AI 影片生成 API 向來以「難以捉摸」著稱,這並非空穴來風。文字生成任務若出錯,通常會立即回傳 400 錯誤;但影片渲染則完全不同,且更具不確定性。一個任務可能會在 GPU 佇列中無限期等待卻毫無預警,或者只回傳了請求片段中的一半。有時候,渲染雖然完美結束,但最終產出的影片看起來卻在物理上完全不合理或嚴重扭曲。
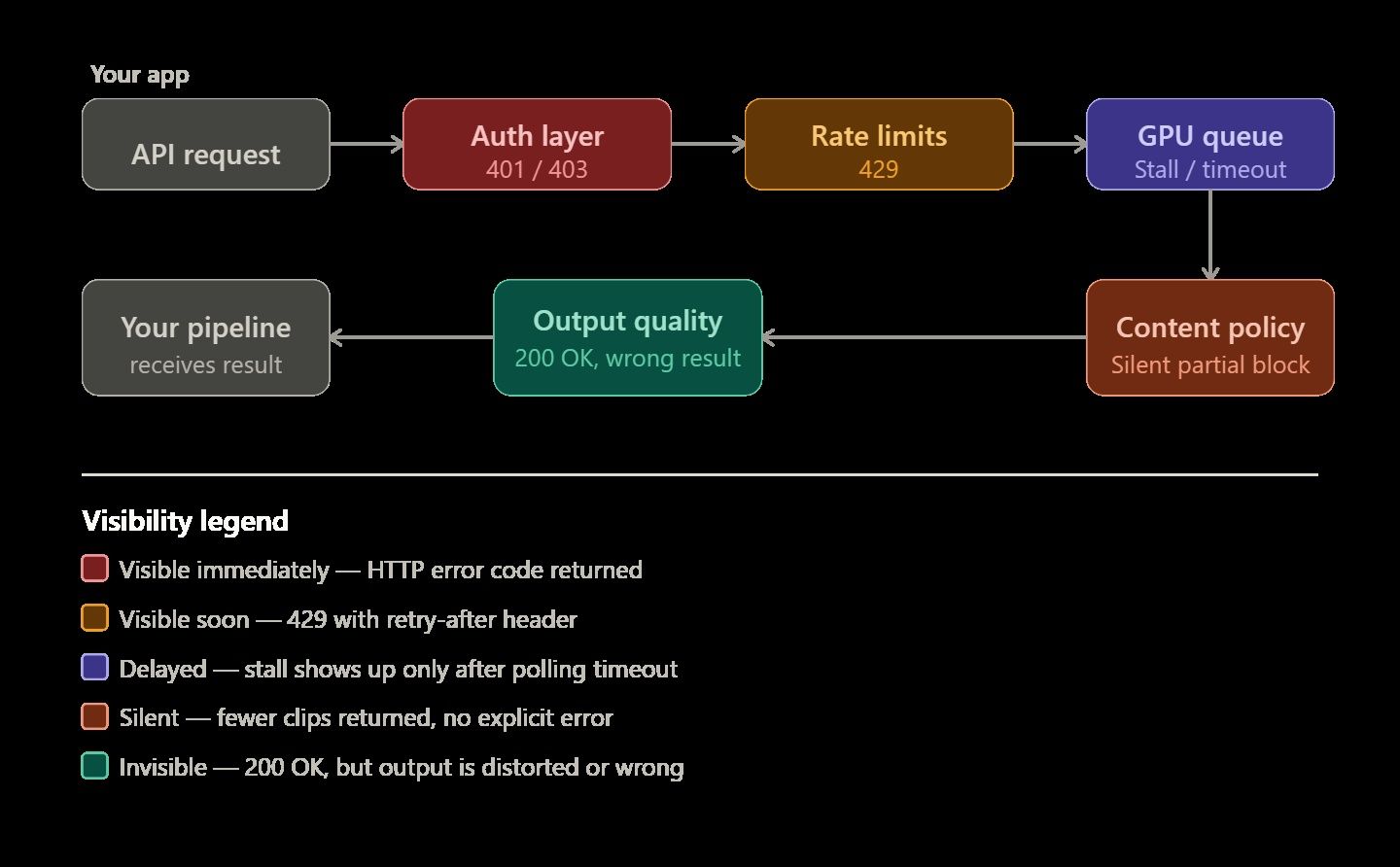
若要打造可靠的系統,你必須理解這些特定錯誤發生的原因。正是這種技術掌握度,區分了簡單的 Demo 與真正能服務終端使用者的穩定影片流水線。
本指南將剖析最常見的錯誤類型、如何精確解讀 API 回應,以及打造低成本、高穩定性影片渲染流水線的具體策略。程式碼範例將使用 Atlas Cloud API,這是一個統一的推理平台,透過單一端點即可存取 300 多種影片與多模態模型,對於處理多模型架構非常有幫助。
AI 影片 API 的五大錯誤類別
AI 影片流水線錯誤通常可分為五大類。掌握正確的分類有助於你更快速地解決問題,例如判斷是該修正程式碼、重寫提示詞 (Prompt),還是僅需耐心等待。
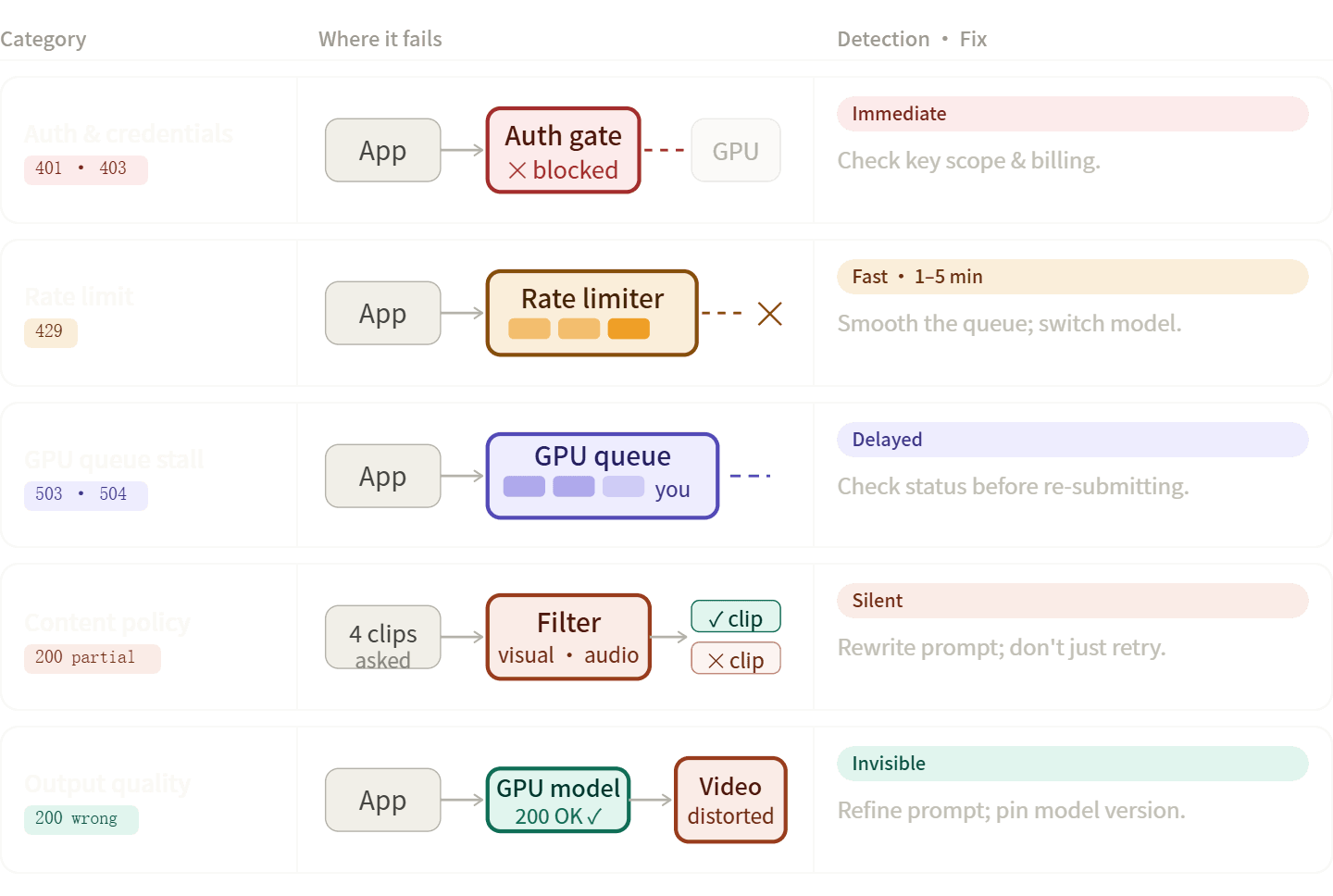
驗證與憑證錯誤 (401, 403)
| 錯誤碼 | 常見原因 | 修正方法 |
|---|---|---|
| 401 Unauthorized | Authorization: Bearer 標頭缺失或格式錯誤 | 確認金鑰是從環境變數載入,而非寫死在程式中 |
| 403 Forbidden (額度) | API 額度用盡 | 充值或升級方案 |
| 403 Forbidden (權限) | 金鑰缺乏請求模型的存取範圍 | 重新生成具有正確權限的金鑰 |
開發者常在此處混淆。因額度不足導致的 403 與因權限不足導致的 403 使用相同的錯誤碼,但解決方案截然不同。不要只看狀態碼,務必完整閱讀回應內容中的錯誤訊息,以釐清問題所在。
在 Atlas Cloud 等平台上,單一 API 金鑰即可涵蓋所有模型,這意味著「驗證漂移」(即 Provider A 的金鑰可用,但 Provider B 的金鑰已過期)的情況將不復存在。
速率限制錯誤 (429)
影片 API 的速率限制比文字 API 更嚴苛,因為每個請求都會佔用一個 GPU 插槽長達 30–90 秒。少量的併發請求就可能耗盡帳面上看起來很寬裕的額度。
需優先釐清的關鍵指標:
- RPM (每分鐘請求數): Google Veo 3.1 API 的正式模型通常允許 50 RPM;預覽版模型則限制為 10 RPM,且每個專案最多 10 個併發請求。
- 併發請求限制: 即使在 RPM 額度內,若超過併發限制,仍會收到 429 錯誤。
- TPM (每分鐘 Token 數): 影片模型較少見,但在具備統一計費模態的平台上則需注意。
有效的解決策略:
| 策略 | 適用情境 | 不適用情境 |
|---|---|---|
| 指數退避與重試 (Exponential back-off) | 因瞬時流量高峰導致的 429 | 當瓶頸在於併發數限制時 |
| 流量平滑化 / 請求佇列 | 高流量批次流水線 | 互動式、對延遲敏感的 UX |
| 離峰排程 (批次處理) | 內容預生成工作流 | 即時生成需求 |
| 模型路由至負載較低的變體 | 具備多個等效模型的統一平台 | 單一供應商架構 |
內容政策與安全過濾器拒絕
這類錯誤容易被誤診,因為 API 回應有時並不明確,可能只是回傳的片段比你要求的少。Google Veo 文件明確指出,若回傳的影片數量少於預期,部分輸出可能已被安全過濾器攔截,而非傳輸層級請求失敗。
兩個主要觸發面:
- 視覺提示詞: 主題內容、場景語境,或隱含的暴力/露骨內容。
- 音訊/對話提示詞: 語音內容、歌曲請求及密集的聲景會觸發獨立的過濾器堆疊。
如果你的片段僅在包含音訊提示時失敗,請將音訊與視覺場景拆開除錯。針對被政策攔截的提示詞進行重試通常無效,必須修改提示詞本身。
傳輸與基礎設施錯誤 (500, 503, 504)
| 錯誤碼 | 典型解決時間 | 建議做法 |
|---|---|---|
| 429 RESOURCE_EXHAUSTED | 1–5 分鐘 | 退避後重試 |
| 503 Service Unavailable | 30–120 分鐘 | 等待;檢查狀態儀表板 |
| 504 Gateway Timeout | 不定 | 重試前先確認渲染任務是否仍在處理中 |
| 500 Internal Server Error | 不定 | 記錄 Prediction ID;未確認狀態前切勿自動重試 |
處理 500/504 錯誤的黃金法則:重試前務必確認渲染任務是否仍在進行中。針對 504 錯誤進行盲目重試可能導致重複渲染並造成費用加倍。
輸出品質失效
這類情況並非 HTTP 錯誤——API 回傳 200,但輸出結果異常。常見形式如下:
- 視覺瑕疵或幾何失真: AI 影片具有機率性,模型是解讀輸入內容而非進行物理運算。
- 支援音訊的模型卻無聲音: 通常是提示詞或參數問題,而非基礎設施故障。
- 持續時間或解析度錯誤: 觸發了不支援的組合——並非所有模型都支援所有時間/解析度組合。
- 流水線靜默丟棄: 部分編碼流水線會在特定格式下靜默丟棄影片,僅在 QA 階段被發現。
讀取非同步回應:Prediction ID 與狀態輪詢
AI 影片生成天生即為非同步。請求-回應週期分為兩個階段:
- POST 至生成端點 → 接收一個 prediction_id
- GET 結果端點並帶上該 ID → 持續輪詢直到進入最終狀態
Atlas Cloud 的回應結構展示了已完成的預測結果:
plaintext1{ 2 "id": "pred_abc123", 3 "status": "completed", 4 "model": "bytedance/seedance-2.0/text-to-video", 5 "outputs": ["https://storage.atlascloud.ai/outputs/result.mp4"], 6 "metrics": { "predict_time": 45.2 }, 7 "created_at": "2025-01-01T00:00:00Z", 8 "completed_at": "2025-01-01T00:00:45Z" 9}
三種最終狀態:
| 狀態 | 含義 | 動作 |
|---|---|---|
| completed | 渲染成功;可獲取輸出內容 | 在過期前下載 |
| failed | 渲染失敗;請檢查 error 欄位 | 記錄錯誤訊息;評估是否重試 |
| expired | 輸出內容已過期不可用 | 若仍需要則重新提交 |
最常見的輪詢錯誤
開發者經常檢查 status === "failed",卻從不讀取隨後出現的 error 欄位。該欄位內含可操作的資訊——若缺少它,你只知道渲染失敗,卻無法判斷是該修改提示詞、檢查額度,還是等待基礎設施恢復。
生產環境可用的輪詢模式
plaintext1import time 2import requests 3 4def poll_prediction(prediction_id: str, api_key: str, max_wait: int = 600) -> dict: 5 url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 6 headers = {"Authorization": f"Bearer {api_key}"} 7 terminal_states = {"completed", "failed", "expired"} 8 wait = 5 9 10 for _ in range(max_wait // wait): 11 resp = requests.get(url, headers=headers).json() 12 status = resp.get("status") 13 14 if status in terminal_states: 15 if status == "failed": 16 print(f"Render failed: {resp.get('error')}") 17 return resp 18 19 time.sleep(wait) 20 wait = min(wait * 1.5, 60) # 將退避時間限制在 60 秒內 21 22 raise TimeoutError(f"Prediction {prediction_id} did not complete within {max_wait}s")
在每次渲染完成後記錄 metrics.predict_time。此數值的飆升是基礎設施效能下降的領先指標——在問題演變成失敗前,這是一個非常有用的訊號。
打造強韌的渲染流水線
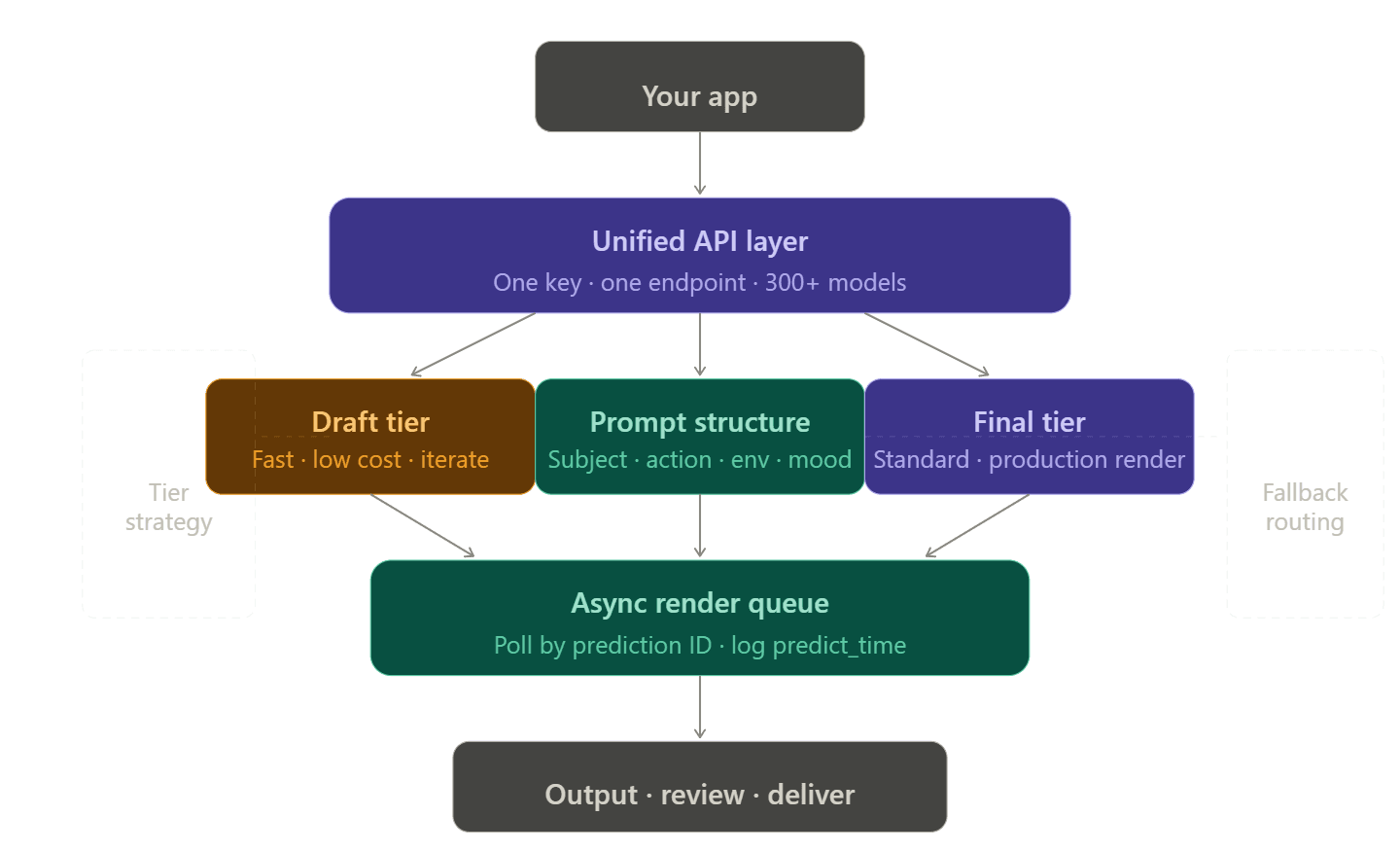
單一供應商 vs. 統一 API 架構
為每個影片供應商管理不同的帳戶、Token 與帳單頁面是非常痛苦的,開發者稱之為「整合稅」。如果不幸遇到模型額度用盡,你需要備案,而備案又需要額外的 API 金鑰、計費設定與錯誤處理程式碼。
統一 API 平台透過單一端點路由多個供應商,徹底解決此問題。在 Atlas Cloud 上,從 openai/sora-2/text-to-video 切換至 bytedance/seedance-2.0/text-to-video 僅需修改一個字串——標頭、驗證與帳單邏輯保持不變。
草稿到正式的層級分流
最有效的成本與可靠性優化策略之一,就是針對工作流的不同階段選擇合適的模型層級:
| 階段 | 推薦層級 | 原因 |
|---|---|---|
| 提示詞探索 / 概念驗證 | 快速 / 經濟版 | 比標準版省下 78% 以上成本;錯誤能以低成本發現 |
| 內部審閱草稿 | 快速版 | 對於相關利益者審閱已足夠 |
| 最終正式渲染 | 標準 / Pro 版 | 品質差異值得投資 |
| 批次內容 (社群媒體、行銷) | 快速版 | 大量產出下,成本差距顯著 |
在 Atlas Cloud 上,Seedance 2.0 的快速版成本為每秒 USD0.081,標準版則為 USD0.10,在大規模操作下差異可觀。若團隊每月生成 200 個 10 秒片段,使用快速版可省下 USD38。
以提示詞工程作為錯誤預防
模糊的提示詞是流水線失敗的隱形殺手。「一個人在走路」這類提示詞強迫模型做出太多隨意決策,導致輸出不一致,進而引發更多重試。
可靠的四組件提示詞結構:
plaintext1[主體 + 細節] + [動作 + 動作風格] + [環境 + 光影] + [鏡頭 + 氛圍] 2 3範例: 4"A woman in a red coat walking briskly through a rain-slicked Tokyo street at night, 5neon reflections on wet pavement, medium tracking shot, cinematic and tense"
在使用支援多模態輸入的模型時(Seedance 2.0 支援最多 12 個參考檔案),提供視覺參考可有效降低歧義,進而減少因輸出品質不佳導致的失敗。
選擇合適的模型
並非所有 AI 影片工具都會因相同原因失敗,因為它們的設計目標各異。在特定任務中使用錯誤的模型會導致看起來像技術故障的低品質結果,但實則是「用錯了工具」。
模型能力對照表
| 模型 | 強項 | 注意事項 | 價格 (Atlas Cloud) |
|---|---|---|---|
| Wan 2.7 | 物理模擬、真實物體互動 | 僅限單一影像參考;成本較高 | USD0.1/sec |
| Kling 3.0 | 高解析度輸出;原生對嘴;免費層級 | 最高解析度下生成時間較長 | USD0.071-0.143/sec |
| Veo 3.1 | 電影級品質;高度安全合規 | 預覽版模型速率限制 (10 RPM) | USD0.05–0.20/sec |
| Seedance 2.0 | 多參考輸入控制;原生音訊 | 需要更精確的提示詞結構 | USD0.081–0.10/sec |
| Wan 2.6 | 最低成本;高量產出 | 無原生音訊;最高 1080p | USD0.018-0.07/sec |
價格來源於 2026 年 4 月 Atlas Cloud 文件。具體價格請參閱官方網站。
何時切換模型 vs. 修正請求
當出現以下情況時,切換模型:
- 僅在包含音訊或對話時失敗,可能該模型不具備音訊能力。
- 物理或物體互動品質不佳,非提示詞問題。
- 使用預覽模型遇到了正式模型不會有的速率限制。
當出現以下情況時,修正提示詞:
- 風格不符但結構正確。
- 安全過濾器針對特定語言觸發。
- 持續時間或解析度參數遭拒。
請鎖定特定版本字串(例如 kling-v3.0-std 而非 kling-latest)。靜默的模型更新可能帶來難以除錯的品質倒退。
除錯工具箱
每個階段的日誌記錄建議
日誌是縮短除錯時間的最快途徑。最有效的最簡日誌應包含:
請求階段:
- 模型 ID 與版本
- 提示詞雜湊值 (Hash),而非完整提示詞 (保持日誌簡潔)
- 持續時間、解析度與模式參數
- 時間戳記
回應階段:
- Prediction ID
- 初始狀態
- 任何即時錯誤訊息
輪詢結束階段:
- 最終狀態
- 來自 metrics 的 predict_time
- 錯誤欄位內容 (若失敗)
- 輸出 URL (若成功)
區分基礎設施與應用錯誤
當生成失敗時,以下除錯序列可節省時間:
- 先檢查 API 健康狀態儀表板 — 若平台服務異常,你就在處理錯誤的問題了。
- 閱讀 x-deny-reason 回應標頭 — 出口代理拒絕的訊息會在此呈現,若沒檢查此欄位,看起來會像模型錯誤。
- 若從前端呼叫,請檢查 CORS 錯誤 — 在瀏覽器 DevTools 中,這與驗證失敗的症狀相同。
- 驗證檔案限制 — 大多數平台對輸入檔案大小(通常為 16 MB)與格式有限制。
Atlas Cloud 的監控面板能顯示自動擴充狀態與個別請求數據,有助於區分是基礎設施慢速的一天,還是提示詞/程式碼的問題。
成本優化
三大槓桿
渲染成本是三個變數的乘積。同時優化這三者,比單純尋找便宜模型更能節省開支:
| 槓桿 | 低成本選項 | 高成本選項 | 典型倍數 |
|---|---|---|---|
| 模型層級 | 快速版 | 標準/Pro 版 | 3–5 倍 |
| 持續時間 | 4–5 秒 | 12–15 秒 | 3 倍 |
| 解析度 | 720p | 4K | 2–4 倍 |
一個 8 秒的 4K 標準渲染,其成本可能是同時間 720p 快速版的 6-8 倍。若你的分發管道是社群媒體,使用者通常分不出 720p 與 1080p 的差異。
按量計費 vs. 訂閱制
Google AI Pro (USD19.99/月) 等消費者 AI 方案雖然透過網頁介面提供有限的影片生成功能,但不包含 API 存取權。這是許多團隊從工具轉換到生產流水線時最常犯的預算錯誤。
Atlas Cloud 採用按量計費,讓支出與實際開發規模同步。建議追蹤「成品影片每秒成本」,這是公平比較不同模型與定價層級的最佳標準。
參考資產重複使用
若你需生成許多具有相同角色、場景或風格參考的片段,請預先註冊這些資產:
- 上傳參考影像或影片一次,儲存回傳的資產 ID。
- 在後續請求中使用
asset://<ark_asset_id>,而非重複上傳。 - 大多數平台不對參考檔案上傳進行計費,僅對生成的輸出時長收費。
生產準備檢查清單
在將影片生成流水線部署至生產環境前,請驗證以下項目:
驗證
- API 金鑰從環境變數載入,非寫死。
- 金鑰具備所用模型的正確存取範圍。
- 已建立輪替策略。
速率限制與併發
- 確認每個模型層級的 RPM 與併發請求上限。
- 已為批次處理設定流量平滑化或佇列。
- 設定速率限制時的備援模型。
錯誤處理
- 已處理所有最終狀態 (completed, failed, expired)。
- 每個失敗狀態皆已擷取並記錄 error 欄位。
- 長時間渲染的子行程/請求超時設定為 ≥ 10 分鐘。
- 未確認狀態前,不進行盲目自動重試。
內容與提示詞
- 提示詞已根據平台規範預先審查。
- 音訊與視覺觸發因子已在測試中隔離。
- 採用 4 組件提示詞結構作為團隊標準。
模型配置
- 鎖定特定版本字串 (非 latest)。
- 模型層級對應工作流階段 (草稿用快速版,成品用標準版)。
- 確認選定模型所需的所有參數 (時長、解析度、音訊)。
成本控制
- 設定帶有警報的按量計費儀表板。
- 非正式渲染預設使用快速版。
- 重複使用資產時使用資產 ID。
可觀測性
- 每次渲染皆記錄 Prediction ID、狀態與 predict_time。
- 已收藏 API 健康儀表板,除錯前先查看。
- 已設定 predict_time 飆升警報。
一個具備錯誤處理能力的影片流水線,並不會比會崩潰的流水線難以打造。關鍵在於處理失敗時的智慧與細節:確保日誌紮實,並鎖定特定模型版本。在考慮其他進階功能前,先建立一套從草稿到成品的標準化流水線。
常見問題 (FAQ)
Premium 方案出現 429 Resource Exhausted 錯誤的原因?
429 錯誤表示你觸發了速率限制。為了確保系統流暢,服務商會限制你的請求與 Token 數量。
- 修正方法: 在程式碼中加入指數退避機制,讓系統能自動等待與重試。此外,檢查儀表板中的「使用層級」(Usage Tier),升級方案以解鎖更高速率。
如何避免「內容審核」誤判?
安全過濾器常會誤解技術提示詞而觸發違規。
- 修正方法: 將提示詞中的模糊詞彙改為技術術語。例如,不要說「混亂的能量」,改用「高速攝影機移動」。你也可以使用 LLM 來清理提示詞,將其轉化為機器易於理解的描述,從而避免誤判。
如何降低渲染流水線的延遲?
延遲通常來自不佳的輪詢或過大的模型。使用 Webhooks 取代手動輪詢以接收完成通知。若為自託管,可應用 FP8 量化來加速推理。若為 API 使用者,請切換至 非同步處理,以平行化處理多個生成請求而非串列執行。






