Seedance 1.5 Pro is now available on Atlas Cloud: Enhanced Synchronization and Control for Generative Video
Discover Seedance 1.5 Pro, the revolutionary AI video generation model from ByteDance, now officially launching on the Atlas Cloud platform with a powerful API for developers.
Seedance 1.5 Pro Price Snapshot:
| Model | Price |
|---|---|
| Seedance 1.5 Pro Text-to-Video | $0.0867/SEC |
| Seedance 1.5 Pro Image-to-Video | $0.0867/SEC |
Introduction of Seedance 1.5 Pro
Marking a significant evolution from Seedance 1.0, ByteDance's Seedance 1.5 Pro introduces V2A native generation for seamless, synced audio-visual output, designed to maximize professional video creation efficiency.
Core Features & Capabilities of Seedance 1.5 Pro
Audio-Visual Synchronization
This update prioritizes the alignment between auditory inputs and visual outputs, ensuring technical consistency throughout the video duration.
- Precision Lip-Syncing: The model utilizes millisecond-level timing to map mouth movements to speech patterns. This reduces the "dubbing effect" often seen in generative video where lip flaps do not match the spoken phonemes.
- Integrated Soundscapes: The generation process includes environmental sounds, action-based audio cues, background music, and vocals alongside the visual stream.
- Temporal Emotional Alignment: The model analyzes the tone and cadence of the input audio to adjust the character’s visual emotional expressions, ensuring the facial performance corresponds to the delivery of the line.
Comparative Analysis: In many current video generation models, audio is generated separately or loosely coupled, leading to drift over long clips. Seedance 1.5 Pro integrates these modalities, effectively reducing the need for manual re-timing or ADR (Automated Dialogue Replacement) in post-production.
Multi-Speaker Narrative and Multilingual Support
Seedance 1.5 Pro expands generation capabilities to support complex interaction scenarios and diverse linguistic requirements.
- Multi-Character Interaction: The system supports scenes involving multiple speakers, maintaining distinct identities and smooth turn-taking between characters.
- Global Language Coverage: The model demonstrates consistent performance across English, Japanese, Korean, Spanish, Indonesian, Portuguese, and Mandarin. It also accounts for regional dialects within these languages.
- Natural Speech Synthesis: The audio engine generates voices that adhere to natural speech patterns, preserving character consistency across different languages.
Practical Context: For multinational corporations, this feature facilitates the creation of localized training materials or marketing assets. A single video concept can be generated in multiple languages with correct lip-syncing for each region, removing the requirement to hire separate voice actors for every target market.
Directorial Control and Prompt Adherence
This version improves the user's ability to dictate specific visual outcomes through text prompts, moving away from stochastic or random generation.
- Camera Movement Control: Users can specify cinematic techniques such as panning, zooming, tracking shots, and varying motion speeds with predictable results.
- Action Fidelity: The model adheres strictly to prompts describing specific character actions, movements, or interactions with objects.
- Scene Composition: Users retain control over shot layout, timing, and pacing. The system also supports integrated visual effects within the generation process.
Comparative Analysis: Standard generative models frequently disregard complex instruction sets, resulting in "hallucinated" camera angles or incorrect actions. Seedance 1.5 Pro functions as a reliable visualization tool, allowing storyboard artists and directors to plan scenes accurately before physical production.
Visual Fidelity and Stability
The rendering engine in Seedance 1.5 Pro focuses on maintaining high resolution and structural integrity suitable for professional display.
- Texture and Detail: The output mimics live-action footage by maintaining clean textures and reducing digital artifacts.
- Lighting and Composition: The model applies professional-grade color handling and stable lighting physics, preventing illogical shadow placement.
- Temporal Consistency: The video quality remains constant across distinct scenes and longer durations, avoiding the degradation or morphing often observed in extended generative clips.
Practical Context: Previous iterations of AI video often suffered from flickering backgrounds or warping objects. The stability offered here allows the footage to be used in commercial broadcasting or high-definition presentations where visual errors are easily noticeable.
Application of Seedance 1.5 Pro
Corporate Localization
- Scenario: A global software company needs to release a product update video in seven languages simultaneously.
- Application: Using the multilingual support and lip-syncing features, the team generates a single avatar presentation. They input scripts in Spanish, Mandarin, and English. The model generates distinct video files where the avatar’s lip movements match each language perfectly, ensuring a native viewing experience for all regions.
Here is a case to test its multilingual ability, Click to see the video.
Film Pre-Visualization (Pre-vis)
- Scenario: A director wants to visualize a complex tracking shot involving two actors arguing in a moving vehicle.
- Application: Utilizing the camera control and emotional alignment features, the production team inputs the script and camera motion prompts. Seedance 1.5 Pro generates a rough cut of the scene, allowing the cinematographer to plan lighting and lens choices based on the AI-generated reference before arriving on set.
Click here to see the output video.
Automated News Broadcasting
- Scenario: A media outlet requires rapid video summaries of breaking news articles.
- Application: The outlet connects their text feed to the Seedance 1.5 Pro API on Atlas Cloud. The model automatically generates a news anchor reading the text with a neutral, professional tone and appropriate background visuals, delivering a ready-to-publish video minutes after the text is finalized.
Click here to see the output video.
Conclusion
Seedance 1.5 Pro offers a structured advancement in generative video, moving from experimental outputs to controlled, production-ready assets. By addressing synchronization, control, and visual stability, it provides a functional tool for creators requiring precision and efficiency.
👇Experience Seedance 1.5 Pro on Atlas Cloud today.👇
Atlas Cloud lets you use Seedance 1.5 Pro first in a playground, then via a single API.
Method 1: Use directly in Atlas Cloud playground
Try Seedance 1.5 Pro in the playground.
Method 2: Access via API
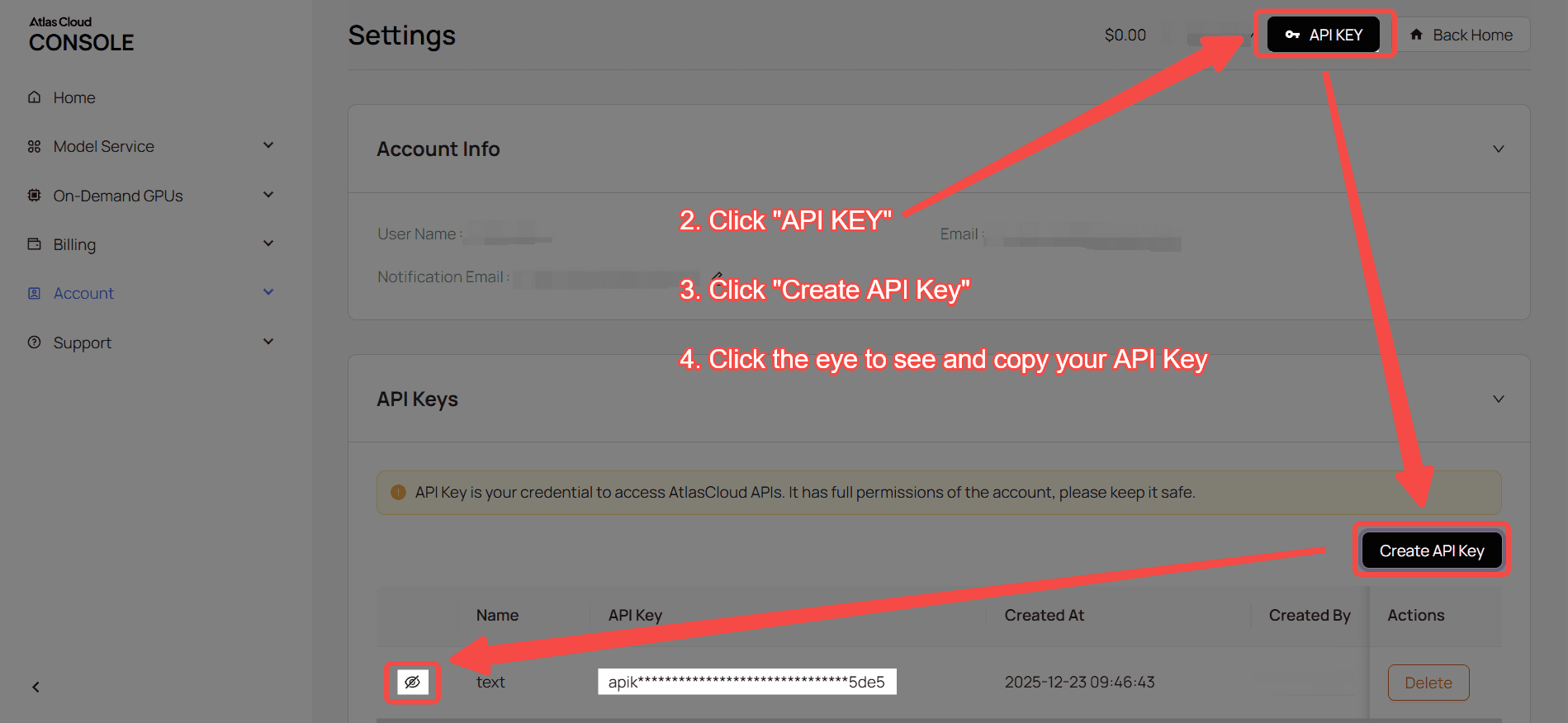
Step 1: Get your API key
Create an API key in your console and copy it for later use.
Step 2: Check the API documentation
Review the endpoint, request parameters, and authentication method in our API docs.
Step 3: Make your first request (Python example)
seedance 1.5 pro text-to-video as example.
plaintext1import requests 2import time 3 4# Step 1: Start video generation 5generate_url = "https://api.atlascloud.ai/api/v1/model/generateVideo" 6headers = { 7 "Content-Type": "application/json", 8 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 9} 10data = { 11 "model": "bytedance/seedance-v1.5-pro/text-to-video", 12 "aspect_ratio": "16:9", 13 "camera_fixed": False, 14 "duration": 5, 15 "generate_audio": True, 16 "prompt": "Shot 1 (establishing): Wide aerial of a quiet coastal cliff at sunrise, low fog rolling over the ocean, golden light breaking through thin clouds. A lone runner appears as a small silhouette on the winding path. Camera: smooth drone-like glide forward, slow and steady, cinematic pacing. Shot 2 (character): Medium tracking shot at ground level beside the runner, shoes crunching gravel, breath visible in the cool air, wind tugging at a lightweight jacket. Camera: gimbal-stable side-tracking, shallow depth of field, keep the runner’s face and jacket details consistent. Shot 3 (emotion): Close-up on the runner’s face—focused eyes, subtle micro-expressions, a quick swallow, determination building. Camera: gentle push-in, soft background bokeh, natural handheld micro-shake kept minimal. Shot 4 (end beat): The runner reaches the cliff overlook and slows to a stop; fog parts to reveal a vast sunlit ocean. The runner exhales and smiles slightly. Camera: slow tilt up from the runner to the horizon, hold for a calm finish. Style: photoreal live-action, natural sunrise lighting, filmic color grading, realistic wind and fabric motion, crisp facial detail. Continuity: same runner, same outfit, consistent sunrise direction and color temperature across shots; avoid warping, duplicate limbs, flicker, jump cuts, text overlays, logos.", 17 "resolution": "720p", 18 "seed": -1 19} 20 21generate_response = requests.post(generate_url, headers=headers, json=data) 22generate_result = generate_response.json() 23prediction_id = generate_result["data"]["id"] 24 25# Step 2: Poll for result 26poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 27 28def check_status(): 29 while True: 30 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 31 result = response.json() 32 33 if result["data"]["status"] in ["completed", "succeeded"]: 34 print("Generated video:", result["data"]["outputs"][0]) 35 return result["data"]["outputs"][0] 36 elif result["data"]["status"] == "failed": 37 raise Exception(result["data"]["error"] or "Generation failed") 38 else: 39 # Still processing, wait 2 seconds 40 time.sleep(2) 41 42video_url = check_status()
FAQ
Q: Which languages and speech formats does the model support?
A: Seedance 1.5 Pro offers native audio-visual joint generation.
- Language Support: It covers seven major languages (English, Mandarin, Japanese, Korean, Spanish, Indonesian, Portuguese) with regional dialect accuracy.
- The Advantage: By integrating voice and visual synthesis, it achieves organic lip-syncing and multi-speaker fluidity that stitching separate tools (like ElevenLabs for TTS) cannot match in a single workflow.
Q: What level of control do users have over camera movement and scene direction?
A: Seedance 1.5 Pro provides granular cinematic control—including pans, zooms, and tracking.
- Precision: It adheres strictly to user prompts for character acting and layout, making it ideal for storyboard planning.
- differentiation: Crucially, it aligns these visual movements with audio pacing, offering a layer of directorial coherence often missing in standard video generation models.
Q: Is the visual output suitable for commercial broadcasting or large screens?
A: Yes. Seedance 1.5 Pro delivers photorealistic quality comparable to OpenAI’s Sora and Kling AI.
- Visual Fidelity: It produces clean textures and professional lighting, minimizing the "flickering" or temporal inconsistencies common in earlier architectures like Stable Video Diffusion (SVD).
- Commercial Use: Its ability to maintain stylistic consistency across long-form content makes it a viable solution for premium brand storytelling and high-stakes presentations.





