Wan 2.6 对决 Veo 3.1:Wan 2.6 是我们未曾预料到的"Veo 杀手"吗?
紧跟 AI 视频模型的发展就像一份全职工作。刚掌握了一个,又有两个新的发布了。
今天,我们来拨开迷雾。我们将迎来 Wan 2.6(阿里巴巴的商业巨头)与 Veo 3.1(谷歌对控制近乎偏执的更新)的对决。
您是在寻找电影般的流畅度,还是只想一个能遵循您的指令而不会生成多余手指的 AI?让我们来详细分析一下,这样您就可以停止滚动,开始渲染了。
简而言之:快速对比(规格与价格概览)
Wan 2.6 vs Veo 3.1 一览
| Wan 2.6 | Veo 3.1 | |
|---|---|---|
| 价格 | Atlas Cloud 上每秒 $0.08 | Atlas Cloud 上每秒 $1.12 |
| 核心侧重 | 角色控制与故事创作 | 提示词遵循与艺术细节 |
| 通常时长 | 5 秒;10 秒;15 秒 | 4 秒;6 秒;8 秒 |
| 输入类型 | 文本生成视频;图像生成视频;视频参考 | 文本生成视频;图像生成视频;图像参考 |
| 尺寸 | 文本生成视频和视频参考:720_1280;1280_720;960_960;1088_832;832_1088;1920_1080;1080_1920;1440_1440;1632_1248;1248_1632;图像生成视频:根据参考图像的尺寸。 | 文本生成视频和图像生成视频:宽高比:16:9,9:16 |
| 分辨率 | 图像生成视频:720P,1080P | 文本生成视频和图像生成视频:720P,1080P |
| 优势 | 多镜头叙事,面部稳定性,电影摄影路径 | 纹理,清晰对话的唇部运动 |
| 音频 | 叙事与对话 | 沉浸式背景声景 |
| 最适合 | 角色动画,快速构思 | 概念可视化,社交媒体内容 |
| 语义外推 | 擅长电影场景 | 一般 |
| 镜头构图 | 智能提示词执行 | 一般 |
| 一致性 | 角色一致性 | 一般 |
Wan 2.6 概览
阿里巴巴云的 Wan 2.6 拥有开创性的多模态能力和原生的音频同步功能。这个最新的 Wan 2.6 更新为创作者提供了先进的文本到视频和图像到视频工具,可生成长达 15 秒的 1080p 电影级内容。
核心要点:
- 智能分镜(多镜头叙事)
理解镜头边界,并在特写、中景和远景镜头中保持相同的角色身份。非常适合广告和故事板,其中主角必须保持一致。
- 15 秒高保真片段
将典型的视频时长推至约 15 秒。足以讲述一个完整的叙事环节——铺垫 → 行动 → 反响——在单次生成中完成,完美契合 6-15 秒的广告时段和社交媒体吸引点。
- 高保真音频与稳定的多角色对话
在原生音频生成方面的一大飞跃。Wan 2.6 提供超逼真的声音音色,并支持稳定的多人对话。它能在多个角色之间创建同步、自然的对话,消除了 AI 音频中常见的机器人音调。
- 高级视频参考(参考指导表演)
您可以上传一段排练视频(手机录制),Wan 2.6 会将时序、走位和肢体语言克隆到一个生成的角色上。这使得导演能够在无需重拍的情况下获得演员级别的控制力。
总而言之,Wan 2.6 感觉像是一个为导演量身定制的综合叙事引擎,它将智能化的多镜头视觉效果与高保真的对话相结合,能够提供完整、15 秒的电影级故事情节。
Veo 3.1 概览
Veo 3.1 是一款视频生成模型,旨在提供增强的输出质量和更快的处理速度。它通过三个主要技术进步来改进内容创作:
- 视觉保真度: 该模型生成的视频细节更清晰,纹理更鲜明。它以更高的饱和度渲染颜色,以创建逼真的图像。
- 控制与稳定性: 用户可以精确地控制镜头运动和物体轨迹。该系统保持时间连贯性,确保所有帧中的运动平滑且一致。
- 音频同步: 该模型能合成清晰的对话和环境声音,与视觉线索同步。它能将唇部动作与语音匹配,并生成上下文相关的音效。
Veo 3.1 作为一个专业工具,在生成具有原生同步音频的稳定、高分辨率视频方面表现出色。
核心区别
时长与格式
- Wan 2.6 生成的视频最长可达 15 秒。它提供多种宽高比选项以适应不同平台。
- Veo 3.1 将输出限制在最多 8 秒。此时长限制了在单个剪辑中讲述复杂故事的能力。
内容或制作流程
- Wan 2.6 非常适合特定产品广告。它能自主处理创意任务,例如安排对话和确定镜头构图。
- Veo 3.1 侧重于商业概念的可视化。当遵循严格的脚本以产生专业结果时,它的表现最佳。
结论
Wan 2.6 优先考虑创意自由和更长的格式,适用于需要叙事发展的内容。Veo 3.1 则专注于精度和稳定性,以执行严格控制的高保真场景。
用例:何时/选择 Wan 2.6 或 Veo 3.1
(相同提示词,不同输出)
一个有用的决策方法是想象用相同的创意简报运行两个模型,并比较输出。
示例 1:奇幻电影场景
plaintext1提示词: 2镜头 1:大雨倾盆,一座古老破败的日式庭院,落叶和苔藓丛生,一个身穿破旧盔甲的孤独武士背对着镜头站立,慢慢拔出他的武士刀,刀刃反射着闪电的光芒,有氛围感的雾气,电影感广角镜头,黑泽明电影美学 3镜头 2:武士饱经风霜的面部特写,雨水顺着深深的皱纹流下,眼神锐利而坚定,浅景深,水滴凝固在空中,戏剧性的侧光,肖像构图 4镜头 3:镜头平滑地向下倾斜,露出他的敌人:一个被野草和高草完全覆盖的花园,武士叹了口气,挥刀砍断杂草,擦去额头上的汗水,背景是普通的郊区后院,喜剧性的反高潮,打破了史诗般的幻觉 5--ar 16:9 6--style cinematic 7--quality 4K 8--fps 24
- Wan 2.6 (点击查看输出视频)
- Veo 3.1(点击查看输出视频)
- 哪个更好?
- 镜头构图能力:Wan 2.6
- 角色一致性:Wan 2.6
- 提示词遵循能力:Veo 3.1
- 背景声景:Veo 3.1
示例 2:短产品广告
plaintext1提示词:一位男子在推广此 AI 伴侣玩具(参考图)。

示例 3:动漫风格
提示词:
"高质量动漫风格。一个穿着色彩鲜艳花朵图案浴衣的女孩,站在夜晚传统的神社台阶上。她回头看向镜头,露出温柔的微笑。巨大的、充满活力的烟花在她身后漆黑的天空中绽放,照亮了她的轮廓。悬挂的纸灯笼散发出柔和的光芒。萤火虫,魔法般的氛围。"
- Wan 2.6 (点击查看输出视频)
- Veo 3.1 (点击查看输出视频)
- 哪个更好?
- 镜头构图能力:Wan 2.6
- 叙事与对话:Wan 2.6
- 提示词遵循能力:Veo 3.1
- 背景声景:Veo 3.1
- 细节:Veo 3.1
结论:选择 Wan 2.6 还是 Veo 3.1?
更好的方法:在 Atlas Cloud 上同时使用两个模型
Atlas Cloud 不仅限于"Wan 2.6 对决 Veo 3.1",它允许您并排使用两个模型——首先在 Playground 中,然后通过统一的 API。
方法 1:直接在 Atlas Cloud 平台使用
| Wan 2.6 系列 | Veo 3.1 系列 |
|---|---|
| Wan 2.6 文本生成视频 | Veo 3.1 文本生成视频 |
| Wan 2.6 图像生成视频 | Veo 3.1 图像生成视频 |
| Wan 2.6 参考视频 | Veo 3.1 参考图像 |
方法 2:通过 API 访问
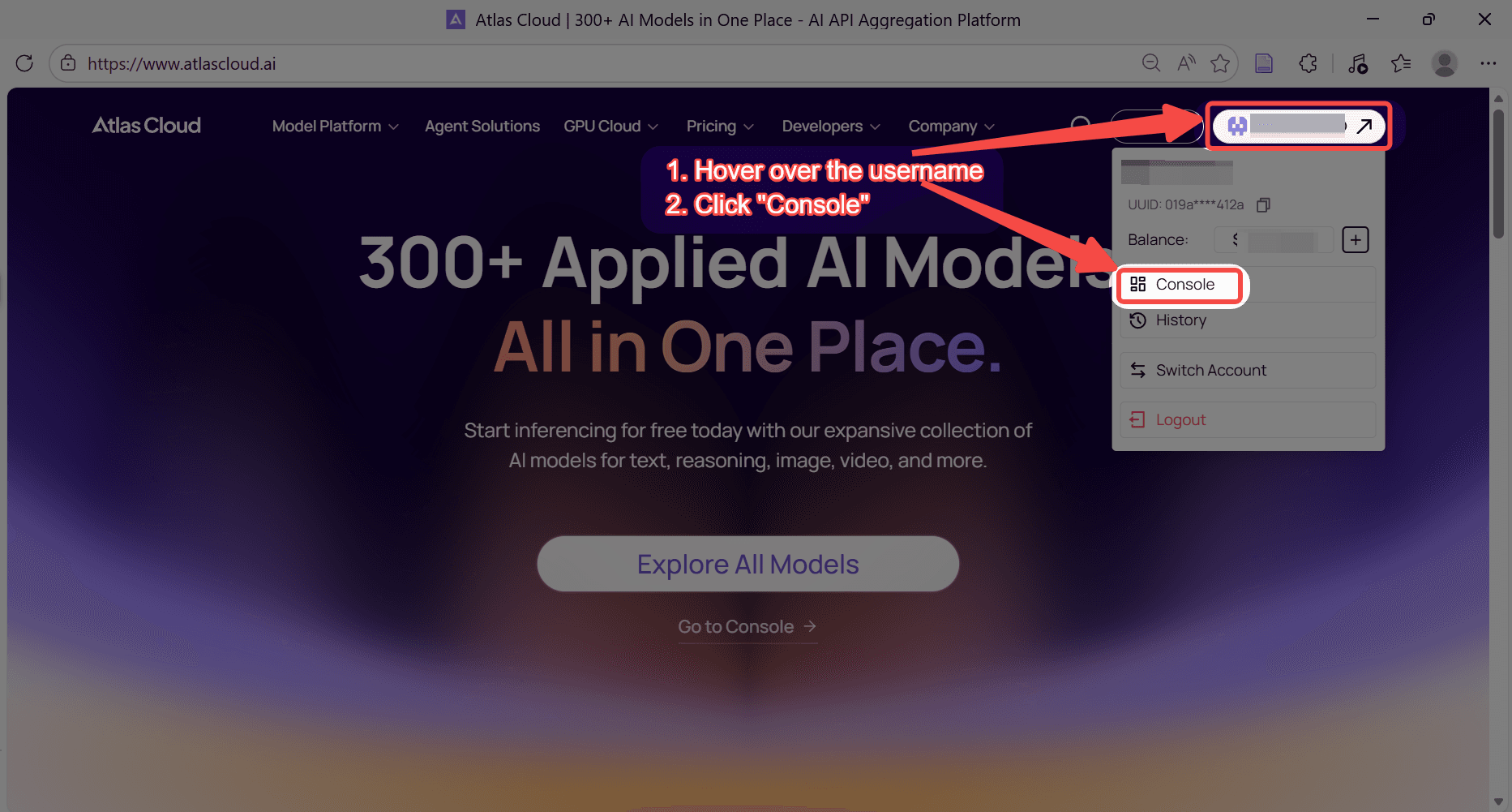
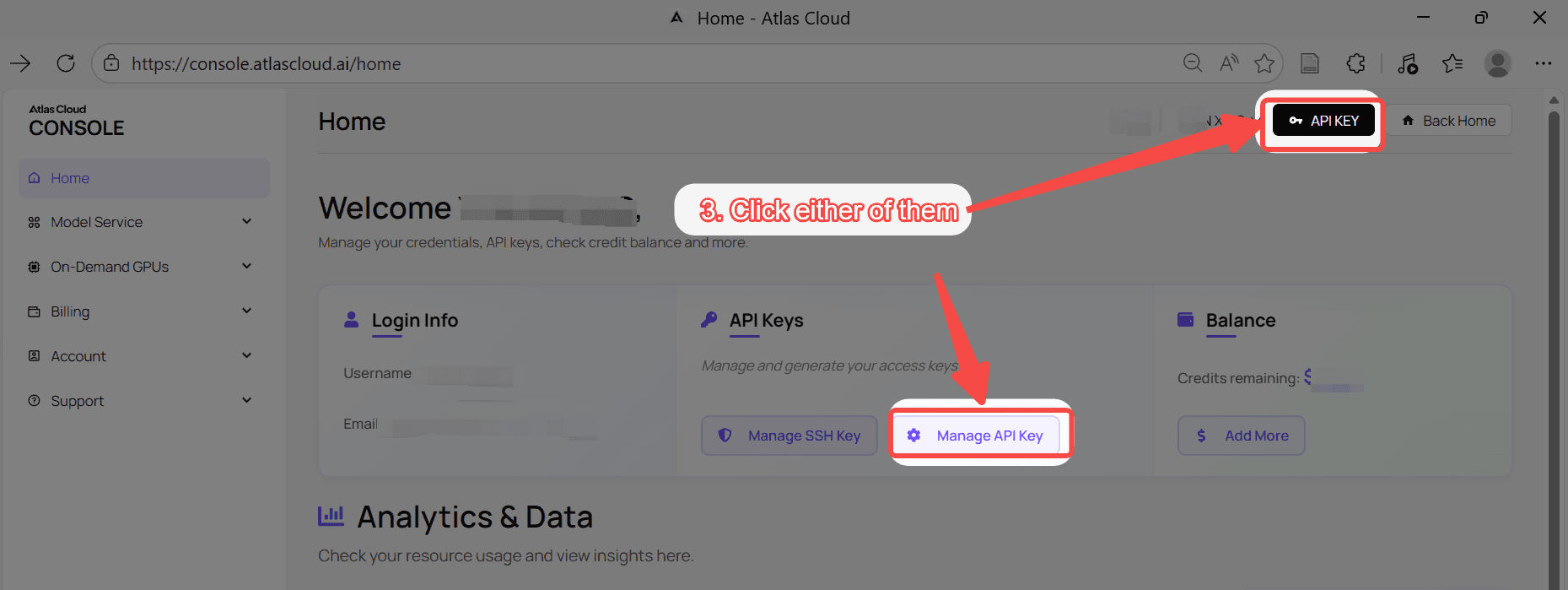
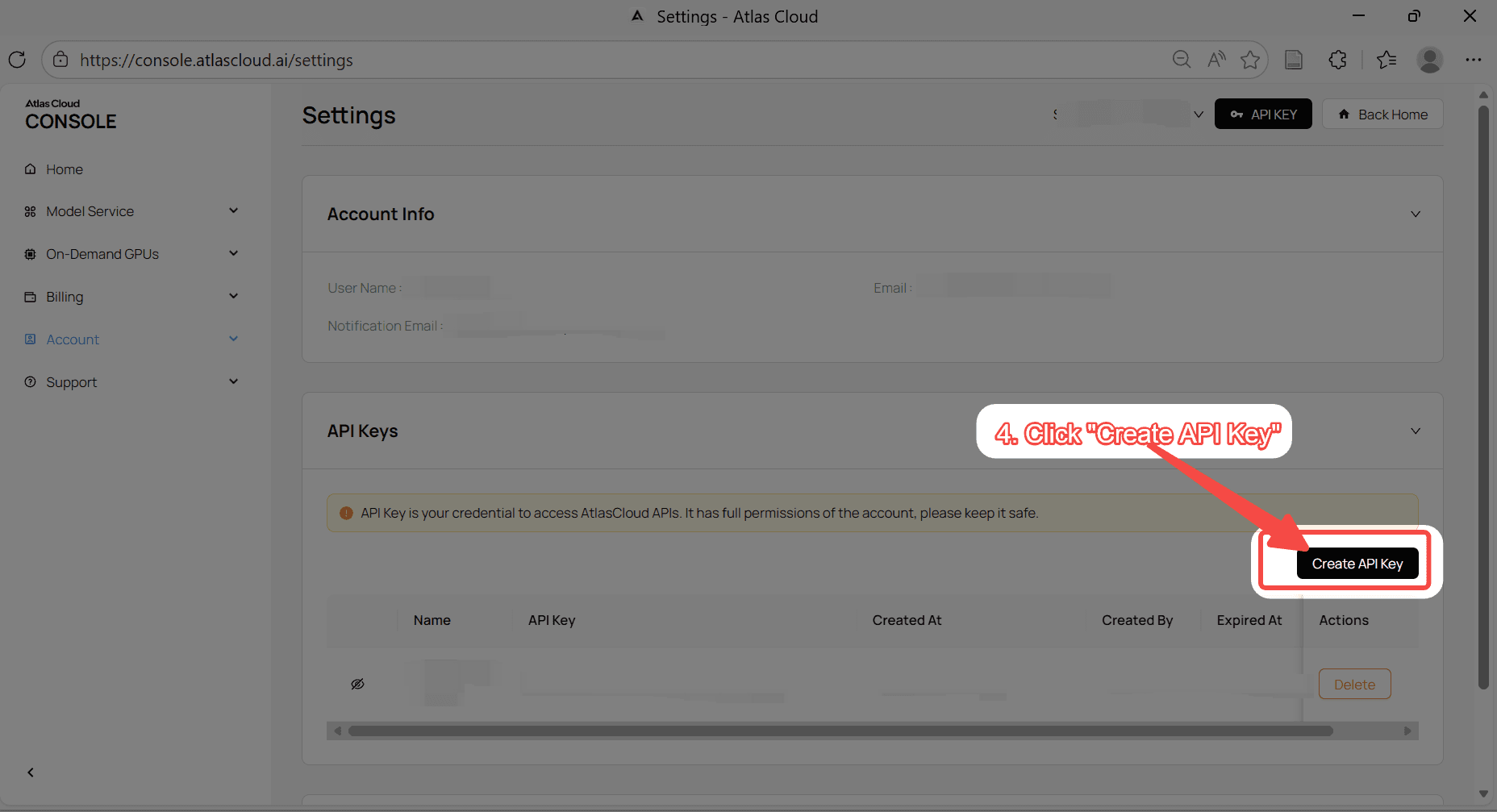
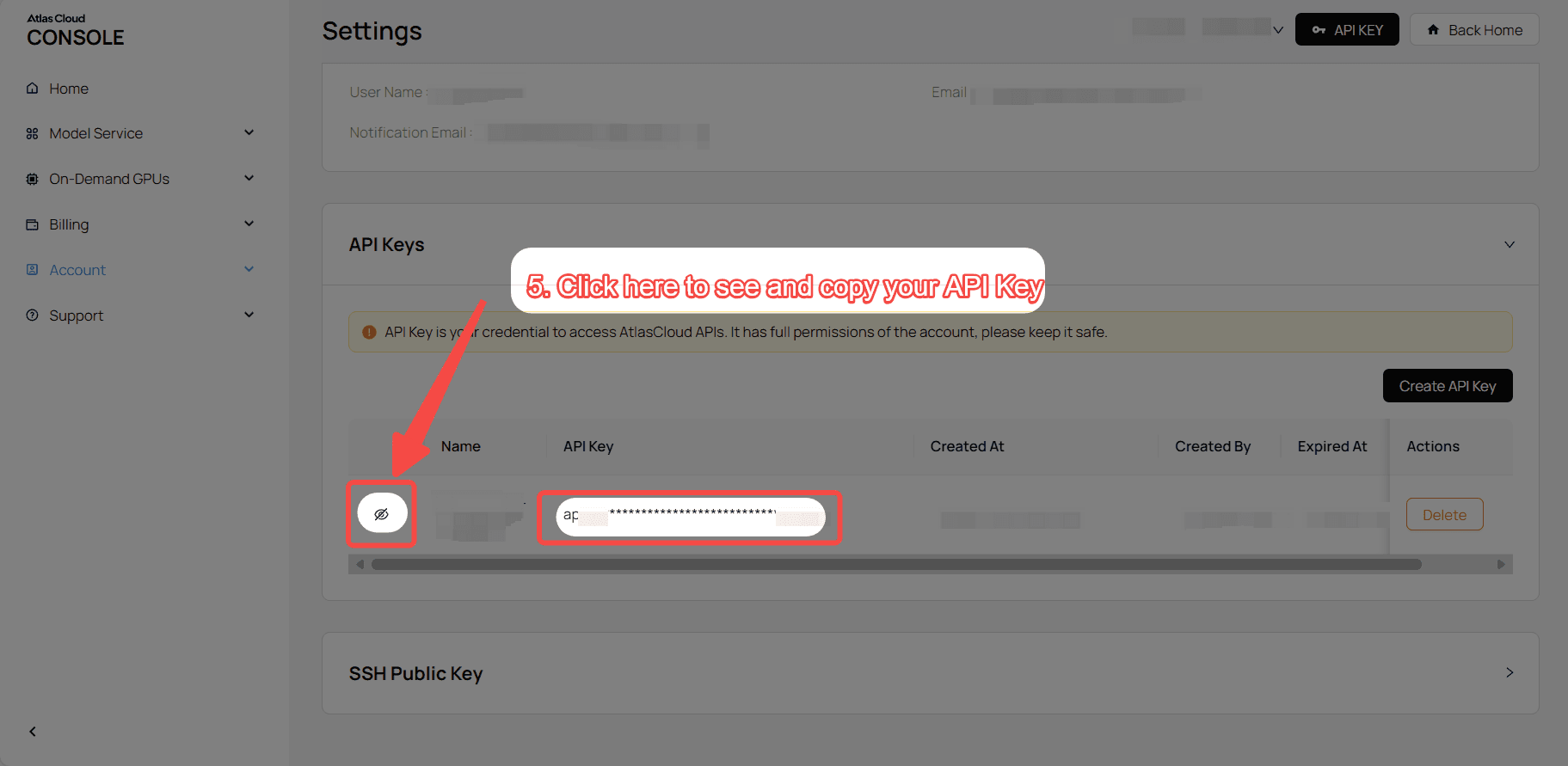
步骤 1:获取您的 API 密钥
在您的 控制台 中创建 API 密钥并复制以备后用。
步骤 2:查看 API 文档
在我们的 API 文档 中查看端点、请求参数和身份验证方法。
步骤 3:进行第一次请求(Python 示例)
示例:使用 Wan 2.6(文本生成视频)生成视频。
plaintext1import requests 2import time 3 4# Step 1: Start video generation 5generate_url = "https://api.atlascloud.ai/api/v1/model/generateVideo" 6headers = { 7 "Content-Type": "application/json", 8 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 9} 10data = { 11 "model": "alibaba/wan-2.6/text-to-video", 12 "audio": None, 13 "duration": 15, 14 "enable_prompt_expansion": True, 15 "negative_prompt": "example_value", 16 "prompt": "A cinematic sci-fi trailer. Shot 1: Wide shot, a lonely explorer in a battered spacesuit walking across a desolate red Martian desert, a massive derelict spaceship in the distance. Shot 2: Close-up, the explorer stops and wipes dust off their helmet visor, eyes widening in shock. Shot 3: Over-the-shoulder shot, revealing a glowing, bioluminescent blue flower blooming rapidly in front of them. 8k resolution, highly detailed, consistent character.", 17 "seed": -1, 18 "size": "1920*1080", 19 "shot_type": "multi" 20} 21 22generate_response = requests.post(generate_url, headers=headers, json=data) 23generate_result = generate_response.json() 24prediction_id = generate_result["data"]["id"] 25 26# Step 2: Poll for result 27poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 28 29def check_status(): 30 while True: 31 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 32 result = response.json() 33 34 if result["data"]["status"] in ["completed", "succeeded"]: 35 print("Generated video:", result["data"]["outputs"][0]) 36 return result["data"]["outputs"][0] 37 elif result["data"]["status"] == "failed": 38 raise Exception(result["data"]["error"] or "Generation failed") 39 else: 40 # Still processing, wait 2 seconds 41 time.sleep(2) 42 43video_url = check_status()
FAQ
哪个模型能生成更长的视频? Wan 2.6 可生成长达 15 秒的视频,足以完成完整的叙事弧。Veo 3.1 将输出限制在最多 8 秒。
音频功能有何不同? Wan 2.6 专注于稳定的多人对话和逼真的声音音色。Veo 3.1 则侧重于将环境声音、情境效果和精确的唇部动作与视觉线索同步。
哪个工具在角色一致性方面更好? Wan 2.6 具有智能分镜功能。这可以在单次生成中跨特写、中景和远景镜头保持角色身份。



