AI 视频 API 中的角色一致性(Character consistency)是指在不同镜头中维持角色视觉特征——如面部细节、服装和比例——的能力。通过摆脱“提示词碰运气”的模式,转向使用参考锚点(Reference Anchors)和微调 LoRA 等结构化的 API 约束,创作者现在可以制作具备 95% 视觉连续性的剧集内容,并将制作成本降低高达 80%。
多年来,“角色漂移”(Character Drift)现象——即主角的脸部特征或服装在帧与帧之间发生不一致的变化——让 AI 视频长期处于“恐怖谷”模因的范畴。这种视觉稳定性的缺失,是阻碍 AI 视频从短片段走向专业叙事的主要障碍。
如今,这一领域由**持久性(Persistence)**定义。行业已经从“反复尝试提示词”转向结构化生产。以 Atlas Cloud 为代表的集中式平台,通过提供通往高一致性 AI 视频 API 的统一网关,终于解决了这一“身份危机”。
| 指标 | 2024 年表现 | 2026 年表现 |
|---|---|---|
| 角色漂移 | 高(50% 面部偏移) | 极低(<5% 视觉差异) |
| 身份设置 | 手动提示词 | 自动化参考锚定 |
| 渲染模式 | 逐帧渲染 | 状态保持的时间相干性 |
通过掌握这些 AI 视频 API,创作者不再仅仅是“提示词工程师”,而是在导演一个数字电影的新纪元。以下技术已将 AI 从实验性玩具转变为专业的影视引擎:
- Atlas Cloud:一个统一的 API 平台,整合了 Seedance 2.0 和 Kling 3.0 等最前沿模型,允许开发者通过单一端点锁定整个系列的角色身份。
- LTX Studio:专为多镜头一致性和叙事控制而设计的综合性平台。
- 自定义 ComfyUI 端点:模块化工作流,允许创作者将特定的角色身份(LoRA)嵌入潜在空间(latent space)。
2026 年的 API 如何解决时间相干性
从闪烁的“梦境般”片段到稳定的剧集内容,这种转变源于 AI 视频 API 处理数据方式的根本性变革。在 2026 年,行业已超越了简单的文本提示,转向“状态化”(Stateful)架构,将角色身份视为一种持久变量,而非随机生成。
超越提示词:身份锚定(Identity Anchoring)
现代 API 利用“身份锚定”来消除角色漂移。开发者不再仅仅使用“蓄须男子”这种基础文本提示,而是使用“基础身份”。这通常是一张清晰的照片或 3D 头部模型,充当严格的规则。它像稳固的锚点一样工作,确保每一帧看起来都与原始角色完全一致,无论光线或摄像机角度如何变化,脸部和骨骼结构始终保持不变。

图示: Image_0.png 展示了单一中性参考肖像(“锚点”)如何强制 AI API 在多样化、动态的场景中维持相同的身份(注意独特的伤疤和耳环),包括透视、光照和环境的变化。
LoRA 和 IP-Adapter 的作用
为了实现“最先进”的一致性,技术管线利用了两个关键组件:
- LoRA(低秩自适应): 这些是经过微调的小型权重层,用于“锁定”角色的特定审美,例如独特的皮肤纹理或服装图案。
- IP-Adapter: 与需要训练的 LoRA 不同,IP-Adapter 允许即时的“零样本”(zero-shot)身份注入。
目前最稳定的专业工作流采用“混合堆栈”:
| 组件 | 技术功能 | 一致性目标 |
|---|---|---|
| 身份 LoRA | 基本体型与氛围 | 70% |
| PuLID / IP-Adapter | 精确的面部特征锁定 | 90% |
| ControlNet | 空间与姿态调控 | 95%+ |
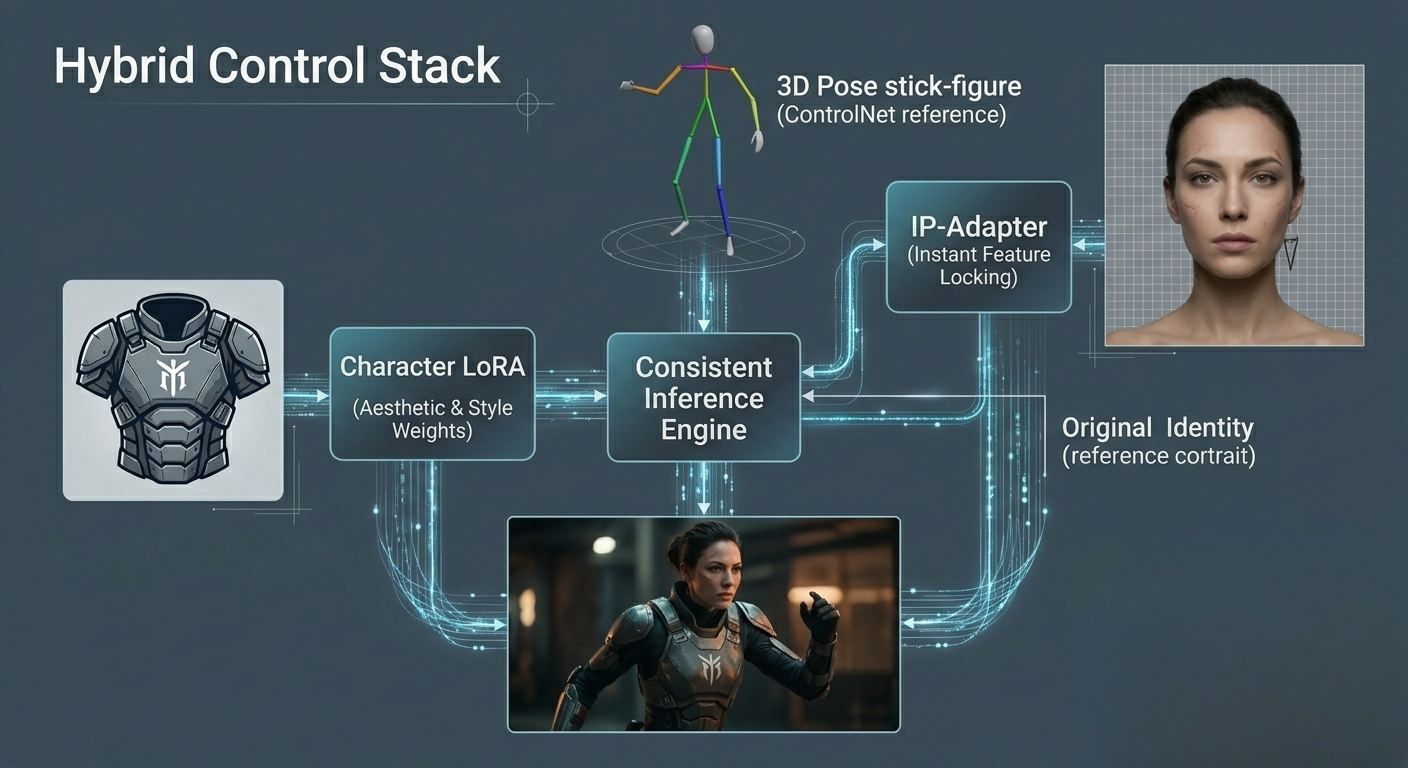
image_1.png 直观展示了如何应用多种约束。我们可以看到空间控制(ControlNet/姿态)、特定角色特征(IP-Adapter 引用图像)以及专门的审美权重(LoRA 负责盔甲)相结合,从而在新的情境中生成一致的角色。
种子轨迹与潜在空间锁定(Latent Space Locking)
一项高价值的技术突破是使用“潜在空间锁定”。每个 AI 生成都始于一个“种子”(随机噪声)。通过在帧间保持噪声模式或“种子轨迹”的一致性,API 能够防止“脸部融化”的过渡。这种方法确保像素背后的数学逻辑平稳演变,使角色在复杂环境中移动时不会丢失视觉完整性。
将这三部分结合起来,创作者终于可以制作出主角在每一集中都保持相同形象的剧集。从第一场戏到季终,面部始终完美一致。

Image_2.png 提供了对比。顶部时间轴(标准噪声)显示了 image_0.png 中的角色脸部“融化”——特征、表情甚至身份都发生了偏移。底部时间轴(锁定噪声)显示脸部保持了近 95% 的同一性,仅呈现出自然的动作演变(如转头),这归功于 API 所应用的数学约束。
变革剧集制作管线
角色一致性 AI 视频 API 的集成,从根本上改变了剧集媒体的经济格局。这里的重大胜利不再仅仅是“速度”,而是让任何人都能创作高质量的故事。这些工具处理了保持视觉一致性的难题,使小型创作者和微型工作室也能制作出媲美大型好莱坞电影的作品。
新的生产范式
过去,为动画系列创建一致的角色需要对 3D 建模、骨骼绑定和贴图进行巨额的前期投资。如果角色设计在季中发生变更,这种“技术债务”可能会导致整个制作瘫痪。
现代 AI 工作流 用动态、微调的权重取代了这些僵化的资产。采用 AI 原生管线的制作团队报告称,总开销降低了 70-90%。
效率基准:传统与 AI 原生对比
下表说明了针对 22 分钟标准剧集的关键绩效指标差异:
| 特性 | 传统动画/CGI | AI 视频 API 工作流 |
|---|---|---|
| 角色设置 | 数月的建模/绑定 | 2–4 小时的 LoRA 训练 |
| 每集成本 | $100,000 – $1M+ | $500 – $5,000 |
| 迭代速度 | 数周(渲染时间) | 数分钟(推理时间) |
| 一致性 | 完美(手工编码) | 高(API 约束 95%+) |
虽然传统方法在像素级精度上仍占优势,但“推理优于渲染”的模型允许创作者在几分钟内生成初稿。这种“时间压缩”使得工作室每月发布的内容量增加了 42%,将剧集内容从慢节奏的奢侈品转变为敏捷、响应迅速的媒介。
案例研究:“微剧集”与虚拟偶像的兴起
我们正从随机片段走向真实叙事,这催生了一个新趋势:AI“微剧集”。通过利用能保持角色外观一致的智能视频工具,人们正在制作视觉效果堪比常规动画的剧集,且投入的时间和成本大大降低。

独立创作革命:20 天制作 20 集
TikTok 和 YouTube Shorts 上的独立创作者不再受限于曾困扰 AI 生成视频的“身份漂移”。通过使用如 Atlas Cloud 等统一平台编排 Seedance 2.0 或 Kling 3.0 等模型,创作者可以定义一次“角色 ID”并在整个季度重复使用。
这一技术飞跃促成了序列化叙事的兴起,特点如下:
- 制作速度: 创作者在数周内即可推出 20 集的微剧集,而传统 CGI 则需要 12–18 个月。
- 参与度: 虚拟偶像现已占据 4.2% 的市场份额,平均参与率达到 5.67%——几乎是真人偶像的三倍。
全球品牌一致性与 AI 发言人
对于全球化企业而言,过去的“身份危机”曾是一种品牌安全风险。如今,公司利用 AI 视频 API 在不同市场维持一致的“虚拟发言人”。通过 API 调用集中的角色嵌入,品牌可以生成本地化内容,其中发言人保持视觉一致,同时用不同语言说话或出现在特定文化场景中。
| 收益 | 对全球品牌的影响 |
|---|---|
| 视觉保真度 | 所有地区的身份同一性保持 95%+。 |
| 本地化 | 通过本地化 API 调用实现实时口型同步和语言翻译。 |
| 风险管理 | 相比人类明星代言人,争议风险为 0%。 |
市场增长趋势
这种一致性带来的经济影响是惊人的。行业数据显示,品牌支出正发生根本性转向,倾向于这些持久的数字资产:
- 市场规模: 虚拟偶像市场在 2026 年初达到 46 亿美元。
- 效率: AI 一致性角色的单条内容制作成本比涉及真人网红的内容低 38%。
- 采纳率:92% 的品牌目前正在使用或积极测试用于剧集式营销的 AI 工作流。
通过将角色身份视为可扩展的数字资产,AI 视频 API 已超越了“玩具”阶段,成为高效剧集经济的支柱。
如何实现工作流的一致性
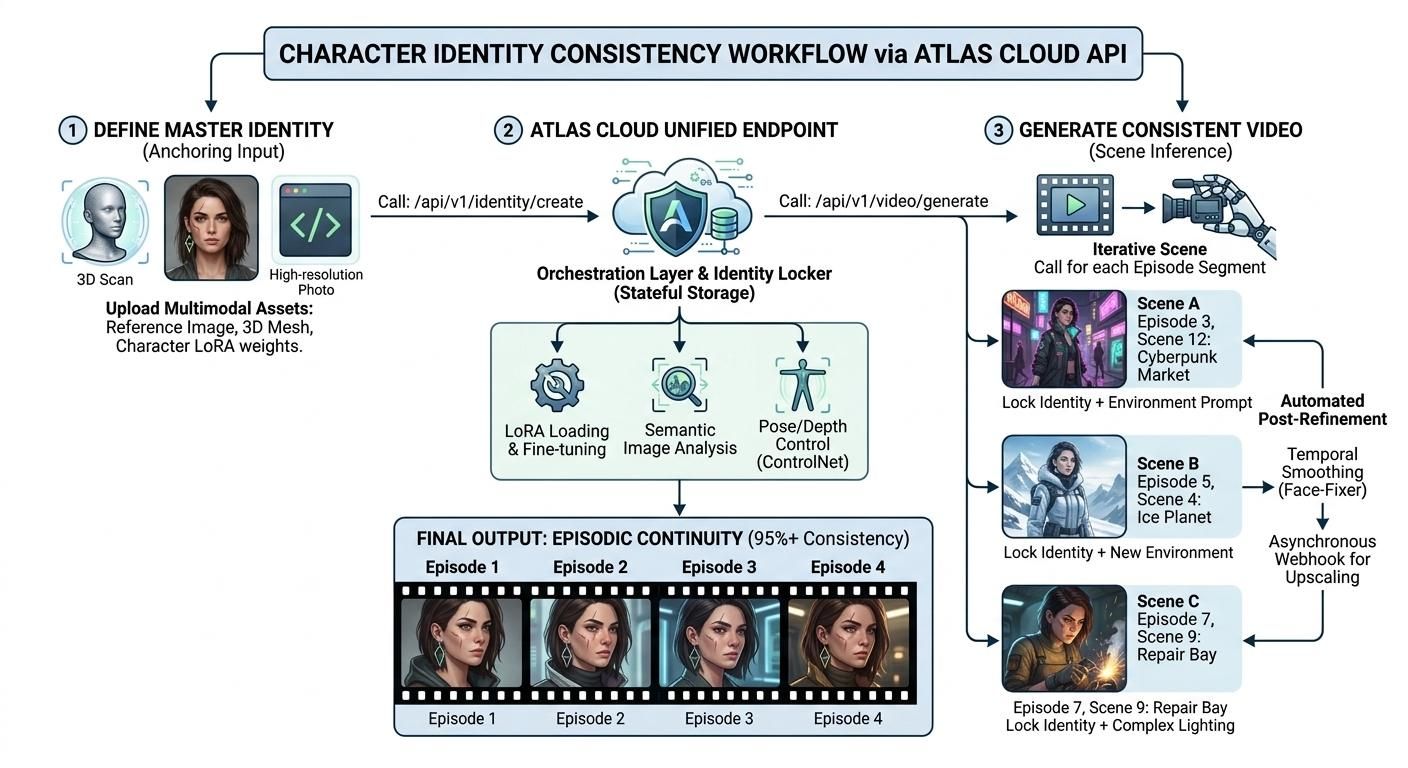
从仅仅玩玩 AI 片段到制作真正的剧集需要新的规划。你需要一个组织严密、易于扩展的工作流。行业标准已转向使用多模态输入来锚定视觉身份的“一键式访问”架构。通过利用统一的 AI 视频 API,创作者可以在无需逐帧编辑的情况下,在各种场景中维持角色连续性。
第一步:定义主身份(Master Identity)
任何一致性剧集的基石都是主身份。除了简单的文本描述外,创作者现在使用多种文件的组合。他们通常采用清晰的参考照片并结合 3D 地图或角色 LoRA。这种“身份锚点”保持了稳定性,确保脸部、细小伤疤甚至衬衫图案在每个镜头中都丝毫不差。
第二步:通过 Atlas Cloud 进行编排
专业管线不再需要为不同模型拼凑独立的 API 密钥和不兼容的数据格式,而是采用 Atlas Cloud 统一 API。这一编排层允许在保持同一核心代码库的同时无缝切换模型。
例如,创作者可以通过 Atlas Cloud 调用 Seedance 2.0 “通用参考” 系统,锁定 15 秒复杂动作序列的角色特征。如果某个镜头需要 Kling 3.0 更流畅的运动效果或 Veo 3.1 更写实的电影级灯光,开发者只需在 Atlas Cloud 环境中切换模型参数即可。
| 工作流阶段 | 工具示例 | 核心优势 |
|---|---|---|
| 模型切换 | Kling 3.0 ↔ Veo 3.1 | 针对镜头类型优化性能 |
| 身份锁定 | Seedance 2.0 Ref | 永久的面部与服装持久性 |
| 集成 | Atlas Cloud SDK | 统一端点,无碎片化密钥 |
seedance-2.0 以图生视频 代码示例:
plaintext1import requests 2import time 3 4# 第一步:开始视频生成 5generate_url = "https://api.atlascloud.ai/api/v1/model/generateVideo" 6headers = { 7 "Content-Type": "application/json", 8 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 9} 10data = { 11 "model": "bytedance/seedance-2.0/image-to-video", 12 "prompt": "一艘平滑的未来派飞船缓慢环绕巨大的行星飞行。你可以看到行星明亮的云层和太空中的发光大气。背景中满是星星和彩色的气体云。飞船平稳地沿着轨道移动,看起来就像一部科幻大片的场景。当摄像机跟随飞船时,光感显得深邃且真实。", 13 "image": "https://static.atlascloud.ai/media/images/454eee7f1a05a0bf276afe2e056200ba.png", 14 "duration": 5, 15 "resolution": "720p", 16 "ratio": "adaptive", 17 "generate_audio": True, 18 "watermark": False, 19 "return_last_frame": False, 20} 21 22generate_response = requests.post(generate_url, headers=headers, json=data) 23generate_result = generate_response.json() 24prediction_id = generate_result["data"]["id"] 25 26# 第二步:轮询结果 27poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 28 29def check_status(): 30 while True: 31 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 32 result = response.json() 33 34 if result["data"]["status"] in ["completed", "succeeded"]: 35 print("生成的视频:", result["data"]["outputs"][0]) 36 return result["data"]["outputs"][0] 37 elif result["data"]["status"] == "failed": 38 raise Exception(result["data"]["error"] or "生成失败") 39 else: 40 time.sleep(2) 41 42video_url = check_status()
第三步:生成后优化

为了达到“4K 广播级”质量,最后阶段涉及自动化后处理桥接。利用 Atlas Cloud 的异步 Webhook 架构,系统可以在 1080p 渲染完成的瞬间自动触发外部增强任务。
常见的自动化后处理任务包括:
- 时间平滑: 消除角色特征的微小波动。
- 外部 4K 超分: 将 1080p API 输出通过专门的超分辨率模型进行处理。
- 视听同步: 使用 Vidu Q3 集成,自动根据角色动作调整音效时序。
通过在 API 中使用此三步流程,团队可以自动处理 85% 的视觉工作。这让你能在几分钟内创作高质量剧集,同时保持完美的视觉连贯性。
展望未来:终结“恐怖谷”?
随着我们走向 2026 年下半年,AI 视频 API 的演进正从预渲染的剧集内容转向“实时身份”范式。曾经制造“恐怖谷”的技术障碍——如微抖动和光照不一致——正在被实时神经渲染所消除。
向实时一致性视频的转变
下一个前沿是向“实时 AI 虚拟人”的转型。这些工具的后续版本有望在 100 毫秒内完成处理。这意味着角色在实时对话时能保持外观一致。这将改变叙事方式:人们能够在直播中与角色对话,或在节目中选择自己的故事路径。即使故事因你的行为而改变,角色依然能保持完美的形象。
伦理层:保护身份权利
随着复制角色甚至个人能力变得触手可及,随之而来的是重大的法律挑战。行业目前正在开发“身份权利”框架以防止未经授权的数字克隆。在 2026 年,我们看到了以下技术的出现:
- 链上身份验证: 使用区块链为角色的独特权重配置“签名”。
- 水印标准: 所有 API 生成的角色必须强制执行 SynthID 风格水印,以区分人类演员与合成演员。
常见问题解答
什么是 AI 视频中的角色一致性?
角色一致性意味着 AI 模型能保持主体形象绝对稳定。它确保脸部、头发和衣服在不同角度和场景中保持一致。在真实的剧集制作中,正是这一点将一系列随机片段转化成了连贯、紧凑的故事。
哪些 AI 视频 API 支持角色一致性?
虽然市场上不断涌现新模型,但目前通过 API 提供稳健一致性控制的领跑者包括:
- LTX-Studio: 专注于电影级的“场景间”角色锁定。
- Magic Hour: 专注于一致性角色动画和换脸的创作者的热门选择。
- Atlas Cloud: 一个通过单一专注一致性的端点来协调多个模型的统一平台。
我可以使用自己的脸进行角色一致性创作吗?
可以。通过“角色客串”(Character Cameo)功能和 IP-Adapter,你可以上传自己的参考肖像。API 会提取你的“面部潜在权重”并将其应用于数字主角,确保你在整集中始终是那个一致的主角。






