你的提示词触碰到了拒绝墙。这并非因为内容有害,而是因为触发了关键词过滤器。
Ollama 社区的开发者将此称为“拒绝向量”(refusal vectors):即与实际危害无关、纯粹由关键词触发的封锁。无论是用于安全研究的恶意软件逆向工程、医学案例研究文档、成人内容创作,还是暗黑小说写作,主流 AI 都会拦截这些内容。本列表根据真实的社区数据(而非营销文案)对 2026 年最佳无审查 AI 模型进行了排名。榜单涵盖了三个类别:用于文本和代码的无审查 LLM 模型、2026 年最适合私有硬件部署的无审查本地 AI 模型,以及通过 API 进行图像和视频生成的 2026 年无审查 AI 模型。文中所有数据均标注了日期,截至 2026 年 5 月。
对于初次接触该领域的读者,若想了解更广泛的工具环境,可以参考 无审查 AI 图像生成器指南,将其作为选择特定模型前的起点。
我们如何评估 2026 年最佳无审查 AI 模型
在 2026 年,Ollama 的社区下载量比基准测试分数更能提供可靠的排名依据,因为基准测试分数往往是为了公关稿而刻意挑选的,无法反映真实性能(Ollama,无审查模型搜索,2026)。数百万次的拉取代表了数以千计的硬件设置和提示词类型,这比精心策划的评估集更难被操控。
本文通篇使用三个排名指标。对于 Ollama 无审查模型,主要指标是来自 ollama.com 的拉取次数,数据提取于 2026 年 5 月。对于 OpenRouter 模型,由于平台未公开拉取次数,排名依据为参数规模和上下文窗口。对于图像和视频模型,排名依据为单次输出价格,同组内价格越低排名越靠前。
大多数 2026 年无审查 AI 模型属于两个技术类别:微调(fine-tuned)和剔除(abliterated)。像 Dolphin 系列这样的微调模型是在不强化拒绝行为的数据集上训练的;而剔除模型则是通过手术式移除其拒绝权重。社区一致认为,微调模型在处理各种提示词类型时表现得更为稳定。
实际上,下载量也与模型的稳定性相关。一个达到百万次以上拉取量的模型,已在广泛的硬件配置中经过测试,暴露并修复了小型测试组完全无法察觉的 bug 和不稳定性。
Ollama 下载量最高的前 5 款无审查模型是什么?
在 2026 年,下载量最高的五款 Ollama 无审查模型累计拉取次数已超过 920 万次,其中 llama2-uncensored 以 260 万次位居榜首(Ollama,无审查模型搜索,2026)。这些是经社区验证而非基准测试评出的 2026 年最佳无审查 Ollama 模型。硬件是大多数用户首先考虑的过滤条件:该类别的显存需求从 4GB 以下到 40GB 不等。
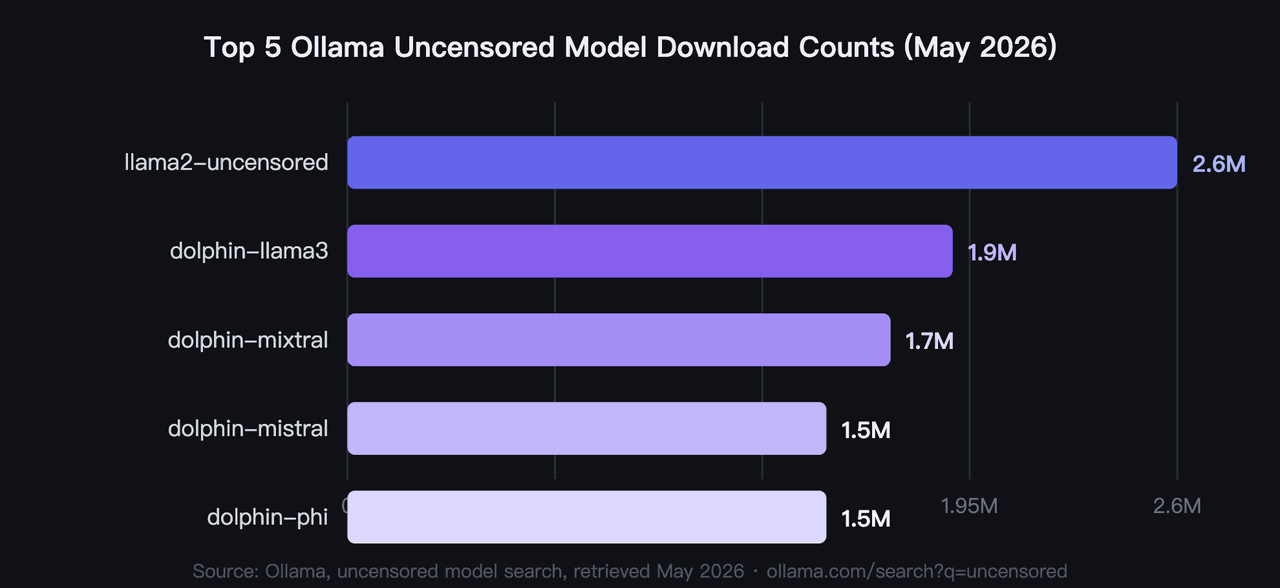
1. llama2-uncensored:Ollama 上下载量最高的无审查 AI 模型
无审查本地 AI 的原始社区标杆。George Sung 和 Jarrad Hope 发布了这个微调版本,在不降低通用能力的情况下移除了 Llama 2 的拒绝行为。它是大多数开发者的入门模型,其 260 万次的拉取量反映了两年多来的实际应用。目前还没有任何其他无审查 LLM 的下载量能与之比肩。
- 参数规模: 7B 或 70B
- 显存需求: ~6GB (7B);~40GB (70B)
- 适用场景: 通用无限制对话和内容生成
- 平台: Ollama
2. dolphin-llama3:最适合代理工作流的无审查 Llama 3 LLM 模型
基于 Llama 3 架构、由 Eric Hartford 开发的 Dolphin 是目前下载量最高的现代架构无审查模型,拉取次数达 190 万次(Ollama,dolphin-llama3 模型页面,2026)。它支持函数调用,上下文窗口根据配置可从 8K 扩展至 256K token。8B 版本大小为 4.7GB,适配大多数主流消费级 GPU。
- 参数规模: 8B 或 70B
- 显存需求: ~5GB (8B);~40GB (70B)
- 适用场景: 编程、代理(Agentic)工作流和函数调用
- 平台: Ollama
3. dolphin-mixtral 8x7B:用于复杂推理的无审查 MoE AI 模型
混合专家架构(MoE)将每个 token 通过其 8 个专家层中的一部分进行处理。这使得它在推理成本低于同等总参数规模密集模型的情况下,能产生接近 70B 的推理质量。Eric Hartford 的无审查微调版本始终保持着对编程能力的侧重。
- 参数规模: 8x7B(单次推理的激活参数远低于总参数)
- 显存需求: 量化后约 12-16GB
- 适用场景: 复杂编程任务、技术推理和更长的指令链
- 平台: Ollama
4. dolphin-mistral:用于快速响应的无审查 7B 本地 AI 模型
相比 dolphin-mixtral,它在 CPU 受限的硬件上更轻、更快。它获得了 150 万次拉取,深受那些既需要快速响应代码补全,又没有高端 GPU 的开发者青睐。Mistral 的基础架构赋予了该 7B 模型极高的性能尺寸比。
- 参数规模: 7B
- 显存需求: ~5-6GB
- 适用场景: 轻量级代码辅助和快速对话响应
- 平台: Ollama
5. dolphin-phi 2.7B:最轻量的无审查本地 AI 模型
微软的 Phi 基础架构将强大的推理能力浓缩进 2.7B 的参数中。Eric Hartford 的无审查微调保留了这一效率。在 4GB 以下显存占用下,它可以在大多数配备独立显卡的消费级笔记本电脑上运行,成为 2026 年最佳无审查本地 AI 模型的平民化入口。
- 参数规模: 2.7B
- 显存需求: 4GB 以下
- 适用场景: 笔记本电脑部署、快速测试和硬件受限环境
- 平台: Ollama
排名第 6-10 的最佳无审查 LLM 模型:编程、角色扮演与长上下文
在 2026 年,Dolphin 系列在 Ollama 无审查目录中占据了前 10 名中的 5 个席位。这种集中度反映了 Eric Hartford 将一致的微调方法论应用于不同基础架构的成功(Ollama,hermes3 模型页面,2026)。第 6 到第 10 名的模型涵盖了角色扮演、日常对话、开发者工具、指令遵循和扩展上下文,这些正是主流 AI 的拒绝机制造成干扰最严重的领域。
6. hermes3:用于角色扮演和代理任务的无审查 AI 模型
Nous Research 开发了 hermes3,主打角色扮演深度和结构化工具调用。它提供从 3B 到 405B 四种尺寸,是本列表中尺寸跨度最大的模型。8B 版本拥有 130 万次拉取,非常适合创意写作和代理任务规划工作流(Ollama,hermes3 模型页面,2026)。
- 参数规模: 3B, 8B, 70B 或 405B
- 显存需求: ~2GB (3B);~5GB (8B);~40GB (70B)
- 适用场景: 角色扮演、创意虚构和代理任务规划
- 平台: Ollama
7. wizard-vicuna-uncensored:用于通用场景的多尺寸无审查 AI 模型
一款基于 Llama 2 的成熟模型,提供最高 30B 的三种尺寸选择。其 120 万次拉取主要来自那些需要更广泛参数范围及可靠无审查方案的用户。虽然它在上下文窗口能力上不及 dolphin-llama3,但在日常对话和创意内容处理方面表现稳定。
- 参数规模: 7B, 13B 或 30B
- 显存需求: ~5GB (7B);~9GB (13B);~20GB (30B)
- 适用场景: 通用对话和多尺寸创意内容生成
- 平台: Ollama
8. dolphincoder:基于 StarCoder2 的无审查 AI 编程模型
以 StarCoder2 为基础使 dolphincoder 成为了纯粹的专家级模型。与其他作为通用模型并辅以无审查微调的 Dolphin 型号不同,该模型专门针对软件开发。它的 94.3 万次拉取几乎全部来自开发者而非创意用户。15B 版本能够处理比 7B 更庞大的代码库。
- 参数规模: 7B 或 15B
- 显存需求: ~5GB (7B);~10GB (15B)
- 适用场景: 代码生成、调试和技术文档撰写
- 平台: Ollama
9. wizardlm-uncensored:用于研究工作流的无审查指令遵循 LLM
一款 13B 参数的指令遵循模型,拥有 61 万次拉取。它的优势在于能够遵循复杂的多步指令,而不进行推诿或拒绝执行子任务。在研究工作流中,一次拒绝就可能中断长链路,因此这种可靠性具有直接的生产力价值。它虽没有 dolphin-llama3 那样的现代基础架构,但执行指令任务非常稳定。
- 参数规模: 13B
- 显存需求: ~9GB
- 适用场景: 复杂多步指令链和研究工作流
- 平台: Ollama
10. everythinglm:拥有 16K 上下文窗口的无审查 LLM
其核心亮点是基于 Llama 2 架构的 16K 上下文窗口。大多数 7B 模型通常限制在 4K 或 8K token。额外的上下文让 everythinglm 能够处理完整的代码库、长文档或延长的对话历史而无需截断。其 53.6 万次拉取在该列表中虽属中规中矩,但它填补了该尺寸级别其他模型无法覆盖的空白。
- 参数规模: 13B
- 显存需求: ~9GB
- 适用场景: 长文档分析、扩展上下文对话和全代码库审查
- 平台: Ollama
Dolphin 系列在 Ollama 下载量中的主导地位反映了社区总结的一种模式:由单一作者采用一致方法论进行的微调无审查模型,优于一次性的剔除尝试。剔除(Abliteration)是从单个模型中移除拒绝权重,而微调则是跨不同基础架构构建稳定的无审查行为。这种一致性解释了为什么前 10 名中有 5 个席位属于 Eric Hartford 的作品,而非任何单一的基础架构。
如何在本地设置 Ollama 无审查模型?
在 2026 年,只需三个命令即可在 Mac、Linux 或 Windows 上安装任何 Ollama 模型:从 ollama.com 安装 Ollama,运行 ollama pull [模型名],然后运行 ollama run [模型名](Ollama 文档,2026)。无需 API 密钥,不受外部内容审核限制,你的提示词永远不会离开你的硬件。
以 dolphin-llama3 为例:ollama pull dolphin-llama3 下载 4.7GB 的 8B 文件;ollama run dolphin-llama3 打开交互式提示符。整个推理过程都在你的本地 GPU 或 CPU 上运行。
对于喜欢使用图形界面的用户,LM Studio 提供了桌面 GUI。它使用与 Ollama 相同的 GGUF 模型文件,并提供模型选择和参数调整的可视化界面。llama.cpp 是这两个工具背后的底层推理引擎,当你需要更多地控制量化级别和上下文长度设置时,它也支持直接在命令行使用。
需要特定硬件要求和量化设置以在消费级 GPU 上运行 2026 年最佳无审查本地 AI 模型的开发者,可以参考完整的本地设置指南,其中详细介绍了最小显存配置和常见设置错误。
没有本地 GPU 时有哪些 OpenRouter 无审查模型可用?
在 2026 年,OpenRouter 通过 API 托管无审查 LLM,完全免除了对 GPU 的硬件要求。venice/uncensored 模型作为免费层模型提供,每百万输入和输出 token 费用为 USD0(OpenRouter,venice/uncensored 模型页面,2026)。这使得 OpenRouter 无审查模型成为没有专用硬件用户的实际切入点。
权衡很简单:OpenRouter 会通过其基础设施路由你的提示词,因此对话并不像本地模型那样私密。本地 Ollama 模型将一切保存在你的设备上。没有一种方法是绝对完美的,正确的选择取决于你的威胁模型和硬件可用性。
11. venice/uncensored:免费的 OpenRouter 无审查模型
OpenRouter 免费层上的 Venice 无审查模型。采用 24B Mistral-Small 架构,由 Cognitive Computations 与 Venice.ai 合作微调,支持无审查输出。具备 32K 上下文窗口,费用为每百万 token USD0。OpenRouter 的免费层对所有免费模型应用了每天 200 次请求的平台范围限制。
- 参数规模: 24B
- 显存需求: 无(云端托管)
- 适用场景: 在没有本地硬件的情况下测试无审查 LLM;在平台速率限制内免费
- 平台: OpenRouter
12. Sao10K: Llama 3.3 Euryale 70B:通过 OpenRouter 使用的大型无审查模型
由 Sao10k 开发的 70B 创意角色扮演和指令遵循模型,针对无审查输出进行了微调。基于 Llama 3.3 70B,拥有 131K 上下文窗口。在 OpenRouter 上有活跃的真实使用记录,可通过平台全局搜索按名称查询。
- 参数规模: 70B
- 显存需求: 无(云端托管)
- 适用场景: 在没有本地硬件的情况下进行复杂的创意写作、角色扮演和长指令链
- 平台: OpenRouter
13. Sao10K: Llama 3 8B Lunaris:通过 OpenRouter 使用的轻量级无审查模型
Lunaris 8B 是由 Sao10k 开发的一款多功能通用和角色扮演模型,基于 Llama 3 8B。它是多个模型的战略融合体,旨在平衡创造力与改进后的逻辑和通识知识。它提供了比 Stheno v3.2 更出色的体验,并增强了创造力和推理能力。这是 OpenRouter 上性价比最高的无审查方案,价格为每百万 token USD0.04/USD0.05,在平台上有超过 60 亿 token 的真实使用量。
- 参数规模: 8B
- 显存需求: 无(云端托管)
- 适用场景: 以极低成本进行轻量级无审查对话和创意写作
- 平台: OpenRouter
14. TheDrummer: Cydonia 24B V4.1:通过 OpenRouter 使用的无审查创意写作模型
Cydonia 24B V4.1 是由 TheDrummer 开发的一款无审查创意写作模型,基于 Mistral Small 3.2 24B,具备良好的记忆力、指令遵循能力和智能水平,带有 131K 上下文窗口。该模型维护活跃,可通过 OpenRouter 的全局搜索直接按名称查询。
- 参数规模: 24B
- 显存需求: 无(云端托管)
- 适用场景: 在没有本地硬件的情况下进行无审查创意写作和角色扮演
- 平台: OpenRouter
如何通过 Atlas Cloud 访问无审查图像和视频模型
在 2026 年,大多数无审查图像和视频模型都需要本地 GPU 硬件或专用的 API 平台,因为主流云服务商应用了在推理层面拦截 NSFW 输出的内容过滤器。Atlas Cloud 是一个专门为消除此类限制而构建的模型 API 平台,涵盖了文本、图像、视频和音频领域的 300 多种精选模型。
入门只需三步:
- 在 atlascloud.ai 创建帐户
- 从仪表板生成 API 密钥
- 使用密钥调用模型端点 — 图像和视频模型使用其自有的 REST 格式;LLM 端点遵循 OpenAI Chat Completions 格式
为什么 Atlas Cloud 对无审查用例特别有意义:
- 平台的隐私政策声明:“您生成的内容绝不会用于训练,也绝不会被任何人查看。” 这是一个公开发布且明确的承诺,而非默认假设。
- 目录中的任何模型均无每日生成上限。
- 无审查图像目录涵盖 33 种文本转图像模型,起价为每张图像 USD0.003。
- 无审查视频目录涵盖 10 多种 NSFW 视频模型,起价为 USD0.01/秒。
完整的无审查模型目录可在 Uncensored AI 浏览。此列表中的第 15 到第 20 名模型均可通过单个 Atlas Cloud API 密钥访问。
哪些是 2026 年最好的 NSFW 和成人内容生成无审查 AI 图像模型?
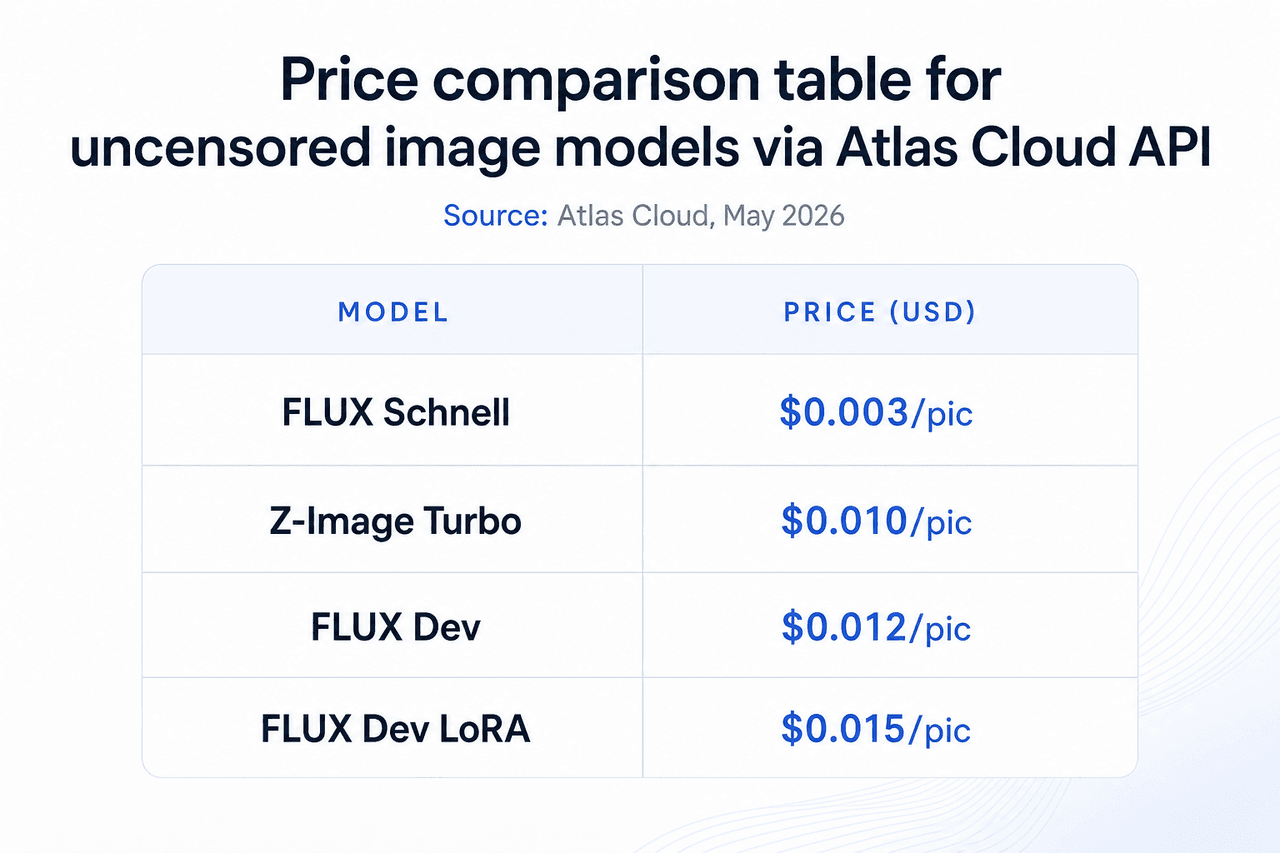
在 2026 年,FLUX 架构为大多数高质量无审查图像生成提供了动力,可通过 Atlas Cloud API 在不同价格和质量层级上获取(Atlas Cloud,文本转图像模型列表,2026)。Atlas Cloud 的目录总共涵盖 33 种文本转图像模型。用例包括艺术创作、角色设计、无审查内衣模特和成人肖像生成、游戏资产创作以及大规模批量插图。
Atlas Cloud 的主页声明“涵盖文本、图像、视频和音频的 300 多种精选模型”,其针对无审查目录的隐私政策写道:“您生成的内容绝不会用于训练,也绝不会被任何人查看。”
有关基于浏览器和 API 的无审查图像工具的全面分析,最佳无审查 NSFW AI 图像生成器指南涵盖了两个类别并进行了功能比较。专注于 FLUX 架构的开发者可以阅读 FLUX 无审查图像生成器指南以获取微调和工作流细节。
对于非文本提示词、而是从现有图像开始的工作流,无审查 AI 图生图指南以及最佳无审查 AI 图像编辑器指南分别涵盖了转换和编辑流程。专注于动画风格或插画角色输出的团队将在无审查动漫 AI 图像生成器指南中找到专业的选项。
15. FLUX Schnell:用于批量生成的快速无审查 AI 图像模型
Atlas Cloud 图像目录中的低成本选项。每张图像 USD0.003 的价格,使其成为速度和数量比细节更重要的批量生成工作流的理想工具。没有每日上限,且不存储任何内容用于训练。
- 价格: USD0.003/张
- 显存需求: 无(API 访问)
- 适用场景: 批量图像生成、快速原型设计和高产量无审查输出
- 平台: Atlas Cloud API
按每张图像 USD0.003 计算,USD3.00 的预算可以生成 1,000 张图像。该单次输出成本比大多数提供商对生成结果文件收取的云存储费用还要低。这彻底改变了工作室的经济模型——原本彻夜运行昂贵的本地 GPU 设备进行批量生成,现在使用 API 方法不仅更便宜,而且速度更快,能够胜任大批量工作。
16. FLUX Dev:用于最终制作的高质量无审查 AI 图像模型
价格是 FLUX Schnell 的四倍,但在解剖结构、光影和纹理细节上明显更优。对于关注单张图像质量的最终成图场景,USD0.012 的价位是一个切实的进阶。它适用于作品集、商业成人内容以及对质量有严格要求的制作素材。
- 价格: USD0.012/张
- 显存需求: 无(API 访问)
- 适用场景: 高质量单张图像、作品集展示和最终制作素材
- 平台: Atlas Cloud API
17. FLUX Dev LoRA:支持自定义风格训练的无审查图像模型
LoRA 微调将自定义风格、角色外貌或主体注入到 FLUX Dev 基础模型中。当你在整个批量中需要一致的角色形象,或者希望将特定风格应用于集合中的每张图像时,该模型是最佳选择。Atlas Cloud 会在服务端处理 LoRA 的加载。
- 价格: USD0.015/张
- 显存需求: 无(API 访问)
- 适用场景: 角色一致性、自定义风格训练和品牌图像系列
- 平台: Atlas Cloud API
18. Z-Image Turbo:中等质量的经济型无审查 AI 图像模型
在价格-质量曲线上介于 FLUX Schnell 和 FLUX Dev 之间。每张图像 USD0.01,Z-Image Turbo 提供了一种针对速度优化的不同架构,避免了 Schnell 在低价格点产生的图像简化。当 Schnell 的质量不够,而 FLUX Dev 的成本对所需产量来说过高时,它是务实的选择。
- 价格: USD0.01/张
- 显存需求: 无(API 访问)
- 适用场景: 在质量和成本之间需要平衡的中等产量生成
- 平台: Atlas Cloud API
哪些是 2026 年用于 NSFW 动画的最好无审查 AI 视频模型?
在 2026 年,无审查视频生成需要一套独立于图像生成的管道,因为主流视频平台应用了相同的内容过滤,即使源图像是在别处生成的,也拒绝将 NSFW 内容动画化(Atlas Cloud,无审查模型目录,2026)。Atlas Cloud 的无审查视频页面标题为“无限制的创作自由。无过滤。无限制。”并涵盖了 10 多种 NSFW 视频模型,完整目录还包括 Wan 2.6、Wan 2.5 和 Van 系列变体。
19. Wan 2.2 Turbo Spicy Infinite I2V:最低成本的无审查视频模型
从静止图像进行 NSFW 动画生成的入门级选项。USD0.01/秒的价格使其成为将静态图像制作成 NSFW 视频内容最具成本效益的方式。分辨率可达 1080p,支持可变剪辑时长,是预算敏感型生产线的正确起点。
- 价格: USD0.01/秒
- 分辨率: 1080p
- 时长: 可变
- 适用场景: 高性价比 NSFW 动画制作和动态概念预览
- 平台: Atlas Cloud API
20. Seedance v1.5 Spicy:用于最终产出的高质量无审查视频模型
目录中的电影级质量选项。USD0.049/秒的价格大约是 Wan 2.2 Turbo Spicy Infinite 的 2.5 倍,但它能产生更平滑的运动效果、更好的跨帧主体连贯性以及更自然的过渡。对于以视觉保真度为第一考量的最终 NSFW 视频成品,这是 Atlas Cloud 无审查视频阵容中的首选。
- 价格: USD0.049/秒
- 分辨率: 720p
- 时长: 5 秒
- 适用场景: 最终质量的 NSFW 视频、专业成人内容和交付级输出
- 平台: Atlas Cloud API
最佳无审查 AI 图生视频生成器指南涵盖了 Wan 2.7 和 Wan 2.2 Spicy 系列的所有变体,包括所有时长和分辨率选项。
无审查 AI 模型快速选择指南
| 需求 | 推荐 |
|---|---|
| 整体最佳无审查 LLM | llama2-uncensored 或 dolphin-llama3 |
| 编程任务 | dolphin-mixtral 8x7B 或 dolphincoder |
| 角色扮演和创意写作 | hermes3 |
| 4GB 显存以下 | dolphin-phi 2.7B |
| 无审查图像生成 | FLUX Schnell via Atlas Cloud (USD0.003/张) |
| 从图像生成 NSFW 视频 | Wan 2.2 Turbo Spicy Infinite via Atlas Cloud (USD0.01/秒) |
无审查 AI 模型常见问题解答
2026 年最无审查的 AI 模型是什么?
根据 Ollama 的下载量,llama2-uncensored 以 260 万次拉取处于领先地位,使其成为 2026 年无审查 AI 模型中社区认可度最高的选择(Ollama,无审查模型搜索,2026)。若论原始能力,dolphin-llama3 提供了更多功能:函数调用、最高 256K 上下文以及 Llama 3 基础架构。答案取决于你的用例更看重已验证的稳定性还是现代化的能力。
哪些无审查模型可以在 Ollama 上运行?
此列表中的十款模型均可作为 Ollama 无审查模型运行:llama2-uncensored、dolphin-llama3、dolphin-mixtral、dolphin-mistral、dolphin-phi、hermes3、wizard-vicuna-uncensored、dolphincoder、wizardlm-uncensored 和 everythinglm。社区模型 jaahas/qwen3.5-uncensored 也可在 Ollama 上运行以支持多语言使用。所有模型均可通过 ollama pull [模型名] 安装。
OpenRouter 上有哪些无审查模型?
在 2026 年,OpenRouter 通过 API 托管无审查 LLM,完全免除了对 GPU 的硬件要求。选项包括免费层模型 venice/uncensored(每百万 token USD0,每天 200 次请求),以及包括 Sao10K Euryale 70B、Lunaris 8B 和 TheDrummer Cydonia 24B 在内的付费模型(OpenRouter,venice/uncensored 模型页面,2026)。这些 OpenRouter 无审查模型无需本地 GPU,无需任何硬件投入即可开始使用。
剔除(abliterated)模型与微调(fine-tuned)无审查模型有什么区别?
剔除是在权重层面手术式地移除模型的拒绝权重。像 Dolphin 系列这样经过微调的无审查模型,从一开始就是通过不强化拒绝行为的数据集进行训练的。社区一致发现微调模型更稳定:剔除可能会在处理各种提示词类型时导致输出不一致,而微调则产生可靠的结果,这就是为什么 Dolphin 模型占据了 Ollama 无审查下载量的主要部分。
我可以在笔记本电脑上本地运行无审查 AI 模型吗?
是的。dolphin-phi 2.7B 在 4GB 显存以下即可运行,成为在配备独立显卡的笔记本电脑上进行部署的入门之选。拥有 6-8GB 显存即可运行此列表中的任何 7B 模型。集成显卡无法运行。针对无审查 AI 模型的本地设置指南详细介绍了最小硬件配置和量化设置。
结论
2026 年最佳无审查 AI 模型完全取决于你的用例。对于通用 LLM 工作,dolphin-llama3 是最强劲的 Ollama 选择。对于笔记本电脑,dolphin-phi 涵盖了 4GB 以下显存的需求。对于无需硬件的云端 LLM 访问,OpenRouter 免费层上的 venice/uncensored 是每百万 token USD0 的务实起点。对于大规模无审查图像生成,通过 Atlas Cloud API 使用 FLUX Schnell 即可实现每张图像 USD0.003 且无每日上限的生成。对于 NSFW 视频,Atlas Cloud 目录起价为 USD0.01/秒,并提供经过验证的“无训练、无人查看”政策。
希望全面了解图像、视频和编辑器等无审查 AI 工具的读者,可以参考 无审查 AI 图像生成器指南以了解完整图景。






