
几个月前,我们给自己定下了一个看似简单却极具挑战的目标:在单张 GPU 上,于一分钟内生成时长超过 15 秒、质量高且连贯的视频。像 Wan2.2 这样的现今视频扩散模型在生成 3-5 秒短片方面表现优异,但要将其扩展到 10 秒、30 秒甚至一分钟,问题就变得复杂起来。
本文记录了我们实际采取的路径。我们调研了近期论文和技术报告中提出的六种方法——TTT、LoL、Self Forcing、Self Forcing++、Infinite Talk 和 Helios,评估了它们各自的权衡,最终选择了 SVI(Stable Video Infinity),并将其整合进我们 DiffSynth Engine 中的 TurboWan 模型里。我们将逐一介绍这些路径,随后阐述 SVI 的工作原理,最后给出生产数据。
为什么长视频生成很难
一旦时长超过五秒,三个核心瓶颈就会显现。
显存(VRAM)墙
Wan2.2 使用全注意力机制(Full Attention),其计算成本随潜在空间 token 数量呈 O(n²) 增长。数学逻辑非常残酷:
5秒 (81帧): 约 3.27 万 tokens,注意力矩阵约 10 GB。
10秒 (165帧): 约 6.55 万 tokens,注意力矩阵约 40 GB —— 已经超出了单张 GPU 的处理能力。
30秒 (约500帧): 约 20 万 tokens,根本不可行。
实际上,仅 Self Forcing 一项,在 165 帧时仅 KV 缓存就会占满 H200 的 129 GB 显存。
时间轴漂移(Temporal drift)
即使显存足够,也会出现三种漂移现象(Helios 论文中将其定义为):位置偏移(主体在画面中乱跑)、色彩偏移(色调和亮度逐渐变化)以及还原偏移(模型过度纠正导致可见的不连续性)。
因果一致性(Causal consistency)
标准视频扩散模型使用双向全注意力机制,即每一帧都要关注所有其他帧。这意味着无法进行流式输出:在第 N 帧生成完毕前,你无法展示第 1 帧。
我们设定的具体目标很务实:≥15 秒视频,视觉连续流畅,主体在整个片段中保持稳定,总等待时间小于 60 秒,训练需求最小化,并且优先复用已有的权重。
调研结果
我们调研了六个系列的方案。名称大多来自论文标题;分类逻辑后续会用到。
路径 1 · TTT (测试时训练)
论文:One-Minute Video Generation with Test-Time Training (arXiv 2504.05298, 2025年4月)。
核心思路是在推理期间对模型进行微调,使其记住已生成的内容。在每个 Transformer 模块的注意力层后插入一个小型 TTT 层(2 层 MLP,加上门控和局部注意力),并通过从短片段扩展到全长一分钟的课程训练进行优化。
每模块插入: 在标准注意力层后,拼接一个门控(Gate)、TTT 层、局部注意力层,以及 LayerNorm。
课程学习: 按渐进式窗口长度进行训练 —— 3s → 9s → 18s → 30s → 60s。
成本: 256 张 H100 训练约 50 小时。
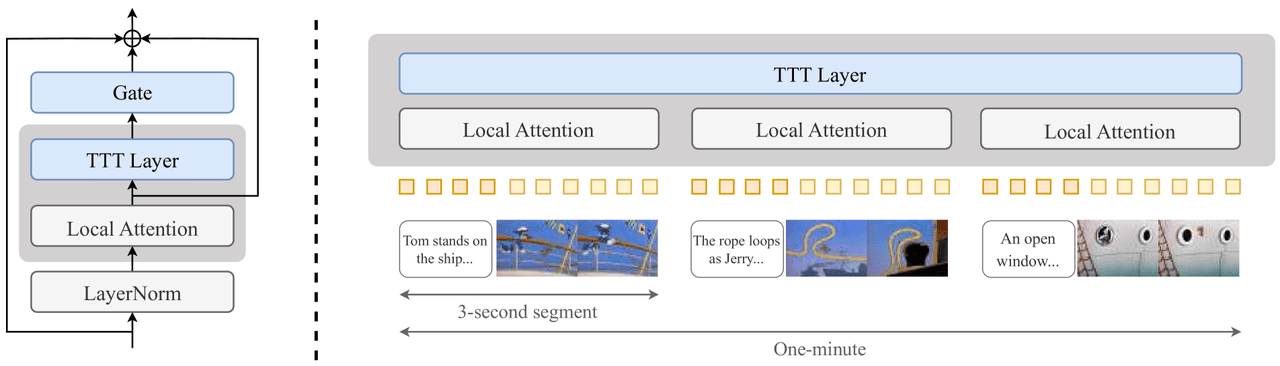
TTT — 左:插入点(Gate + TTT Layer + Local Attention + LayerNorm,通过残差连接在标准注意力层后)。右:视频被分段为 3 秒片段,各片段由内部局部注意力处理,TTT 层负责在片段间携带全局记忆。
该方法可行,论文实现了 1 分钟生成。但训练成本极高,实验仅针对 CogVideoX 5B(迁移到 Wan2.2 14B 的效果未经验证),且插入的 TTT 层与我们依赖的内核优化相冲突。结论:不予采纳。
路径 2 · LoL (Longer than Longer)
论文:LoL: Longer than Longer, Scaling Video Generation to Hour (arXiv 2601.16914, 2026年1月)。
LoL 针对自回归长视频中的特定故障模式——汇聚崩溃(sink-collapse),即多头注意力全部收敛于锚帧,导致视频周期性退回到初始状态。解决方案是多头 RoPE 抖动(Multi-Head RoPE Jitter):对每个头进行小的随机相位扰动,以打破头间的同质性。无需训练,即插即用。
故障模式: 汇聚崩溃 —— 在自回归 RoPE 下,远端帧的位置相位会周期性地与锚帧重合,注意力过于集中,导致内容回弹至锚帧。
修复方案: 给每个注意力头分配其独特的随机相位偏移。头将无法再塌陷到同一列。无需重新训练,可直接嵌入现有模型。
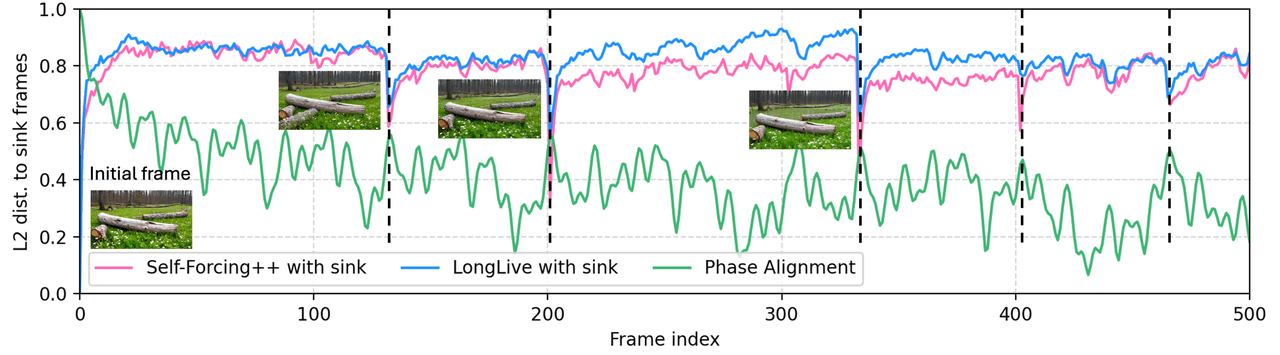
距离锚点的 L2 距离 vs 帧索引。Self-Forcing++ (红) 和 LongLive (蓝) 均出现汇聚,在特定帧位置反复回弹,这些就是视频退回锚帧的崩溃事件。LoL 的相位对齐 (绿) 消除了回弹。
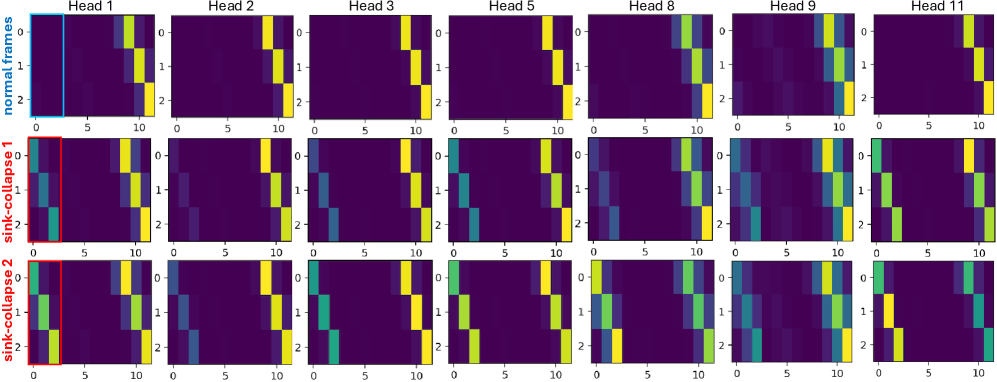
多头注意力图。上行:正常帧 —— 各头模式明显不同。下行:汇聚崩溃期间 —— 每个头看起来都一样,全都集中在锚帧列上。RoPE Jitter 恢复了头间的多样性。
LoL 在 CogVideoX/HunyuanVideo 上实现了 12 小时的视频生成,质量损失很小。问题在于所有演示都是静态场景;我们不确定它在舞蹈、体育或强运动场景下的表现。此外,我们需要修改 Wan2.2 的注意力机制。结论:对于未经证实的效果,适配成本过高。不予采纳。
路径 3 · Self Forcing (Causal Wan2.2)
论文:Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (arXiv 2506.08009, NeurIPS 2025 Spotlight)。
Self Forcing 将 Wan2.2 的双向全注意力机制替换为因果注意力(causal attention):每一帧只关注其之前的帧。这一改动解锁了流式生成——当第一个分段完成,即可立即解码输出。
双向: 每一帧关注所有帧 → 必须完成全部 40 步去噪才能展示任何一帧。因果: 帧只看到过去 → 第一个分段完成后即可流式传输。
该论文的训练技巧在于:不是在干净的真值上下文中训练(教师强制),也不是使用自定义注意力掩码(扩散强制),而是通过带有循环 KV 缓存的实际推理路径进行训练,使训练与推理分布完全匹配。
生成循环: 使用 DMD 的压缩步长计划去噪下一小段帧,并以已生成帧构建的循环 KV 缓存为条件。
流式传输: 一旦片段完成,即刻进行 VAE 解码并输出。
承接: 将新片段的潜在表示推入 KV 缓存,供下一个片段关注。
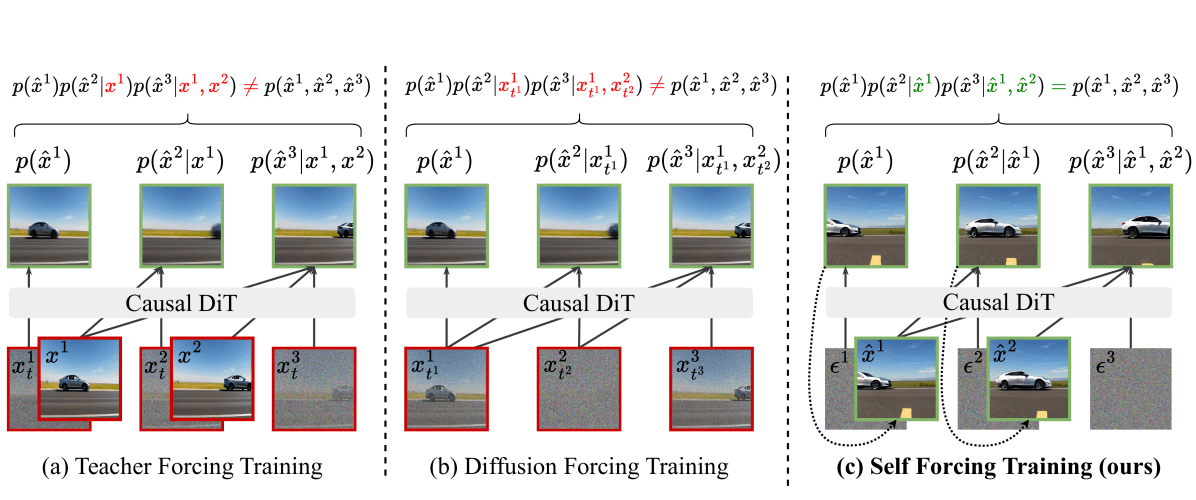
三种训练范式对比:(a) 教师强制在干净帧上训练,推理时噪声帧导致分布外漂移;(b) 扩散强制使用自定义注意力掩码,仍存在训练/推理不匹配;(c) Self Forcing 通过循环 KV 缓存重演真实的推理过程,完全对齐。
我们在 FastVideo 框架下,使用单张 H200 进行测算:
| 长度 | 帧数 | 耗时 | 显存 (VRAM) |
|---|---|---|---|
| 5s | 81 帧 | 70s | — |
| 10s | 165 帧 | 168s | 129 GB (近满载) |
| 20s | 321 帧 | 287s | 129 GB (KV 缓存限 42 帧) |
这是架构上最优雅的方案,我们非常认可。但 10 秒已填满 H200 显存,165 帧时质量下降,原始模型需要针对因果注意力进行微调,且真正的流式传输还需要 VAE 支持因果 Conv3D。
结论:等待社区解决显存和质量问题,目前暂不采用。
路径 4 · Self Forcing++
论文:Self-Forcing++: Towards Minute-Scale High-Quality Video Generation (arXiv 2510.02283, 2025年10月)。
在 Self Forcing 基础上增加了三个功能:向后噪声初始化(Backward Noise Initialization)(每个新片段从已生成帧反向集成的噪声开始,消除边界不连续性)、扩展 DMD 对齐(从长序列中切分 5 秒窗口并与教师模型的短窗口输出对齐)、以及使用光流奖励的 GRPO 阶段,以推动更具活力的运动。
第一步: 对学生模型进行长于 5 秒的自循环训练,利用循环 KV 缓存积累长草稿。第二步: 从草稿中随机切分 5 秒窗口,通过扩展 DMD 与教师的短窗口分布进行对齐。第三步: 使用光流幅度作为奖励进行 GRPO 精调,促使模型产生更多动态运动。技巧: 每个新片段从上一片段反向集成的噪声开始,而不是新鲜的高斯噪声 —— 因此不再出现片段边界跳变。
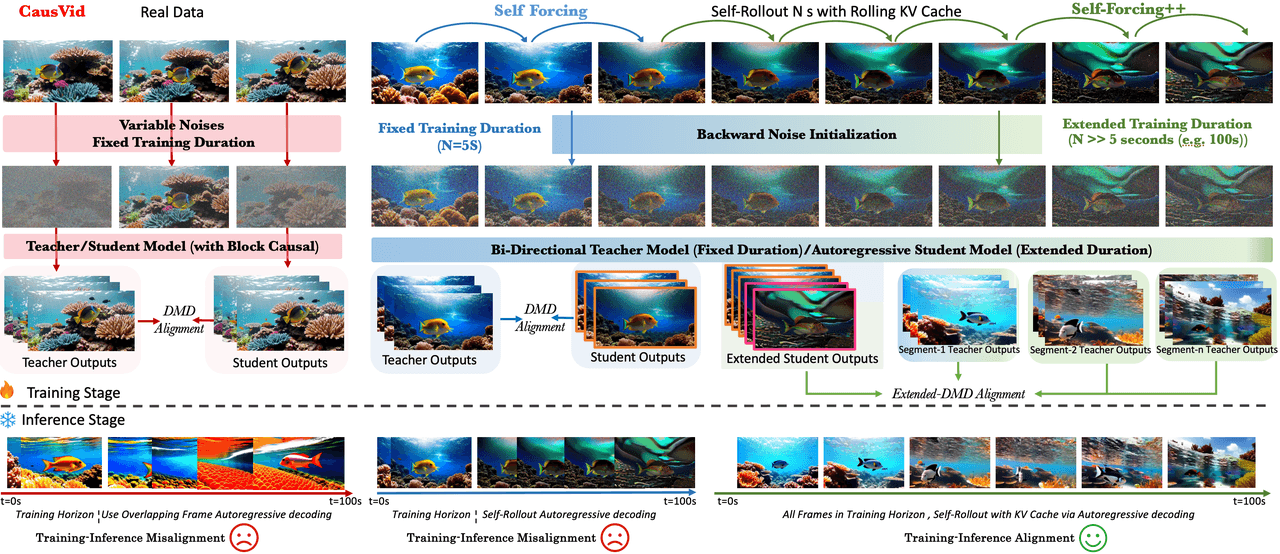
左至右:CausVid (固定时长,训练/推理不匹配) → Self Forcing (固定时长 + DMD 对齐) → Self-Forcing++ (扩展时长 + 向后噪声初始化 + 扩展 DMD 对齐)。下行展示了训练阶段和推理阶段的对应关系。
结果:在 1.3B Wan2.1 上实现了分钟级视频(最长约 4 分 15 秒)。非常好的论文。但在生产中我们遇到了两个阻碍:内容多为静态(运动幅度低),且基础模型仅为 1.3B(远低于 Wan2.2 14B),且没有开源代码或权重可供引导。结论:目前暂不采用。
路径 5 · Infinite Talk (A2V)
这是一个完全不同层面的问题——音视频生成(Audio-to-Video),通过音频驱动持续的数字人说话。
每片段输入捆绑: 新片段的噪声潜在表示、该时间窗口的音频特征、用户提供的参考图像、前一片段的最后一帧,以及软条件权重。参考身份: 参考图像保持长期的外观稳定。自适应约束: 软权重根据相似度漂移收紧或放松参考限制。运动桥梁: 上一段的最后一帧承接边界处的运动。
对于特定的数字人说话场景非常出色,效果持久。但其架构与 Wan2.2 差异较大,需要专项训练,且无法泛化到一般场景。结论:在特定垂直领域有价值,非通用长视频方案。
路径 6 · Helios
论文:Helios: Real Real-Time Long Video Generation Model (PKU-YuanGroup, arXiv 2603.04379, 2026年3月)。
撰写本文时,Helios 是长视频领域的 SOTA —— 14B 参数,在单张 H100 上实现 19.5 FPS 的实时性。其技巧在于将历史帧压缩为三层金字塔,并注入到当前帧的去噪过程中,使 token 预算无论视频多长都保持恒定。
多项记忆: 短期历史(最后 3 帧)保持全分辨率;中期(最后 20 帧)适度压缩;长期(之前所有内容)进行重度压缩。总 token 预算恒定。引导注意力: 在每个 DiT 块内,干净的历史 KV 与嘈杂的当前 QKV 分开处理,确保历史噪声不会污染当前去噪。金字塔采样: 先在低分辨率采样以定义结构,再细化至高分辨率增加细节 —— 总体 token 数量减少约 2.3 倍。
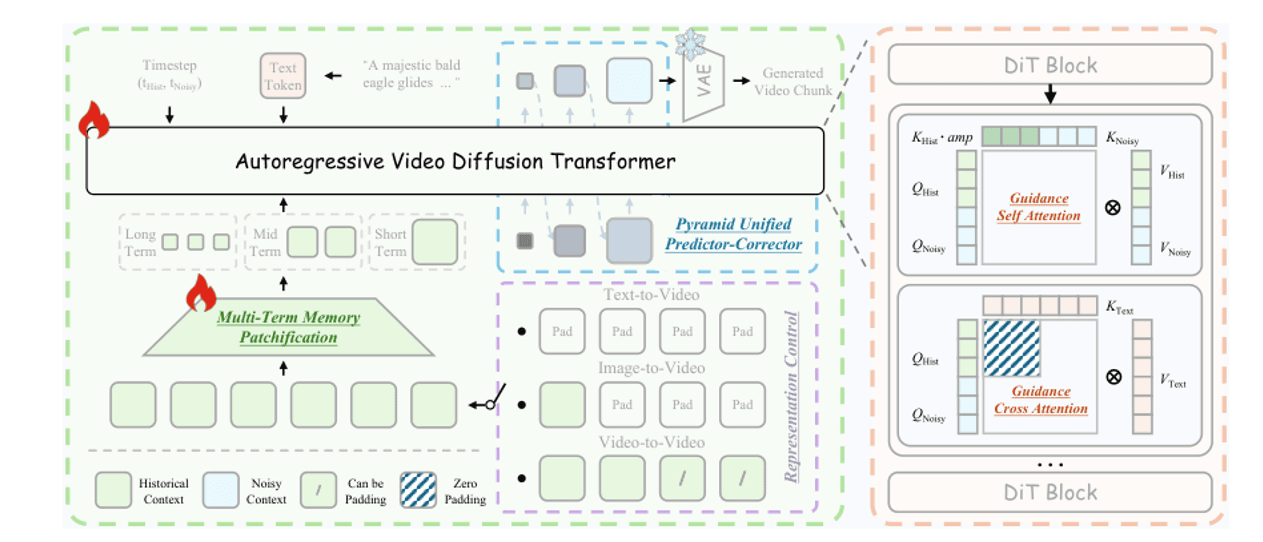
Helios 架构。左:统一历史注入 — 短/中/长期历史以不同比率压缩,在进入 DiT 前与当前帧拼接。右:金字塔统一预测-校正 — 先低 token 数定义结构,后高 token 数细化细节,计算量减少约 2.3 倍。

Helios 论文系统定义并可视化了长视频生成中的三种漂移类别:(a) 位置偏移,(b) 色彩偏移,(c) 还原偏移(噪声),(d) 还原偏移(模糊)。引导注意力专为此类漂移设计。
Helios 在 H200 上的吞吐量表现惊人——随长度几乎平滑:
| 长度 | 耗时 | 吞吐量 |
|---|---|---|
| 240 帧 (10s) | 24s | 约 10 FPS |
| 480 帧 (20s) | 42s | 约 11.4 FPS |
| 960 帧 (40s) | 82s | 约 11.7 FPS |
| H100 单卡 (Helios-Distilled) | — | 19.5 FPS |
问题在于多项记忆补丁(Multi-Term Memory Patchification)需要对 14B 模型进行全面重训。目前没有开源权重,仅有技术报告,我们无法直接加装 LoRA。结论:这是中长期方向,但当前无法落地。
路线比较总结
将全部六种路径横向对比,加上我们最终选定的 SVI:
| 方案 | 最大时长 | 质量 | 是否需训练 | 工程难度 | 泛化性 | 推荐指数 |
|---|---|---|---|---|---|---|
| TTT | 1 分钟 | 高 | 需重度训练 | 高 | 中 | ★★☆ |
| LoL | 小时级 | 中 (仅限静态) | 需训练 | 中 | 中 | ★★☆ |
| Self Forcing | 理论无限 | 中 (10s后下降) | 现有模型 | 高 (显存问题) | 高 | ★★★ |
| Self Forcing++ | 分钟级 | 低 (多为静态) | 需训练 | 极高 (无代码) | 高 | ★☆☆ |
| Infinite Talk | 无限 | 高 (仅数字人) | 需训练 | 高 | 低 (仅 A2V) | ★★☆ |
| Helios | 理论无限 | 高 (行业 SOTA) | 全面重训 | 极高 (无权重) | 高 | ★★★☆ |
| SVI | 无限 | 中-高 | 开源 LoRA | 中 | 高 | ★★★★ |
调研总结出的分类法
仔细观察,我们调研的所有方案都可以分为三类:
A 类 — 扩展注意力范围本身 (Self Forcing, LoL, TTT)。让模型直接处理更长的序列。理论质量最高。由于显存呈平方级增长,目前工程上在 10 秒左右触及天花板。
B 类 — 分层历史压缩 (Helios)。压缩过去帧并作为条件注入。绕过了显存限制。成本是一次对 14B 模型的全面重训。
C 类 — 状态化滚动生成 (SVI, Infinite Talk)。将长视频拆分为带有重叠状态的短片段。显存恒定,长度无限,仅需 LoRA 训练。代价是片段边界处可能出现不连续性,以及无法完全消除的长程漂移。
本季度我们选择了 C 类方案。明年,我们将持续关注 B 类技术文献的进展。
下一篇文中,我们将分享实际的落地细节 —— 针对 ≥15 秒视频生成的六种方法尝试,我们为何最终选择 SVI,以及生产环境的数据表现。阅读第 2 部分 →






