
在第 1 部分中,我們調研了六種長影片生成方法——TTT、LoL、Self Forcing、Self Forcing++、Infinite Talk 和 Helios,並最終認定 SVI 是目前唯一能在無需重新訓練 14B 模型的前提下實現落地的途徑。本文將深入探討其實際構建過程:片段拼接循環(clip-stitching loop)的運作原理、為什麼「錯誤回收」(Error-Recycling)至關重要,以及我們在 TurboWan 上首次部署的生產數據。
選擇:SVI (Stable Video Infinity)
SVI 的核心理念是將無限長度的生成轉化為透過精心設計的記憶傳輸(memory transfer)來拼接有限數量的短片段。聽起來很簡單,但它同時解決了大部分工程痛點:無需基礎模型重新訓練(僅需在 TurboWan 上掛載一個小型 LoRA)、維持恆定的顯存佔用、可與現有的速度蒸餾(speed-distillation)技術組合,且官方 LoRA 權重已公開。
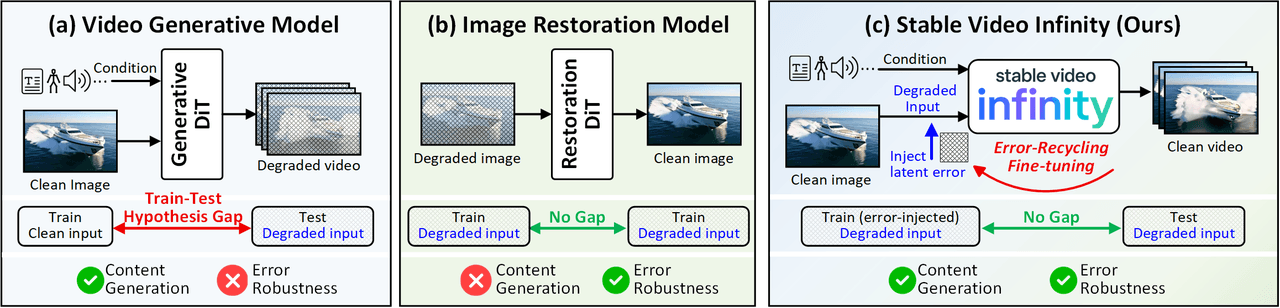
SVI 的思維模型。(a) 標準影片生成模型存在「訓練-測試假設差距」(Train-Test Hypothesis Gap)——它們在乾淨的輸入上訓練,但在推理時卻面臨充滿噪點和誤差累積的輸入。(b) 影像修復模型對誤差具有魯棒性,但無法生成新內容。(c) SVI 的錯誤回收微調(Error-Recycling Fine-Tuning)架起了兩者的橋樑——利用自生成的誤差作為監督訊號,使模型能主動識別並修正自身的生成誤差。
片段拼接原理
每個片段為 81 幀(5秒 @ 16fps)。生成過程就是一個循環:以全局身份錨點(global identity anchor)和前一個片段的短期運動橋接(short-term motion bridge)作為下一個片段的條件,然後進行拼接。
片段 1: 輸入:參考影像 + 空的運動記憶。輸出:一個 5 秒片段。提取運動記憶:最後 4 幀的潛在空間(latent)。片段 2: 輸入:參考影像 + 來自片段 1 的運動記憶。輸出:一個 5 秒片段。從其尾部提取運動記憶。…… 重複 N 個片段,最後將片段 1 + 片段 2 + … + 片段 N 拼接成長影片。
巧妙之處在於無需修改 DiT 注意力機制。歷史上下文以潛在空間形式在輸入層進行拼接,並透過一個小型 LoRA 教導模型實際利用這些前綴。
錨點潛在空間(Anchor latent): 用戶提供的參考影像,經由 VAE 編碼 → 保持主體/角色外觀的全局一致性。運動潛在空間(Motion latent): 前一個片段最後 4 / 8 / 12 幀的潛在空間 → 告訴模型上一個片段是如何結束的。填充(Padding): 對齊輸入形狀,確保 DiT 看到一個整潔的拼接序列:錨點 + 運動 + 填充。
錯誤回收微調(Error-Recycling Fine-Tuning)
使 SVI 在處理多個片段時依然穩定的關鍵在於其 LoRA 的訓練方式。標準推理總是從純高斯噪點開始去噪,但在長影片拼接中,早期片段的誤差會污染後續片段的條件設定。如果只在乾淨的參考輸入上訓練,就會固化訓練與推理之間的差距。
標準訓練: 每個片段的參考輸入都是乾淨的基準事實(ground truth)→ 模型從未見過推理時實際面臨的帶噪歷史上下文,導致不連續性累積。
錯誤回收: 在訓練過程中,刻意將模型自身過去的誤差注入參考輸入,使 LoRA 明確學習如何在帶噪的歷史上下文中運作。片段邊界的視覺不連續性顯著降低。
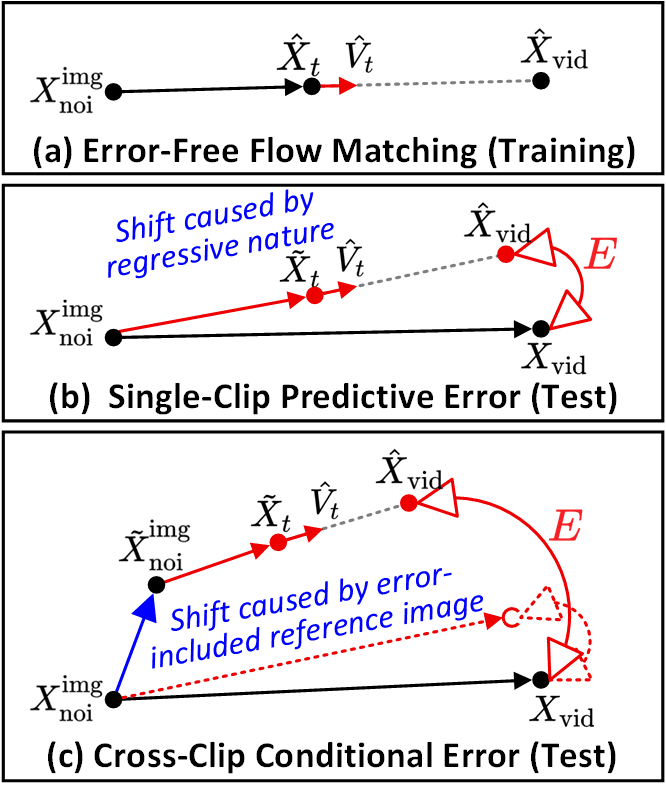
SVI 定義了兩種核心錯誤類型。(a) 無誤差流匹配(Error-Free Flow Matching)是訓練時的軌跡。(b) 單片段預測誤差(Single-Clip Predictive Error)——去噪路徑與理想軌跡之間的每片段偏差。(c) 跨片段條件誤差(Cross-Clip Conditional Error)——受誤差污染的參考影像導致片段間的連鎖偏移。錯誤回收明確注入了兩者。
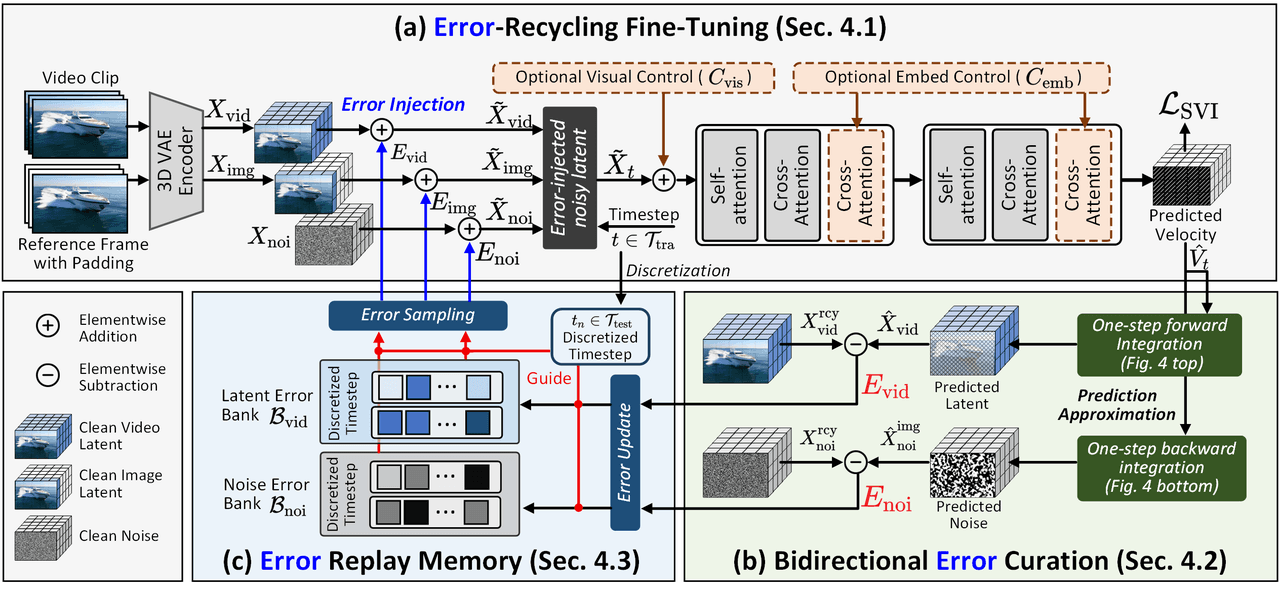
SVI 訓練框架。(a) 將 DiT 自生成的誤差注入潛在空間,打破無誤差假設。(b) 透過一步前向/後向積分高效計算雙向誤差。(c) 將誤差儲存在重放記憶體(Replay Memory)中並動態重採樣以供重複使用,形成閉環的誤差監督循環。
SVI 區分了兩類誤差。單片段預測誤差是指去噪路徑與理想軌跡之間的每片段偏差;跨片段條件誤差是指當受誤差污染的參考影像流入下一個片段時導致的連鎖偏差。錯誤回收同時注入這兩者,因此 LoRA 習得了明確的誤差容忍度。
LoRA 變體
SVI 發布了三個變體——SVI-Shot(靜態圖像 → 短片段)、SVI-Dance(人類動作,也可接受姿態序列輸入)以及 SVI-Film(多鏡頭/場景轉換長影片)。超參數:每片段 81 幀,
1num_motion_frames在 TurboWan 上堆疊
我們將 SVI 的 LoRA 掛載在 TurboWan(由 Atlas 優化的 Wan 加速版)之上,並在堆疊中保留了我們用於風格控制的專用 LoRA。在推理時,多個 LoRA 權重會同時疊加。
基礎: TurboWan。LoRA 1: 專用 LoRA — 內容/風格控制。LoRA 2: SVI LoRA — 長影片一致性。組合: TurboWan 速度 + SVI 長影片連續性 + Spicy 風格,全部在一次推理中完成。
完整的推理流程很直接:將參考影像編碼為錨點潛在空間,將其與上一個片段的運動潛在空間和填充進行拼接,執行 TurboWan 去噪、解碼、附加,並從新生成片段的尾部更新運動潛在空間。經過 N 次迭代後,將所有內容拼接成一段影片。
1. 編碼參考影像 → 錨點潛在空間。 2. y = concat(錨點潛在空間, 運動潛在空間, 填充)。 3. 在 y 和文本嵌入(text embedding)條件下執行 TurboWan 5 步去噪。 4. VAE 解碼片段並附加到輸出列表。 5. 設定運動潛在空間 = 剛生成片段的尾部(最後 num_motion_frames 幀)。 6. 重複 N 次,然後將所有片段拼接。
部分生產數據
標準測試:使用單一參考影像和 3 個提示詞,生成約 15 秒的輸出(3 個片段 × 5 秒):
| 指標 | 數值 |
|---|---|
| 生成時長 | 15s (3 個片段) |
| 單片段推理時間 | ~14s (TurboWan fp8, 單 GPU) |
| 總推理時間 | ~42s |
| 主體一致性 | 良好 |
實際案例:貓咪大冒險
為了具體呈現跨片段的表現,我們運行了一個 15 秒的案例,包含一個參考影像和三個鏡頭。風格提示詞固定為 Pixar 風格配以暖色調燈光;角色是一隻有著好奇大眼睛的橘色虎斑貓;三個鏡頭分別展示了從窗台到人行道,再到遇見一隻黃金獵犬的過程,每個鏡頭都有各自的鏡頭運動。

片段 1 (0–5s):窗台上的橘色 Pixar 小貓,鏡頭從特寫緩慢拉遠。風格和角色在各幀之間保持穩定。

片段 2 (5–10s) 轉場邊界處:小貓外觀與片段 1 一致,隨後在跳下時轉身並改變姿勢。運動潛在空間成功將運動狀態跨越邊界傳遞過來。

片段 3 (10–15s):引入了一隻黃金獵犬,場景過渡到室內/室外邊界。小貓的 Pixar 風格在所有三個片段中保持穩定。
運行匯總指標:
| 指標 | 數值 |
|---|---|
| 總時長 | 15s (3 片段 × 5s) |
| 總幀數 | 240 幀 (16fps) |
| 總推理時間 | 33s (TurboWan, 單 GPU) |
| 影片生成速度比 | 2.2 s/s |
| 主體一致性 | Pixar 橘貓全程穩定 |
| 片段邊界不連續性 | 無明顯跳剪 |
這是在單張 GPU 上於 33 秒內生成的 15 秒長影片,具備跨片段的主體一致性——完全在我們設定的 ≤ 60 秒等待目標內。在 14 個案例的內部測試集上,有 9 個案例沒有出現明顯問題(通過率 64%)。
最後誠實地總結:在影片生成領域,速度、長度和質量是「不可能三角」的三個角。目前沒有任何單一方法能同時領先這三者。有趣的工作在於,根據現有的硬體和訓練預算,選擇你可以最小化犧牲的那一個角。SVI 稍微犧牲了一點長度和邊界質量,作為回報,我們今天就能在單張 GPU 上實現具備 Wan2.2 級別保真度的長影片生成。






