
我們使用 6 組相同的「模型中立」提示詞(Prompt)對 Grok Imagine Image 和 GPT Image-2 模型進行了測試。這些提示詞涵蓋了組合語義、逼真解剖結構、多語言文字渲染、幾何變換、局部編輯以及多參考圖融合等範疇。
Grok Imagine Image 與 GPT Image-2 模型均可透過單一 Atlas Cloud API 金鑰使用,這意味著本基準測試的完整過程可在幾分鐘內重現。
為什麼要進行這項 AI 圖像模型比較基準測試?
網路上所有的「AI 圖像模型比較」往往都掉進了同一個陷阱:刻意挑選的提示詞、從五張中選一張最好的結果,以及未經實證的宣稱。本基準測試基於 Tier A 原則建立:使用模型中立的提示詞、所有模型採用相同的輸入、單一隨機種子(Seed)預設輸出(拒絕刻意挑選),並制定了每個類別可用一句話描述的評分標準。
本次完整測試包含六個模型:Grok、GPT Image 2、Nano Banana 2、Nano Banana Pro、Wan 2.7 和 Seedream 5.0。本文將重點放在 Grok 與 GPT Image 2 的正面對決,因為對於需要選擇預設圖像模型的開發者而言,這是最具商業參考價值的組合。
我們如何測試 Grok Imagine Image 與 GPT-Image 2:6 個類別,一項 Tier A 原則
每個提示詞都針對一個明確的能力維度。通過/失敗(Pass/Fail)標準是在執行模型之前定義的,而非在看到輸出結果後才設定。
| 類別 | 測試的主要維度 | 通過/失敗標準(一句話) |
|---|---|---|
| 類別 1 · 組合語義 | 指令對齊能力 | 模型是否數出了 7 個物體,放置位置正確,並遵守了否定清單? |
| 類別 2 · 逼真解剖與光影 | 視覺品質與物理特性 | 5 根手指是否解剖結構正確,臉部是否出現焦散光影? |
| 類別 3 · 多語言海報 | 圖像內文字渲染 | 中英文是否渲染正確,有無漏筆畫或產生幻覺字體? |
| 類別 4 · 幾何變換 (I2I) | 編輯可控性 + 身分一致性 | 旋轉 45 度後,是否仍為同一人且衣著細節完整? |
| 類別 5 · 局部編輯與區域保留 | 編輯精確度 | 是否僅進行了 3 處編輯,且其餘像素完全未變? |
| 類別 6 · 多參考圖融合 | 跨圖像一致性 | 3 個不同參考圖的身分、風格和場景是否融合為一張連貫圖像? |
類別 1 · 組合語義(T2I)
提示詞:
A flat-lay overhead photograph of a wooden dining table containing exactly seven ceramic objects: three identical white teacups arranged in an equilateral triangle in the center, two black bowls placed to the right of the teacups, one red apple sitting inside the leftmost black bowl, and one empty wooden spoon resting on top of the rightmost black bowl with its handle pointing toward the upper-left corner of the frame. No coffee cups, no metal items, no plates, no glassware. Soft diffused window light from the upper-left, mid-morning. Realistic photography, no styling props.
(要求生成一張俯視平鋪照片,畫面中嚴格包含七件陶瓷器皿,並有明確的空間關係:三只白色茶杯呈等邊三角形排列居中,兩只黑碗在茶杯右側,一顆紅蘋果放在最左邊的黑碗裡,一把木勺搭在最右邊的黑碗上且柄朝左上方。否定指令:不得出現咖啡杯、金屬器具、盤子、玻璃器皿。)
這項測試具有刻意針對性。對於現有的基於擴散模型(Diffusion-based)的架構而言,計數、空間語言(「右側」、「最左邊」)以及否定子句一直都是已知的弱點。
評分檢查清單
| # | 準則 | 檢查 |
|---|---|---|
| 1 | 物體總數 | 嚴格為 7 件陶瓷器皿 |
| 2 | 三只白茶杯 | 等邊三角形排列 |
| 3 | 兩只黑碗 | 位於茶杯右側 |
| 4 | 紅蘋果 | 位於最左邊黑碗內 |
| 5 | 木勺 | 位於最右邊黑碗上,柄指向左上方 |
| 6 | 否定合規性 | 無咖啡杯 / 無金屬 / 無盤子 / 無玻璃器皿 |
| 7 | 光源 | 左上方柔和漫射光,陰影一致 |
| 8 | 攝影風格 | 無造型道具(棕櫚葉、蠟燭等) |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 物體計數: 肉眼可見 5 個茶杯(非 3 個),且以聚簇方式排列而非等邊三角形。兩只黑碗存在,紅蘋果正確地放在其中一個碗內。木勺存在且位於最右側碗上,柄部大約指向左上方——此準則通過。否定合規性表現良好:沒有咖啡杯、金屬、盤子或玻璃器皿。左上方的光源與一致的陰影表現通過。無造型道具。
GPT Image 2 在空間組件的指令遵循上表現更強,儘管兩個模型都未能同時滿足 7 個物體的計數與所有放置限制。
類別 2 · 逼真解剖與光影(T2I)
提示詞:
Close-up portrait of an East Asian woman in her early thirties holding a half-full crystal wine glass of red wine in her right hand, all five fingers and thumb fully visible wrapping naturally around the stem and partially around the bowl. She is seated by a tall west-facing window during golden hour. Late afternoon sunlight slices through the wine creating warm crimson caustic patterns on her left cheekbone and jawline. Her left hand rests on an open hardcover book on her lap. Catchlights from the window visible in both eyes. Skin shows ultra-detailed pores, fine peach-fuzz, subsurface scattering on the earlobe and bridge of the nose. Hair backlit with rim light. 85mm lens, f/2.0, shallow depth of field, photographic realism.
這是生成式模型在單圖測試中最困難的一項。
評分檢查清單
| # | 準則 | 檢查 |
|---|---|---|
| 1 | 手部解剖 | 5 根手指 + 大拇指,自然握住杯腳與杯身 |
| 2 | 焦散光影 | 紅酒產生的暖紅色光斑投射在顴骨上 |
| 3 | 眼神光一致性 | 雙眼位置與形狀相同 |
| 4 | 次表面散射 (SSS) | 耳垂與鼻樑處背光時可見 |
| 5 | 輪廓光物理性 | 方向與光源一致 |
| 6 | 皮膚真實感 | 無 AI 式塑料感過度平滑;毛孔與細小絨毛可見 |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 在其核心優勢上表現強勁。手部解剖結構正確——手指數量準確,握住杯腳和杯身的姿勢自然,手腕角度符合物理邏輯。僅憑這一點就通過了許多模型完全失敗的門檻。皮膚紋理展現了真正的毛孔級細節,可見細微絨毛,沒有過度平滑的塑料感,鼻樑和顴骨上的次表面散射呈現出溫暖、透光的質感,達到了照片級真實感。頭髮的輪廓光與窗口光源方向高度一致。
然而,焦散光投影是 Grok 的弱項。雖然臉部出現了紅色光影,但呈現出的效果像是過度戲劇化、誇張的紅色覆蓋層,比起真實陽光穿過酒杯產生的細膩柔邊光纖維,更像是後期調色效果。
GPT Image 2 則顛倒了優劣勢。其焦散光影的渲染在物理上明顯更準確——顴骨上的暖紅色圖案更小、更彌散,且遵循了陽光以正確角度穿過酒杯的空間幾何規律。這是 Grok 遺漏的細節。然而 GPT Image 2 在其他地方付出了代價:手部解剖結構稍顯生硬,手指圍繞杯腳的角度表現出輕微的僵硬感。皮膚紋理傾向於 AI 肖像常見的平滑、略顯扁平的質感,次表面散射的暖意較少,輪廓光強度也不如 Grok。
類別 3 · 多語言海報(T2I)
提示詞:
A vintage 1960s-style travel poster for a fictional film festival, illustrated in the style of mid-century commercial design. Top of poster, large bold serif Chinese characters reading "时光电影节" (line 1), and below in smaller Chinese characters "第七届 · 上海 · 1965年5月" (line 2). Center: a stylized illustration of an old film projector casting a beam onto a slightly curved cinema screen. Lower-center: a tall champagne coupe glass with the English text "GRAND OPENING NIGHT" wrapping along the curvature of the glass bowl, following the elliptical perspective. Right edge, vertical text reading "presented by 时代影业 · TIMES PICTURES" running top-to-bottom. Bottom strip: small English credits text "music · HUANG ZHAN / cinematography · GU CHANGWEI / poster design · ZHANG GUANGYU" in a single line. Color palette: cream off-white background, deep crimson red, mustard yellow accents. Slight aged paper texture, subtle grain.
評分檢查清單
| # | 準則 | 檢查 |
|---|---|---|
| 1 | 中文準確性 | 無筆畫缺失,無幻覺字體 |
| 2 | 雙語排版 | 中英文未混雜,各自出現在正確區域 |
| 3 | 杯身彎曲文字 | 英文符合香檳杯的橢圓透視 |
| 4 | 右側垂直文字 | 從上到下可讀 |
| 5 | 排版層級 | 標題與副標題區分明確 |
| 6 | 風格與可讀性 | 保持 1960 年代美學且不犧牲文字清晰度 |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 製作了一張視覺衝擊力強的海報,具有濃郁的 60 年代插畫風格。然而,它在最關鍵的文字標準上失敗了:標題顯示的是繁體「時光電影節」,而不是提示詞要求的簡體「时光电影节」。這屬於字元集合規性失敗,對於任何在地化或出版場景來說,這是一個重大錯誤。結構上,「GRAND OPENING NIGHT」出現在香檳杯上且有弧度,但橢圓透視感較隨意。整體佈局雖美,但繁簡體的錯誤是本項目的明確失分點。
GPT Image 2 順利通過了字元集測試:標題「时光电影节」和副標題「第七届 · 上海 · 1965年5月」均正確渲染為簡體中文,無漏筆畫或幻覺字符——這是對 Grok 的直接優勢。香檳杯上的文字緊貼杯身彎曲,透視感令人信服。右側垂直文字「时代影业 · TIMES PICTURES」清晰可讀。底部的 credits 行呈現良好。 typographic 的層級關係維護得非常清晰。整體而言,這是一個更符合商業出版需求的結果。
類別 4 · 幾何變換(I2I)
提示詞要求將全體模特兒順時針旋轉 45 度,同時保持相機位置不變。參考圖中包含複雜的層次穿搭:長棕色大衣、皮質肩披、可見漸變色(深棕→銀→米色)的皮草披肩、帶有肖像的銅製胸章、黑色皮手套及雙色皮靴。模型必須僅靠對身分的理解來保留這些細節。

這是針對能力強度的壓力測試。
評分檢查清單
| # | 準則 | 檢查 |
|---|---|---|
| 1 | 面部身分 | ArcFace 相似度 ≥ 0.5 |
| 2 | 皮草披肩露出 | 原先隱藏的右側銀色部分可見 |
| 3 | 胸章 | 圓形銅邊、內嵌肖像、正確的透視橢圓壓縮 |
| 4 | 下擺與內層 | 旋轉後的垂墜方向正確 |
| 5 | 腳步姿勢 | 左腳在前 |
| 6 | 手套體積 | 旋轉後手部位置與針織紋理可見 |
| 7 | 靴子顏色邊界 | 棕色 |
| 8 | 背景一致性 | 純灰攝影棚背景 (DINO 區域 ≥ 0.95) |
| 9 | 輸出比例 | 維持 9:16 全身框架,未裁切為肖像 |
| 10 | 視線方向 | 隨旋轉調整,不繼續直視相機 |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok 的面部身分維持在 ArcFace 0.5 閾值以上。皮草披肩原本隱藏的右側部分在 45 度旋轉後部分可見,漸變連續性合理。胸章輪廓保留,但內嵌肖像細節有壓縮。
GPT Image 2 表現出略強的服裝層次一致性,但引入了更多的面部身分偏移——這取決於具體應用場景,是一個重要的考量點。
類別 5 · 局部編輯與區域保留(I2I)
提示詞要求對客廳場景進行精確的三處編輯:移除沙發上的貓、將熱茶換成加冰的柳橙汁、在咖啡桌中間的書上放上一副折疊的黑框眼鏡。明確禁止更改其他細節:沙發紋理、書的位置、檯燈、窗景等。

對於產品攝影修圖或疊代開發來說,保留原始場景不被重繪至關重要。
評分檢查清單
| # | 準則 | 檢查 |
|---|---|---|
| 1 | 完成 3 項編輯 | 貓移除 |
| 2 | 沙發還原 | 無貓型凹痕或毛髮殘留 |
| 3 | 柳橙汁物理性 | 杯子幾何、冰塊折射、影子與場景光一致 |
| 4 | 眼鏡放置 | 正確位於中間書本上 |
| 5 | 沙發紋理 | 菱形編織圖案完整 |
| 6 | 書籍未變 | 位置、封面色彩不變 |
| 7 | 檯燈與窗景 | 形狀與背景一致性維持 |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 完成了所有編輯,且沙發修復得很乾淨。不過,柳橙汁杯的反射光模式與場景方向不符,看起來像是由獨立模型合成的,且與桌面之間的接觸陰影不足,有輕微的「懸浮感」。
GPT Image 2 在場景保留方面更勝一籌。窗外背景模糊一致性保持得更好,這正是 Grok 失敗的地方。柳橙汁的渲染效果更精細,陰影方向準確。雖然整體場景亮度有輕微偏移,但它更接近像素級的真實保留。
類別 6 · 多參考圖融合(I2I)
要求將三組獨立參考圖融合:身分肖像(拉丁裔女性、琥珀色眼睛、深棕色捲髮)、水彩插畫風格(日本鄉村風景、可見筆觸、童話氛圍)、以及場景布局(歐洲鵝卵石街道、鑄鐵路燈、石拱門)。



評分檢查清單
| # | 準則 | 檢查 |
|---|---|---|
| 1 | 三要素解耦 | 身分、風格、場景融合 |
| 2 | 完整風格轉移 | 輸出為水彩畫,而非照片加濾鏡 |
| 3 | 身分保留 | 琥珀色眼睛與面部結構在水彩處理下可辨識 |
| 4 | 場景結構保存 | 鵝卵石、路燈、拱門布局完整 |
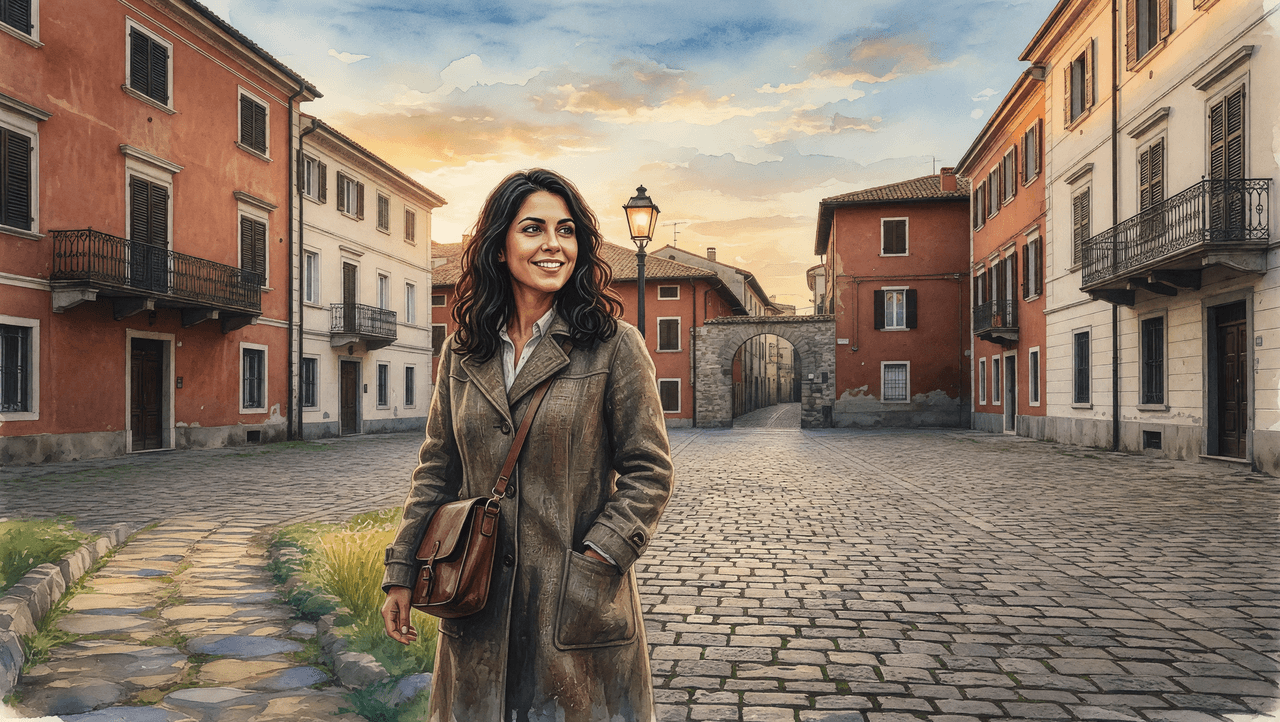 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 在核心準則上失敗了:輸出結果是照片級真實,而非水彩。它保留了完全的照片清晰度,僅覆蓋了輕微的紋理,未能展現水彩應有的筆觸與顏色滲透效果。渲染媒介完全錯誤是一個嚴重的減分項。
GPT Image 2 在整個畫面中實現了真正的水彩渲染,建築、地面、天空和人物都帶有明顯的筆觸和柔和的色彩滲透,一致性非常好。身分特徵(捲髮、臉部結構)在水彩變形下仍能被識別,同時完整保留了場景布局。這是唯一完成了該項任務的模型。
透過 Atlas Cloud 體驗 Grok Imagine Image 和 GPT Image 2
本基準測試是可重現的。Grok Imagine 與 GPT Image 2 現在都已透過 Atlas Cloud 開放使用——無需按模型單獨計費,也沒有等待名單。
為什麼選擇 Atlas Cloud
- 一個 API 金鑰,300+ 模型。 透過更改單一模型欄位,即可在 Grok、GPT Image 2、Flux、Wan、Seedream 和池中其他模型之間輕鬆切換。
- 全模態覆蓋。 LLM、文生圖、圖生圖、文生影片、圖生影片,皆在同一平台上實現。
- 無冷啟動,無意外限流。 Atlas Cloud 運行在專為吞吐量優化的推理基礎設施上,無論進行多少次呼叫,延遲表現始終如一。
- 為比較工作流程而生。 本基準測試展現的使用場景——在多個模型間執行相同提示詞並比較輸出,正是 Atlas Cloud 架構設計的核心目的。






