yxUS-H6oB1A
1. 起源:雙強模型碰撞
2026 年 4 月。
OpenAI 發布了 GPT Image 2 —— 在文字渲染、世界知識與美學呈現上皆推向了極限。
「從今天起,AI 生成的圖像就如同 AI 生成的文字一樣,正式進入了普通人再也無法分辨真偽的時代。」
與此同時,X (Twitter) 上出現了兩篇高流量的貼文:
@AI_Jasonyu:
GPT-Image 2 (beta) + Seedance 2.0 —— 這兩者組合簡直是絕配。工作流程很簡單:先用 GPT-Image 2 產出分鏡腳本;確認後,交給 Seedance 2.0 製作長篇影片。這才是 AI 影片該有的樣子。
@arrakis_ai:
Codex + GPT Image 2 的管線流程簡直強到犯規。這是我今年看過最具顛覆性的 AI 工作流。我丟進去一行手稿——「把它轉換成漫畫」——出來就是一本完整成形的漫畫書。
兩篇貼文都指向同一個核心:最強的影像模型 + 最強的影片模型,串聯成一個完整管線。
問題在於:過去要執行這個流程,你需要 GPT Image 2 的額度、ByteDance Seedance 2.0 的存取權,以及處理兩端提示詞(Prompt)、輪詢(Polling)和 CDN 管理的自定義膠水代碼。
現在,不需要了。
2. Atlas Cloud 現已支援 GPT Image 2:一鍵打通兩端
Atlas Cloud 剛在其模型陣容中加入了 GPT Image 2,與完整的 Seedance 2.0 系列(文字轉影片 / 圖片轉影片 / 參考圖轉影片 / 極速版 / 超解析度)並列。
| 過去 | 現在 |
|---|---|
| 申請 OpenAI 額度 + 分別整合 Seedance | 一個 Atlas Cloud API Key |
| 兩套 SDK、兩套帳單系統、兩份文件 | 統一端點:https://api.atlascloud.ai/api/v1 |
| 自建輪詢 / CDN / 錯誤處理 | 官方 SDK / MCP / 技能模板現成可用 |
實際上只有兩個端點:
生成圖像 (GPT Image 2 / Seedream / Qwen Image ...)
生成影片 (Seedance 2.0 / Kling / Vidu ...)
共用輪詢端點
GET https://api.atlascloud.ai/api/v1/model/prediction/{id}
使用 Bearer token 驗證。執行 export ATLASCLOUD_API_KEY=... 即可開始。
合規說明:本教學中的每一個角色皆由 GPT Image 2 渲染為超寫實數位角色。不涉及任何真人肖像或影射。
3. 最強影像模型 GPT Image 2 + 最強影片模型 Seedance 2.0
市面上大多數 AI 影片教學採用以下兩種路徑之一:
路徑 A:純文字轉影片 (直接 Prompt → 15秒影片)
- 問題:單次生成如賭博,重試成本高。
路徑 B:多片段拼接 (6–12 個片段 × 每個 5 秒,拼湊起來)
- 問題:速度慢(6 次圖生成 + 6 次影片生成)、昂貴、角色一致性極易崩壞。
drama-director 採用了第三種路徑:
路徑 C:一張 9 宮格漫畫頁 + 一段 15 秒動畫影片
- GPT Image 2 生成一張 3×3 的九宮格頁面(9 個分鏡畫面繪製在同一張圖上,就像漫畫書頁)。
- Seedance 2.0 I2V 接收該圖片 + 動作 Prompt,一次呼叫產出 15 秒影片 —— Seedance 將這張九宮格圖片視為其視覺 DNA 與分鏡參考(角色、服裝、場景、光影、配色全數從圖像中鎖定),並輸出該場景的** 15 秒電影級鏡頭** —— 你看到的將是納米絲被拉緊、郵輪駛入、金屬板切開、水柱噴湧,而不是「鏡頭在漫畫書上平移」。
這種組合的三大優勢:
| 維度 | 九宮格路徑 | 6-8 段拼接路徑 |
|---|---|---|
| 成本 | 1 次圖生成 + 1 次影片生成 | 6-8 次圖生成 + 6-8 次影片生成 |
| 時間 | ~3-5 分鐘 | ~8-15 分鐘 |
| 角色一致性 | 9 個畫面皆在同一畫布上,模型自然保證一致 | 每個鏡頭獨立生成,需額外掛鉤參考圖 |
| 迭代成本 | 微調 image_prompt,重生成一張圖 | 修改一個鏡頭會引發整條管線變更 |
| 交付物 | 一段完整的漫畫劇影片,直接發布 | 需要後期剪輯拼接 |
第 3 點——角色一致性——是串聯工作流中最痛苦的痛點。九宮格頁面本質上是「同畫布下的 9 個區域」,因此 GPT Image 2 自然能確保同一個角色在 9 個分鏡中樣貌、服裝完全一致。這項設計決策省去了大量的後端工程。
4. drama-director:一句指令,打通全流程
你要做的事
在 Claude Code 中,你只需要:
將這段小說情節轉化為漫畫劇: <貼上段落>
Claude 會識別觸發詞(「漫畫劇」、「分鏡」、「九宮格」等),載入 drama-director 技能,然後:
- 閱讀素材 → 提煉為 9 個關鍵點(3×3 閱讀順序)
- 構建完整的
image_prompt(分鏡描述 + 風格限制)並展示給你預覽 - 一次呼叫 GPT Image 2 → 九宮格漫畫頁(
.json含image_url) - 展示九宮格圖;你確認後,一次呼叫 Seedance 2.0 I2V → 15 秒動畫漫畫(
.json含video_url) - 輸出 Markdown 報告
從頭到尾你只需輸入兩次訊息:腳本內容,以及「確認」。
底層模型
| 階段 | 模型 ID (預設) | 備註 |
|---|---|---|
| 九宮格頁面 | openai/gpt-image-2/text-to-image | 若 GPT Image 2 尚未完全公開則退回 1.5 |
| 動畫影片 | bytedance/seedance-2.0/image-to-video | 15s / 720p / 1:1,可配置 |
| 極速版 | bytedance/seedance-2.0-fast/image-to-video | 更便宜、更快 |
5. 3 分鐘快速安裝
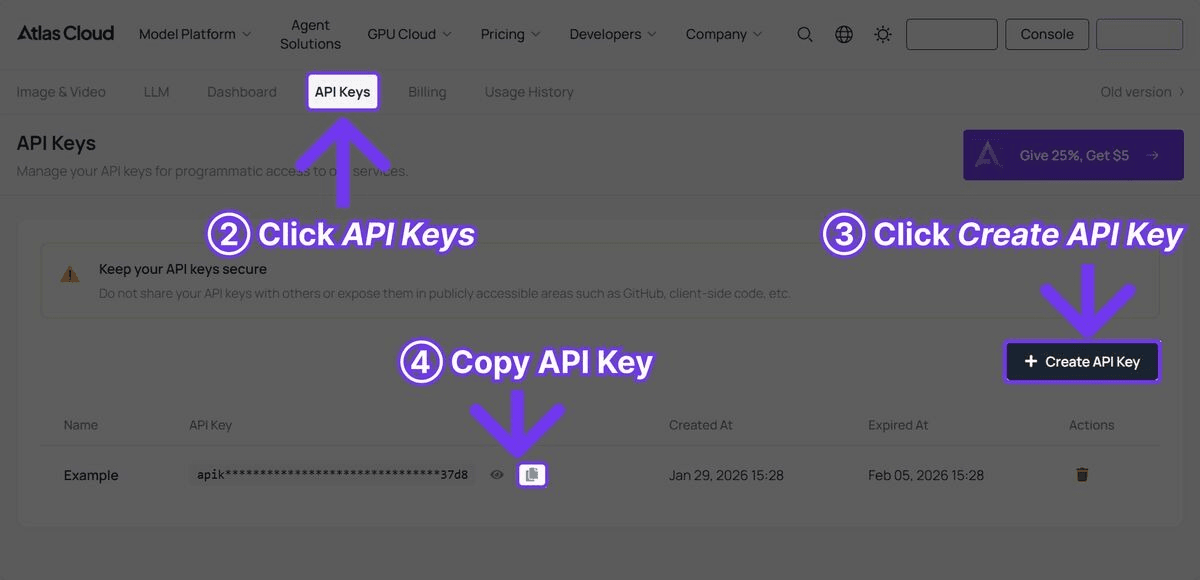
步驟 1 — 取得 API Key
註冊 atlascloud.ai 並從 API Keys 頁面生成密鑰。
export ATLASCLOUD_API_KEY="sk-your-key" echo 'export ATLASCLOUD_API_KEY="sk-your-key"' >> ~/.zshrc
步驟 2 — 安裝 drama-director 技能
將其從 GitHub 克隆到 Claude 的技能目錄:
mkdir -p ~/.claude/skills git clone https://github.com/kianaliang-dev/drama-director-skill ~/.claude/skills/drama-director
驗證:
ls ~/.claude/skills/drama-director/ # 預期:SKILL.md scripts/
此技能完全獨立——
SKILL.md內建了場景原型路由(衝擊 / 對決 / 追逐 / 旅程 / 氛圍 / 揭露 / 對峙等)、Seedance 引擎限制與雙對比剪輯規則。無需額外安裝技能。
步驟 3 — 腳本冒煙測試
python3 ~/.claude/skills/drama-director/scripts/generate_image.py \ --prompt "a cinematic 3x3 comic book page with 9 panels showing a cyberpunk chase scene, bold black gutters, film noir palette" \ --aspect 1:1
約 30 秒後,你應看到一個包含 image_url 的 JSON 區塊。在瀏覽器開啟 URL,如果看到九宮格漫畫頁,說明整個管線運作正常。
6. 演示:《三體》古箏行動 → 15 秒漫畫劇
為何選擇此場景
劉慈欣小說中最具視覺衝擊力的橋段之一——貨輪被納米絲切開。充滿密集的電影化動作,正好 9 個關鍵點:
巴拿馬運河,深夜。50 根直徑不到人類頭髮十分之一的納米絲,像琴弦一樣橫跨水面。
貨輪「審判日號」駛近。船頭接觸納米絲。船體繼續前進——被切成了 45 層橫截面。
切片錯位,層疊倒塌。巨大的金屬板像撲克牌一樣墜入運河,激起數層樓高的水柱。
岸上所有人屏住呼吸。這是人類歷史上首次用此手段湮滅巨輪。
對話流程
你貼入 Claude Code:
將這段三體情節轉為漫畫劇 (9 宮格 + 15s 影片): 巴拿馬運河,深夜。50 根納米絲橫跨水面... (貼上全文)
Claude 的動作:
- 識別觸發詞,載入
drama-director技能。 - 將文章拆解為 9 個關鍵點(佈線 → 船隻接近 → 初次接觸 → 開始錯位 → 完全切開 → 倒塌 → 金屬墜落 → 廣角殘局 → 岸上觀察者)。
- 展示
image_prompt供你審閱:
(略:與原文描述一致的詳細 Prompt)
你回覆「確認」。
- 執行
generate_image.py→ 約 1 分鐘回傳 9 宮格圖。Claude 發送image_url。 - 你回覆「OK, continue」。
- 根據內建的場景原型路由,Claude 選擇「衝擊」(Impact)模式,套用 Seedance 引擎限制與動作 Prompt:
(略:與原文描述一致的動作 Prompt)
關鍵概念:Seedance I2V 將九宮格圖片視為視覺 DNA,然後依據動作 Prompt 生成真實場景的電影鏡頭。這就是為什麼
drama-director內建完整的 Seedance 提示規範——場景原型路由、引擎限制、三段式結構(風格與心情 → 動態 → 靜態)——一個自帶規則集的安裝包。
- 2-3 分鐘後影片就緒。提供
video_url與/tmp/drama_output/report.md。
成本預估
| 項目 | 呼叫次數 | 預估價格 |
|---|---|---|
| GPT Image 2 9宮格 (1:1) | 1 | 依 Atlas Cloud 現行定價 |
| Seedance 2.0 I2V (15s) | 1 | 約 $0.101/秒 × 15s ≈ $1.5 |
| 總計 | 每集約 $1.5-2 |
相比單次 T2V 賭博或 6-8 段拼接,成本降低了 1/5 – 1/8。
7. 常見變體
| 需求 | 只需補充指令 |
|---|---|
| 切換動漫風格 | "Use Japanese anime style, Studio Ghibli palette" |
| 美式漫畫感 | "Use American superhero comic style" |
| Netflix 電影質感 | "Use photorealistic cinematic Netflix style, 16:9, 8K" |
| TikTok 直式 | "Use 9:16 nine-panel layout" |
| 1080p 輸出 | "Render video at 1080p" |
| 節省成本 | "Use seedance-2.0-fast" |
| 指定角色長相 | "Main character looks like this: [URL], reference this look" |
8. Atlas Cloud 官方 MCP + 技能倉庫 (開發者用)
若你想自建管線或在 Claude Desktop 使用工具,請參考:
官方技能庫
npx skills add AtlasCloudAI/atlas-cloud-skills
Repo: https://github.com/AtlasCloudAI/atlas-cloud-skills
官方 MCP Server (9 大工具)
claude mcp add atlascloud -- npx -y atlascloud-mcp
安裝後,這些 MCP 工具即可在 Claude Desktop 中使用。
9. 設計決策
1. 為何是 9 宮格? 3×3 平衡了閱讀與訊息密度——讀者一眼可見,9 個點足以承載完整戲劇弧線。
2. 為何一張圖 + 一段影片就夠了? 因為 Seedance 2.0 I2V 的動態生成能力極強,將漫畫視覺 DNA 轉換為真實影像,無需人類進行分鏡拼接。
3. 為何動作 Prompt 不描述「平移漫畫」,而是「場景動作」? 因為 Seedance 的任務是根據圖像 DNA 來演繹真實事件(如:金屬崩解、水流爆發),而不僅僅是處理圖片。
10. 常見問題 (FAQ)
- API 費用?:採按量付費。15 秒成片約 $1.5-2 美元。
- 角色不一致?:加強 Prompt,使用「同一角色、同一服裝」等明確描述。
- 影片像靜止圖?:增強動作 Prompt 的動態描述,如「camera dolly-in, diagonal sweep」。
11. 下一步
安裝完技能後,試試這些情節:
- 經典科幻場景:「水滴」、「二向箔」。
- 網路小說高潮:任何奇幻或懸疑小說的對決。
- 新聞視覺化:將突發新聞分解為 9 宮格漫畫劇。
想擴充技能(加入語音、字幕、B-roll)?直接編輯 ~/.claude/skills/drama-director/SKILL.md 即可,它是純 Markdown + Python,修改起來非常簡單。






