
在第1部分中,我们调研了长视频生成的六种方法——TTT、LoL、Self Forcing、Self Forcing++、Infinite Talk 和 Helios,并最终确定 SVI 是目前唯一无需对 14B 模型进行重训练即可落地的路径。本文将探讨其实际构建过程:剪辑拼接循环如何运作、为什么“错误循环(Error-Recycling)”至关重要,以及我们在 TurboWan 上首次部署的生产数据。
选择:SVI (Stable Video Infinity)
SVI 的核心理念是将无限长度的生成转化为有限数量短视频剪辑的拼接,并辅以精心设计的内存传输。这听起来很简单,但它能同时解决大部分工程痛点:无需基础模型重训练(仅需在 TurboWan 上挂载一个小型 LoRA)、恒定的显存占用、可与现有的速度蒸馏技术结合,且官方 LoRA 权重已公开。
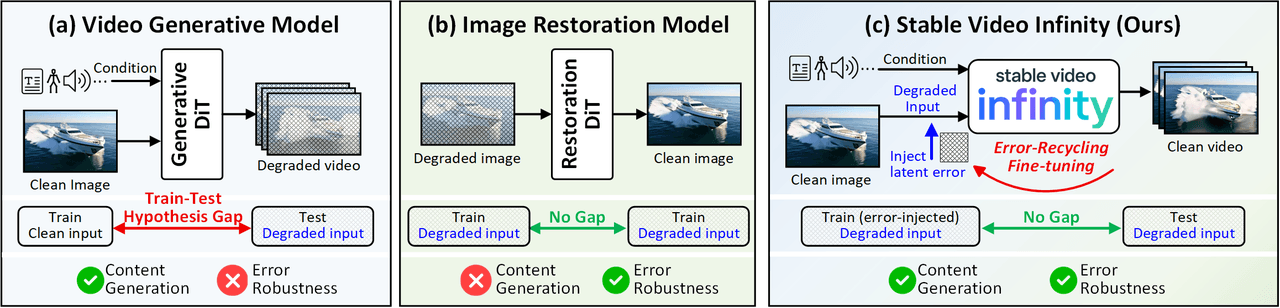
SVI 的思维模型。(a) 标准视频生成模型存在“训练-测试假设偏差”,即在训练时使用干净的输入,但在推理时面临充满噪点和误差累积的输入。(b) 图像修复模型对误差具有鲁棒性,但无法生成新内容。(c) SVI 的“错误循环微调(Error-Recycling Fine-Tuning)”弥合了两者——利用自生成的错误作为监督信号,使模型主动学习识别并修正自身的生成错误。
剪辑拼接的原理
每个剪辑为 81 帧(5秒 @ 16fps)。生成过程是一个循环:以前一个剪辑的全局身份锚点和短期运动桥接作为下一个剪辑的条件,然后进行拼接。
剪辑 1: 输入:参考图像 + 空的运动内存。输出:5秒剪辑。提取运动内存:最后 4 帧的潜空间(latent)。剪辑 2: 输入:参考图像 + 来自剪辑 1 的运动内存。输出:5秒剪辑。从其尾部提取运动内存。…… 对 N 个剪辑重复此过程,然后将剪辑 1 + 剪辑 2 + … + 剪辑 N 拼接成长视频。
其精妙之处在于无需修改 DiT 注意力机制。历史上下文在输入层面以潜空间形式拼接,并通过一个小型 LoRA 教会模型如何实际利用这些前缀。
锚点潜空间: 用户提供的参考图像,经 VAE 编码 → 保持主体/角色外观的全局一致性。运动潜空间: 前一个剪辑最后 4/8/12 帧的潜空间 → 告知模型上一个片段是如何结束的。填充: 对齐输入形状,使 DiT 看到一个规整的拼接序列:锚点 + 运动 + 填充。
错误循环微调(Error-Recycling Fine-Tuning)
SVI 能在多个剪辑中保持稳定的关键在于其 LoRA 的训练方式。标准推理总是从纯高斯噪声开始去噪,但在长视频拼接中,早期剪辑的错误会污染后续剪辑的条件。如果只使用干净的参考输入进行训练,就等于埋下了“训练-推理偏差”。
标准训练: 每个剪辑的参考输入都是干净的真值(Ground Truth)→ 模型从未见过推理时实际面临的带有噪声的历史上下文,导致不连续性累积。
错误循环(Error-Recycling): 在训练期间,有意将模型自身的过去错误注入到参考输入中,使 LoRA 显式学习处理带有噪声的历史上下文。剪辑边界处的视觉不连续性显著下降。
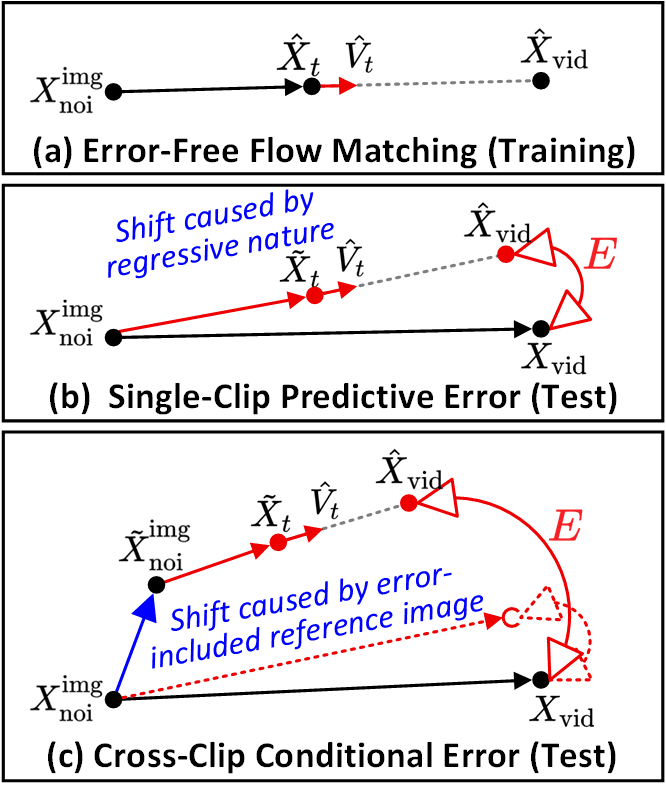
SVI 识别出两种核心错误类型。(a) 无错误流匹配是训练时的轨迹。(b) 单剪辑预测误差——去噪路径与理想轨迹之间的每剪辑偏差。(c) 跨剪辑条件误差——被错误污染的参考图像导致跨剪辑的级联漂移。错误循环机制明确注入了这两类误差。
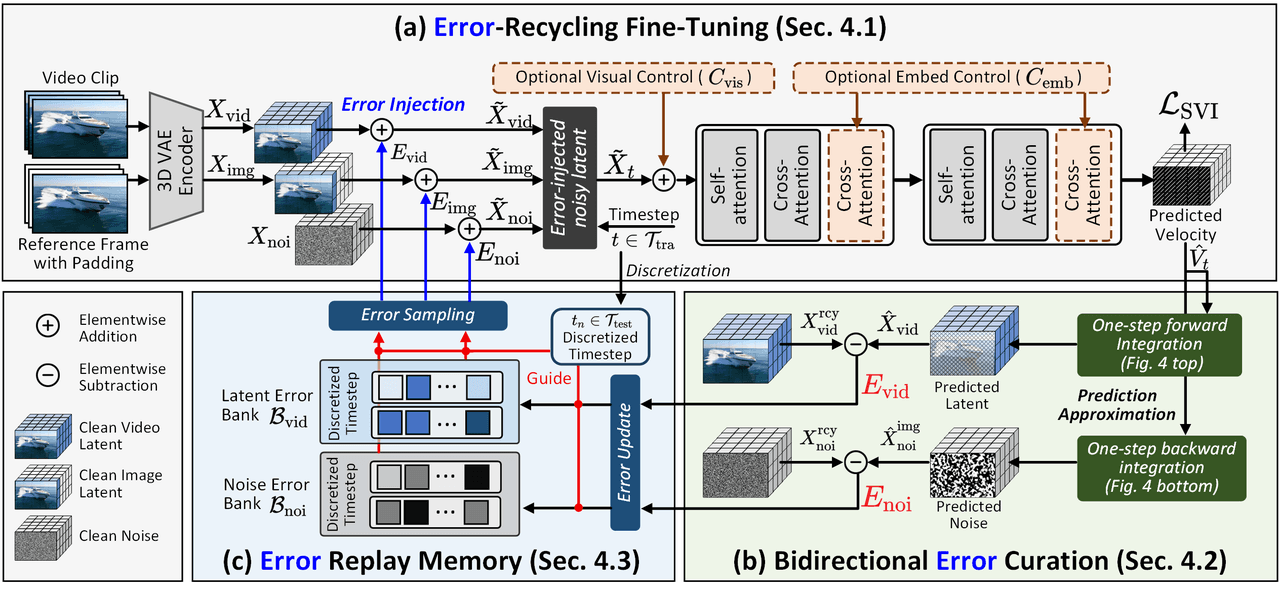
SVI 训练框架。(a) 将 DiT 自生成的错误注入潜空间,打破无错误假设。(b) 通过一步前向/后向积分高效计算双向误差。(c) 将错误存储在重放内存(Replay Memory)中并动态重采样复用,形成闭环的错误监督循环。
SVI 区分了两种错误类型。_单剪辑预测误差_是去噪路径与理想轨迹之间的每剪辑漂移;_跨剪辑条件误差_是当错误污染的参考图像流入下一个剪辑时引发的级联漂移。错误循环注入了两者,从而使 LoRA 学习到显式的容错能力。
LoRA 变体
SVI 推出了三种变体——SVI-Shot(用于静态图像到短剪辑)、SVI-Dance(用于人体动作,也可接收姿态序列输入)和 SVI-Film(用于多镜头/场景转换的长视频)。超参数:每个剪辑 81 帧,运动帧数 num_motion_frames ∈ {4, 8, 12},LoRA 秩(rank)通常为 16–64。
在 TurboWan 上的堆叠
我们将 SVI 的 LoRA 挂载在 TurboWan(由 Atlas 优化的加速版 Wan)之上,并在堆栈中保留我们专门的 LoRA 来控制风格。在推理时,多个 LoRA 权重同时叠加。
基座: TurboWan LoRA 1: 专用 LoRA — 内容/风格控制。LoRA 2: SVI LoRA — 长视频一致性。组合: TurboWan 的速度 + SVI 的长视频连续性 + 风格化,一次推理流程完成。
完整的推理流程很直观:将参考图编码为锚点潜空间,与前一个剪辑的运动潜空间和填充拼接,运行 TurboWan 去噪,解码,追加,并根据新生成剪辑的尾部更新运动潜空间。在 N 次迭代后,将所有片段拼接成一个视频。
1. 将参考图像编码为锚点潜空间。 2. y = concat(锚点潜空间, 运动潜空间, 填充)。 3. 在 y 和文本嵌入的条件下,运行 TurboWan 的 5 步去噪。 4. VAE 解码剪辑并追加到输出列表。 5. 设置运动潜空间 = 刚生成的剪辑的尾部(最后 num_motion_frames 帧)。 6. 重复 N 次剪辑,然后将它们全部拼接。
生产数据
标准测试:单张参考图 + 3 条提示词,生成约 15 秒的输出(3 个 5 秒剪辑):
| 指标 | 数值 |
|---|---|
| 生成时长 | 15秒 (3个剪辑) |
| 单剪辑推理时间 | ~14秒 (TurboWan fp8, 单 GPU) |
| 总推理时间 | ~42秒 |
| 主体一致性 | 良好 |
工作示例:猫咪大冒险
为了具体展示跨剪辑表现,我们运行了一个 15 秒的案例,包含一个参考图和三个镜头。风格提示词设定为皮克斯风格,暖色调照明;角色是一只大眼睛、充满好奇心的橙色虎斑小猫;三个镜头分别展示了它从窗台到人行道,再到遇见金毛寻回犬的过程,每个镜头都有各自的摄像机运镜。

剪辑 1 (0–5秒):窗台上橙色的皮克斯小猫,摄像机缓慢从特写拉远。风格和角色在各帧间保持稳定。

剪辑 2 (5–10秒) 转换边界:小猫的外观与剪辑 1 匹配,随后在跳下时转动并变换姿态。运动潜空间跨边界保持了运动状态。

剪辑 3 (10–15秒):引入了一只金毛寻回犬,场景向室内/室外边界转换。小猫的皮克斯风格在所有三个剪辑中保持稳定。
本次运行的汇总指标:
| 指标 | 数值 |
|---|---|
| 总时长 | 15秒 (3个剪辑 × 5秒) |
| 总帧数 | 240帧 (16fps) |
| 总推理时间 | 33秒 (TurboWan, 单 GPU) |
| 视频生成耗时比 | 2.2 秒/秒 |
| 主体一致性 | 皮克斯橙色小猫全程稳定 |
| 剪辑边界不连续性 | 无明显跳帧 |
这就是在单 GPU 上,在 33 秒内完成的 15 秒长视频,并具备跨剪辑的主体一致性——远低于我们设定的 60 秒等待目标。在包含 14 个案例的内部测试集中,9 个案例没有出现明显问题(64% 的通过率)。
最后必须诚实地说,在视频生成领域,速度、长度和质量是“不可能三角”的三个顶点。目前还没有任何一种方法能同时在三者上领先。有趣的工作在于,基于现有的硬件和训练预算,抉择出你可以牺牲最少的那一个维度。SVI 在长度和边界质量上做出了一点妥协,换取了今天就能在单 GPU 上实现 Wan2.2 级别保真度的长视频生成能力。






