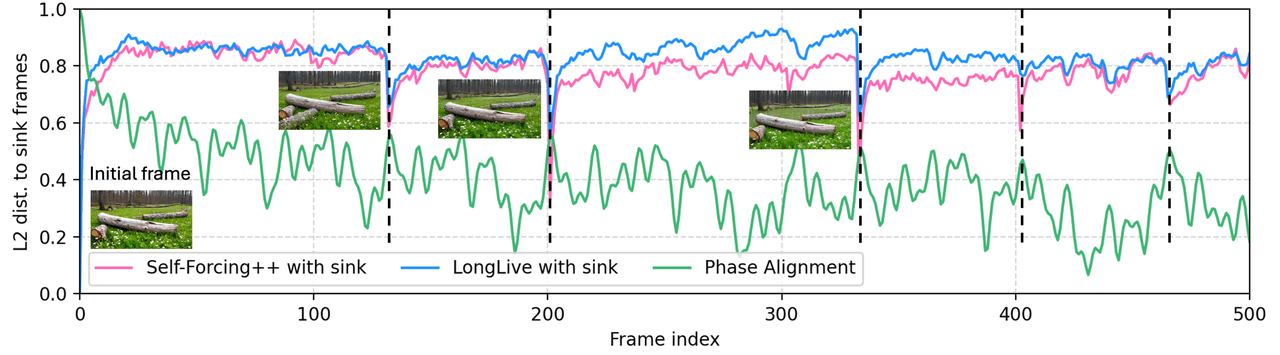
錨定幀的 L2 距離與幀索引對比。Self-Forcing++ (紅) 和 LongLive (藍) 都會發生坍塌,在特定幀位置反覆跳回;LoL 的相位對齊 (綠) 則消除了這種跳回現象。
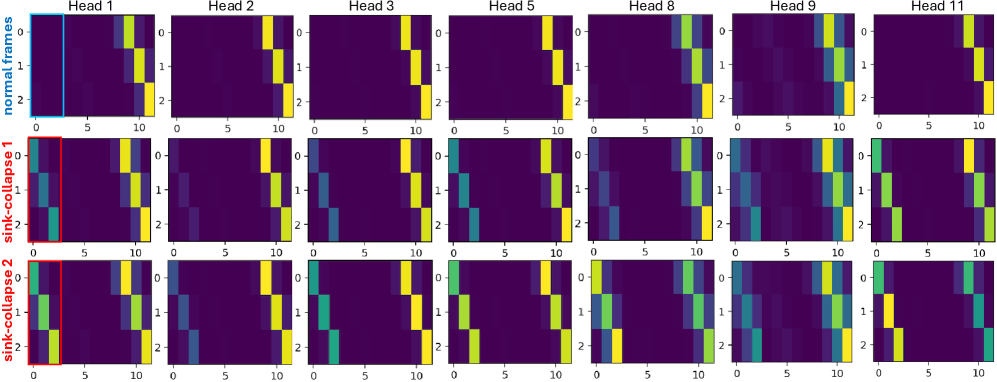
每頭注意力圖。上排:正常幀——各頭表現出明顯差異。下排:在坍塌期間——每頭看起來都一樣,全部集中在錨定幀的那一列。RoPE Jitter 恢復了各頭的多樣性。
LoL 在 CogVideoX/HunyuanVideo 上實現了 12 小時的影片生成,且品質損失極小。但問題在於所有展示案例多為靜態場景;我們不確定它在舞蹈、運動等有強烈動態的場景中表現如何。此外,我們必須修改 Wan2.2 的注意力機制。結論:在動態內容上的增益未經證實且調整成本過高。未入選。
路徑 3 · Self Forcing (Causal Wan2.2)
論文:Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (arXiv 2506.08009, NeurIPS 2025 Spotlight)。
Self Forcing 將 Wan2.2 的雙向 Full Attention 替換為*因果(causal)*注意力:每一幀只關注前一幀。這一改變解鎖了串流生成——一旦第一區塊完成,即可解碼並輸出。
**雙向:**每一幀關注所有幀 → 必須完成全部 40 個去噪步驟才能顯示任何一幀。**因果:**每一幀只看過去 → 第一個區塊完成即可即時串流。
論文的核心訓練技巧在於:它不是使用乾淨的基準內容(教師強制),而是利用滾動式 KV 快取重複推論過程,確保訓練與推論的分布一致。
**生成循環:**使用 DMD 的壓縮步長計畫,基於已生成幀組成的滾動 KV 快取,去噪出下一個小片段。
**串流:**區塊一完成,立即進行 VAE 解碼並輸出。
**傳遞:**將新區塊的潛在變量推入 KV 快取,供下一個區塊參考。
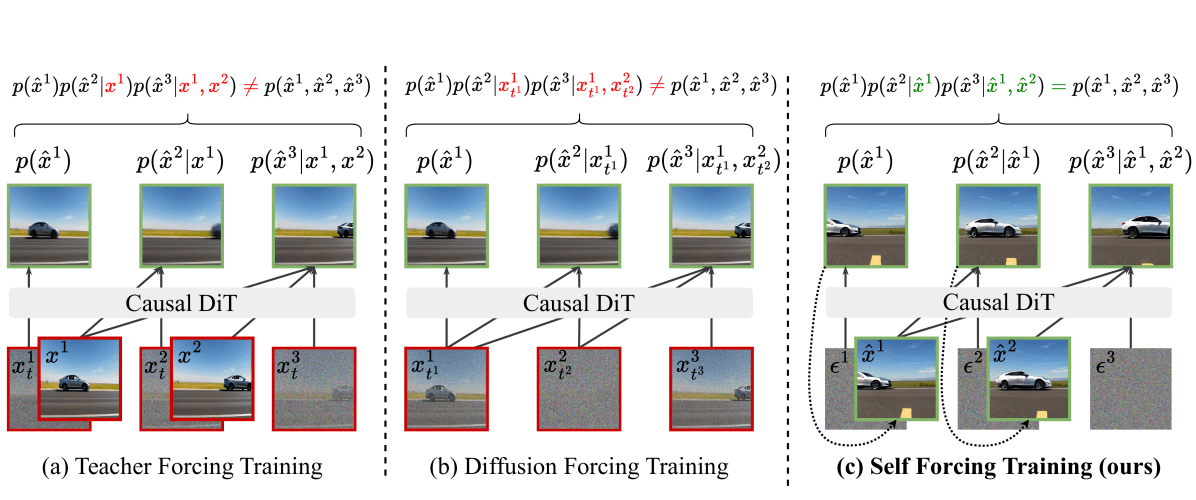
三種訓練範式對比:(a) 教師強制訓練在乾淨幀上——推論時雜訊會導致偏差;(b) 擴散強制使用自定義注意力遮罩,但仍有訓練推論不匹配;(c) Self Forcing 利用滾動 KV 快取重現真實推論過程,完全對齊訓練與推論。
我們在 FastVideo 框架下於單顆 H200 測量結果如下:
| 長度 | 幀數 | 時間 | VRAM |
|---|---|---|---|
| 5s | 81 幀 | 70s | — |
| 10s | 165 幀 | 168s | 129 GB (近滿載) |
| 20s | 321 幀 | 287s | 129 GB (KV 快取限制在 42 幀) |
這是架構上最乾淨的解法,我們非常喜歡。但 10 秒已填滿 H200 的 VRAM,且 165 幀時品質下降,原模型需要因果注意力微調,真正的串流還需要 VAE 中的 Causal Conv3D。
結論:等待社群解決 VRAM 和品質問題,目前暫不採用。
路徑 4 · Self Forcing++
論文:Self-Forcing++: Towards Minute-Scale High-Quality Video Generation (arXiv 2510.02283, 2025年10月)。
在 Self Forcing 基礎上增加了三點:後向雜訊初始化(每個新區塊從前一區塊反向整合的雜訊開始,消除邊界斷層);擴充 DMD 對齊(將長卷軸切分成 5 秒視窗,並針對教師模型的短視窗進行對齊);以及 GRPO 階段,利用光流獎勵來推動更動態的運動。
**步驟 1:**以滾動 KV 快取自行延伸長於 5 秒的長卷軸草稿。**步驟 2:**從草稿中隨機切出 5 秒視窗,執行擴充 DMD 與教師分布對齊。**步驟 3:**利用光流大小作為獎勵進行 GRPO 調整。**技巧:**新區塊從上一區塊反向整合的雜訊開始,而非新鮮的高斯雜訊,因此不會出現區塊斷層。
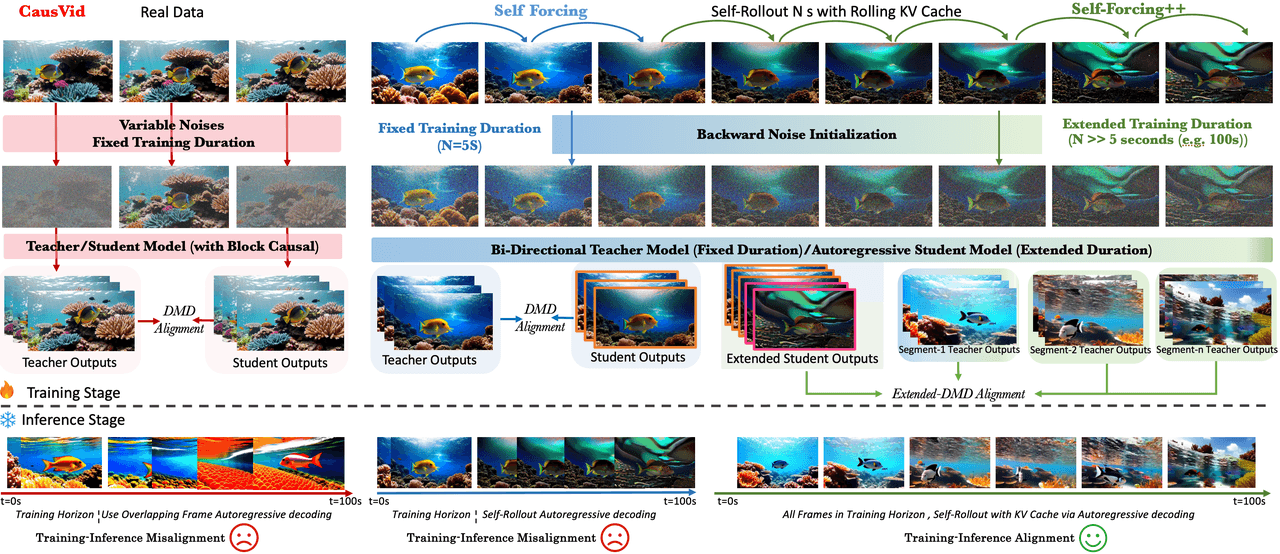
從左至右:CausVid(訓練長度固定,訓練推論不匹配)→ Self Forcing(固定長度 + DMD 對齊)→ Self-Forcing++(延伸長度 + 後向雜訊初始化 + 擴充 DMD 對齊)。
結果:在 1.3B Wan2.1 上實現了一分鐘級別的影片(最長約 4 分 15 秒)。好論文,但我們在生產環境遇到兩個困難:內容多為靜態,基礎模型僅 1.3B(遠低於 Wan2.2 14B),且無程式碼或權重可供啟動。結論:暫不選用。
路徑 5 · Infinite Talk (A2V)
完全不同的問題類型——音訊轉影片(Audio-to-Video),由音訊驅動連續的說話頭像生成。
**每區塊輸入:**新區塊的帶雜訊潛在變量、該時間視窗的音訊特徵、用戶參考圖、上一區塊的最後一幀,以及一個軟約束權重。**參考身份:**參考圖像保持長期外觀穩定。**適應性約束:**軟權重根據相似度漂移調整參考的強度。**運動橋樑:**上一區塊的最後一幀跨界傳遞運動。
對於說話頭像來說非常優秀,但架構與 Wan2.2 差異過大,需要專門訓練,且無法推廣到通用場景。結論:在特定領域有價值,非通用長影片解決方案。
路徑 6 · Helios
論文:Helios: Real Real-Time Long Video Generation Model (PKU-YuanGroup, arXiv 2603.04379, 2026年3月)。
截至撰寫本文時,Helios 是長影片領域的 SOTA(最先進技術)——14B 參數,在單顆 H100 上達到 19.5 FPS 的即時效能。訣竅是將歷史幀壓縮為三層金字塔並注入當前幀的去噪中,使標記預算在影片變長時保持恆定。
**多階記憶:**短期歷史(最後 3 幀)保留完整解析度;中期(最後 20 幀)中度壓縮;長期(之前所有內容)高度壓縮。標記預算與影片長度無關。**指導注意力:**在每個 DiT 區塊內,乾淨的歷史 KV 與帶雜訊的當前 QKV 分開處理,防止歷史雜訊污染當前去噪。**金字塔採樣:**先以低解析度採樣定義結構,再提升至高解析度添加細節,總體標記數減少約 2.3 倍。
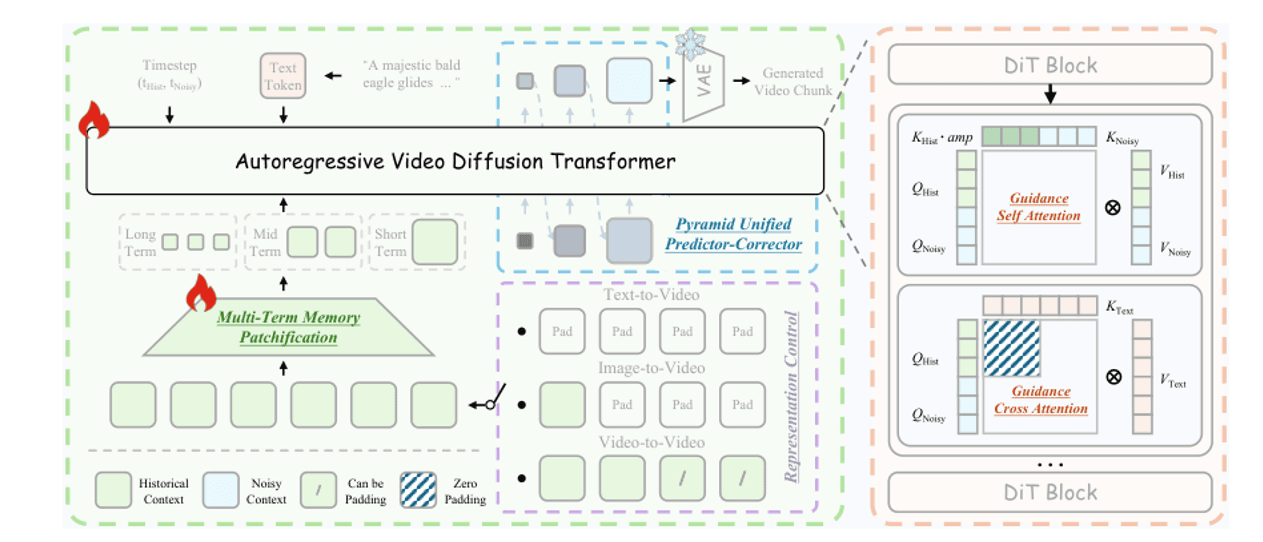
Helios 架構。左:統一歷史注入——不同壓縮比的歷史資訊合併進入 DiT。右:金字塔統一預測校正器——先低標記數定義結構,後高標記數完善細節。

Helios 系統定義並視覺化了三類漂移:(a) 位置偏移,(b) 色彩偏移,(c) 修復偏移(雜訊/模糊)。指導注意力專門為解決這些問題設計。
Helios 在 H200 上的測量吞吐量表現驚人——效能基本上不受長度影響:
| 長度 | 時間 | 吞吐量 |
|---|---|---|
| 240 幀 (10s) | 24s | ~10 FPS |
| 480 幀 (20s) | 42s | ~11.4 FPS |
| 960 幀 (40s) | 82s | ~11.7 FPS |
| H100 單卡 (Helios-Distilled) | — | 19.5 FPS |
缺點是「多階記憶補丁化」(Multi-Term Memory Patchification)需要對 14B 模型進行全面重新訓練。目前沒有釋出權重,只有技術報告,因此我們無法簡單地加裝 LoRA。結論:中長期發展方向,目前無法部署。
路徑總結與比較
將六種路徑並列,並加入我們最終選擇的 SVI:
| 方法 | 最大長度 | 品質 | 訓練需求 | 工程難度 | 通用性 | 推薦 |
|---|---|---|---|---|---|---|
| TTT | 1 分鐘 | 高 | 大量訓練 | 高 | 中 | ★★☆ |
| LoL | 小時級 | 中 (僅靜態) | 需訓練 | 中 | 中 | ★★☆ |
| Self Forcing | 理論無限 | 中 (>10s 掉品質) | 現有模型 | 高 (VRAM問題) | 高 | ★★★ |
| Self Forcing++ | 分鐘級 | 低 (多靜態) | 需訓練 | 極高 (無程式碼) | 高 | ★☆☆ |
| Infinite Talk | 無限 | 高 (頭像) | 需訓練 | 高 | 低 (僅 A2V) | ★★☆ |
| Helios | 理論無限 | 高 (SOTA) | 完全重訓 | 極高 (無權重) | 高 | ★★★☆ |
| SVI | 無限 | 中高 | 開源 LoRA | 中 | 高 | ★★★★ |
從盤點中歸納的分類學
如果仔細觀察,我們調查的所有方法都屬於以下三類:
A 類 — 擴展注意力範圍本身(Self Forcing, LoL, TTT)。讓模型直接處理更長的序列。理論品質最高,但 VRAM 呈二次方成長,目前工程上在 10 秒左右會遇到瓶頸。
B 類 — 分層歷史壓縮(Helios)。壓縮過去幀並注入作為條件。繞過 VRAM 限制,但成本是需要重新訓練 14B 模型。
C 類 — 狀態滾動式生成(SVI, Infinite Talk)。將長影片分解為帶有重疊狀態的短片段。VRAM 恆定,長度無限,僅需 LoRA 訓練。代價是片段邊界可能出現不連續,以及需要管理但無法完全消除的長期漂移。
本季度,我們選擇部署 C 類。明年,我們將持續關注 B 類的文獻發展。
在下一篇文章中,我們將深入探討實際部署的情況——針對 ≥15 秒影片生成的六種方法,我們為何選擇 SVI,以及生產環境的數據表現。閱讀第二篇 →






