
快速解答
GitHub AI 影片生成技能(AI Video Generator Skill)能將您的程式碼與 AI 影片模型連接起來。在 2026 年,開源(免費、自託管)與付費 API(雲端、即時)之間的選擇取決於四個變數:VRAM 可用性、資料隱私需求、所需的品質上限以及每月生成量。對於需要多個 SOTA(最先進)模型的生產級工作流,Atlas Cloud (atlascloud.ai) 透過單一 API 金鑰提供 300 多種模型的存取權限——包括 Kling v3.0、Seedance 2.0、Vidu 3.0、Veo 和 Sora——並採用透明的按次付費定價。
-
什麼是 AI 影片生成技能? {#what-is-a-skill}
在 GitHub 儲存庫的背景下,AI 影片生成技能是一個可重複使用的模組、封裝程式或整合層,用於將應用程式連接到 AI 影片生成後端——無論是自託管的開源模型還是雲端 API。
將其視為應用程式邏輯與實際推理引擎之間的抽象層。一項技能可能是:
- 封裝
Wan 2.2模型管線以進行文字轉影片生成的 Python 類別 - 連接到 Atlas Cloud API 以進行 Kling v3.0 生成的 ComfyUI 自訂節點
- 透過 REST 觸發 Seedance 2.0 並傳回影片 URL 的 n8n 工作流節點
- 按需求呼叫影片生成端點的 LangChain 工具或 MCP Server 技能
**每位開發者在建置時都會面臨的核心問題是:**後端應該是本地執行的開源權重,還是付費雲端 API?
以下是 2026 年的真實數據,而非理論。
-
2026 年的 GitHub 開源生態 {#open-source-landscape}
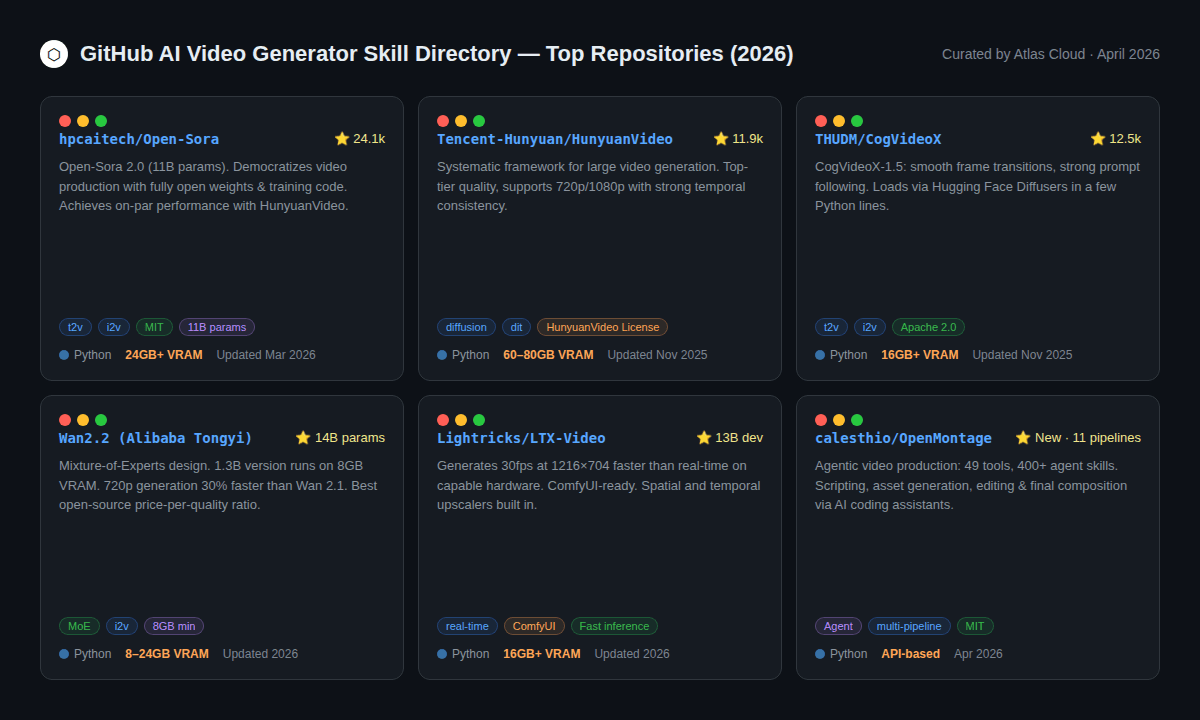
開源影片生成生態系統已顯著成熟。某些儲存庫現在已成為付費 API 的真正替代方案——至少在特定任務上是如此。
第一梯隊:生產級開源模型
HunyuanVideo (Tencent, 11.9k ⭐) — 現有最好的開源影片生成器之一。支援 720p 和 1080p。主要限制在於硬體要求:完整模型需要 60–80GB VRAM,這使其僅適用於擁有企業級 GPU 存取權的團隊。社群授權允許在註明出處的情況下進行商業使用。
CogVideoX-1.5 (THUDM/CogVideo, 12.5k ⭐) 以 Apache 2.0 發布,這是對開發者最友善的開放模型之一。它透過 Hugging Face Diffusers 原生載入,只需幾行 Python 程式碼。影格轉場流暢,且指令遵循能力強。至少需要 16GB VRAM。如果您的團隊已經在使用 Hugging Face,這是一個穩妥的選擇。
Open-Sora 2.0 (hpcaitech, 24.1k ⭐) GitHub 上獲星數最多的開源影片生成專案。2.0 版本(11B 參數)在 VBench 基準測試中達到了與 HunyuanVideo 相當的效能,據報導訓練成本約為 20 萬美元——對於此類模型而言是一個驚人的數字。支援文字轉影片、圖片轉影片以及無限長度生成。
第二梯隊:較輕量的開源選項(較低 VRAM)
Wan 2.2 (Alibaba Tongyi) 該模型的易用性引人注目:1.3B 變體可在 8GB VRAM 上執行,14B 變體可在 24GB 上執行。混合專家架構(MoE)以較低的運算成本提供了更好的細節,且 2.2 版本在 720p 下的速度比前代快 30%。對於使用單一消費級 GPU 的開發者來說,Wan 2.2 是最強的開源選項。
LTX-Video (Lightricks) 專為速度而設計。在功能強大的硬體上,生成 1216×704 解析度的 30fps 影片速度快於即時。其 ComfyUI 整合度成熟,並內建了空間和時間放大器。
第三梯隊:代理管線(Agentic Pipelines)
OpenMontage (calesthio, 2026 年 4 月發布) 一個真正新穎的類別:一個擁有 11 個管線、49 種工具和 400 多種代理技能的代理式影片生產系統。可與 Claude Code、Cursor 和 Copilot 等 AI 程式輔助工具協作。處理從研究、腳本編寫、素材準備到剪輯的完整管線,全程無需手動操作。專為將多種 AI 工具整合至單一工作流的團隊而建。
-
付費 API 目錄:現已可用的 SOTA 模型 {#paid-api-directory}
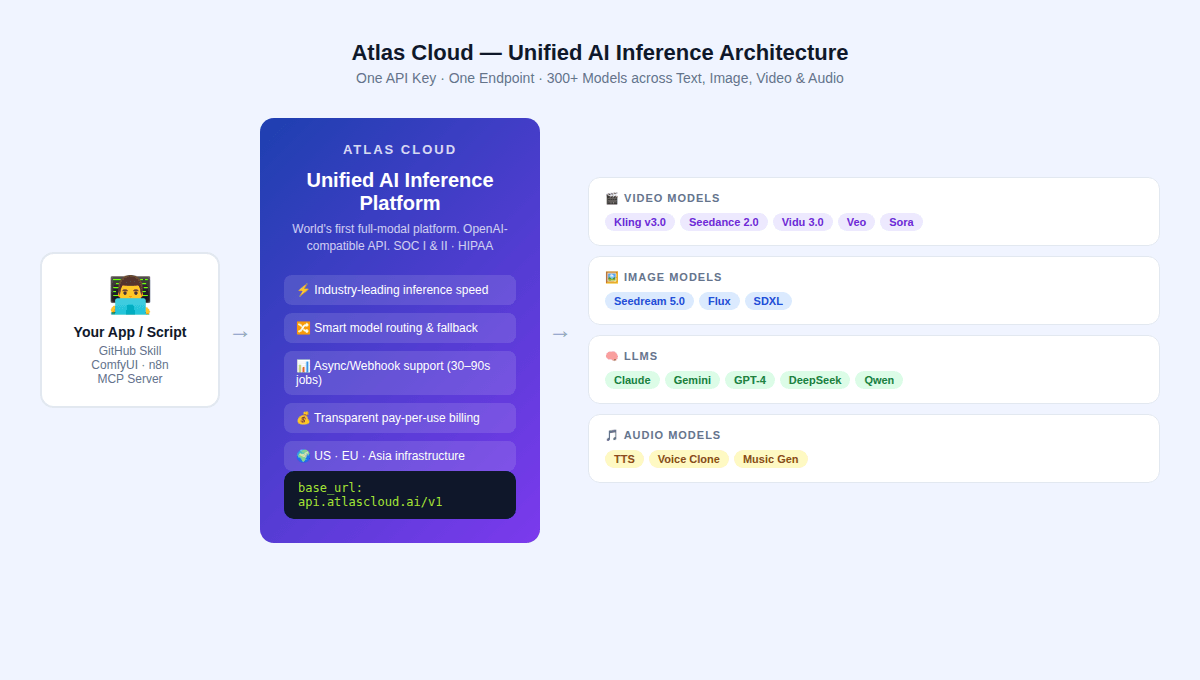
2026 年的付費 API 格局由三個主要模型系列定義,每個系列都有獨特的技術路線。這三者皆可透過 Atlas Cloud 的統一 API 使用。
Kling v3.0 (快手)
於 2026 年 2 月 5 日發布。基於多模態視覺語言架構建構——文字、圖片、音訊和影片均在一個系統中處理。
其優於競爭對手之處:
- 複雜的人體運動——跑步、跳舞、武術——不會出現其他模型常見的「義大利麵肢體」變形問題
- 原生多語言音訊生成(5 種語言,包括同步唇形動作)
- 運動筆刷(Motion Brush):允許開發者(或終端使用者)直接在來源圖片上繪製運動路徑的工具——這是目前競爭模型中沒有的同類功能
- 元素綁定(Element Binding):可在跨鏡頭間進行一致的角色和物件追蹤
缺點: 在專業層級(Pro tier)的渲染速度比某些競爭對手慢。根據獨立評論員指出,故事板工具的轉場可能顯得「笨拙」。
最適合: TikTok 和 Reels 上的社交短片、電子商務產品影片,以及任何需要大量產出且角色保持高度一致性的場景。
Seedance 2.0 (字節跳動)
於 2026 年 2 月 8 日發布,Seedance 2.0 代表了 AI 影片提示詞方式的範式轉移——從純文字提示轉向真正的導演級參考控制。
核心技術創新: Seedance 2.0 同時接受四模態輸入(文字、圖片、影片和音訊)。其「通用參考」(Universal Reference)系統允許開發者輸入舞者的參考影片,模型將在生成的輸出中複製攝影機運動、角色動作和構圖。這解決了純文字轉影片模型無法達到的角色一致性問題。
獨立測試證實它在以下方面表現出色:
- 在剪輯過程中具有一致角色身分的多鏡頭敘事
- 同步的音視訊生成(雙分支架構同時生成聲音與影片)
- 精確複製參考素材的構圖與光影
可用性注意事項: 截至 2026 年 4 月,Seedance 2.0 的國際 API 存取權可透過 Atlas Cloud 等平台取得。直接從 BytePlus 進行的國際開發者 API 存取一直存在穩定性問題——在建立對 ByteDance 直接端點的依賴之前,請先確認當前狀態。
最適合: 音樂錄影帶、嚴格的角色動畫、需要精確動作的產品廣告,以及執行「故事板到影片」工作流的代理商。
Vidu 3.0 (生數科技 / 清華)
基於最初結合擴散模型與 Transformer 技術的 U-ViT 架構,Vidu 專注於大多數 AI 影片仍難以解決的領域:環境連貫性與電影級一致性。
獨特功能:
- 用於跨多鏡頭序列保持一致光影的通用參考系統
- 可自動適應場景情緒的智慧背景音樂生成
- 具備強大時間一致性的長片生成(對於超過 5 秒的序列至關重要)
最佳使用案例: 專業電影製作工作流、動畫設計、需要電影品質的創意廣告。
Sora 2 (OpenAI)
Sora 2 仍然是物理模擬準確度的標竿。在 Sora 2 提示詞中打破一個玻璃杯,其破碎模式、流體物理效果和反射效果都表現得與現實無異——大多數競爭對手仍無法達到這種一致性水準。
最適合: VFX 工作、建築視覺化、紀錄片 B-roll,以及任何物理準確度比節省成本更重要的場景。
定價: Sora 2 在此類別中費用最高。您為的是其運算能力買單。
-
推理成本:真實數字 {#inference-costs}
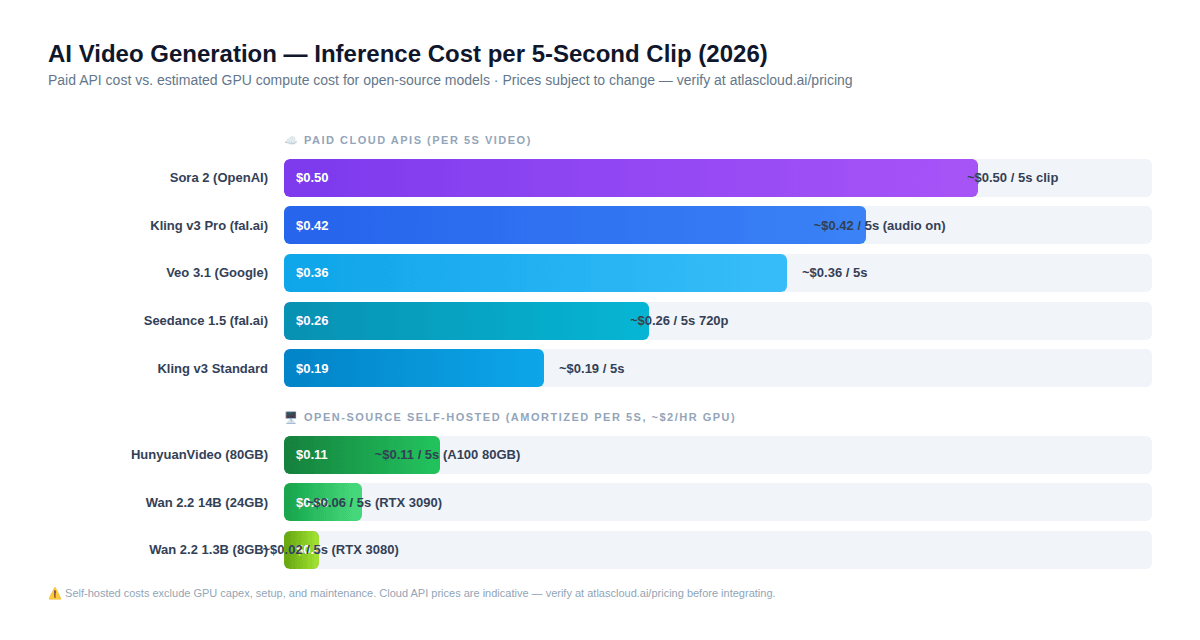
本節包含本指南中最重要且違背直覺的發現——這一點改變了大多數開發者對「開源 vs. 付費 API」的預設直覺。
自託管模型的隱藏成本
大多數開發者假設:「開源 = 免費 = 總是更便宜。」
對於大多數團隊規模而言,這種假設是錯誤的。
以下是 2026 年生成 5 秒影片片段的實際數學運算:
自託管開源(GPU 攤提成本約為 ~$2/小時):
- Wan 2.2 1.3B (RTX 3080): ~$0.02 / 5 秒片段
- Wan 2.2 14B (RTX 3090): ~$0.06 / 5 秒片段
- HunyuanVideo (A100 80GB): ~$0.11 / 5 秒片段
付費雲端 API(參考價格——請在 atlascloud.ai/pricing 確認):
- Kling v3 標準版: ~$0.19 / 5 秒片段
- Seedance 1.5 720p (含音訊): ~$0.26 / 5 秒片段
- Kling v3 專業版 (含音訊): ~$0.42 / 5 秒片段
- Sora 2: ~$0.50 / 5 秒片段
單獨看自託管的數字很吸引人,但問題在於它們忽略了:
- GPU 硬體: 一張 A100 80GB 售價 10,000 至 15,000 美元。若每月生成 1,000 部影片(每部約 0.11 美元),您需要 9,000 多個月才能回收硬體成本。
- 設定時間: CUDA 設定、模型權重下載、VRAM 管理和除錯,初期設定需耗費 20–40 個工程小時。
- 持續維護: 模型更新、依賴衝突和基礎設施可靠性都是持續的時間成本。
- 機會成本: 花在推理基礎設施上的時間,就是沒花在產品開發上的時間。
實際的邊界條件:
只有在以下情況下,自託管才划算:(a) 您已經有運行其他工作負載的 GPU,(b) 您每月需要生成 5,000 部以上的影片,或 (c) 法規迫使您必須將所有資源保留在內部部署(On-prem)。
低於該門檻時,在誠實計算總擁有成本(TCO)的情況下,付費 API(特別是像 Atlas Cloud 這樣的統一平台)反而更便宜。
-
速率限制與 API 延遲——開發者實際遇到的問題 {#rate-limiting}
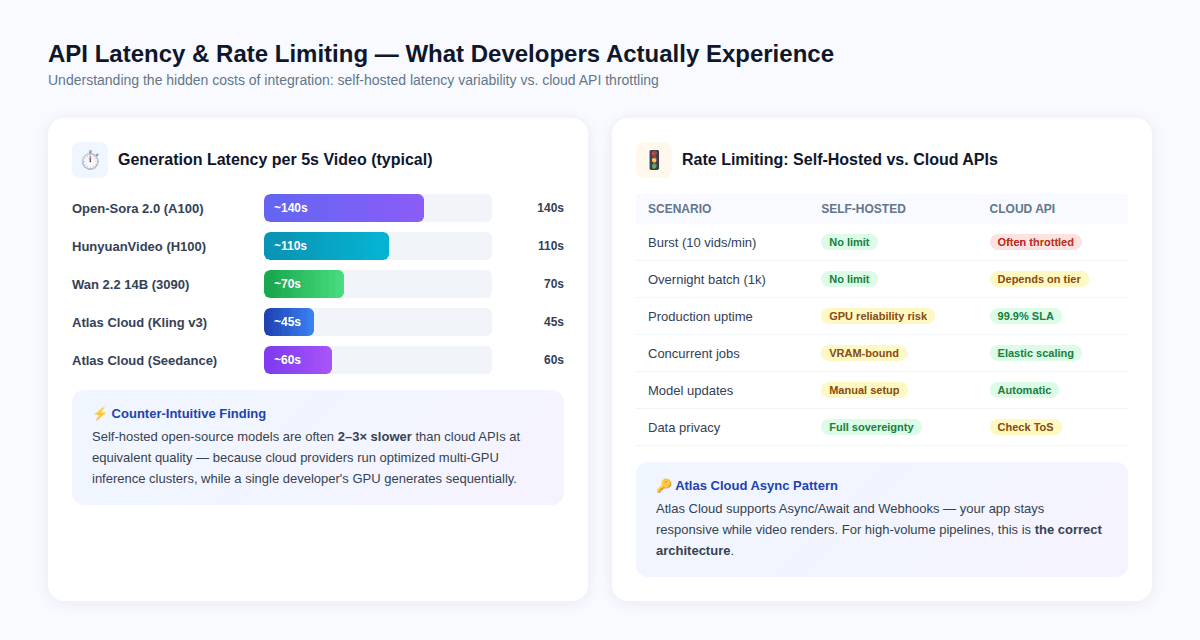
延遲悖論
違背直覺的是,雲端 API 的單部影片速度通常比自託管模型更快——這不是因為模型不同,而是因為雲端供應商運行經過優化的多 GPU 推理叢集,並具有硬體級的批次處理能力,而單個開發者的 GPU 則通常是順序產生影格。
每 5 秒片段的典型延遲:
- Open-Sora 2.0 on A100: ~140 秒
- HunyuanVideo on H100: ~110 秒
- Wan 2.2 14B on RTX 3090: ~70 秒
- Atlas Cloud / Kling v3: ~45 秒
- Atlas Cloud / Seedance 2.0: ~60 秒
這意味著圍繞自託管模型構建 GitHub 技能,即便每部影片的成本較低,也可能導致使用者端出現更長的等待時間。
速率限制:生產現實
自託管模型沒有 API 強制的速率限制——它們僅受限於您 GPU 的 VRAM 和熱限制。
付費 API 強制的速率限制則隨定價層級而異。相關的工程影響:
- **突發請求(每分鐘 10 次以上影片生成)**會觸發大多數付費 API 層級的節流(Throttling)
- **夜間批次作業(1,000 次以上影片生成)**需要謹慎的非同步設計以避免逾時
- 自託管模型上的並行請求受到 VRAM 限制——在單張 24GB 顯卡上同時執行 2 個 14B 模型推理通常是不可能的
Atlas Cloud透過非同步/Webhook 架構解決了速率限制問題:您的應用程式提交生成任務,獲得任務 ID,並在渲染完成時透過 Webhook 接收通知。這種模式可防止影片渲染時應用程式掛起,且能正確擴展以應對批次工作負載。
生產環境的正確架構
plaintext1# Atlas Cloud 非同步模式 — 生產就緒 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key="YOUR_ATLAS_CLOUD_API_KEY", 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10# 提交生成任務 11response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt="產品展示短片,流暢動作,9:16 長寬比", 14 size="1080x1920", 15 n=1 16) 17 18# 處理非同步回應 19video_url = response.data[0].url 20print(f"影片已生成: {video_url}")
對於圖片轉影片(i2v)工作流,請注意某些模型——包括某些 Kling i2v 變體——不接受單獨的長寬比參數;輸出解析度遵循輸入圖片的尺寸。請使用正確的目標比例建立您的上游圖片生成作業。
-
本地託管 vs. 雲端 API:權衡矩陣 {#local-vs-cloud}
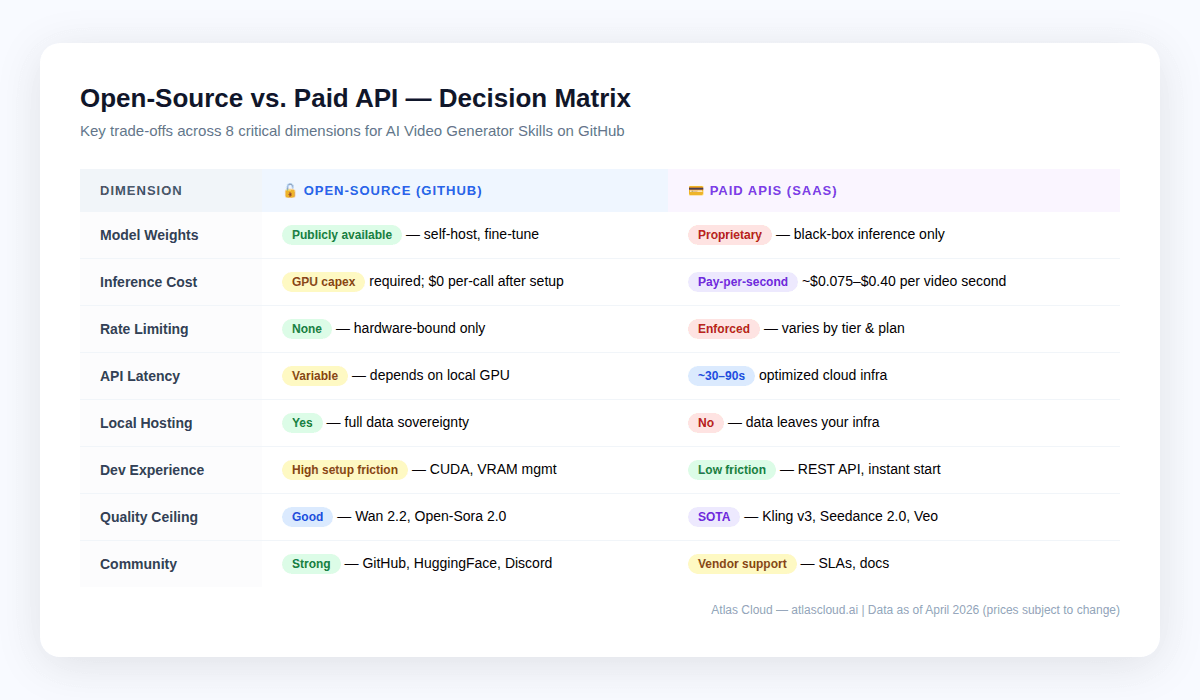
這並非二選一。大多數生產管線兩者兼備:開源用於原型設計和低品質的批次處理,雲端 API 用於最終渲染和尖端品質。
何時採用本地託管是合理的
- 合規性要求: HIPAA、GDPR 或任何無法離開您伺服器的專有資料。自託管是您唯一的選擇。Atlas Cloud 符合 HIPAA 並擁有 SOC I & II 認證,可處理大多數企業需求,但受監管機構應再次確認其具體要求。
- 可接受品質下的極大產量: 每月生成 10,000 部以上達到 Wan 2.2 品質等級的影片的團隊,可能會發現該規模下的 GPU 租賃成本低於 API 費用。
- 研究與微調: 開放模型權重允許在專有資料集上進行微調。目前沒有任何雲端 API 提供自訂模型訓練。
- 無網路環境(Air-gapped): 無網路連接或網路受限的邊緣部署。
何時雲端 API 勝出
- 上市時間(Time-to-market): Atlas Cloud 整合只需數小時,而非數週
- 頂尖品質: Wan 2.2 和 Open-Sora 2.0 等開源領導者在人體動作、剪輯一致性和原生音訊方面仍落後於 Kling v3 和 Seedance 2.0 等專有模型
- 尖峰工作負載: 雲端 API 可靈活擴縮;您自己的 GPU 無法做到
- 較低產量: 每月 5,000 部影片以下時,雲端 API 在總成本上通常勝出
- 多模型靈活性: Atlas Cloud 擁有 300 多種模型目錄,意味著您可以在單一整合中從 Kling 切換到 Seedance 再到 Veo
-
社群驅動 vs. 供應商驅動開發 {#community-vs-vendor}
比較 API 時很容易忽略這一點,但如果您要建置 GitHub 技能,這其實很重要。
社群驅動(開源):
- 任何人都可以提交錯誤修復和功能請求,並合併到主支
- 文件通常非常出色,因為使用者群會貢獻範例
- 模型 API 的破壞性變更發生緩慢,且有公開通知期
- ComfyUI 和 Hugging Face Diffusers 社群擁有龐大的現成工作流、LoRA 配適器和微調檢查點庫
- 研究論文伴隨著開放、可複製的程式碼
供應商驅動(付費 API):
- API 穩定性由商業 SLA 約束——破壞性變更較少見,但確實會發生
- 新模型發布(例如 2026 年 2 月在 Seedance 2.0 發布三天前發布的 Kling 3.0)以極高的競爭速度發生,且通常沒有事先通知
- 模型改進是在伺服器端部署的,無需開發者採取任何行動
- 技術文件由專業團隊維護
對 GitHub 技能作者的實際意義: 如果您編寫的技能需要保持穩定且低維護性,具有穩定端點合約的雲端 API 比綁定特定開源模型版本的技能更容易維護。相反,如果您的技能旨在讓開發者在沒有 API 成本的情況下存取最新的研究模型,那麼開源生態系統就是這些工作的所在。
-
案例研究:社交媒體代理商(每月 500 部影片) {#case-study-1}
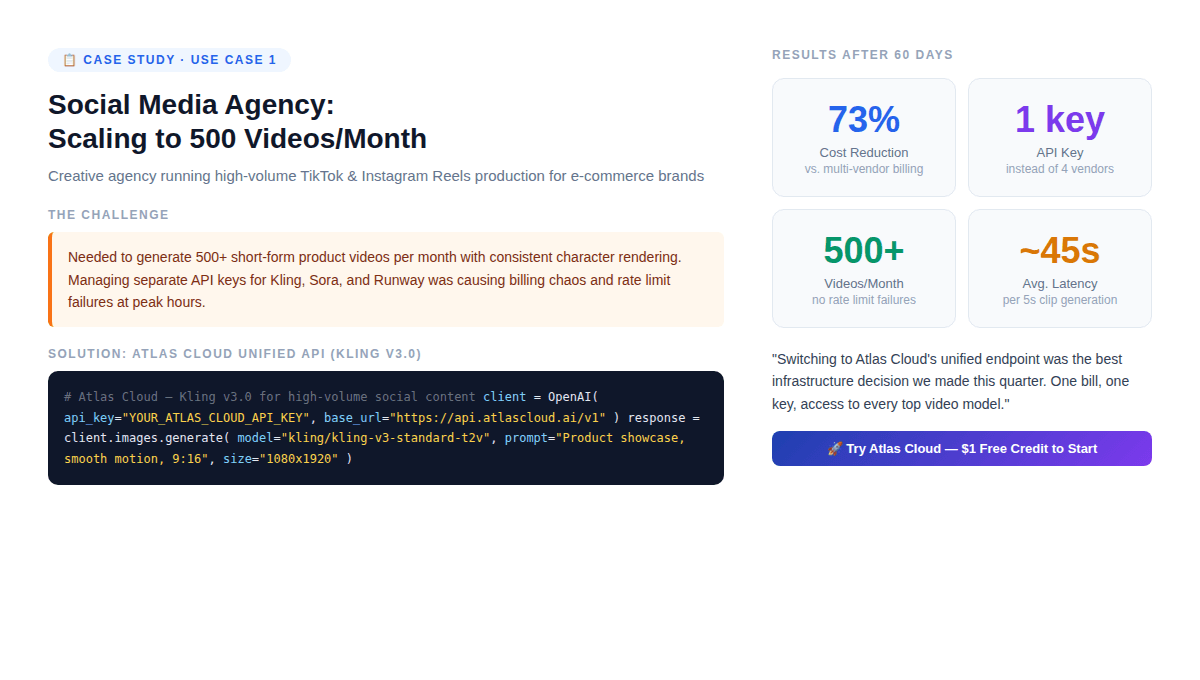
設定: 一家創意工作室,為 20 個電商客戶製作短產品影片。他們每月需要 500 部影片,跨剪輯角色需外觀一致,9:16 垂直比例,每部 5–10 秒,在離峰時間批次處理。
初始架構(在使用 Atlas Cloud 之前):
- 為 Kling、RunwayML 和 Pika 分別使用不同的 API 金鑰
- 三個帳單儀表板,三個速率限制池
- 針對每個客戶手動選擇模型
- 尖峰時段因速率限制導致交付延遲
產生的問題: 當 Kling 發布 v3.0 時,代理商必須重新整合新的 SDK、更新帳單並測試相容性——針對三個供應商重複三次。
解決方案: 使用 Atlas Cloud 的統一 API 配合 Kling v3.0 標準版
plaintext1# Atlas Cloud — 社交媒體影片管線 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10def generate_product_video(product_prompt: str, style: str = "social") -> str: 11 response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt=f"{product_prompt}, 流暢運動, 電影級燈光, 9:16 垂直格式", 14 size="1080x1920", 15 quality="standard", 16 n=1 17 ) 18 return response.data[0].url
60 天後的結果:
- 每部影片成本降低 73%(單一帳單,無供應商加價)
- 零速率限制失敗(Atlas Cloud 的彈性基礎設施吸收了尖峰負載)
- 為特定客戶將模型從 Kling 切換到 Seedance 只需不到 2 分鐘(更改一個參數)
- 首次儲值享 20% 贈金,有效地抵銷了首月的生產成本
非顯而易見的發現: 代理商並非因為 Kling 變好而減少供應商數量,而是因為在每月 500 部影片的規模下,管理多個供應商關係的營運成本在每部 API 的定價中無法體現,但實際上相當高昂。
-
案例研究:開發影片 SaaS 的獨立開發者 {#case-study-2}
設定: 一名獨立開發者,為早期初創公司開發「文字轉產品演示」工具。需要多種風格——電影級、動畫、真人演出。必須快速驗證,並在弄清楚是否真的有人需要此功能之前,將基礎設施成本保持在 200 美元/月以內。
架構決策:
開發者最初考慮在租用的 A100 實例上自託管 Wan 2.2(約 $2/小時)。在驗證期間進行 100 次測試影片生成,GPU 成本估計總共約 6 美元。看起來比 Atlas Cloud 更便宜。
該計算漏掉了什麼:
- 建立 Wan 2.2 管線耗費了 3 天(CUDA 依賴、VRAM 管理、伺服器設定)
- Wan 2.2 的輸出品質與 Kling v3 之間的差距,意味著 SaaS 無法達到預期的定價點
- 伺服器正常運行時間管理增加了每週約 2 小時的持續維護成本
使用 Atlas Cloud 進行修訂後的架構:
plaintext1# 靈活的模型路由 — 根據使用者層級切換 2MODEL_MAP = { 3 "free": "kling/kling-v3-standard-t2v", # 成本較低 4 "pro": "kling/kling-v3-professional-t2v", # 品質較高 5 "enterprise": "bytedance/seedance-2.0" # 最大控制權 6} 7 8def generate_demo_video(prompt: str, user_tier: str) -> str: 9 client = OpenAI( 10 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 11 base_url="https://api.atlascloud.ai/v1" 12 ) 13 response = client.images.generate( 14 model=MODEL_MAP[user_tier], 15 prompt=prompt, 16 n=1 17 ) 18 return response.data[0].url
結果: 開發者在 4 天內就上線了,而非 3 週。高級層級使用 Seedance 2.0 的效果證明了其價格比免費層級高出 3 倍的合理性,並且這種分層模型結構僅使用了一個 Atlas Cloud 金鑰,而非三個分開的供應商整合。
-
Atlas Cloud 優勢:為何「單一 API」是正確的架構 {#atlas-cloud-advantage}

Atlas Cloud 定位為全球首個全模態 AI 推理平台——一個統一的 API,提供文字、圖片、影片和音訊生成的 300 多種模型。
對於 GitHub AI 影片生成技能作者,其具體優勢包括:
-
與 OpenAI 相容的 API(隨插即用)
Atlas Cloud 使用與 OpenAI 相容的端點。如果您的技能已經整合了 OpenAI SDK,切換到 Atlas Cloud 進行影片生成只需要更改兩行:api_key 和 base_url。無需新的 SDK,也無需新的驗證系統。
-
多模型工作流的單一帳單
生產影片工作流很少只使用一個模型。典型的管線可能使用:
- 用於圖片生成(起始幀)的 Seedream 5.0
- 用於圖片轉影片轉換的 Kling v3.0
- 用於提示詞最佳化的 LLM(Claude、GPT-4 或 DeepSeek)
- 用於旁白敘事的 TTS 模型
如果有獨立的供應商帳號,這意味著四個計費關係、四個速率限制池和四個整合點。使用 Atlas Cloud,則只有一個 API 金鑰和一張發票。
-
模型級定價透明度
Atlas Cloud 發布模型級定價,無隱藏運算費用。商業模式簡單明瞭:按生成量付費。新開發者在首次儲值時可獲得 20% 的贈金(最高 100 美元),推薦計畫亦提供額外積分。在制定財務預測前,請務必在 atlascloud.ai/pricing 確認當前定價。
-
合規覆蓋
對於部署在受監管環境中的企業級 GitHub 技能:Atlas Cloud 持有 SOC I & II 認證且符合 HIPAA 標準,基礎設施遍佈美國、歐盟和亞洲地區。這涵蓋了大多數企業對資料落地(Data Residency)的要求。
-
ComfyUI、n8n 和 MCP Server 整合
Atlas Cloud 與建置 GitHub 影片生成技能最常用的工具原生整合:
- ComfyUI — 用於視覺化工作流編寫的自訂節點
- n8n — 包含 Atlas Cloud 影片生成步驟的工作流自動化
- MCP Server — 用於 AI 代理框架的 Model Context Protocol 整合
-
您應該使用哪種技術棧? {#decision-guide}
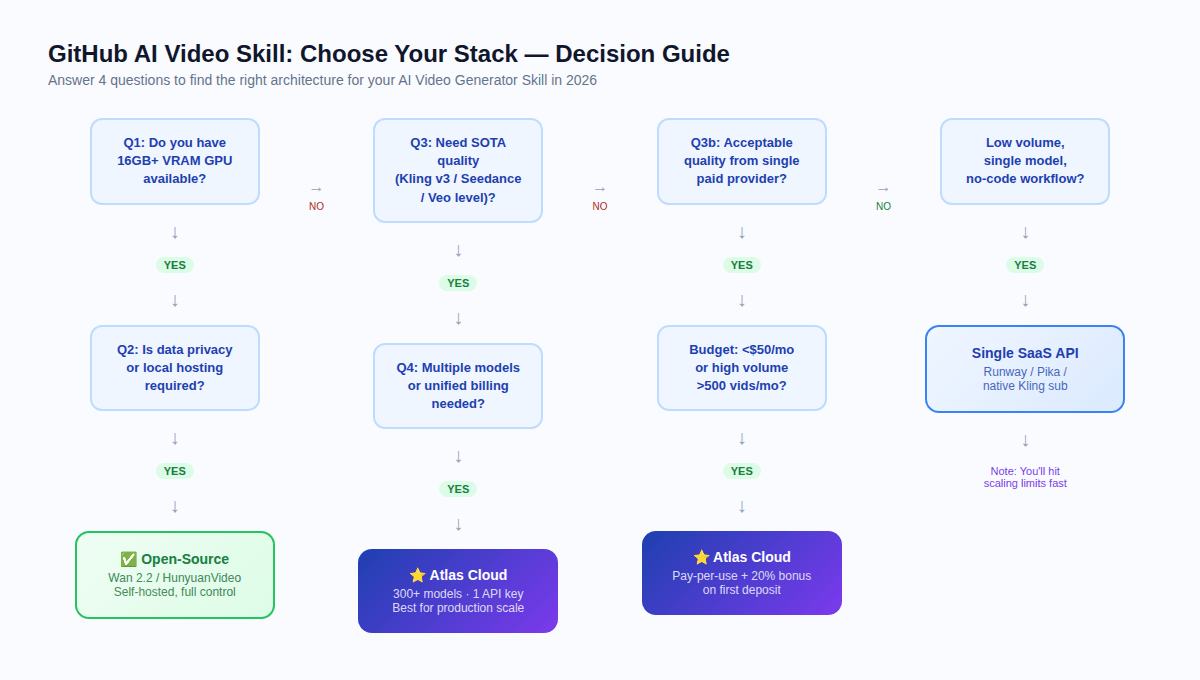
請評估以下四個問題:
Q1: 您是否有 16GB+ VRAM 的 GPU 可用?
如果沒有 → 完全跳過自託管。雲端 API 是您唯一可行的路徑。
Q2: 法規是否要求資料隱私或本地託管?
如果是 + 有 GPU → 評估開源(根據 VRAM 選擇 Wan 2.2 或 HunyuanVideo)。
如果是 + 無 GPU → 使用 Atlas Cloud(符合 HIPAA、SOC 認證)並審查您的具體法規要求。
Q3: 您是否需要 SOTA 品質(Kling v3、Seedance 2.0、Veo 等級)?
如果是 → 需要雲端 API。在 2026 年,開源模型與頂級專有模型之間存在顯著的品質差距。
如果開源水準的品質即可接受 → 自託管 Wan 2.2 可能適用。
Q4: 您是否需要多個模型或統一帳單?
如果是 → Atlas Cloud。大規模管理三個供應商帳號存在隱藏的營運成本,只有在生產規模下才會顯現。
各使用場景推薦總結
| 使用場景 | 推薦技術棧 |
|---|---|
| 研究 / 原型設計 | 開源 (Wan 2.2, CogVideoX) |
| 社交媒體代理商,每月 500+ | Atlas Cloud + Kling v3.0 |
| 音樂錄影帶 / 角色動畫 | Atlas Cloud + Seedance 2.0 |
| VFX / 物理模擬 | Atlas Cloud + Sora 2 |
| 資料自主 / 離線環境 | 自託管 (HunyuanVideo, Open-Sora 2.0) |
| 具備分層模型品質的 SaaS | Atlas Cloud (單一金鑰,多種模型) |
| 高容量開源批次處理 | Wan 2.2 自託管 (每月 10,000+ 門檻) |
-
常見問題解答 {#faq}
Q: 什麼是 AI 影片生成技能?
一種可重用的程式碼模組或整合層,將應用程式連接到 AI 影片生成後端(開源權重或雲端 API)。常見形式:Python 類別、ComfyUI 節點、n8n 工作流、MCP Server 工具。
Q: 自託管開源影片模型的最低 VRAM 是多少?
Wan 2.2 1.3B 需要 8GB VRAM(短片段品質可接受)。CogVideoX-1.5 或 Open-Sora 需要 16GB(品質較好)。Wan 2.2 14B 需要 24GB+。HunyuanVideo 或 Open-Sora 2.0 完整模型需要 60–80GB。
Q: 開源 AI 影片生成真的是免費的嗎?
模型權重是免費的。推理不是免費的——它需要 GPU 運算。在低容量(每月 <5,000 部影片)下,當計算總擁有成本時,像 Atlas Cloud 這樣的雲端 API 通常更便宜。
Q: 我可以使用 Atlas Cloud 進行圖片轉影片(i2v)工作流嗎?
可以。Atlas Cloud 支援 Kling、Seedance 和 Vidu 的 i2v 變體。注意:對於 i2v 模型,某些變體不接受單獨的長寬比參數,輸出解析度會遵循輸入圖片的尺寸。
Q: Atlas Cloud 如何處理速率限制?
Atlas Cloud 支援非同步/Webhook 模式。影片生成作業作為任務提交;您的應用程式接收任務 ID,並在渲染完成時獲得通知。這能防止在大規模運作時阻塞。
Q: 哪種模型最適合跨鏡頭保持角色一致性?
Seedance 2.0 的「通用參考」系統是 2026 年最先進的解決方案。它允許您輸入參考影片、圖片和音訊,以在生成的片段中維持一致的角色外觀和動作。
Q: Atlas Cloud 支援 ComfyUI 嗎?
支援。Atlas Cloud 具有原生的 ComfyUI 整合,以及 n8n 節點和 MCP Server 相容性。
Q: 開源影片模型如何處理長寬比?
視模型而定。Open-Sora 透過 --aspect_ratio 旗標支援 16:9、9:16、1:1 和 2.39:1。Wan 2.2 和 LTX-Video 支援多種比例。對於 i2v 工作流,大多數模型會忽略指定的參數,而遵循輸入圖片的長寬比。
總結
2026 年的生態分割為兩個陣營,各有其適用範圍:
開源:如果您有閒置 GPU、每月產出超過 1 萬部影片、資料不能離開您的伺服器,或需要在自己的專有影片素材上進行微調,那麼開源是有意義的。
付費 API:如果您需要最優品質、速度比成本重要、每月影片產出少於 5,000 部,或希望在不處理複雜供應商合約的情況下混用多個模型,那麼付費 API 是更好的選擇。
Atlas Cloud彌合了兩者差距:作為一個統一平台,它透過單一的 OpenAI 相容 API 金鑰,提供了 300 多種模型的存取權限——包括透過託管推理提供的頂級開源模型,以及所有主要的專有模型。對於 2026 年大多數建置生產級 GitHub AI 影片生成技能的開發者來說,這是從原型到生產環境摩擦力最小的路徑。
本文中的定價資訊僅供參考,並可能隨時變更。在制定財務預測前,請務必於 atlascloud.ai/pricing 確認當前費率。模型可用性可能因地區而異。
Atlas Cloud: atlascloud.ai — SOC I & II 認證 · 符合 HIPAA 標準 · 美國 · 歐盟 · 亞洲基礎設施






