你的提示詞觸發了攔截機制。這並非因為內容有害,而是因為關鍵字觸發了篩選器。
Ollama 社群的開發者將這種現象稱為「拒絕向量」(refusal vectors):即與實際危害無關、僅由關鍵字觸發的封鎖。無論是為了安全研究進行的惡意軟體逆向工程、醫學案例研究文檔、成人內容創作,還是暗黑文學寫作,主流 AI 都會對這些內容進行封鎖。本清單基於真實的社群數據(而非行銷文案)對 2026 年最佳無審查 AI 模型進行了排名。內容涵蓋三大類別:用於文本與程式碼的無審查 LLM 模型、適用於私有硬體部署的 2026 年最佳本地無審查 AI 模型,以及透過 API 進行圖像與影片生成的 2026 年無審查 AI 模型。文中所有數據來源均已標註,截止日期為 2026 年 5 月。
對於剛接觸此領域的讀者,若想了解更廣泛的工具概況,建議先參考 無審查 AI 圖像生成器指南,這將是挑選具體模型前的實用起點。
我們如何對 2026 年最佳無審查 AI 模型進行排名
在 2026 年,來自 Ollama 的社群下載量比基準測試分數更具可靠的排名參考價值,因為基準測試往往是為了新聞稿而挑選,而非反映實際性能(Ollama,無審查模型搜尋,2026)。數百萬次的下載量代表了數以千計的硬體配置與提示詞類型,這比精心挑選的評估集更難以被操弄。
本文採用三種排名指標:針對 Ollama 無審查模型,主要指標為 ollama.com 的下載次數(截至 2026 年 5 月);針對 OpenRouter 模型,因平台不公開下載量,排名依據參數規模與上下文視窗;針對圖像與影片模型,則依據單位輸出成本,同組中成本較低者排名靠前。
大多數 2026 年的無審查 AI 模型分為兩種技術類別:微調(fine-tuned)與抹除(abliterated)。像 Dolphin 系列這類的微調模型是在不會強化拒絕行為的數據集上進行訓練的;而抹除模型則是透過外科手術式移除拒絕權重。社群一致認為,微調模型在處理各類提示詞時表現更穩定。
實際上,下載量也與模型的穩定性呈正相關。一個下載量超過 100 萬次模型,意味著已在多種硬體配置下經過測試,並修復了小型測試群體無法發現的錯誤與不穩定問題。
2026 年最熱門的 5 款 Ollama 無審查模型是什麼?
2026 年,下載量前五名的 Ollama 無審查模型累計下載量超過 920 萬次,其中 llama2-uncensored 以 260 萬次位居榜首(Ollama,無審查模型搜尋,2026)。這些是經由社群驗證、而非基準測試背書的 2026 年最佳無審查 Ollama 模型。硬體是使用者最優先考慮的篩選條件:該組模型的 VRAM 需求從 4GB 以下到 40GB 不等。
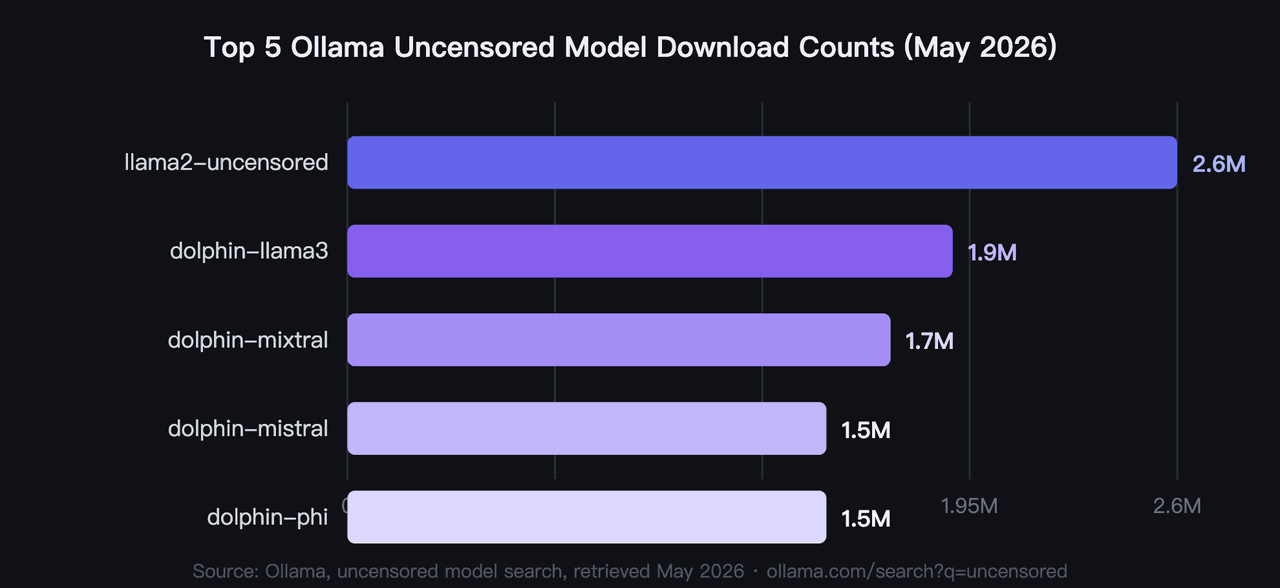
1. llama2-uncensored:Ollama 上下載次數最多的無審查 AI 模型
這是社群針對本地無審查 AI 的原始標竿。George Sung 和 Jarrad Hope 發布了此微調版本,旨在移除 Llama 2 的拒絕行為,同時不降低通用能力。它是大多數開發者的入門模型,260 萬次的下載量反映了其超過兩年的實戰經驗。目前尚無單一無審查 LLM 能達到此下載量。
- 參數規模: 7B 或 70B
- VRAM: 約 6GB (7B);約 40GB (70B)
- 適用場景: 通用無限制對話與內容生成
- 平台: Ollama
2. dolphin-llama3:適用於 Agentic 工作流程的最佳無審查 Llama 3 LLM
Eric Hartford 基於 Llama 3 架構開發的 Dolphin 是目前最熱門的現代架構無審查模型,下載量達 190 萬次(Ollama,dolphin-llama3 模型頁面,2026)。它支援函式呼叫(function calling),上下文視窗可根據配置從 8K 擴展至 256K tokens。8B 版本大小為 4.7GB,適用於大多數中階消費級 GPU。
- 參數規模: 8B 或 70B
- VRAM: 約 5GB (8B);約 40GB (70B)
- 適用場景: 程式設計、Agentic 工作流程與函式呼叫
- 平台: Ollama
3. dolphin-mixtral 8x7B:用於複雜推理的無審查 MoE AI 模型
混合專家(MoE)架構會將每個 token 路由至其 8 個專家層的子集進行處理。這使其在較低的推理成本下,能產生接近 70B 規模的推理品質。Eric Hartford 的無審查微調版本始終保持對程式設計能力的強勁優化。
- 參數規模: 8x7B(單次推理的實際參數遠低於總參數)
- VRAM: 量化後約 12-16GB
- 適用場景: 複雜程式開發任務、技術推理與長指令鏈
- 平台: Ollama
4. dolphin-mistral:用於快速回應的無審查 7B 本地 AI 模型
在 CPU 資源受限的硬體上,它比 dolphin-mixtral 更輕盈快速。它吸引了 150 萬次下載,使用者偏好將其用於無需高階 GPU 的程式碼補全。Mistral 的基礎架構賦予了它在 7B 模型中極佳的性能尺寸比。
- 參數規模: 7B
- VRAM: 約 5-6GB
- 適用場景: 輕量級程式輔助與快速對話回應
- 平台: Ollama
5. dolphin-phi 2.7B:最輕量的無審查本地 AI 模型
微軟的 Phi 基礎架構將強大的推理能力濃縮在 2.7B 參數中。Eric Hartford 的微調版本保留了這一高效率。在 4GB 以下的 VRAM 環境下,它可在大多數配備獨立顯卡的消費級筆記型電腦上運行,成為通往 2026 年最佳無審查本地 AI 模型最容易上手的入口。
- 參數規模: 2.7B
- VRAM: 4GB 以下
- 適用場景: 筆電部署、快速測試與硬體受限環境
- 平台: Ollama
最佳無審查 LLM 模型 6-10 名:程式設計、角色扮演與長上下文
2026 年,Dolphin 系列在 Ollama 無審查目錄的下載量中佔據了前 10 名中的 5 個席位,這種集中度反映了 Eric Hartford 在不同基礎架構上始終如一的微調方法論(Ollama,hermes3 模型頁面,2026)。第 6 至 10 名涵蓋了角色扮演、一般對話、開發工具、指令遵循與擴展上下文,這些正是主流 AI 拒絕機制最令人困擾的使用場景。
6. hermes3:用於角色扮演與 Agentic 任務的無審查 AI 模型
Nous Research 開發的 hermes3 專注於角色扮演深度與結構化工具使用。它提供從 3B 到 405B 的四種尺寸,是此清單中尺寸範圍最廣的模型。憑藉 130 萬次下載,8B 版本在創意寫作與 Agentic 任務規劃工作流程中表現極佳(Ollama,hermes3 模型頁面,2026)。
- 參數規模: 3B, 8B, 70B 或 405B
- VRAM: 約 2GB (3B);約 5GB (8B);約 40GB (70B)
- 適用場景: 角色扮演、創意小說與 Agentic 任務規劃
- 平台: Ollama
7. wizard-vicuna-uncensored:適用於一般用途的多尺寸無審查 AI 模型
這是一款基於 Llama 2 的老牌且經過驗證的模型,提供最高 30B 的三種尺寸。它擁有 120 萬次下載量,深受那些需要廣泛參數選擇的使用者青睞。雖然其上下文視窗能力不及 dolphin-llama3,但在處理一般對話與創意內容時表現穩定。
- 參數規模: 7B, 13B 或 30B
- VRAM: 約 5GB (7B);約 9GB (13B);約 20GB (30B)
- 適用場景: 多尺寸選擇下的通用對話與創意內容
- 平台: Ollama
8. dolphincoder:基於 StarCoder2 的無審查 AI 程式模型
StarCoder2 作為基礎,使 dolphincoder 成為名副其實的專家模型。不同於其他 Dolphin 模型是具備無審查微調的通才,這款模型專注於軟體開發。其 94.3 萬次下載幾乎完全來自開發者。15B 版本能處理比 7B 版本更大的程式碼庫。
- 參數規模: 7B 或 15B
- VRAM: 約 5GB (7B);約 10GB (15B)
- 適用場景: 程式碼生成、除錯與技術文件撰寫
- 平台: Ollama
9. wizardlm-uncensored:用於研究工作流程的無審查指令遵循 LLM
這是一款具備 61 萬次下載的 13B 指令遵循模型。其強項在於能執行複雜的多步驟指令,而不含糊其辭或拒絕子任務。在研究工作流程中,一旦因拒絕而中斷長鏈,這種可靠性便直接轉換為生產力價值。它雖然沒有 dolphin-llama3 的現代架構,但勝在指令執行的穩定性。
- 參數規模: 13B
- VRAM: 約 9GB
- 適用場景: 複雜多步驟指令鏈與研究工作流程
- 平台: Ollama
10. everythinglm:具備 16K 上下文視窗的無審查 LLM
其核心亮點在於基於 Llama 2 的 16K 上下文視窗。大多數 7B 模型通常僅支援 4K 或 8K tokens。額外的上下文讓 everythinglm 能在不截斷的情況下處理完整的程式碼庫、長文檔或擴展的對話歷史。儘管 53.6 萬次下載在此清單中顯得保守,但它填補了此尺寸下其他模型未能涵蓋的空白。
- 參數規模: 13B
- VRAM: 約 9GB
- 適用場景: 長文檔分析、擴展上下文對話與程式碼庫全覽
- 平台: Ollama
Dolphin 系列在 Ollama 下載量上的主導地位反映了社群記錄的一種模式:由同一作者以一致的方法論進行微調的無審查模型,表現優於單次的抹除嘗試。抹除是針對單一模型移除拒絕權重,而微調則是在多種提示詞類型下建立穩定的無審查行為。這種一致性正是為何前 10 名中有 5 個席位屬於 Eric Hartford 的作品。
如何在本地設定 Ollama 無審查模型?
2026 年,在 Mac、Linux 或 Windows 上安裝 Ollama 模型只需三行指令:從 ollama.com 安裝 Ollama,運行 ollama pull [model-name],然後運行 ollama run [model-name](Ollama 文檔,2026)。無需 API 金鑰,無需外部內容審核。提示詞永遠不會離開你的硬體設備。
以 dolphin-llama3 為例:ollama pull dolphin-llama3 會下載 4.7GB 的 8B 模型檔案。ollama run dolphin-llama3 會開啟互動式提示視窗。整個推理過程都在你的本地 GPU 或 CPU 上執行。
對於不習慣終端機的使用者,LM Studio 提供了桌面圖形介面。它使用與 Ollama 相同的 GGUF 模型檔案,並具備視覺化的模型選擇與參數調整功能。llama.cpp 是上述工具背後的推理引擎,當你需要更精確地控制量化等級與上下文長度時,它也支援直接透過指令列使用。
對於想要為消費級 GPU 執行 2026 年最佳無審查本地 AI 模型尋求硬體需求與量化設定的開發者,完整的本地設定指南詳細涵蓋了最小 VRAM 配置與常見的安裝錯誤。
若無本地 GPU,有哪些 OpenRouter 無審查模型可用?
2026 年,OpenRouter 透過 API 提供無審查 LLM 託管服務,完全免去了硬體 GPU 的需求。venice/uncensored 模型提供免費層級,每百萬輸入與輸出 token 費用為 USD0(OpenRouter,venice/uncensored 模型頁面,2026)。這使得 OpenRouter 無審查模型成為無專用硬體用戶的實用選擇。
交換條件很明確:OpenRouter 會透過其架構路由你的提示詞,因此對話並非如本地模型般具備隱私性。本地 Ollama 模型能將所有內容保留在設備上。兩種方式並無絕對優劣,選擇取決於你的威脅模型與硬體可用性。
11. venice/uncensored:免費無審查 OpenRouter 模型
這是 OpenRouter 免費層級下的 Venice Uncensored 模型,基於 24B Mistral-Small 架構,由 Cognitive Computations 與 Venice.ai 合作進行無審查微調。具備 32K 上下文視窗,每百萬 token USD0。OpenRouter 的免費層級對所有免費模型實施全平台每日 200 次請求的限制。
- 參數規模: 24B
- VRAM: 無需(雲端託管)
- 適用場景: 無本地硬體測試無審查 LLM;在平台限制內的免費使用
- 平台: OpenRouter
12. Sao10K: Llama 3.3 Euryale 70B:透過 OpenRouter 的大型無審查模型
由 Sao10k 開發的 70B 創意角色扮演與指令遵循模型,針對無審查輸出進行了微調。基於 Llama 3.3 70B,具備 131K 上下文。在 OpenRouter 上積極維護並有實際使用記錄,可透過平台全域搜尋找到。
- 參數規模: 70B
- VRAM: 無需(雲端託管)
- 適用場景: 複雜創意寫作、角色扮演與無需本地硬體的長指令鏈
- 平台: OpenRouter
13. Sao10K: Llama 3 8B Lunaris:透過 OpenRouter 的輕量無審查模型
Lunaris 8B 是一款由 Sao10k 開發的靈活通用型角色扮演模型,基於 Llama 3 8B。它是多個模型的策略性合併,旨在平衡創意與邏輯能力及通用知識。相比 Stheno v3.2,它在創意與推理方面體驗更佳。它是 OpenRouter 上價格最低的無審查選項,費用為每百萬 token USD0.04/USD0.05,該平台上有超過 60 億 token 的實際使用量。
- 參數規模: 8B
- VRAM: 無需(雲端託管)
- 適用場景: 以最低成本進行輕量無審查對話與創意寫作
- 平台: OpenRouter
14. TheDrummer: Cydonia 24B V4.1:透過 OpenRouter 的無審查創意寫作模型
Cydonia 24B V4.1 是 TheDrummer 開發的一款無審查創意寫作模型,基於 Mistral Small 3.2 24B,具備良好的回憶能力、提示詞遵循與智慧水準,上下文視窗為 131K。積極維護並可直接在 OpenRouter 的全域搜尋中找到。
- 參數規模: 24B
- VRAM: 無需(雲端託管)
- 適用場景: 無需本地硬體的無審查創意寫作與角色扮演
- 平台: OpenRouter
如何透過 Atlas Cloud 存取無審查圖像與影片模型
在 2026 年,大多數無審查圖像與影片模型需要本地 GPU 或專用 API 平台,因為主流雲端供應商在推理層級實施內容過濾,會封鎖 NSFW 輸出。Atlas Cloud 是一個專為移除此類限制而打造的模型 API 平台,涵蓋文本、圖像、影片與音訊領域的 300 多個精選模型。
入門只需三步驟:
- 在 atlascloud.ai 建立帳號
- 從控制面板產生 API 金鑰
- 使用金鑰呼叫模型端點——圖像與影片模型使用其自有的 REST 格式;LLM 端點遵循 OpenAI Chat Completions 格式
為何 Atlas Cloud 在無審查使用場景中具有相關性:
- 平台的隱私政策聲明:「您生成的內容絕不會用於訓練,且絕不會經過人工審查。」這是一項明確發布的承諾,而非預設假設。
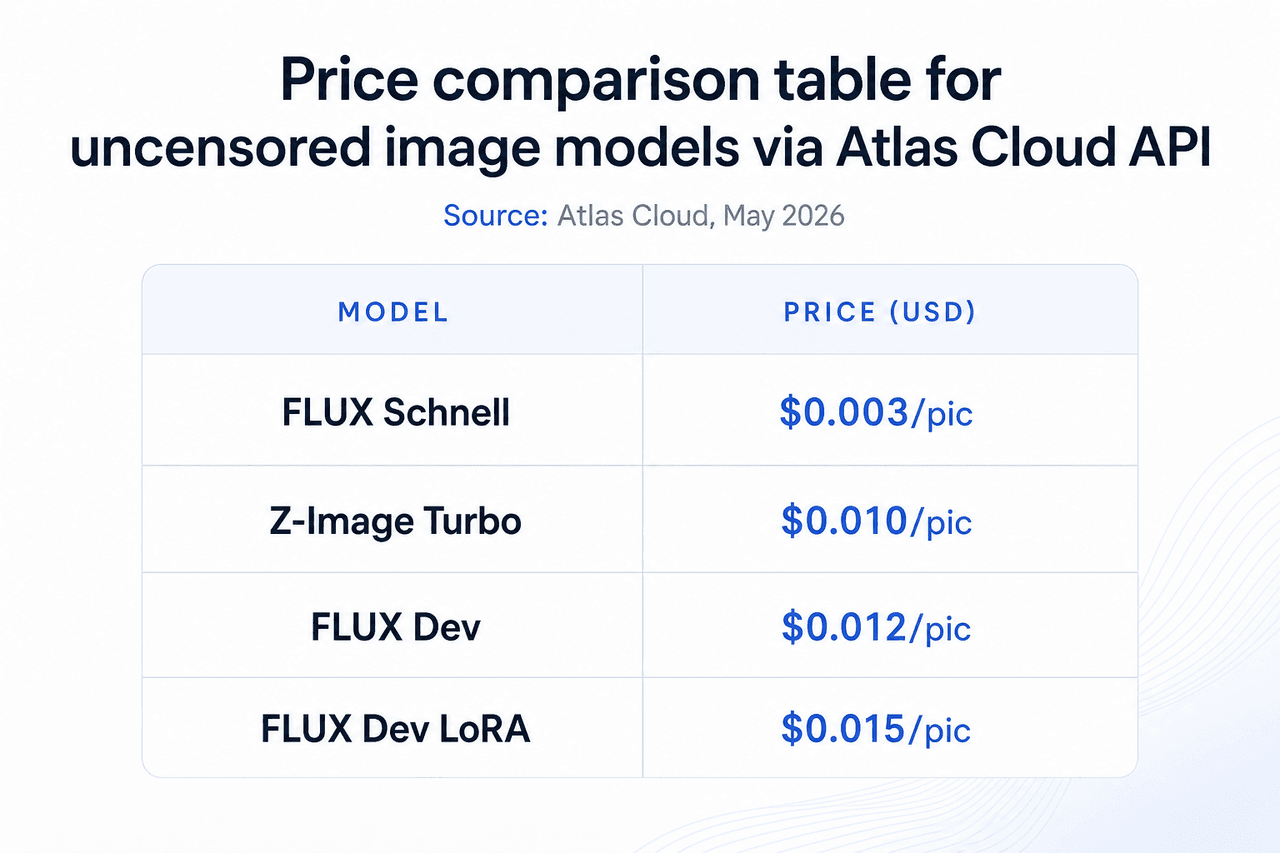
- 目錄中的任何模型均無每日生成上限。
- 無審查圖像目錄涵蓋 33 種文字轉圖像模型,起價為每張圖片 USD0.003。
- 無審查影片目錄涵蓋 10 種以上 NSFW 影片模型,起價為每秒 USD0.01。
完整的無審查模型目錄可在 Uncensored AI 瀏覽。此清單中的第 15 至 20 個模型皆可透過單一 Atlas Cloud API 金鑰存取。
哪些是 2026 年用於 NSFW 與成人內容生成的最佳無審查 AI 圖像模型?
在 2026 年,FLUX 架構驅動了大多數高品質的無審查圖像生成,並透過 Atlas Cloud API 在不同價格與品質層級提供服務(Atlas Cloud,文字轉圖像模型列表,2026)。Atlas Cloud 目錄總計涵蓋 33 種文字轉圖像模型。使用場景包括美術、角色設計、無審查內衣模特與成人肖像生成、遊戲資產創作以及批次插圖生成。
Atlas Cloud 的首頁聲明其擁有「超過 300 種涵蓋文本、圖像、影片與音訊的精選模型」,其無審查目錄的隱私政策寫道:「您生成的內容絕不會用於訓練,且絕不會經過人工審查。」
如需瀏覽器端與 API 端無審查圖像工具的完整拆解,請參閱 最佳無審查 NSFW AI 圖像生成器指南,其中涵蓋了兩種分類及能力比較。專注於 FLUX 架構的開發者可閱讀 FLUX 無審查圖像生成器指南以了解微調與工作流程細節。
對於從現有圖像而非提示詞開始的工作流程,無審查 AI 圖像轉圖像指南 與 最佳無審查 AI 圖像編輯器指南 分別涵蓋了轉換與編輯流程。專注於動漫風格或插畫角色輸出的團隊,可在 無審查動漫 AI 圖像生成器指南 中找到專業化選項。
15. FLUX Schnell:用於批次生成的最快無審查 AI 圖像模型
Atlas Cloud 圖像目錄中的最低成本選項。每張圖像 USD0.003,是追求速度與產量勝過細節的批次生成工作流程的首選工具。無每日限制,且無內容用於訓練。
- 價格: USD0.003/張
- VRAM: 無需(API 存取)
- 適用場景: 批次圖像生成、快速原型設計與高產量無審查輸出
- 平台: Atlas Cloud API
以每張 USD0.003 計算,USD3.00 的預算可產生 1,000 張圖像。此輸出成本低於大多數供應商的雲端儲存費用。這翻轉了以往工作室為了批次生成整夜運行昂貴本地 GPU 機台的經濟模式:API 方案現在不僅更便宜,對於大量生產工作而言也更快。
16. FLUX Dev:用於最終生產的高品質無審查 AI 圖像模型
成本為 FLUX Schnell 的四倍,但在解剖結構、光影與材質細節上有顯著提升。對於強調個別圖像品質的最終輸出,USD0.012 的價格是合理的升級。它適合投資組合作品、商業成人內容與品質要求為首要考量的生產資產。
- 價格: USD0.012/張
- VRAM: 無需(API 存取)
- 適用場景: 高品質單圖、投資組合作品與最終生產資產
- 平台: Atlas Cloud API
17. FLUX Dev LoRA:支援自訂風格訓練的無審查圖像模型
LoRA 微調將自訂風格、角色外觀或主題植入 FLUX Dev 基座。當你在批次中需要一致的角色外觀,或希望將特定風格應用於整套圖片時,請使用此模型。Atlas Cloud 會在伺服器端處理 LoRA 載入。
- 價格: USD0.015/張
- VRAM: 無需(API 存取)
- 適用場景: 角色一致性、自訂風格訓練與品牌化圖像系列
- 平台: Atlas Cloud API
18. Z-Image Turbo:中階品質的預算型無審查 AI 圖像模型
在價格與品質曲線上介於 FLUX Schnell 與 FLUX Dev 之間。每張圖片 USD0.01,Z-Image Turbo 提供了針對速度優化的不同架構,且沒有 Schnell 在較低價位下會產生的圖像簡化問題。當 Schnell 的品質不足,且 FLUX Dev 的成本對於所需產量來說過高時,這是最務實的選擇。
- 價格: USD0.01/張
- VRAM: 無需(API 存取)
- 適用場景: 品質與成本需平衡的中量生成
- 平台: Atlas Cloud API
哪些是 2026 年用於 NSFW 動畫的最佳無審查 AI 影片模型?
在 2026 年,無審查影片生成需要與圖像生成分開的管道,因為主流影片平台實施了相同的內容過濾,即使來源圖像是在他處生成的,它們也會拒絕對 NSFW 內容進行動畫化(Atlas Cloud,無審查模型目錄,2026)。Atlas Cloud 的無審查影片頁面標題為「不受限制的創作自由。無過濾。無限制。」並涵蓋 10 種以上 NSFW 影片模型,完整目錄還包括 Wan 2.6、Wan 2.5 以及 Van 系列變體。
19. Wan 2.2 Turbo Spicy Infinite I2V:最低成本的無審查影片模型
這是將靜態影像進行 NSFW 動畫化的入門選項。每秒 USD0.01 的價格,是將靜態圖像轉為 NSFW 影片內容最具成本效益的方式。解析度高達 1080p 並支援可變剪輯長度,是預算導向型生產流程的正確起點。
- 價格: USD0.01/秒
- 解析度: 1080p
- 時長: 可變
- 適用場景: 高成本效益的 NSFW 動畫製作與動態概念預覽
- 平台: Atlas Cloud API
20. Seedance v1.5 Spicy:用於最終輸出的高品質無審查影片模型
目錄中的電影級畫質選項。每秒 USD0.049,價格約為 Wan 2.2 Turbo Spicy Infinite 的 2.5 倍,但能產生更流暢的動作、更好的幀間主體一致性以及更自然的轉場。對於視覺擬真度為首要考量的最終品質 NSFW 影片輸出,這是 Atlas Cloud 無審查影片陣容中的首選。
- 價格: USD0.049/秒
- 解析度: 720p
- 時長: 5秒
- 適用場景: 最終品質 NSFW 影片、專業成人內容與可交付成品
- 平台: Atlas Cloud API
最佳無審查 AI 圖像轉影片生成器指南 涵蓋了所有長度與解析度選項,包含全系列的 Wan 2.7 與 Wan 2.2 Spicy 變體。
無審查 AI 模型快速選擇指南
| 需求 | 推薦 |
|---|---|
| 最佳整體無審查 LLM | llama2-uncensored 或 dolphin-llama3 |
| 程式設計任務 | dolphin-mixtral 8x7B 或 dolphincoder |
| 角色扮演與創意寫作 | hermes3 |
| 4GB VRAM 以下 | dolphin-phi 2.7B |
| 無審查圖像生成 | 透過 Atlas Cloud 的 FLUX Schnell (USD0.003/張) |
| 圖像生成 NSFW 影片 | 透過 Atlas Cloud 的 Wan 2.2 Turbo Spicy Infinite (USD0.01/秒) |
無審查 AI 模型常見問題 (FAQ)
2026 年最無審查的 AI 模型是哪一個?
就 Ollama 下載量而言,llama2-uncensored 以 260 萬次拔得頭籌,使其成為 2026 年無審查 AI 模型中最具社群驗證的選擇(Ollama,無審查模型搜尋,2026)。若論原始能力,dolphin-llama3 提供更多功能:函式呼叫、高達 256K 上下文以及 Llama 3 基礎架構。答案取決於你的使用場景中,對驗證過的穩定性還是現代化能力更為看重。
哪些無審查模型可在 Ollama 上運行?
本清單中有 10 款模型作為 ollama 無審查模型運行:llama2-uncensored、dolphin-llama3、dolphin-mixtral、dolphin-mistral、dolphin-phi、hermes3、wizard-vicuna-uncensored、dolphincoder、wizardlm-uncensored 與 everythinglm。社群模型 jaahas/qwen3.5-uncensored 也可在 Ollama 上運行以實現多語言使用。所有模型皆透過 ollama pull [model-name] 安裝。
OpenRouter 上有哪些無審查模型可用?
2026 年,OpenRouter 透過 API 提供無審查 LLM 託管服務,完全免去了 GPU 需求。選項包括免費層級的 venice/uncensored 模型(每百萬 token USD0,每日 200 次請求),以及包括 Sao10K Euryale 70B、Lunaris 8B 與 TheDrummer Cydonia 24B 在內的付費模型(OpenRouter,venice/uncensored 模型頁面,2026)。這些 OpenRouter 無審查模型無需本地 GPU,也無需硬體投資即可開始使用。
抹除(abliterated)模型與微調(fine-tuned)無審查模型有何不同?
抹除是從模型權重層級以手術方式移除拒絕權重。像 Dolphin 系列這樣的微調無審查模型,則是從一開始就在不強化拒絕行為的數據集上進行訓練。社群一致發現微調模型更為穩定:抹除可能會在各類提示詞中引入不一致的輸出,而微調則能產生可靠的結果。這解釋了為何 Dolphin 模型主導了 Ollama 無審查下載量。
我可以在筆記型電腦上本地運行無審查 AI 模型嗎?
可以。dolphin-phi 2.7B 運作 VRAM 不到 4GB,使其成為配備獨立顯示卡的筆記型電腦部署入門模型。擁有 6-8GB VRAM 即可運行此清單中的任何 7B 模型。整合式繪圖晶片無法運作。無審查 AI 模型的本地設定指南詳細涵蓋了最小硬體配置與量化設定。
結論
2026 年最佳無審查 AI 模型完全取決於你的使用場景。對於通用 LLM 工作,dolphin-llama3 是功能最強大的 Ollama 選項。對於筆記型電腦,dolphin-phi 涵蓋了 4GB VRAM 以下的需求。對於無需硬體的雲端 LLM 存取,OpenRouter 免費層級的 venice/uncensored 是每百萬 token USD0 的實用起點。對於大規模無審查圖像生成,透過 Atlas Cloud API 的 FLUX Schnell 可產生每張 USD0.003 的輸出,且無每日上限。對於 NSFW 影片,Atlas Cloud 目錄起價為每秒 USD0.01,並具備經過驗證的「不訓練、不審查」政策。
讀者若想獲取跨圖像、影片與編輯器的無審查 AI 工具完整概覽,請參閱 無審查 AI 圖像生成器指南,內容涵蓋了完整版圖。






