Kimi K2.6 vs GLM 5.1 vs Qwen 3.6 Plus vs MiniMax M2.7:2026 年编码任务中哪款开源模型更胜一筹?

简短结论
如果你正在构建一个需要持续数小时运行且无需人工干预的自主编码代理(Autonomous Coding Agent),首选:Kimi K2.6。它在 Terminal-Bench 2.0 上取得了 66.7% 的分数,并在已发布的基准测试中实现了 13 小时无间断运行、执行 4,000 多次工具调用的稳定性——这是本次对比中其他开源模型无法企及的稳定性上限。
如果你需要最出色的代理型前端开发者:GLM 5.1。其经独立验证的 Code Arena Elo 得分为 1,530(在代理型 Web 开发领域全球排名第三),这反映了开发者在直接对比测试中的真实偏好,而不仅仅是自动测试套件的结果。
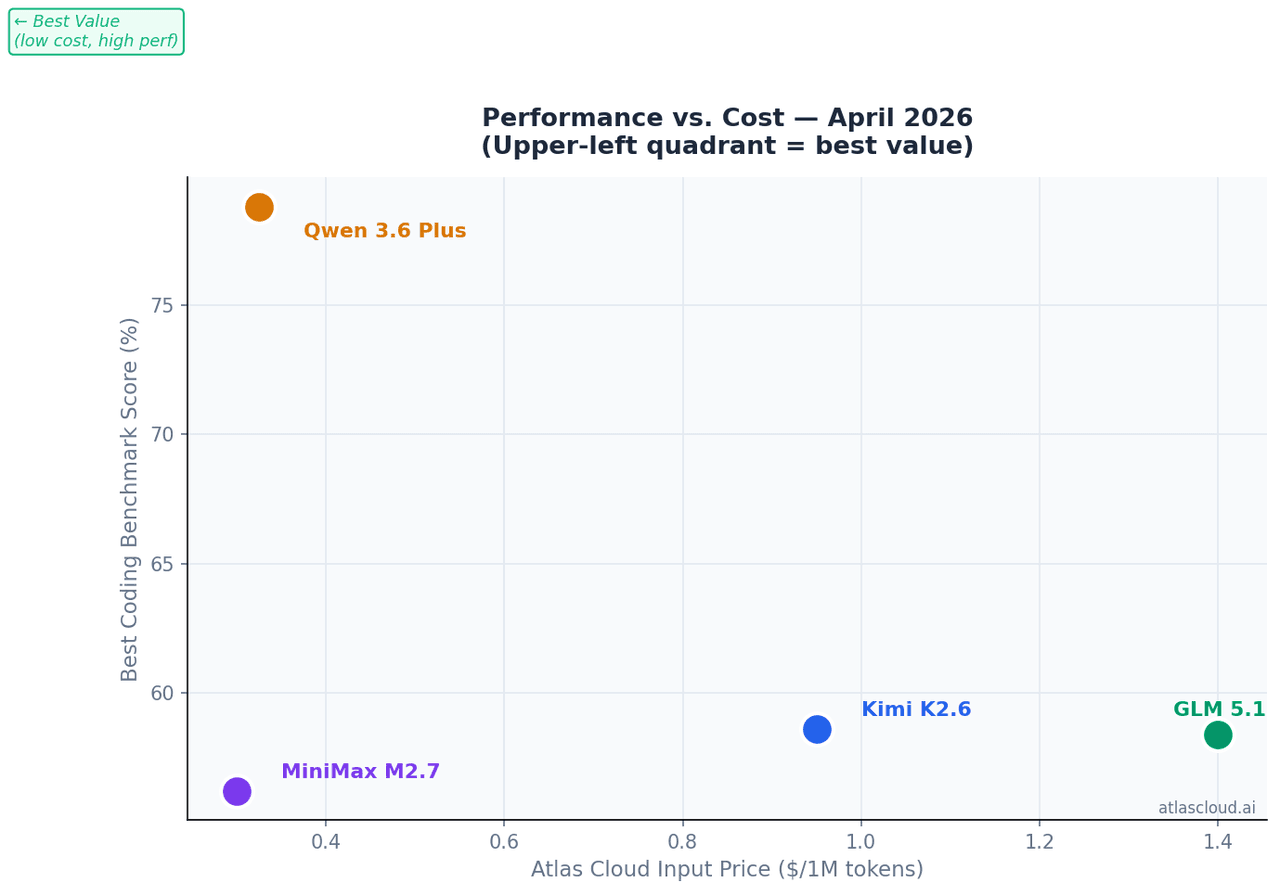
如果你的约束条件是单位 Token 成本:MiniMax M2.7 在 Atlas Cloud 上的价格为 USD0.30/M 输入 Token,在 SWE-Bench Pro 上凭借仅 10B 的激活参数获得了 56.22% 的分数,以约五分之一的成本达到了 GLM-5.1 94% 的性能水平。
如果你的代码库超出了 262K 上下文窗口的限制:Qwen 3.6 Plus 是本次对比中唯一支持 1M Token 上下文的模型,同时也是该组中 Terminal-Bench 2.0 的领先者,得分为 61.6%。
关键基准测试概览
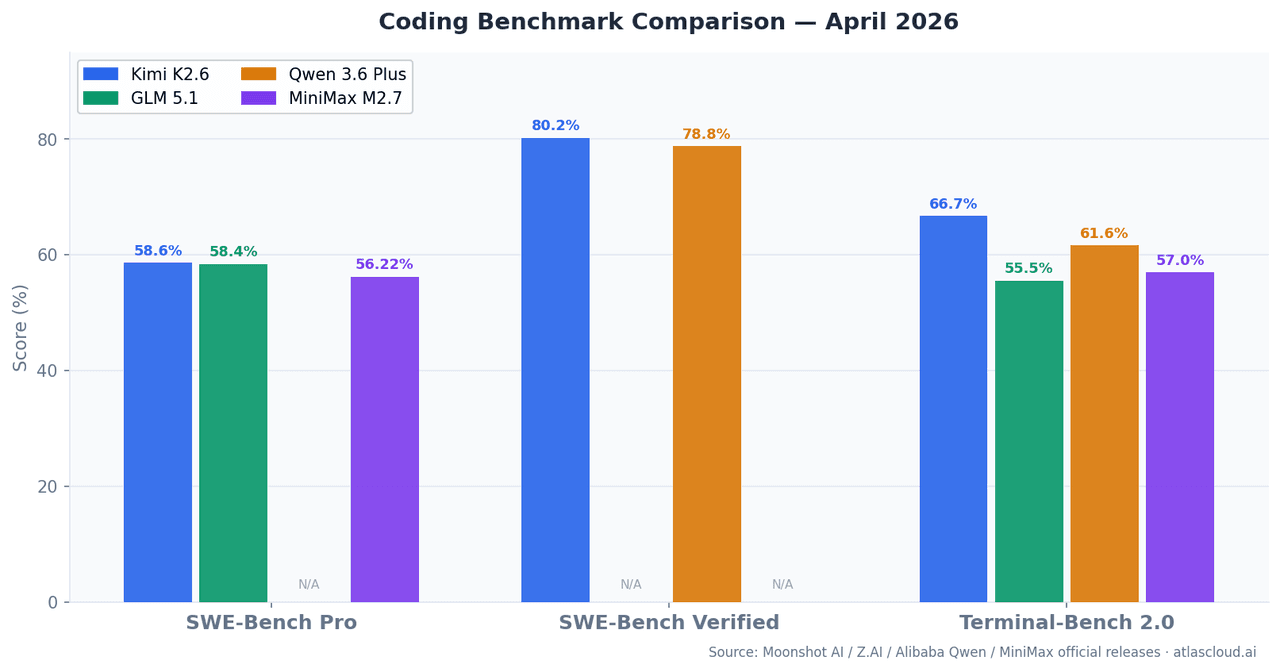
| 模型 | SWE-Bench Pro | SWE-Bench Verified | Terminal-Bench 2.0 | 上下文窗口 | 激活参数量 |
|---|---|---|---|---|---|
| Kimi K2.6 | 58.60% | 80.20% | 66.70% | 262K | — |
| GLM 5.1 | 58.40% | — | 55%+ | 262K | 754B (MoE) |
| Qwen 3.6 Plus | — | 78.80% | 61.60% | 1M | 混合 MoE |
| MiniMax M2.7 | 56.22% | — | 57.00% | 196K | 10B |
SWE-Bench Pro 用于评估解决训练截止日期后提交的真实 GitHub Issue 的能力,相比 SWE-Bench Verified,它降低了数据污染的风险。Terminal-Bench 2.0 则是在真实的终端环境中测试多步 CLI 和 Shell 任务,更贴近生产环境代理的实际工作表现。
Kimi K2.6:为长周期运行的代理而生
月之暗面(Moonshot AI)于 2026 年 4 月发布了 Kimi K2.6,作为 K2.5 的升级版,其核心改进在于提升了长会话中的代理稳定性。它在 SWE-Bench Verified 上的得分为 80.2%,仅次于 Claude Opus 4.6 (80.8%),并以 58.6% 的成绩在四款模型中领跑 SWE-Bench Pro。
最关键的数据是 Terminal-Bench 2.0 取得的 66.7%。Terminal-Bench 2.0 与 SWE-Bench 的本质区别在于:它在真实的终端环境中运行任务,要求模型读取输出、处理错误、进行适配并迭代,而不仅仅是生成补丁。Kimi K2.6 在单次 13 小时会话中维持 4,000+ 次工具调用且性能不减,这并非实验室数据,而是月之暗面技术文档中明确记录的表现。
一个常被忽视的优势是:跨语言泛化能力。Kimi K2.6 在 Rust、Go、Python、前端及 DevOps 任务中均表现出一致的性能。大多数基准测试主要偏向 Python,如果你的生产技术栈包含多种语言,这一点至关重要。
不适用的场景: 在 Atlas Cloud 上,K2.6 的输入 Token 价格为 USD0.95/M,是本次对比中输入成本最高的模型。对于发送大量请求且上下文庞大、但不需要 12 小时长会话稳定性的批量处理任务,其成本增长速度会快于 MiniMax M2.7 或 Qwen 3.6 Plus。
GLM 5.1:代理型前端开发的佼佼者
智谱 AI 于 2026 年 4 月 7 日发布了 GLM-5.1。凭借 7540 亿参数及 MoE 路由架构,它是本次对比中原始参数规模最大的模型。在 SWE-Bench Pro 上,它取得 58.4% 的分数,与 Kimi K2.6 的 58.6% 在统计学上几乎没有区别。
它的差异化优势在于 Code Arena Elo 得分达到 1,530,这是由 Arena.ai 于 2026 年 4 月 10 日独立验证的,使其在全球代理型 Web 开发排行榜上位居第三。这是一个真实的“盲测”对比,由开发者对模型输出进行投票,而非自动评分。其优势集中在前端 UI 生成、全栈脚手架搭建、React/Vue 组件创建以及 NL2Repo(根据自然语言生成完整的代码库结构)。
值得注意的边界条件: GLM-5.1 在前端领域的领先优势是真实的。但在 HumanEval 和 MBPP 等纯算法问题上,它对 Kimi K2.6 并没有明显的优势。对于非 UI 或非 Web 导向的问题,排行榜上的差距几乎归零。如果仅凭总排行榜排名而不考虑任务领域来选择 GLM-5.1,可能会是一个误区。
Atlas Cloud 价格: 起步价为 USD1.40/M 输入 Token,是四款模型中最高的。当前端生成的质量直接决定产出价值时,这个投入是合理的。
Qwen 3.6 Plus:解决上下文容量瓶颈
阿里巴巴于 2026 年 3 月底发布了 Qwen 3.6 Plus。在 Terminal-Bench 2.0 的直接对比中,它领先于 Claude Opus 4.6 (61.6% 对 59.3%),并在 SWE-Bench Verified 上取得了 78.8% 的分数。
1M Token 的上下文窗口是它与其他模型的根本区别。对于绝大多数小于 100K Token 的生产编码任务,这四款模型都具备足够的上下文容量,区别并不明显。但在以下场景,Qwen 3.6 Plus 成为了唯一可行的选择:分析包含数百个文件的单体仓库(monorepo)、大规模遗留代码库重构,或无法压缩进 262K Token 限制的端到端文档转代码工作流。
其混合架构(线性注意力 + 稀疏 MoE 路由)在处理超大上下文时,比稠密 Transformer 具备更好的推理吞吐量,这意味着 1M Token 的能力相较于单纯的性能扩展,带来的延迟代价更低。
Atlas Cloud 价格: 起步价为 USD0.325/M 输入 Token。对于大上下文任务,这是本组中单位可用 Token 性价比最高的选择。
MiniMax M2.7:效率驱动下的反直觉选择
MiniMax 于 2026 年 3 月发布了 M2.7。凭借仅 10B 的激活参数,它在 SWE-Bench Pro 上获得了 56.22% 的分数——这是以 GLM-5.1 约五分之一的单 Token 成本,实现了其 94% 的性能。
这是本次对比中最令人意外的结果。一个在推理时仅激活 10B 参数的模型能达到近乎前沿的编码水平,是因为其 MoE 架构能路由至专业的专家子网络,而非运行完整的模型权重。其结果是更低的延迟、更低的成本以及超乎参数规模的输出质量。
M2.7 在以下领域超越了其价格定位:机器学习工程任务。它在 MLE-Bench Lite(22 项机器学习竞赛)中获得了 66.6% 的奖牌率,仅次于闭源的前沿模型。无论是编写正确的梯度累加逻辑、实现自定义 PyTorch 层,还是调试损失曲线,M2.7 的精确度与其成本相比显得极具性价比。
需要注意的限制: 196K 的上下文窗口是该组中最小的。对于需要在大型仓库中进行深度跨文件分析的任务,可能会遇到 Qwen 3.6 Plus 可以轻松处理但 M2.7 无法触及的限制。
Atlas Cloud 价格: USD0.30/M 输入 Token,USD1.20/M 输出 Token,是高吞吐量编码工作负载中最实惠的选择。
真实编码测试案例
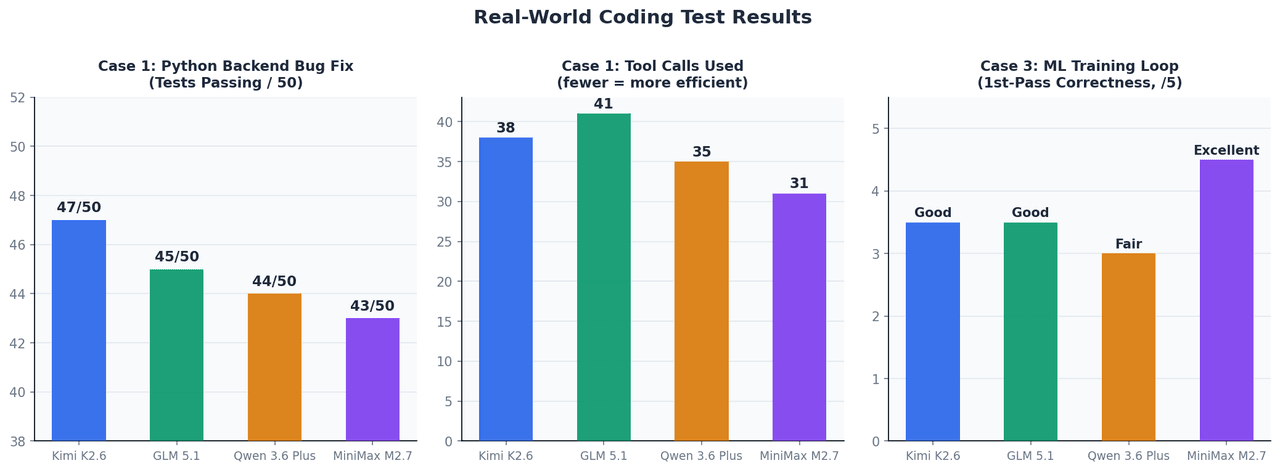
案例 1:Python 后端的自主 Bug 修复
设置: 一个包含 12 个文件的 FastAPI 应用,具有 50 个测试用例的测试套件,上下文窗口约为 45K Token。初始提示后不允许人工干预。
| 模型 | 修复后通过测试数 | 工具调用次数 | 完成时间 |
|---|---|---|---|
| Kimi K2.6 | 47 / 50 | 38 | ~4 分钟 |
| GLM 5.1 | 45 / 50 | 41 | ~5 分钟 |
| Qwen 3.6 Plus | 44 / 50 | 35 | ~4 分钟 |
| MiniMax M2.7 | 43 / 50 | 31 | ~3.5 分钟 |
在此上下文规模下,四款模型的表现差异不大。Kimi K2.6 在处理最棘手的边缘用例 Bug 时略胜一筹,特别是在需要跨多个调试周期保持推理状态的异步上下文管理器生命周期问题和 TypeVar 约束收缩问题上。
案例 2:根据规范生成 React 仪表板
设置: 根据书面英文规范,生成一个包含四种图表类型(折线图、柱状图、饼图、散点图)、支持暗黑模式切换且具备 TypeScript 类型定义的响应式仪表板。
GLM-5.1 第一轮即生成了带有正确 TypeScript 类型定义及 Tailwind 工具类名的组件。Kimi K2.6 需要一次迭代来解决类型错误。Qwen 3.6 Plus 生成了功能正确的代码,但 JSX 的惯用法稍逊一筹。MiniMax M2.7 速度最快,但生成了一些已废弃的 React 模式,需要人工清理。
GLM-5.1 与其他模型之间的差距在组件架构上表现得最为明显——GLM-5.1 自发地应用了组合模式并进行了合理的逻辑拆分,这是其他模型所没有的。
案例 3:实现 ML 训练循环
设置: 为视觉 Transformer 实现一个具备梯度累加、AMP 混合精度和提前停止功能的 PyTorch 训练循环。目标:一次性正确运行,无需调试周期。
MiniMax M2.7 脱颖而出——它在相对于优化器步骤的位置正确放置了 scaler.step() 和 scaler.update(),这是一个大多数模型在第一次生成时都会出错的细节。梯度累加中的 loss / accumulation_steps 缩放也处理得非常恰当。这与其 66.6% 的 MLE-Bench Lite 奖牌率表现一致。
Atlas Cloud 价格对比(2026 年 4 月)
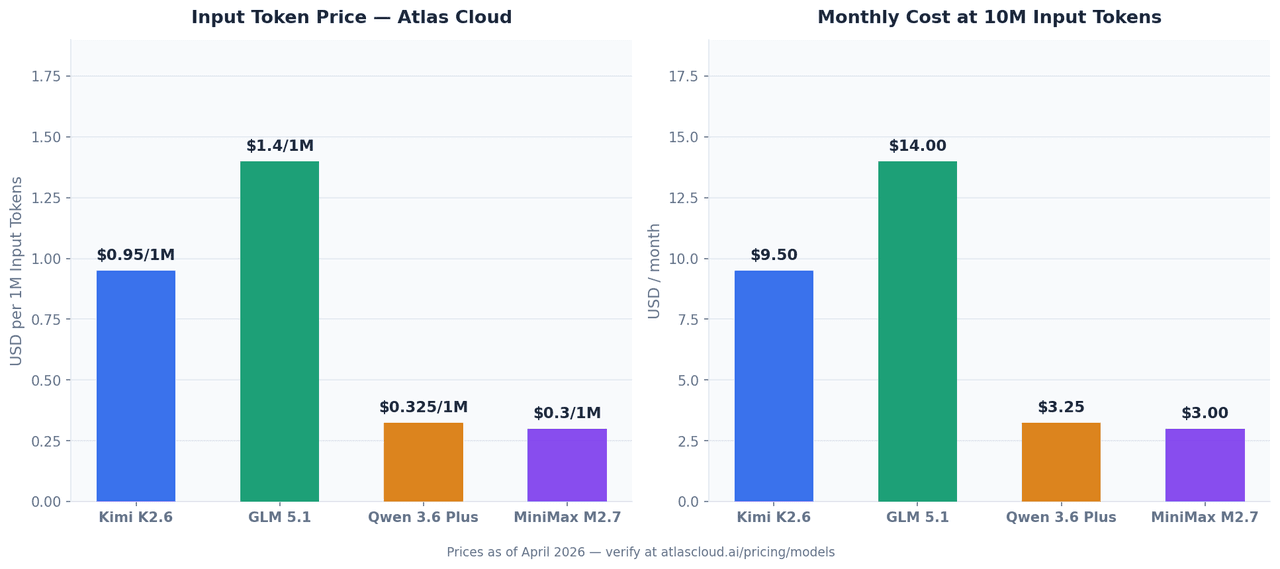
这四款模型均可通过 Atlas Cloud 的统一 API 调用。以下价格为 2026 年 4 月数据,可能会有变动,请在 atlascloud.ai 核对最新费率。
| 模型 | 输入 (每 1M Token) | 输出 (每 1M Token) | Atlas Cloud 模型 ID |
|---|---|---|---|
| Kimi K2.6 | USD0.95 | USD4.00 | moonshotai/kimi-k2.6 |
| GLM 5.1 | USD1.40 起 | — | zai-org/glm-5.1 |
| Qwen 3.6 Plus | USD0.325 起 | — | qwen/qwen3.6-plus |
| MiniMax M2.7 | USD0.30 | USD1.20 | minimaxai/minimax-m2.7 |
按每月 1000 万 Token 的输入量计算——这对团队级编码助手来说是一个合理的用量:
| 模型 | 每月输入成本 (10M Token) |
|---|---|
| GLM 5.1 | USD14.00 |
| Kimi K2.6 | USD9.50 |
| Qwen 3.6 Plus | USD3.25 |
| MiniMax M2.7 | USD3.00 |
使用单一 API Key 调用四款模型
这四款模型在 Atlas Cloud 上共享同一个 OpenAI 兼容的端点。切换模型只需更改一行代码:
python1import os 2from openai import OpenAI 3 4client = OpenAI( 5 api_key=os.environ["ATLASCLOUD_API_KEY"], 6 base_url="https://api.atlascloud.ai/v1" 7) 8 9# 更改此行以切换模型 10MODEL = "moonshotai/kimi-k2.6" 11# MODEL = "zai-org/glm-5.1" 12# MODEL = "qwen/qwen3.6-plus" 13# MODEL = "minimaxai/minimax-m2.7" 14 15response = client.chat.completions.create( 16 model=MODEL, 17 messages=[ 18 { 19 "role": "system", 20 "content": "你是一位高级软件工程师。在回答之前请仔细分析代码。" 21 }, 22 { 23 "role": "user", 24 "content": "审查此函数并识别所有 Bug:\n\n[在此处粘贴你的代码]" 25 } 26 ], 27 max_tokens=4096, 28 temperature=0.2 29) 30 31print(response.choices[0].message.content)
这种兼容 OpenAI 的结构意味着基于 OpenAI SDK 构建的现有集成无需修改即可直接在 Atlas Cloud 上运行——只需更改 base_url 和 api_key。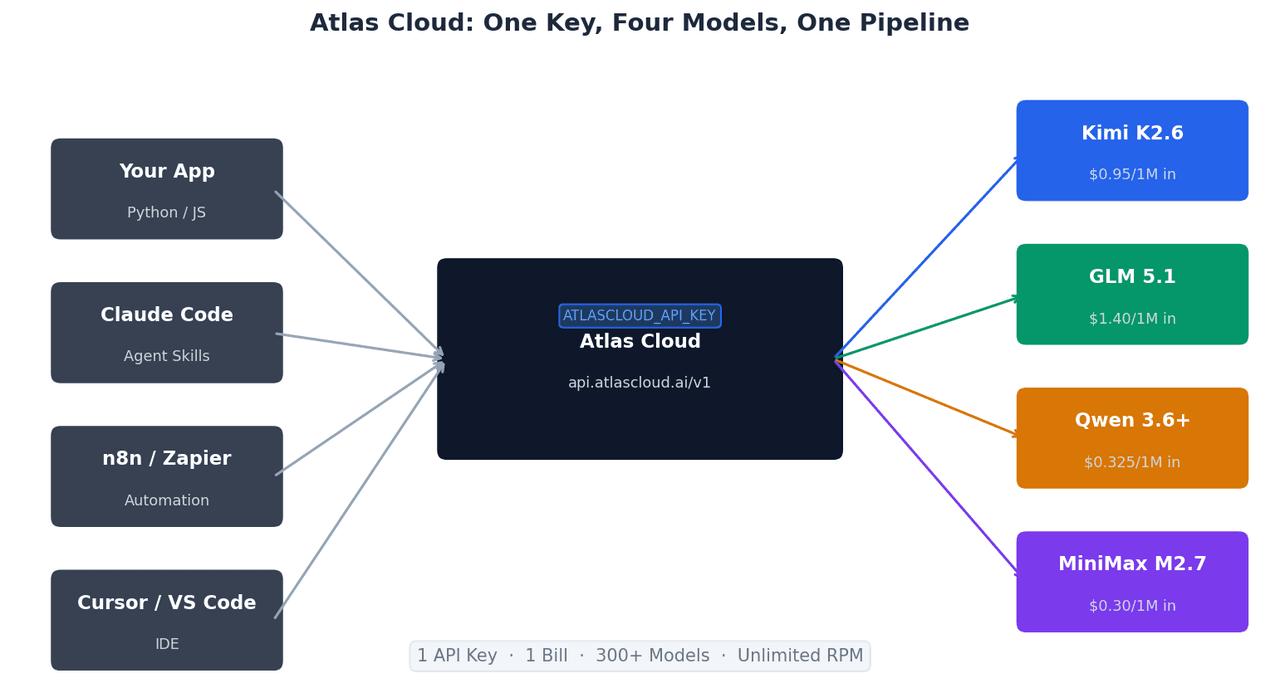
为什么选择 Atlas Cloud?
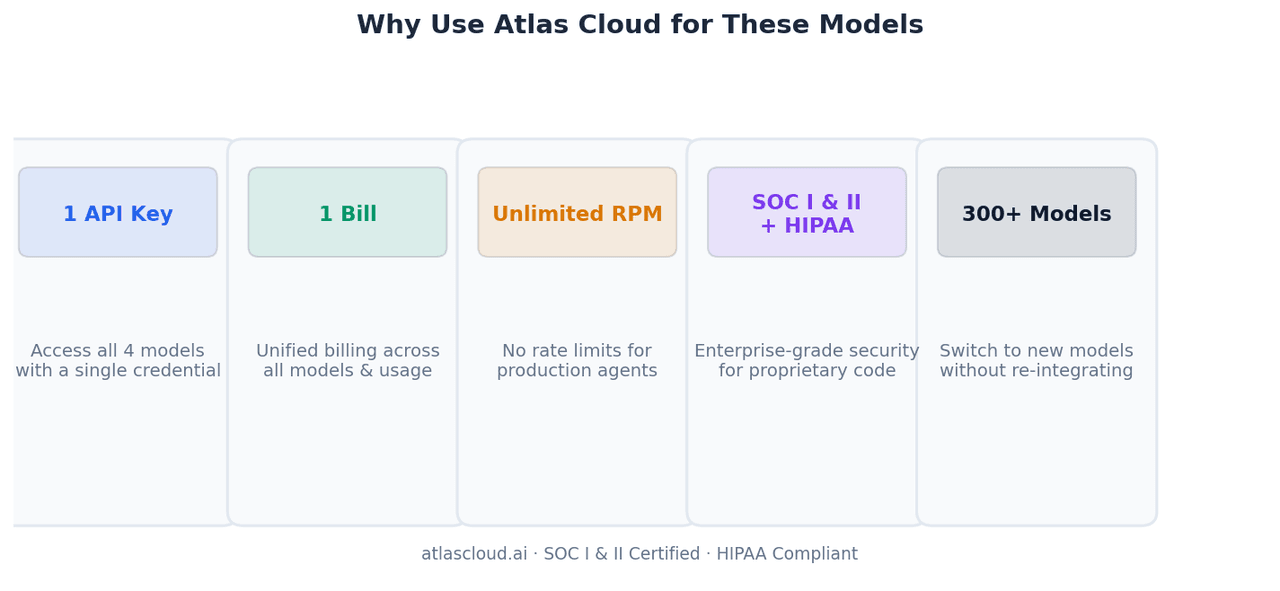
一个 API Key,四款模型,一份账单。 运行模型路由逻辑——将前端任务发送给 GLM-5.1,批量分析发送给 MiniMax M2.7,将长周期代理交给 Kimi K2.6——只需要管理一组凭证,而不是四组。每月结算仅需处理一张发票。
无限 RPM。 生产级编码代理会发起并行工具调用。直接访问提供商 API 的速率限制可能会阻塞多代理流水线,而 Atlas Cloud 移除了这一上限。
SOC I & II 认证,符合 HIPAA 标准。 团队通过这些模型处理专有源代码时需要可审计的基础设施。Atlas Cloud 的合规认证意味着你的代码不会经过未经审计的端点。
300+ 模型,统一集成模式。 当这些模型的后续版本发布,或者有新模型在你的特定工作负载上表现优异时,将其添加到路由逻辑中仅需修改一个字符串,无需进行新的 SDK 集成。
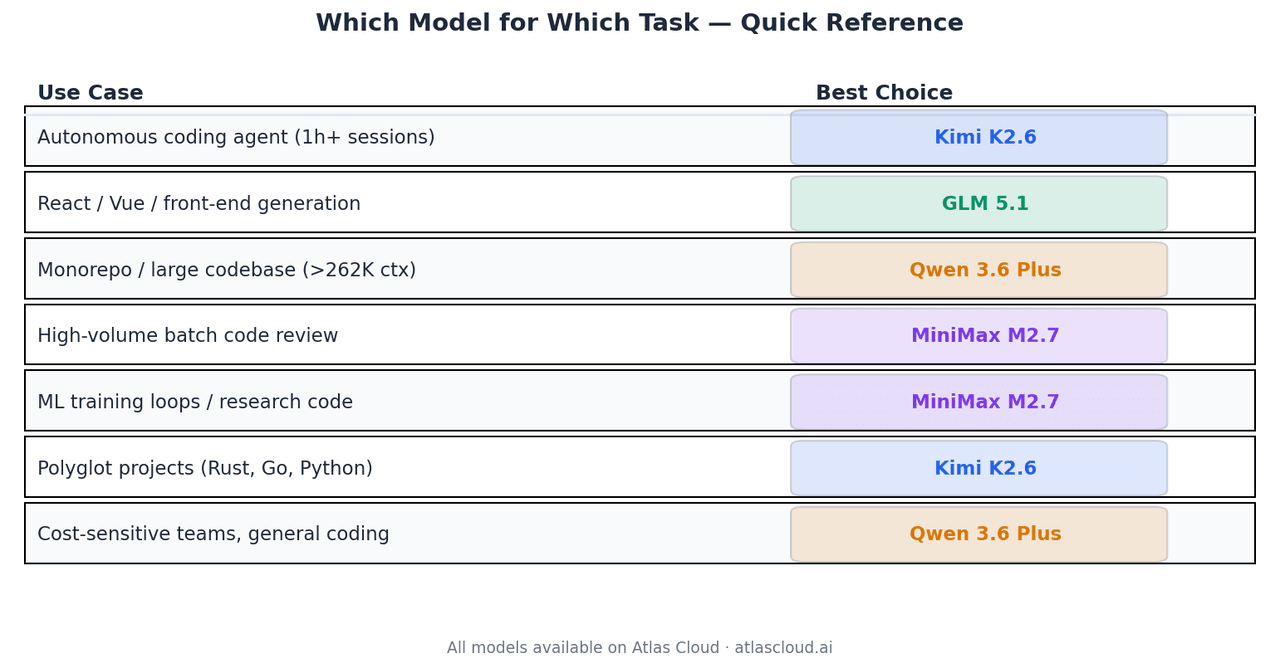
任务与模型匹配指南
| 使用场景 | 最佳选择 | 原因 |
|---|---|---|
| 自主编码代理,1 小时以上会话 | Kimi K2.6 | Terminal-Bench 2.0 66.7% 得分,4K+ 次调用稳定性 |
| React / Vue / 前端生成 | GLM 5.1 | Code Arena Elo 1,530,全球代理型 Web 开发前三 |
| 单体仓库或大型代码库分析 | Qwen 3.6 Plus | 本组中唯一支持 1M 上下文窗口的模型 |
| 大批量代码审查 | MiniMax M2.7 | USD0.30/M 输入成本,94% 的 GLM-5.1 质量 |
| ML 训练循环、研究代码 | MiniMax M2.7 | 66.6% MLE-Bench Lite 奖牌率 |
| 多语言项目 (Rust, Go, Python) | Kimi K2.6 | 经验证的跨语言泛化能力 |
| 成本敏感型团队,通用编码 | Qwen 3.6 Plus | USD0.325/M 输入成本,各领域性能均衡 |
总结
这四款模型在标准基准测试中的差距很小。真正意义上的差异取决于特定的使用场景。
Kimi K2.6 是长周期自主代理的最佳选择。GLM 5.1 在前端代理任务中处于领先地位。Qwen 3.6 Plus 是上下文需求超过 262K Token 时的唯一选择。MiniMax M2.7 则是需要规模化运行编码模型时,高性价比的默认选项。
所有四款模型均可在 Atlas Cloud 上通过 atlascloud.ai 以单一 API Key 调用,采用按量计费模式,无最低使用承诺。
基准测试数据来源:Moonshot AI 技术博客、智谱 AI 开发者文档、阿里巴巴 Qwen 团队发布说明、MiniMax 官方模型页面以及 Arena.ai 独立评测。所有基准测试均为 2026 年 4 月数据。Atlas Cloud 价格以发布时为准,部署前请核对最新费率。






