
多年來,創作者的工作相當枯燥。他們必須先製作無聲影片,隨後花費數小時添加音效,這通常會導致嚴重的同步問題。例如,人物嘴型動了,但聲音卻慢了一拍。這種不協調感顯得虛假,讓觀眾難以專注於影片內容。
Vidu Q3 透過內建音效的 AI 影片生成技術,解決了這些陳年難題。與其他工具不同,它能一次性生成包含音訊與影像的 16 秒短片。這種智慧型方法確保了每個字都能與人物的唇形完美匹配,同時確保畫面中的每個聲響(如碰撞或點擊聲)都能與動作精準同步。
2026 年 AI 唇形同步 (AI lip-sync 2026) 標準現在優先採用「單次生成」(One-Pass) 技術,以降低延遲並提升真實感。透過將對話與背景音樂直接整合至生成過程中,Vidu Q3 消除了語音不同步帶來的「恐怖谷」效應,顯著提升了社群媒體與行銷內容的觀眾留存率。
為什麼 Vidu Q3 的「原生音訊」與眾不同?
與傳統先生成視覺再「疊加」音效的模型不同,Vidu Q3 採用了單次生成架構。這意味著模型能同時合成:
- SFX (音效): 如腳步聲或落葉聲等環境音。
- BGM (背景音樂): 根據場景情緒弧線量身打造的配樂。
- 對話: 精準對時的語音模式。
透過同時生成這些元素,物理動作與聲音之間的時間差被數學鎖定,徹底消除了音訊延遲帶來的「恐怖谷」效應。
16 秒的里程碑
Vidu Q3 現在支援長達 16 秒的影片片段。這個長度在以下幾個主要方面是一個絕佳的平衡點:
- 社群媒體廣告: 有足夠的時間吸引注意力、解釋價值並加入行動呼籲 (CTA)。
- 敘事流暢度: 這種長度允許 AI 唇形同步有自然的停頓,使 2026 年的影片專案看起來流暢而不突兀。
效能比較
為了了解 Vidu Q3 在同類產品中的表現,我們觀察了視聽延遲——即視覺動作與對應聲音之間的時間差。
| 功能 | Vidu Q3 (首選) | Kling 2.6 | Veo 3.1 |
| 同步架構 | 原生單次生成 (統一) | 原生單次生成 | 原生單次生成 |
| 最大時長 | 16 秒 (業界領先) | 10 秒 | 8 秒 |
| 長腳本對齊 | 極佳 (100+ 字元) | 中等 (易偏移) | 高 (視覺導向) |
| 物理音效逼真度 | 高 (基於材質) | 平衡 | 氛圍感 |
| 鏡頭間連續性 | 無縫音訊切換 | 基礎 | 進階 |
| 延遲 / 音訊漂移 | < 30ms | < 15ms | ~10ms |
雖然競爭對手可能提供略低的延遲,但 Vidu 是唯一能提供完整 16 秒創作長度的模型。其生成同步環境的能力,使其成為追求電影級真實感、且不想處理手動對齊技術難題的創作者的首選。
打造完美音訊的「導演提示詞」公式
要達到高保真的 2026 年 AI 唇形同步 標準,必須超越簡單的描述。為了充分利用 原生音訊 AI 影片,創作者必須在單一提示詞中架起視覺動作與聽覺反應之間的橋樑。
單次生成中的「主體-音訊橋接」掌握
在 Vidu Q3 中,「主體-音訊橋接」(Subject-Audio Bridge) 是一種將特定聲音錨定在視覺提示上的技術。由於模型使用「單次生成」,它會尋找語義連結——將 原生音訊 AI 影片 資料對齊到您的提示詞中。例如,如果您描述「玻璃破碎」,該橋接會觸發特定的工作流程:
- 時間精確度: AI 會識別撞擊的確切影格。
- 聲學映射: 它會準備一個高頻音訊峰值(如「叮」或「碎裂聲」)來佔據該特定時間戳。
- 環境背景: 它會根據視覺場景是小房間還是大廳,調整殘響效果。
這種整合式方法與模組化 AI 系統相比,顯著降低了漂移現象。
提示詞配方:三層架構法
為了確保模型捕捉到場景的每一層,請遵循此結構層級:
[視覺描述] + [鏡頭運動] + [音訊層:對話/音效/背景音樂]
提示詞組件分解
| 組件 | 功能 | 範例 |
| 視覺描述 | 定義主體、紋理與動作 | 一位鐵匠正在敲打燒紅的鐵劍 |
| 鏡頭運動 | 設定視角與深度 | 極致特寫,火花飛向鏡頭 |
| 音訊層 | 指定聲音類型與強度 | 音效:尖銳的金屬撞擊聲,嘶嘶作響的蒸汽 |
案例研究:高同步執行
讓我們拆解一個旨在實現最大同步的提示詞:
這是我的參考圖片:

這是我的影片提示詞:

接下來,讓我們看看影片生成結果:
影片資訊:1080p, H264, Flash 模式
- 基於音素的唇形同步在 Flash 模式下仍能保持如此精確,令人驚嘆。通常,「快速」或「輕量」模型為了節省運算時間會犧牲微表情,但對「Loved」和「Real」等詞的對齊依然穩定,證明了 Vidu Q3 的原生音訊架構即使在去除高階迭代採樣後依然強大。
- H.264 是一種有損格式,通常難以捕捉雨水或膠卷顆粒等細微細節,常在陰暗、顆粒感強的地方留下「巨集區塊」或醜陋的像素方塊。儘管有這些限制,「明暗對照法」(Chiaroscuro) 的光影效果依然出色。陰影保持銳利而未變成模糊的泥團,顯示了模型在色彩分級處理上的優異表現。
- 背景中的濕潤紋理和銳利的雨絲是壓縮導致模糊最明顯的地方。如果您使用 ProRes 或更高位元率的 Pro/高解析度輸出,這些細節會清晰許多。
免費方案非常適合簡單的專案或嘗鮮。但如果您想要真正的電影質感——透過高位元率和銳利畫質克服「恐怖谷」——您應該將工作轉移到 Atlas Cloud。
透過使用 Atlas Cloud 上的 Vidu Q3 Turbo,您可以繞過本地運算瓶頸,生成無浮水印、高保真的內容,保留每一個細微之處。
完美唇形同步的專業秘訣:「精通」章節

在 2026 年 AI 唇形同步 中實現電影級真實感,需要的不僅僅是好的提示詞,還需要對引擎如何解讀人類語音有技術性的理解。透過優化腳本和視覺環境,您可以最大化 原生音訊 AI 影片 生成的精確度。
音素優先腳本
鎖定 Vidu Q3 追蹤引擎的秘訣在於「音素」(Phonemes)。具體來說,句子開頭最好使用「爆破音」——即透過阻斷氣流產生的聲音,如 M、B 和 P。這些聲音需要明顯且可見的唇部閉合。當模型在序列開頭偵測到爆破音時,它會為嘴部幾何結構建立一個高信賴度的錨點,顯著降低初始「含糊不清」或影格錯位的機率。
5-9 字規則
為了保持一致性,專業創作者遵循「5-9 字規則」。雖然 Vidu Q3 支援更長的持續時間,但「AI 漂移」(即嘴部動作隨時間與音訊失去同步)往往會在長且不間斷的對話中增加。將語音拆分為 5 到 9 個字的片段,讓模型在每個自然停頓處「重置」其追蹤參數。
| 功能 | 片段長度 | 結果 |
| 理想 | 5-9 個字 | 影格級完美對齊與自然節奏。 |
| 次優 | 15 個字以上 | 「漂移」或唇緣模糊的風險增加。 |
視覺清晰度與照明
唇形同步引擎需要清晰、無遮擋的下臉部視野,才能將音素映射到像素。為確保高保真追蹤:
- 避免遮擋: 確保手部、麥克風或散亂的頭髮不會遮住嘴部區域,因為這些「視覺雜訊」會干擾潛在空間映射。
- 高對比照明: 確保下巴和嘴唇輪廓分明。平淡的照明可能導致 AI 無法處理嘴部內部的深度。
多語言節奏:英語 vs. 中文
Vidu Q3 對不同的語音節奏使用不同的邏輯。英語遵循重音節奏,因此引擎專注於寬廣的母音形狀。中文則是音節計時且具備聲調,需要更快速、精確的唇部動作。若要獲得自然的中文語音,請使用能保持「頭部位置穩定」的提示詞,這有助於引擎更專注於那些細微且快速的嘴部調整。
遵循這些視覺與佈局規則,能讓您的影片與音訊在整個 16 秒片段中保持穩定。
多鏡頭敘事與音訊設計
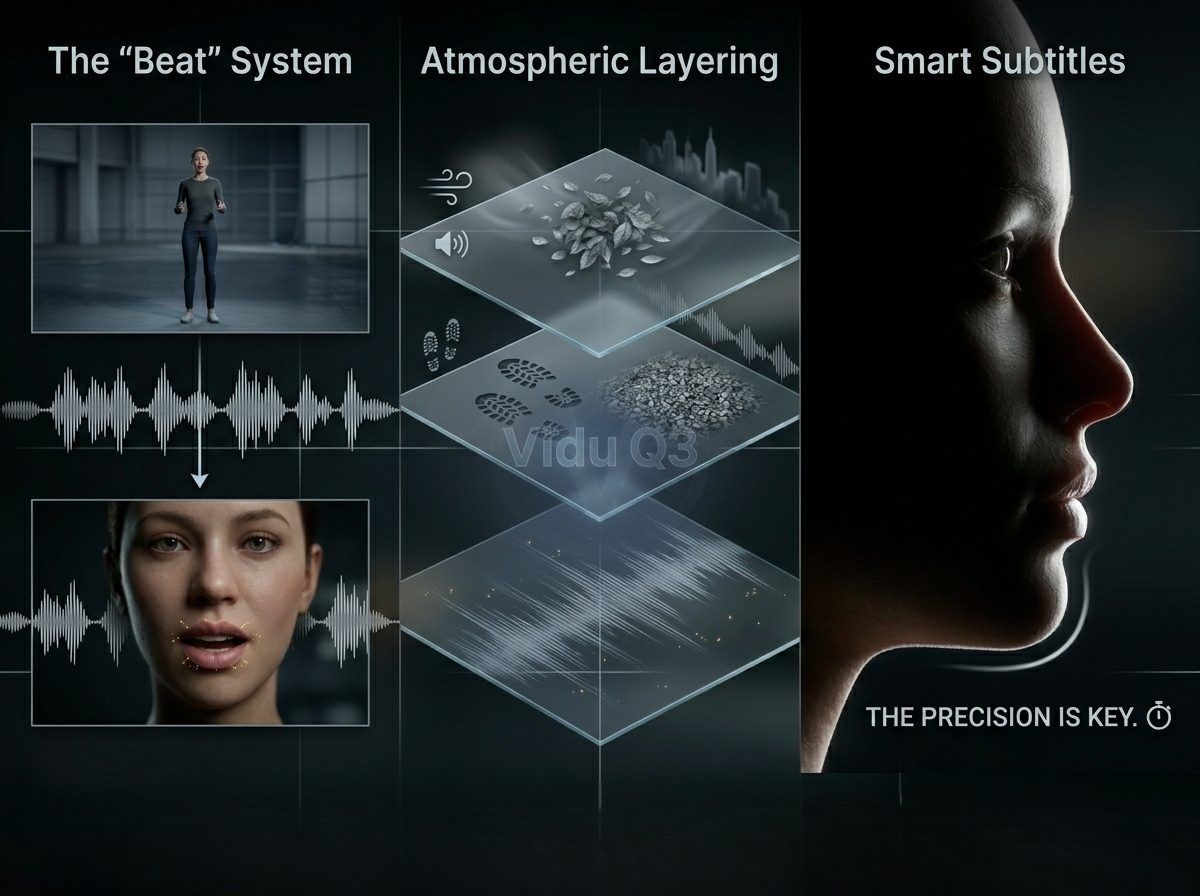
在不同角度間流暢切換故事是專業創作者的標誌。Vidu Q3 透過智慧型多鏡頭工具簡化了這一過程。這些功能即使在鏡頭視角變換時,也能保持您的 AI 影片與音訊完美同步。
「節拍」(Beat) 系統:編排音訊連續性
Vidu Q3 引入了「節拍」系統,允許使用者定義特定的鏡頭轉換而不中斷音訊流。透過編寫「節拍」,您可以指揮從廣角建立鏡頭到緊湊特寫的轉換,同時對話或背景音樂 (BGM) 持續無縫播放。這種連續性避免了模組化 AI 工具中常見的突兀「音訊重置」。
管理多鏡頭轉換:
| 鏡頭類型 | 目的 | 音訊行為 |
| 廣角鏡頭 | 建立環境 | 高殘響,強調環境音 |
| 中景鏡頭 | 聚焦動作 | 平衡對話與音效 |
| 特寫鏡頭 | 增強情緒 | 乾音,優先處理唇形同步 |
氛圍層疊:紮根視覺效果
為了讓 AI 生成的素材感覺紮根於現實,創作者必須超越對話,加入「紋理」。氛圍層疊涉及提示次要與三級聲音,使其與環境互動。
- 環境紋理: 指定風穿過樹林的聲音或遠處城市的嗡嗡聲。
- 物理紋理: 加入「絲綢摩擦聲」或腳步下的「碎石聲」。
- 聲學深度: Vidu Q3 的單次生成會計算主體與鏡頭的距離,自動調整這些聲音的音量與「空氣感」,以匹配視覺深度。
智慧字幕:精準文字同步
自動影片製作中的一個大問題是字幕與語音不符。Vidu Q3 透過直接從生成的對話軌道觸發其內部文字渲染引擎來解決此問題。由於文字是在與 原生音訊 AI 影片 同一階段渲染的,因此時間點是影格級精準的。這確保了觀眾的眼睛與耳朵能在同一毫秒接收到相同資訊,這是 2026 年 AI 唇形同步 高無障礙標準的要求。
利用這些整合功能可減少約 60% 的後期製作時間,實現維持電影品質的「直達社群」工作流程。
常見問題與解決方案
創作者在初次使用 Vidu Q3 時常會遇到技術摩擦。實現完美的 原生音訊 AI 影片 需要排除文字提示與聲學輸出之間細微的互動問題。
問題:嘴巴在動,但發出的聲音聽不懂
這是常見的障礙,視覺上的唇形同步看似活躍,但發音模糊不清。
- 解決方案:腳本衛生。 Vidu Q3 引擎對對話區塊的格式非常敏感。確保您的腳本沒有非語言的填充詞(如「嗯」、「啊」),除非它們是為了塑造「自然主義」的角色特徵。使用標準標點符號來提示 AI 何時停頓換氣,這能重置唇形追蹤的對齊。
問題:聲音太大或模糊
當影片的能量與設定的音量等級不符時,會出現雜訊破裂與失真。
-
解決方案:調整情緒關鍵字。 不要僅僅在提示詞中增加「音量」(AI 可能會將其解釋為增益提升),請使用描述性的語音風格。
- 低強度: 使用「低聲耳語」或「喃喃自語」來降低峰值。
- 高強度: 使用「大聲喊叫」或「宏亮的宣告」來確保 AI 平衡音訊餘裕。
問題:音樂與情緒不符
由於 Vidu Q3 在生成影片的同時生成背景音樂,通用的提示詞(如「快樂的音樂」)通常會導致音調脫節。
- 解決方案:BPM 與流派特定錨點。 將 AI 視為作曲家。提供特定的節奏 (BPM) 或子流派有助於模型將背景音樂錨定在視覺影格率上。
故障排除快速參考表
| 症狀 | 主要原因 | 建議調整 |
| 語音模糊 | 腳本髒亂/俚語 | 使用乾淨、有標點的文字字串 |
| 音訊破音 | 音調不匹配 | 使用「耳語」或「喊叫」描述詞 |
| 情緒漂移 | 背景音樂提示模糊 | 加入 BPM (例如 120 BPM) 或流派 (例如 Lofi) |
這些調整改變了模型映射聲音的方式,能確保您的音訊等級符合專業廣播標準。當您掌握這些修正技巧後,就不再只是玩弄 AI,而是開始製作看起來與聽起來都專業的內容。
結論:AI 內容的未來是「全端」
精通 Vidu Q3 意味著進化為「全端」創作者——了解真正身臨其境的 原生音訊 AI 影片 是建立在同步像素與聲波的協同效應之上。
優先考慮音訊架構的創作者在擁擠的數位市場中具有顯著優勢。透過利用「單次生成」,您將受益於:
- 減少製作時間: 消除了對外部配音工具的需求。
- 提升留存率: 精準的唇形同步與環境紋理能驅動更高的觀眾參與度。
- 平台多樣性: 內容無需額外母帶處理即可進行高保真廣播。
準備好引領「有聲」革命了嗎? 在評論區與我們分享您的第一部 Vidu Q3 作品,或持續關注我們對進階 Vidu 影片轉影片編輯技術的深度解析!
常見問題 (FAQ)
「單次生成」與傳統 AI 影片工作流程有何不同?
在傳統工作流程中,創作者先生成無聲視覺效果,再使用 ElevenLabs 或 SyncLabs 等第三方工具進行後期配音。由 Vidu Q3 和 Veo 3.1 等模型採用的 單次生成,在單一推論週期內合成音訊與影片。這種多模態方法確保了環境音與語音模式在數學上鎖定於視覺影格,根據 2026 年業界基準,手動「縫合」時間減少了約 60%。
目前哪些 AI 影片模型在原生音訊同步方面處於領先地位?
到 2026 年中,市場分為兩條路徑。有些模型專注於高階視覺效果,而另一些則致力於逼真的「有聲」功能。
| 模型 | 最大時長 | 音訊整合 | 適用場景 |
| Vidu Q3 | 16 秒 | 原生 (單次生成) | 敘事與社群廣告 |
| Kling 3.0 | 15 秒 | 原生 (雙語) | 電影級敘事 |
| Veo 3.1 | 8-10 秒 | 原生 (高保真) | 商業品牌內容 |
哪些技術因素會導致 AI「唇形同步漂移」?
當嘴部幾何結構的潛在空間映射隨時間與音訊訊號失去對齊時,就會發生「漂移」。關鍵因素包括:
- 片段長度: 如果角色說話超過 10 秒而沒有停頓,嘴部動作會開始失去軌跡。
- 光影: 當下巴和嘴唇的光線過於平淡時,系統無法清晰辨識嘴部形狀。
- 畫面細節: 以 720p 製作的影片通常會遺失在 1080p 影片中可見的細微面部動作。
AI 能在沒有提示詞的情況下創造自然的音效嗎?
雖然 Vidu Q3 等現代模型利用 聲學環境映射 自動生成環境音(如雨聲或腳步聲),但專業結果仍需要「錨定提示詞」。透過在提示詞中明確定義 [音訊層]——指定背景音樂的強度或音效的紋理——您可以引導模型的「聲學映射」層,防止音訊感覺脫節或過於通用。






