
Kimi 剛剛發布了 K2.6——已在 HuggingFace 上開源,並與 GPT-5.4、Claude Opus 4.6 和 Gemini 3.1 Pro 進行了基準測試。它在 Humanity's Last Exam、DeepSearchQA 和 SWE-Bench Pro 上均優於這三者;代碼能力較 K2.5 提升近 20%,平均任務步驟減少了 35%,且針對 Agent 工作負載的定價僅為 Claude Opus 4.6 的 1/8。
如果你正在運行 AI Agent 並希望將 K2.6 接入現有的工具鏈,本指南涵蓋了四大主流框架——Claude Code、OpenCode、OpenClaw 和 Hermes Agent——透過 atlascloud.ai 提供統一的 API 端點。後半部分將展示 K2.6 在運行時的實際表現。
快速參考
| 工具 | 配置位置 | 切換模型方式 | 注意事項 |
|---|---|---|---|
| Claude Code | 環境變數 ANTHROPIC_* | 修改環境變數或使用 /model | 無 |
| OpenCode | ~/.config/opencode/config.json | 編輯 model 欄位 | 必須使用 @ai-sdk/openai-compatible |
| OpenClaw | ~/.openclaw/openclaw.json | 編輯 primary 欄位 | 需先啟動 gateway |
| Hermes Agent | 交互式 hermes setup | 重新執行 setup | 模型 ID 格式必須精確 |
本文所有教學均在 Windows 使用 WSL2 完成。
第一部分 — 設定
-
Claude Code (最簡單)
Claude Code 官方下載與文件:https://github.com/anthropics/claude-code
Claude Code 原生支援 Anthropic 格式。只需設定三個環境變數即可:
plaintext1# 新增至 ~/.bashrc 或 ~/.zshrc 2export ANTHROPIC_BASE_URL="https://api.atlascloud.ai" 3export ANTHROPIC_AUTH_TOKEN="apikey-xxx" 4export ANTHROPIC_MODEL="moonshot/kimi-k2.6" 5export ANTHROPIC_SMALL_FAST_MODEL="moonshot/kimi-k2.6"

執行 source ~/.bashrc 後,即可正常啟動 Claude Code。若要在會話中切換模型,請在介面輸入 /model。
2. OpenCode (設定檔)
OpenCode 官方下載與文件:https://github.com/anomalyco/opencode
OpenCode 內建了 openai 提供者,但它會自動移除模型 ID 中的 openai/ 前綴,這會導致第三方端點路由失敗。你需要使用 @ai-sdk/openai-compatible 宣告自定義提供者。
~/.config/opencode/config.json:
json
plaintext1{ 2 "$schema": "https://opencode.ai/config.json", 3 "provider": { 4 "atlascloud": { 5 "npm": "@ai-sdk/openai-compatible", 6 "name": "AtlasCloud", 7 "options": { 8 "baseURL": "https://api.atlascloud.ai/v1", 9 "apiKey": "apikey-xxx" 10 }, 11 "models": { 12 "moonshot/kimi-k2.6": { "name": "Kimi K2.6" } 13 } 14 } 15 }, 16 "model": "atlascloud/moonshot/kimi-k2.6" 17}
model 欄位遵循 providerName/modelKey 格式。要切換模型,請編輯最後一行。
3. OpenClaw (設定檔 + 兩個終端機)
OpenClaw 作為兩個獨立進程運行:gateway 和 TUI。使用前兩者皆須啟動。
~/.openclaw/openclaw.json:
json
plaintext1{ 2 "agents": { 3 "defaults": { 4 "model": { 5 "primary": "custom-api-atlascloud-ai/moonshot/kimi-k2.6" 6 } 7 } 8 }, 9 "models": { 10 "providers": { 11 "custom-api-atlascloud-ai": { 12 "baseUrl": "https://api.atlascloud.ai/v1", 13 "api": "openai-completions", 14 "apiKey": "apikey-xxx", 15 "models": [ 16 { 17 "id": "moonshot/kimi-k2.6", 18 "name": "Kimi K2.6", 19 "api": "openai-completions" 20 } 21 ] 22 } 23 } 24 } 25}
啟動順序:
bash
plaintext1# 終端機 1 2openclaw gateway 3 4# 終端機 2 5openclaw tui
若需交互式重配置:openclaw configure
要切換模型,請編輯 primary 欄位並重啟兩個進程。
4. Hermes Agent (交互式設定)
Hermes 使用嚮導而非設定檔:
bash
plaintext1hermes setup
填寫提示資訊:
- Provider: custom
- Endpoint: https://api.atlascloud.ai/v1
- API Key: apikey-xxx
- Model: moonshot/kimi-k2.6
重要: 模型 ID 必須包含 moonshot/ 前綴。單獨輸入 kimi-k2.6 會返回 404。
如需之後切換模型,請重新執行 hermes setup。
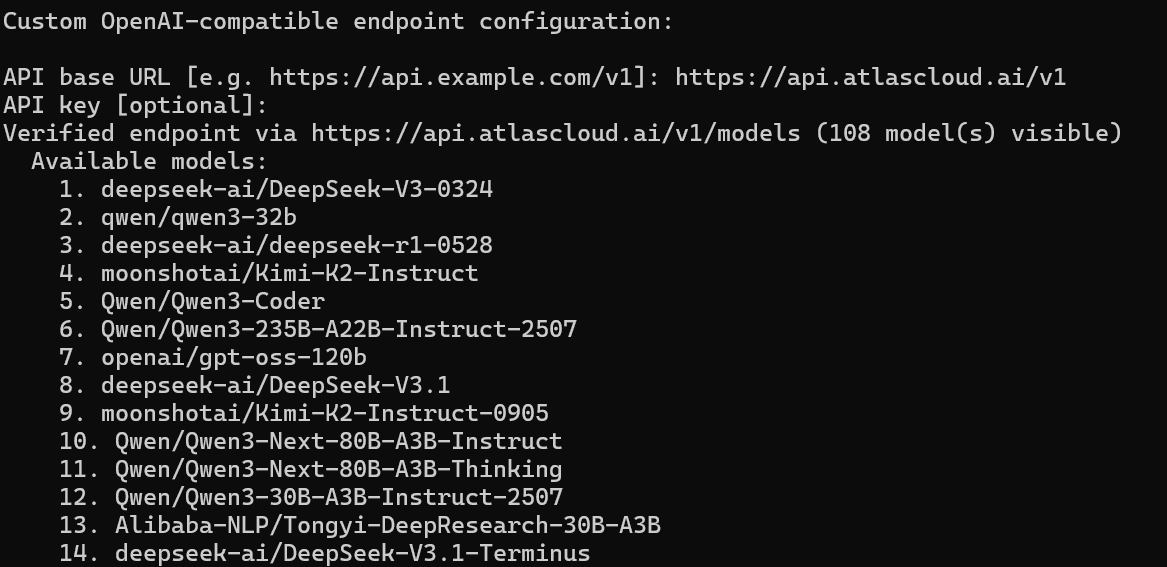
第二部分 — K2.6 的實際效能
Claude Code × K2.6 — 當 23 個 Agent 同時運行時會發生什麼?
當你將 AI 系統推向極限時,什麼會先崩潰?
一位開發者決定親自測試——透過 Claude Code 同時運行 23 個 Agent,並持續一整天。在 26 個會話中,系統處理了高頻工具調用、多步驟流水線以及編寫 PRD 和 SEO 規劃等長鏈任務。換句話說,這是一個非常真實的「生產級」工作負載,通常這類情況最容易出錯。
但這次,發生了意想不到的事。
沒有發生任何 429 速率限制錯誤。
對於任何嘗試過擴展 Agent 工作流的人來說,這點非常顯著。在類似條件下,像 GLM 5.1 這樣的模型往往會頻繁觸發速率限制,迫使重新嘗試、中斷流水線並導致系統不穩定。相比之下,K2.6 表現得非常穩健——它不是最快的,但在壓力下展現了持續的可靠性。
這種區別比聽起來更重要。
因為一旦你超越了單次 Prompt 進入多 Agent 系統,真正的挑戰不再是「模型回答得好不好?」,而是:
它能否在幾十個並行任務中持續表現出色,而不弄垮整個系統?
不僅是生成,更是結構化的規劃
差異不僅體現在穩定性,還體現在 K2.6 處理複雜任務的方式上。
當被要求編寫 PRD 時,模型不只是給出回覆,它還自主構建了問題空間。競爭對手分析、用戶故事、功能優先級——這些並未被明確要求,但模型彷彿知道一個「完整」的 PRD 應該具備什麼。
在 SEO 任務中行為也類似。K2.6 沒有直接給出關鍵字建議,而是先推斷了搜尋意圖,然後相應地調整內容方向。輸出的內容感覺不像是純粹的生成,更像是早期的戰略規劃。
這是一個微妙但重要的轉變:
你得到的不再只是答案,而是井然有序的思考。
在多 Agent 環境中,這種優勢會疊加。當每個 Agent 都產生結構化、高品質的輸出時,協調層需要進行的後續清理工作將大幅減少。
代價:穩定性是有成本的
然而,這種表現並非免費。
K2.6 明顯比 GLM 5.1 慢,特別是在首字延遲 (first-token latency) 方面。延遲不是邊緣性的,大約慢了一個數量級。在單次互動中這或許可以接受,但在一個有 23 個 Agent 並行運行的系統中,每一步都會引入小停頓,這些停頓加起來就很可觀。
部分原因來自於它的架構。K2.6 採用了 Mixture-of-Experts (MoE) 設計,總參數約 1 兆,每次推理激活 320 億。這種規模帶來了強大的能力,但也帶來了調度開銷。由於目前仍是預覽版本,推理優化尚未完全發揮。
因此,取捨很明確:
- 如果你重視吞吐量和速度,這很重要
- 如果你重視大規模下的穩定性和結構化輸出,那麼這很值得
OpenCode × K2.6 — 從一個 Prompt 到九個並行工作流
如果 Claude Code 實驗展示了 K2.6 在壓力下的表現,那麼 OpenCode 則揭示了另一點:它如何組織工作。
K2.6 引入了一個稱為 AgentSwarm 的協調層,單個「協調員」Agent 可以生成數十個專門的子 Agent,每個子 Agent 被分配特定的角色。系統不會在單個執行緒中逐步處理任務,而是將其拆解並同時運行多個進程。
來看一個實例。
研究人員要求 K2.6 對 Dario Amodei 進行深度剖析,追蹤他從普林斯頓物理博士到創立 Anthropic 的歷程。K2.6 沒有將其作為單一的長篇生成任務處理,而是將其拆解為九個並行軌道。

每個軌道都有明確職責。一個 Agent 專注於研究,收集公開資訊;另一個處理排版,將材料格式化為結構化 PDF;另一個 Agent 建構關鍵決策點的數據集;同時,一個寫作 Agent 撰寫了一篇名為《親愛的 2008》的第一人稱敘事文。
這一切都是同時運行的。
最終產出的不僅是單一結果,而是一個協調好的成品套件:一份 80 頁的投影片、結構化數據和排版精美的文件。原本需要多種工具、多次會話和手動組裝的工作,現在一次性交付完成。
為什麼這改變了 AI 的使用方式
這裡的關鍵驅動力是 技能 (Skill) 系統。
K2.6 不將每個任務視為獨立的 Prompt,而是允許你載入結構化知識——例如高盛報告、競爭對手分析或完善的產品規格——並將其轉變為可重用的「技能」。當子 Agent 運行時,它會繼承該框架:分析風格、語氣,甚至結構。
隨著時間推移,這會讓你的系統與基於簡單 Prompt 的工作流完全不同。
它成為了一個可重複的生產流水線。
這也導致了對 AI 使用方式的轉變:
你不再是在引導模型,而是在管理一個團隊。
如果你正在建構基於 Agent 的工作流,這種差異不容忽視。
四種工具皆透過 https://api.atlascloud.ai/v1. 連線。模型 ID: moonshot/kimi-k2.6.
常見問題
-
使用 Hermes Agent 與直接呼叫 Kimi K2.6 API 有什麼區別?
核心區別在於執行 vs. 回應。
直接呼叫 Kimi K2.6 API 本質上是每次請求獲得單個回應。即使對於複雜任務,你仍需手動拆解、在多個 Prompt 間迭代並自行組合輸出。這對於簡單或交互式使用場景效果很好,但對於結構化工作流來說效率較低。
Hermes 透過引入工作流協調改變了這一點。你定義一個包含多個步驟(研究、規劃、執行等)的流水線,Hermes 將每個步驟分配給不同的 Agent。這些 Agent 可以相互傳遞結果、驗證中間輸出,甚至在出錯時重新執行步驟。
實際上,這意味著你從「提示工程 (Prompt Engineering)」轉向了任務編排。API 變成了系統內的一個組件,而不是系統本身。
-
Kimi K2.6 適合多 Agent 工作流和自動化嗎?
是的——這正是它表現極佳的地方。
在多 Agent 架構中,最大的挑戰通常是:
- 步驟間的一致性
- 長時間運行時的穩定性
- 執行結構化任務的能力
Kimi K2.6 在這三個方面都表現強勁。在 Hermes 中使用時,它能在多個階段保持結構化輸出,並處理複雜任務鏈,而不會破壞格式或失去方向。
另一個重要面向是自我修正。如果中間結果偏離目標,系統可以重新生成該步驟,而不是帶著錯誤數據繼續執行。這使得它非常適合那些你不希望手動監控每一步的自動化場景。
總體而言,它更像是一個可靠的執行層,而非簡單的文字生成器。
-
為什麼 Kimi K2.6 在 Agent 工作流中比其他模型慢?
速度較慢主要是因為它的使用方式,而不僅僅是模型本身。
在標準聊天場景中,你只等待一個回應。在 Agent 工作流中,單個任務可能涉及多個步驟——每一步都需要單獨的模型呼叫,以及 Agent 間的協調開銷。這自然會在每個階段引入延遲。
此外,Kimi K2.6 設計了更複雜的架構(例如 MoE 路由),與較小或經過特殊優化的模型相比,會增加推理開銷。當結合多 Agent 編排時,延遲感會更加明顯。
然而,取捨在於每一步都能產生更高品質、更結構化的輸出,減少了重試或手動修復的需求。因此,雖然原始回應時間較慢,但在整個工作流層面,它的效率可能更高。






