
這種感覺你一定很熟悉。
夜深了。你對一個品牌行銷活動已經修改了四輪。AI 剛剛生成了完美的燈光效果,但模特兒的臉卻在今晚第三次發生了細微的變化。衣服一樣,人卻換了。這成品你無法發佈,也沒法修復,只能砍掉重練。
到了午夜,你已經不是在剪輯影片了,而是在玩俄羅斯輪盤。
對於任何試圖建立敘事連續性的人來說——無論是在不同鏡頭中保持同一個模特兒的產品演示、在不同場景中保持同一位講師的教學影片,還是跨鏡頭保持同一位歌手的音樂錄影帶——「角色漂移」(character drift)一直是所有 AI 影片工具的隱形殺手。這就是為什麼 AI 影片一直停留在「新奇展示」的煉獄中,而無法真正走向商業化。

5 月 19 日在 I/O 2026 大會上,Google 的 Gemini Omni 證明了這個時代即將終結。
這項承諾在 Google DeepMind 的產品頁面上濃縮成一句話:「你所做的每一次編輯都建立在前一次的基礎上——從而保持場景的一致性與連貫性。」
那段默默創造歷史的三步驟小提琴手演示
I/O 發布會上最具影響力的時刻不是滾動的彈珠,也不是泡泡雕塑,而是一位小提琴手。
以下是 Google 在舞台上展示並發布在部落格上的確切順序:
- 第一步: 一段小提琴手在舞台上演奏歌曲的基礎影片。
- 第二步: 提示詞——「將小提琴手傳送到影像環境中。」 結果:演奏者被移動到新的背景中,但臉部、姿勢、握弓方式甚至手腕角度都保持完全相同。
- 第三步: 另一個提示詞——「將攝影機角度改為小提琴手的過肩鏡頭。」 結果:新的構圖。同一個小提琴手。同一個身份。同一場演奏。
三個步驟。同一個主角。零漂移。
如果你曾認真使用過現有的 AI 影片工具,這看起來簡直像作弊。但事實並非如此。這是第一次公開證明,「多輪微調」(multi-turn refinement)——電影製作人、廣告商和教育工作者一直在等待的工作流程——在技術上是真實且可行的。
為什麼「多輪一致性」一直是 AI 影片的難解之痛
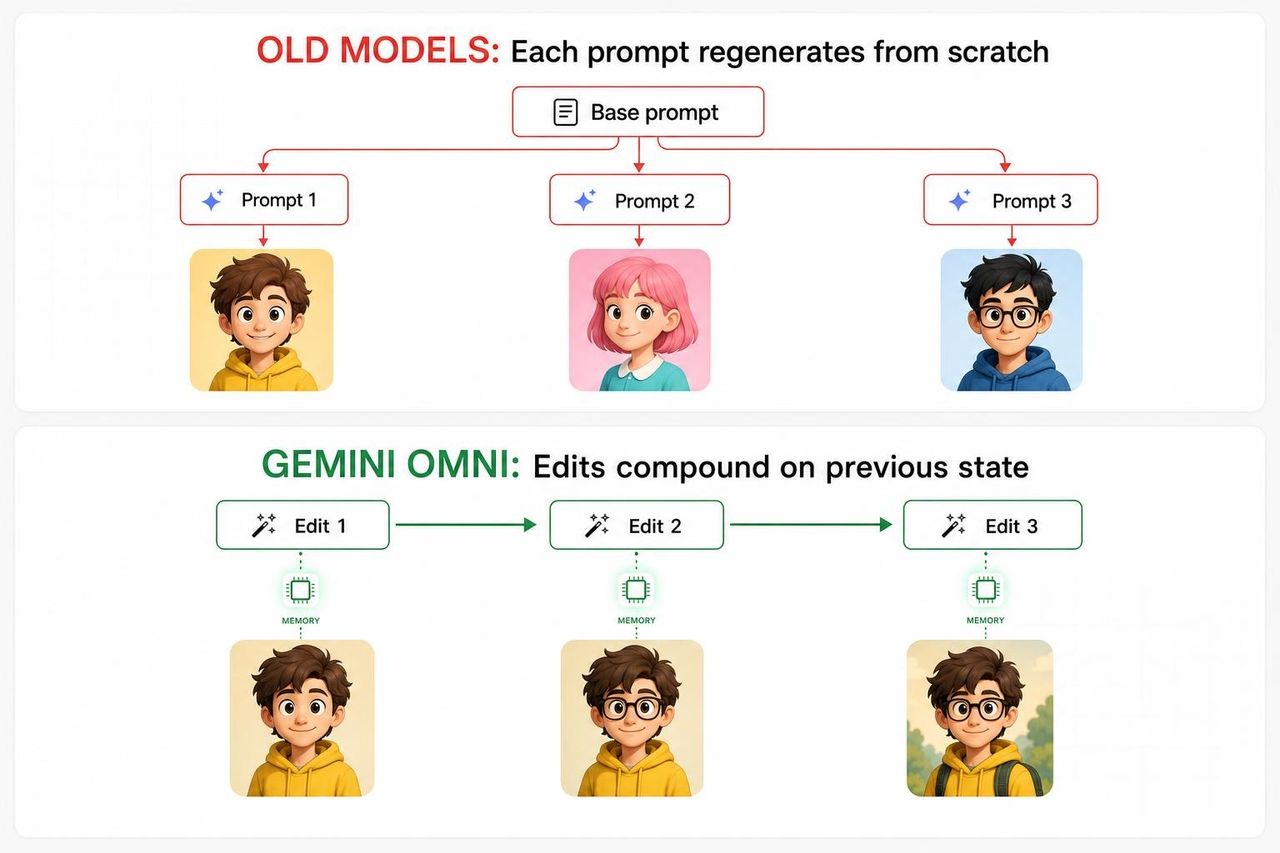
要理解為什麼小提琴手的演示很重要,你需要了解其他所有 AI 影片模型的失敗之處。
在傳統的生成式影片流程中,每一個新的提示詞本質上都是從零開始重新生成場景——使用原始提示詞加上新的提示詞作為組合輸入。模型在輪次之間沒有真正的內在連續性。臉部會漂移,背景道具會消失,光線會改變。到了第三輪,結果通常已經與最初的構想大相徑庭,導致創作者放棄並重啟。
根本原因在於架構。大多數影片模型被訓練為「單次生成器」,而非「多輪代理」。它們被優化為從一個提示詞中產生單一最佳輸出,而不是記住上次生成的內容並在此基礎上進行優化。要求它們進行「編輯」,實際上是要求它們帶著額外的背景資訊重頭來過,而這種運算方式產生的是複合型的漂移,而非複合型的優化。
Omni 的方法截然不同。它被構建為一個「狀態化編輯器」(stateful editor)——這意味著每一輪都會更新場景的持續性表徵,而不是從頭開始重新生成。
「場景會記憶」真正的含義
英語科技媒體也在以各自的觀點達成共識。
Decrypt 最直白地描述了這一突破:「Google 表示,即使在用戶對影片進行修改後,Omni 仍能保持相同的人物、背景和動作的一致性——這是許多 AI 影片模型難以做到的。」
Android Central 指出了關鍵的技術細節:「該公司還表示,該模型在多步驟修改過程中會回憶先前的指令,這使得迭代編輯的過程不再那麼混亂。」
TechRadar 從電影的角度進行了構思:「人物保持可辨識性。場景保持連續性。動作保持連貫,而不是每次修改提示詞時都重置。」
而 Phandroid 將整個功能壓縮成五個字:「場景記住了之前發生的事。」
這就是核心重點。場景擁有記憶。 這一單一屬性,就是 AI 影片從「玩具」轉變為「工具」的關鍵區別。
Omni 在一致性方面與 Sora、Veo 和 Seedance 的對比
截至 2026 年 5 月,各大領先 AI 影片模型在多輪一致性方面的比較如下:
| 模型 | 多輪編輯 | 對話式微調 | 角色一致性 (Medium 評測) | 目前狀態 |
| Gemini Omni Flash | 狀態化、多輪 | 原生聊天式 | (3/5) | 2026 年 5 月 19 日上線 |
| Sora 2 (OpenAI) | 單次生成 | 有限 | 已停產 | Sora App 已關閉;API 將於 2026 年 9 月停用 |
| Veo 3.1 (Google) | 部分支援 | 僅限文字+圖像 | 低於 Omni | 已上線,正被 Omni 取代 |
| Seedance 2.0 (ByteDance) | 基於參考圖,非迭代 | 有限 | (4/5) | 已上線;Artificial Analysis 影片競技場排名第一 |
客觀解讀:Omni 是唯一具備真正「狀態化」多輪編輯功能的模型。Seedance 透過在每次生成時利用最多 9 張參考圖,在角色一致性方面得分更高(根據 Medium 評論員的說法)——但它無法在整個編輯會話中保持這種一致性。Sora 即將退出大眾市場,Veo 則正被整合。
從「重骰」到「微調」——工作流程的變革解鎖了什麼

這裡真正的價值不在於演示,而在於工作流程的轉型。
Blockchain.news 最好地總結了商業影響:「批次編輯能夠在多個影片片段中同步修改,在加速製作的同時保持 AI 生成內容的品質標準。影視、廣告和教育內容創作者透過降低成本和提高敘事可靠性,獲得了顯著優勢。」
最後那個短語——敘事可靠性——是任何內容創作者都應該關心的重點。
在此之前,AI 影片頂多能提供一個不錯的短片。它無法交付一個「系列廣告」——即一套擁有相同主角、相同品牌資產、在多個交付成果中保持視覺語言一致的影片。每一次編輯都像是在擲硬幣。現在,編輯可以疊加了。
TechTimes 總結了公開展示的功能集,包括*「編輯用戶拍攝素材中的動作與物體、在真實與動畫風格之間進行風格轉換、多輪微調,以及解說型內容生成。」*
而 DataCamp 的實測評論證實了多輪行為在實踐中確實可行:「Omni 支援多輪編輯,因此你可以逐步優化細節、環境和攝影機角度,同時保持場景的一致性。」
工作流程的轉變在紙面上看起來很小,但在實踐中卻是巨大的:生成 → 重生成 → 重生成 → 放棄 變成了 生成 → 微調 → 微調 → 發佈。
開發者們已經注意到了。在中國開發者論壇 V2EX 上,一位在發布當天測試了 Omni 的工程師寫道:「生成速度和一致性超出了我的預期。」
當 AI 工程師和一線創作者在發布後數小時內得出相同的觀察結果時,這代表著能力的真正躍遷——而不僅僅是行銷術語。
誠實的懷疑——Omni 並非完美
在有人宣稱一致性問題已完全解決之前,這裡有一些冷靜的觀點。
Medium 上的 AI Analytics Diaries 評論員 將 Omni 與字節跳動的 Seedance 2.0 進行了對比,給 Omni 的角色一致性打了 3 分(滿分 5 分)。
這句話值得貼在每一位 AI 影片產品經理的螢幕上:「兩個模型在跨鏡頭的角色一致性方面都存在困難——這仍然是 AI 影片領域的公開傷口。」
翻譯一下:Omni 在單個編輯會話內的「多輪微調」方面,確實比其他所有公開模型都要好。但在更廣泛的範疇中,這還不是一個已解決的問題。
剩下的差距在哪裡?
- 單場景的多輪一致性運作得非常好(小提琴手演示)
- 跨鏡頭一致性(同一個角色、不同的場景、不同的燈光設置、不同的構圖)仍然不夠完美
- 細微的特徵——精細的面部細節、手部關節、特定的衣物紋理——在多次編輯後仍可能產生漂移
- Omni Flash 目前 10 秒的片段限制,意味著多輪一致性尚未在長篇敘事作品中經過公開的壓力測試
對於 80% 的使用場景——單場景微調、社交媒體長度的內容、行銷素材——Omni 已經足夠好到可以發佈。對於剩下的 20%——那些角色連續性必須支撐 30 個鏡頭序列的電影級作品——仍然需要進行後期剪輯清理。
這實際上改變了什麼——各產業分析
如果多輪一致性現在已經解決(或在單個會話中接近解決),這將解鎖哪些可能:
對於品牌廣告商: 活動連續性。服裝品牌終於可以在十個場景中生成同一位模特兒的十種變體——無需重新拍攝、無需尋找新人才、無需支付十次人工修圖費用。社交優先的創意製作成本效益將有數量級的提升。
對於教育與教學創作者: 系列一致性。單個 AI 生成的講師可以主持整門課程——從第一集到第十二集——而觀眾不會察覺他們是合成的。「內容間一致的人臉」問題曾讓 AI 教育工具陷入停滯兩年。現在它被解決了。
對於電影製作人: 大規模預覽。同一個演員在多個場景提案、多個燈光設置、多個攝影機角度中的表現——全部在單一會話中生成,並可進行迭代微調。從「我有一個想法」到「我可以向導演展示」的差距,從數天縮短






