
圖像產生 API 絕對不盡相同。在開始開發之前,先進行評估是非常值得的。以下為您快速整理目前市面上六款熱門的 API。這份簡單的比較將能協助您為技術架構挑選最合適的方案,並節省寶貴時間。
| 模型 | 預估速度 | 每張圖片成本 | 最佳使用場景 |
| GPT Image 2 | 約 8–10 秒 | USD0.01 | 文字渲染與複雜排版 |
| Grok-3 Image | 約 6–9 秒 | 約 USD0.02-0.07 | 無限制創意與社群趨勢 |
| Flux | 約 5–8 秒 | 約 USD0.003-0.03 | 電影級照片真實感 |
| Seedream v5.0 (Lite) | 約 3–5 秒 | 約 USD0.032 | 大規模內容生成 |
| Nano Banana Pro | 約 1–3 秒 | 約 USD0.14-0.15 | 超快速預覽與批次任務 |
| Ideogram v3 | 約 8–12 秒 | 約 USD0.03-0.06 | 業界領先的排版設計 |
注意: 速度數據基於經驗性生產測試;價格基於 Atlas Cloud(Grok 與 Ideogram v3 除外)。
關鍵重點: 沒有單一模型能解決所有任務,每一項任務都有最適合的模型。在撰寫任何整合程式碼之前,請先確認 API 與您的輸出需求是否匹配。
第一階段:選擇引擎 —— 需求匹配
如果未考慮具體輸出需求就挑選圖像產生 API,就像是用跑車去拖船一樣不切實際。請將重點放在任務本身,而非僅僅是引擎。您的選擇應基於三個核心指標:視覺中的文字處理能力、快速草圖與高品質輸出的平衡,以及廠商的計費方式。
「圖中文字」難題
多數圖像 API 在處理提示詞中包含可讀文字時仍會遇到困難——例如 UI 介面標籤、標誌文案或海報標題。字母模糊、單字混亂,導致成品無法用於商業場景。
Ideogram v3 在處理標準提示詞時的文字渲染準確度超過 95%,而 Midjourney 在處理多字詞串時約有 40% 的機率會出錯。Ideogram v3 能可靠地處理長字串、品牌名稱與複雜佈局——這使其成為任何涉及看板、產品包裝或內嵌文案工作流程的首選。
如果排版不是您的首要需求,這個限制就不會影響您。但若排版至關重要,選錯 API 所造成的後期修改成本,將遠超過節省下的訂閱費用。
照片真實感與速度:將模型與場景匹配
並非所有影像都需要攝影棚級的品質。下表列出了不同使用場景對應的模型層級:
| 使用場景 | 建議層級 | 範例模型 |
| 形象行銷視覺 | 高保真 (High-fidelity) | Flux 2 Pro, Imagen 4 Ultra |
| 即時使用者生成 | Turbo / Lightning | Nano Banana 2, Z-Image Turbo (~1秒) |
| 社群媒體與大規模內容 | 中階 (Mid-range) | Seedream v5.0 Lite, Flux 2 Dev |
| 文字密集型設計素材 | 專業型 (Specialist) | Ideogram v3, GPT Image 2 |
Flux 2 在照片真實感與提示詞遵循度上表現領先,而 Imagen 4 在文字渲染準確度與生成速度上佔據主導。以速度為優先的模型會犧牲部分保真度,但在延遲是產品體驗關鍵環節時,這些模型是唯一可行的選擇。
定價現實:不再只是「單張計費」
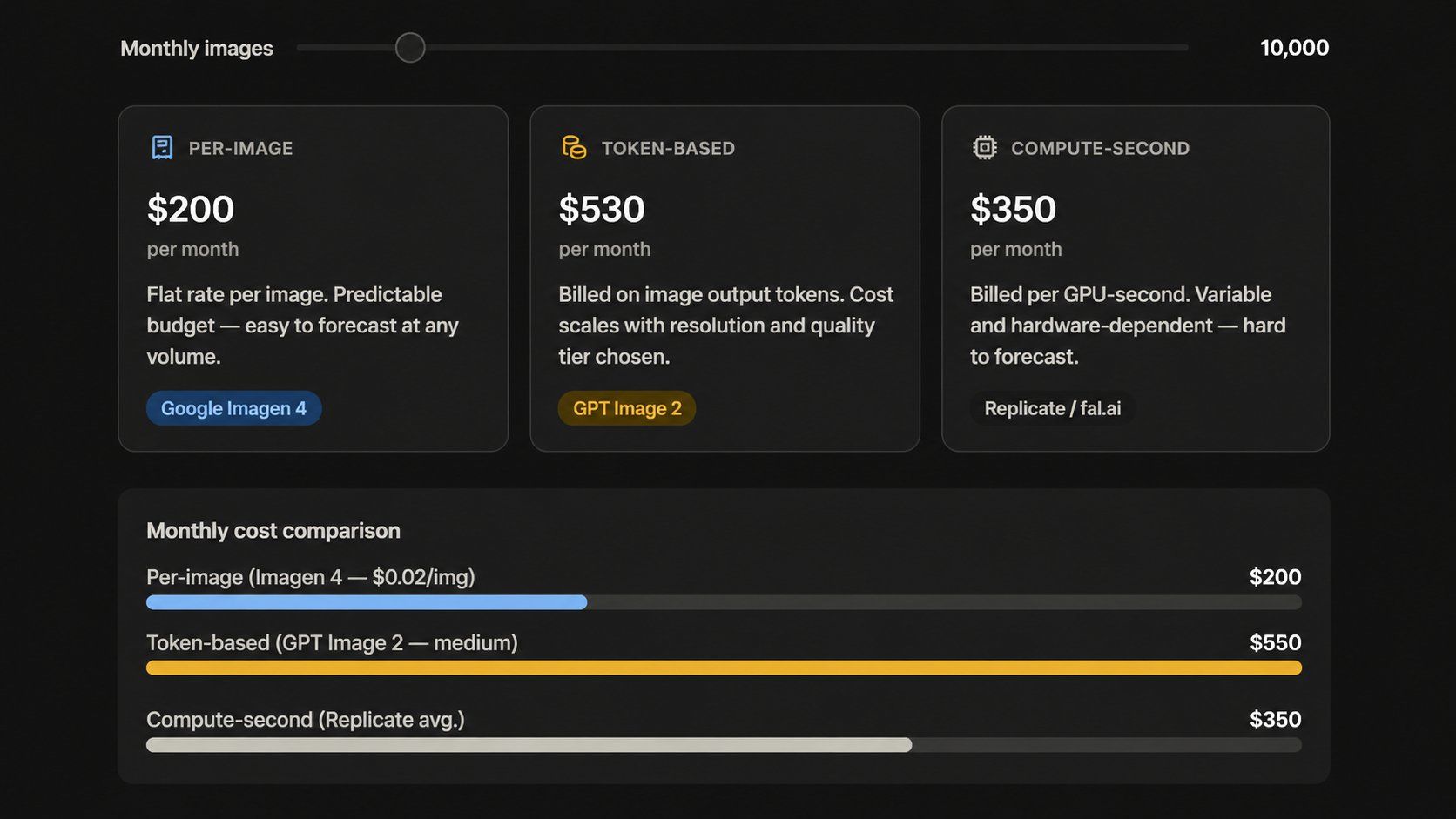
「每張圖片一口價」的模式正在消失。現今領先的 API 計費方式大相徑庭:
- 基於 Token(OpenAI):GPT Image 2 的 API 計費為每百萬輸入 Token 收費 USD8.00,每百萬輸出 Token 收費 USD30.00。網頁估價通常與此不同,因為它們並非官方牌價。
- 按張計費(Google Imagen): Google Imagen 4 每張圖片收費約 USD0.02 至 USD0.06。這種模式讓大規模項目的預算規劃更加容易。
- 按秒計費(Replicate): Replicate 根據每項任務實際使用的 GPU 時間收費。這對於負載波動的工作非常有效,但會增加預測每月總成本的難度。
團隊可能會以為每張圖片成本是 USD0.05,結果發現實際成本高達 USD0.11。這是因為解析度、品質等級與編輯功能會產生額外費用。在簽訂任何合約之前,請務必使用各公司的定價工具測試您的每月負載量。
第二階段:技術整合 —— 「即時」要素
您可以在 15 分鐘內取得第一個來自 API 的影像。基本設定相當簡單,大多數開發人員遇到的困難僅限於登入權限或最終資料管理。請依照以下步驟執行。
環境設定
安裝您所選語言的官方 SDK。以下兩個選項皆提供了標準影像生成請求所需的一切。
Python
plaintext1pip install openai
Node.js
plaintext1npm install openai
基礎的文字轉圖像生成不需要任何其他相依套件。如果您需要處理二進位資料或儲存檔案,工具皆已內建。Python 使用 base64 模組,Node.js 使用 Buffer 類別。兩者開箱即用,無需額外安裝。
驗證標準:超越裸露的 API 金鑰
將原始 API 金鑰直接貼在應用程式程式碼中,仍是開發中最常見且可避免的安全漏洞之一。對於 2026 年的任何生產部署,請遵循以下規範:
| 重要原因 | 最佳實踐 |
| 防止機密外洩至原始碼控制系統 | 將金鑰儲存在環境變數中 |
| 集中輪替與存取稽核 | 使用機密管理工具 (AWS Secrets Manager, HashiCorp Vault) |
| 限制金鑰外洩時的受影響範圍 | 將金鑰權限最小化 |
| 減少未被發現的外洩曝露視窗 | 定期輪替金鑰 |
| 當代表終端使用者(而非僅自身後端)行動時必須 | 使用 OAuth2 進行使用者授權流程 |
OAuth2 適用於應用程式需要「代表個別使用者」(使用其各自的供應商帳戶)生成圖像時。對於使用自有 API 金鑰的伺服器對伺服器呼叫,妥善管理的環境變數並配合定期輪替,已能滿足多數生產環境的安全需求。
範本程式碼
以下是請求 OpenAI gpt-image-2 端點的乾淨、可運作程式碼——Python 與 Node.js 皆可直接複製使用。
Python
plaintext1import os 2import base64 3from openai import OpenAI 4 5client = OpenAI(api_key=os.environ["OPENAI_API_KEY"]) 6 7response = client.images.generate( 8 model="gpt-image-2", 9 prompt="A clean product shot of a ceramic coffee mug on a white marble surface, studio lighting", 10 size="1024x1024", 11 quality="medium", 12 n=1, 13) 14 15# 解碼並儲存圖片 16image_bytes = base64.b64decode(response.data[0].b64_json) 17with open("output.png", "wb") as f: 18 f.write(image_bytes) 19 20print("Image saved to output.png")
Node.js
plaintext1import OpenAI from "openai"; 2import fs from "fs"; 3 4const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); 5 6const response = await client.images.generate({ 7 model: "gpt-image-2", 8 prompt: "A clean product shot of a ceramic coffee mug on a white marble surface, studio lighting", 9 size: "1024x1024", 10 quality: "medium", 11 n=1, 12}); 13 14// 解碼並儲存圖片 15const imageBuffer = Buffer.from(response.data[0].b64_json, "base64"); 16fs.writeFileSync("output.png", imageBuffer); 17 18console.log("Image saved to output.png");
這兩段程式碼皆會從系統設定中讀取 API 金鑰。它們會請求一張標準的 1024×1024 影像並儲存至您的電腦。測試期間,可將品質設定改為 "low",在優化提示詞時將每張成本保持在約 USD0.006。
第三階段:解決 2026 年開發者的痛點
API 運作起來只是完成了一半的工作。區分原型與正式功能的關鍵,在於您如何處理不精確的提示詞、不安全輸入與緩慢的生成時間。這三個領域佔了團隊整合圖像產生 API 後,大部分後期修復工作的來源。
提示詞工程 (Prompt Engineering) vs. 提示詞增強
使用者通常輸入簡短、模糊的內容,但 API 表現則取決於詳細的輸入。這兩者之間的差距直接影響輸出品質——將問題怪罪於模型往往只是掩蓋了提示詞的不足。
兩種方法可縮小此差距:
原生「魔法提示詞」功能 — Ideogram 的 API 提供內建提示詞增強開關,會在生成前自動重寫簡短輸入。在請求中加入 magic_prompt_option: "ON",API 會自動處理增強。這是最省力的做法,適用於消費者導向且使用者不需學習提示詞語法的應用程式。
LLM 閘道模式 (Gateway Pattern) — 先將原始使用者輸入傳送給 LLM 進行處理,再將增強後的結果傳遞給影像 API。這讓您能精確控制增強邏輯,且適用於任何供應商。
plaintext1from openai import OpenAI 2client = OpenAI() 3 4# 第一步:增強提示詞 5enhancement = client.chat.completions.create( 6 model="gpt-4.1-mini", 7 messages=[{ 8 "role": "user", 9 "content": f"Rewrite this image prompt with cinematic detail, lighting, and style: '{user_input}'" 10 }] 11) 12enhanced_prompt = enhancement.choices[0].message.content 13 14# 第二步:產生圖片 15image = client.images.generate( 16 model="gpt-image-2", 17 prompt=enhanced_prompt, 18 size="1024x1024", 19 quality="medium" 20)
安全層:自動化內容審核
允許使用者在沒有審核步驟的情況下產生任意影像是一種風險。至少請實作兩個檢查點:
| 層級 | 偵測內容 | 工具 |
| 輸入篩選 | 在 API 呼叫前的有害文字提示 | OpenAI Moderation API (免費), Azure Content Safety |
| 輸出篩選 | 產生後違反政策的圖片 | Google Cloud Vision SafeSearch, AWS Rekognition |
多數主流影像 API 供應商都有強制執行伺服器端的過濾機制,但這應被視為最後一道防線,而非唯一防線。請建立自己的輸入篩選步驟,以便在耗費資源生成可能被阻擋的內容前,先行拒絕請求。
非同步處理:使用 Webhook 而非輪詢
高保真影像生成可能耗時 5–20 秒。讓使用者在同步請求中盯著載入轉圈是極差的 UX,架構也極不穩定——若連線在中途斷開,結果就會遺失。
正確的模式是 Webhook 驅動的非同步流程:
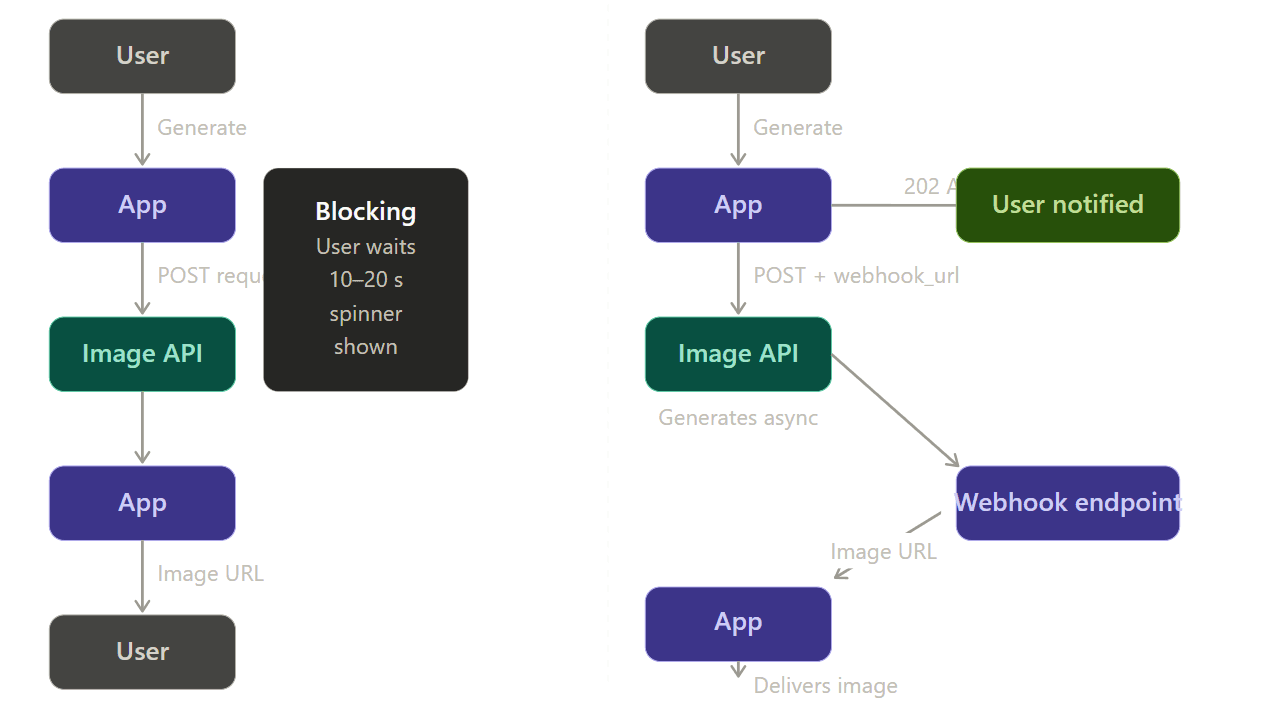
在 Webhook 模式下,您的應用程式會立即提供給使用者一個任務 ID 與 202 Accepted 狀態碼。當影像服務完成時,它會將最終檔案推送到您的伺服器,同時在後台運作。這避免了連線逾時與資料遺失。在您的網站上,只需快速檢查資料庫以確認任務是否完成;您也可以使用 WebSocket 來即時推送更新。這兩種方式都比期望單一網頁連線能維持 15 秒以上安全得多。
進階優化:品牌一致性 —— 建立「護城河」
任何開發人員都能在一下午內串接基本的圖生圖 API。對手無法輕易複製的,是那套能「產生符合您品牌特色」的視覺系統。LoRA 客製化與影像編輯端點,正是讓圖像產生 API 從通用功能轉變為真正產品差異化的關鍵。
LoRA 整合:教導 API 您的風格
LoRA 是一種巧妙的微調 AI 模型方式,無需從頭訓練。只需訓練一個疊加在主引擎上的微小層級,即可建立一個 .safetensors 檔案,並在影像請求中使用它。這能幫助您確保每次輸出的風格一致性,可用於遵守品牌特定的藝術風格、產品氛圍或獨特的視覺主題。
實務操作流程 (Atlas Cloud + Flux):
第一步 — 訓練 LoRA
plaintext1import { atlas } from "@atlas-cloud/sdk"; 2 3// Atlas Cloud 利用 H100 叢集進行快速微調 4const training = await atlas.models.train({ 5 type: "lora", 6 base_model: "flux-dev", 7 dataset_url: "https://your-storage.com/brand-set.zip", 8 trigger_word: "brandstyle", 9 config: { 10 rank: 16, 11 learning_rate: 0.0001, 12 max_steps: 1200 13 } 14}); 15 16const loraId = training.id; // 在您的生成呼叫中使用此 ID
第二步 — 使用您的自訂風格生成
plaintext1const generateResponse = await fetch("https://api.atlascloud.ai/api/v1/model/generateImage", { 2 method: "POST", 3 headers: { 4 "Authorization": `Bearer ${process.env.ATLAS_API_KEY}`, 5 "Content-Type": "application/json" 6 }, 7 body: JSON.stringify({ 8 model: "black-forest-labs/flux-dev-lora", // 專用 LoRA 端點 9 prompt: "A product shot of a ceramic mug, brandstyle, studio lighting", 10 loras: [ 11 { 12 // 支援:<owner>/<model-name> (Hugging Face) 或直接的 HTTPS URL 13 path: "https://api.atlascloud.ai/weights/user-123/brandstyle.safetensors", 14 scale: 0.85 // 「影響力」旋鈕 (0.0 到 1.5) 15 } 16 ], 17 size: "1024x1024", 18 num_inference_steps: 30, // 針對 Flux-Dev 優化 19 output_format: "png" 20 }) 21}); 22 23const { id: predictionId } = await generateResponse.json();
訓練費用為每次 USD2(隨步驟數線性擴展),訓練好的 LoRA 可立即部署至生成端點,無需額外架設基礎設施。
需調整的關鍵參數:
| 參數 | 建議範圍 | 影響 |
| scale | 0.5 – 1.5 | 控制風格覆蓋基礎模型的強弱 |
| steps | 800 – 1500 | 步驟越多 = 風格捕捉越強,但風險在於過度擬合 |
| 訓練影像 | 15 – 30 張 | 品質重於數量 — 不一致的範例會導致不一致的輸出 |
圖生圖與內補繪 (Inpainting):編輯,而不僅是生成
從單純的文生圖轉換為圖生圖能力,開啟了完全不同類別的使用者功能——讓使用者能修改現有照片,而非僅從零生成。
GPT Image 2 的 images.edit 端點可接受一張或多張參考影像以及提示詞,並支援遮罩內補繪 (inpainting) 與外補繪 (outpainting)——模型僅會針對未遮罩區域進行變更,保留其餘部分。
這為您的應用程式解鎖了常見場景:
- 背景替換 — 無需攝影棚即可大規模替換產品照背景
- 物件移除 — 讓使用者從上傳的圖片中清理不想要的元素
- 外補繪 — 延伸現有圖片畫布以適應新的長寬比
plaintext1import openai, base64, pathlib 2 3client = openai.OpenAI() 4 5image_bytes = pathlib.Path("product.png").read_bytes() 6mask_bytes = pathlib.Path("background-mask.png").read_bytes() 7 8result = client.images.edit( 9 model="gpt-image-2", 10 image=image_bytes, 11 mask=mask_bytes, 12 prompt="Replace the background with a clean white studio backdrop", 13 size="1024x1024", 14 quality="medium" 15) 16 17output = base64.b64decode(result.data[0].b64_json) 18pathlib.Path("edited.png").write_bytes(output)
遮罩影像是一個灰階 PNG,白色像素表示模型可自由生成的區域,黑色像素則標記需精確保留的區域。無需額外的內補繪管線——編輯端點能在單次呼叫中完成此操作。
結論與後續步驟
本指南的每一節都指向同一個基本事實:整合影像產生 API 已不再是研究專案,而是一項常規工程任務。工具已趨成熟,文件完整,定價也已降至即使是早期階段的產品,也能在不造成明顯誤差的情況下負擔生成成本。準備好建構了嗎? 從 OpenAI GPT Image 2 API 開始您的第一次整合吧。
常見問題 (FAQ)
我可以將 AI 產生的影像用於商業產品嗎?
可以,但您必須了解「擁有檔案」與「擁有著作權」之間的區別。OpenAI 將結果的所有權利(如用於廣告、產品與銷售)賦予您。在現實世界中,這意味著您可以利用該作品營利,但無法禁止競爭對手使用相同的影像。為了保護品牌,建議加入您的人為處理:嘗試編輯作品、變更排版或使用自訂設定。即便沒有法律上的著作權,這些步驟也能幫助您為企業打造獨特的視覺識別。
如何處理文字密集型影像中的「幻覺」?
請使用專門為文字渲染建構的模型。Ideogram v3 在處理標準提示詞時的準確度超過 95%,而通用模型在處理多字詞串時仍有高比例的出錯率。對於 GPT Image 2,請將必須精確顯示的文字置於提示詞中的引號內,並明確指示該內容應「僅出現一次且完全如所寫」——這能大幅減少重複與拼字錯誤的狀況。
擴展至 10,000 名使用者的最便宜方式為何?
請依照任務進行路由,而非僅單一供應商。一個實用的分層策略:
| 流量 / 場景 | 建議模型 | 預估成本 |
| 草圖與預覽 | GPT Image 2 | ~USD0.01 / 張 |
| 標準社群與行銷 | Seedream v5.0 Lite | ~USD0.032 / 張 |
| 高保真形象資產 | Flux 或 Imagen 4 Ultra | ~USD0.003–USD0.06 / 張 |
| 即時 / 高吞吐量 | Z-Image Turbo | ~USD0.01 / 張 |
注意:上述價格基於 Atlas Cloud。
對於高流量開發者而言,最便宜與最昂貴選項之間的價差可達 33 倍——針對每種任務類型挑選合適的 API,每月可節省數千美元。將此路由策略與非同步 Webhook 處理結合,並根據輸出目標調整品質等級,能確保成本隨著使用者群成長而可預測地擴展。






