Seedance 1.5 Pro 现已登陆 Atlas Cloud:增强生成式视频的同步与控制
了解 Seedance 1.5 Pro,这是来自 ByteDance 的革命性 AI 视频生成模型,现已正式登陆 Atlas Cloud 平台,并提供强大的 API,供开发者使用。
Seedance 1.5 Pro 价格概览:
| 模型 | 价格 |
|---|---|
| Seedance 1.5 Pro 文本到视频 | $0.0867/秒 |
| Seedance 1.5 Pro 图像到视频 | $0.0867/秒 |
Seedance 1.5 Pro 介绍
作为 Seedance 1.0 的重大演进,ByteDance 的 Seedance 1.5 Pro 推出了 V2A 原生生成,可实现无缝同步的视听输出,旨在最大限度地提高专业视频创作效率。
Seedance 1.5 Pro 的核心功能与能力
视听同步
此次更新优先考虑了音频输入与视觉输出之间的对齐,确保了视频全程的技术一致性。
- 精确的唇形同步: 模型采用毫秒级计时来匹配口型与语音模式。这减少了生成视频中常见的"配音效果",即口型与发出的音素不匹配。
- 集成音景: 生成过程包括环境声音、基于动作的音频提示、背景音乐和人声,与视觉流同步。
- 时序情感对齐: 模型分析输入音频的语调和节奏,以调整角色的视觉情感表达,确保面部表演与台词的传递相符。
对比分析: 在许多当前的视频生成模型中,音频是单独生成或松散耦合的,导致长片段出现漂移。Seedance 1.5 Pro 集成了这些模态,有效减少了后期制作中手动重新计时或 ADR(自动对话替换)的需要。
多角色叙事与多语言支持
Seedance 1.5 Pro 扩展了生成能力,以支持复杂的交互场景和多样化的语言需求。
- 多角色交互: 该系统支持涉及多个说话者的场景,保持角色独立性并实现流畅的轮流对话。
- 全球语言覆盖: 该模型在英语、日语、韩语、西班牙语、印度尼西亚语、葡萄牙语和普通话等语言上表现出一致的性能。它还考虑了这些语言的地区方言。
- 自然语音合成: 音频引擎生成符合自然语音模式的声音,在不同语言中保持角色一致性。
实际应用: 对于跨国公司而言,此功能有助于创建本地化的培训材料或营销资产。可以用一种视频概念生成多种语言的版本,每种语言都有正确的唇形同步,从而无需为每个目标市场聘请单独的配音演员。
导演控制与提示遵循
此版本提高了用户通过文本提示指定特定视觉结果的能力,摆脱了随机生成。
- 镜头运动控制: 用户可以指定电影般的技巧,如平移、缩放、跟踪镜头和不同的运动速度,并获得可预测的结果。
- 动作保真度: 模型严格遵循描述特定角色动作、运动或与物体交互的提示。
- 场景构图: 用户可以控制镜头布局、时机和节奏。该系统还支持在生成过程中集成视觉效果。
对比分析: 标准的生成模型经常忽略复杂的指令集,导致"幻觉"镜头角度或不正确的动作。Seedance 1.5 Pro 可作为可靠的可视化工具,使故事板艺术家和导演能够在实际制作前准确规划场景。
视觉保真度与稳定性
Seedance 1.5 Pro 中的渲染引擎专注于保持高分辨率和结构完整性,适合专业显示。
- 纹理与细节: 输出模仿实拍素材,保持清晰的纹理并减少数字伪影。
- 光照与构图: 模型应用专业级色彩处理和稳定的光照物理学,防止不合逻辑的阴影放置。
- 时序一致性: 视频质量在不同场景和长时间内保持恒定,避免了在延长生成片段中常见的退化或变形。
实际应用: AI 视频的早期版本经常出现背景闪烁或物体变形的问题。此处提供的稳定性使其素材可用于商业广播或高清演示,在这些场合视觉错误很容易被注意到。
Seedance 1.5 Pro 的应用
企业本地化
- 场景: 一家全球软件公司需要同时发布七种语言的产品更新视频。
- 应用: 利用多语言支持和唇形同步功能,团队生成了一个单一的头像演示。他们输入了西班牙语、普通话和英语的脚本。模型生成了不同的视频文件,其中头像的口型与每种语言完美匹配,确保了所有地区的母语观看体验。
电影预可视化 (Pre-vis)
- 场景: 一位导演想可视化一个复杂的跟踪镜头,涉及两名演员在一辆移动的车辆中争吵。
- 应用: 利用镜头控制和情感对齐功能,制作团队输入了脚本和镜头运动提示。Seedance 1.5 Pro 生成了场景的粗剪版本,使摄影师能够在到达片场之前,根据 AI 生成的参考来规划灯光和镜头选择。
自动化新闻播报
- 场景: 一家媒体机构需要快速生成突发新闻文章的视频摘要。
- 应用: 该机构将其文本源连接到 Atlas Cloud 上的 Seedance 1.5 Pro API。模型会自动生成一个新闻主播,以中性、专业的语气朗读文本,并配以适当的背景视觉效果,在文本最终确定后几分钟内即可交付可发布视频。
结论
Seedance 1.5 Pro 在生成式视频方面提供了结构化的进步,从实验性输出转向了可控的、可用于生产的资产。通过解决同步、控制和视觉稳定性问题,它为需要精度和效率的创作者提供了一个实用的工具。
👇立即在 Atlas Cloud 上体验 Seedance 1.5 Pro。👇
Atlas Cloud 让您可以在一个沙盒环境中首次使用 Seedance 1.5 Pro,然后通过单个 API 进行访问。
方法 1:直接在 Atlas Cloud 沙盒中使用
在 沙盒 中试用 Seedance 1.5 Pro。
方法 2:通过 API 访问
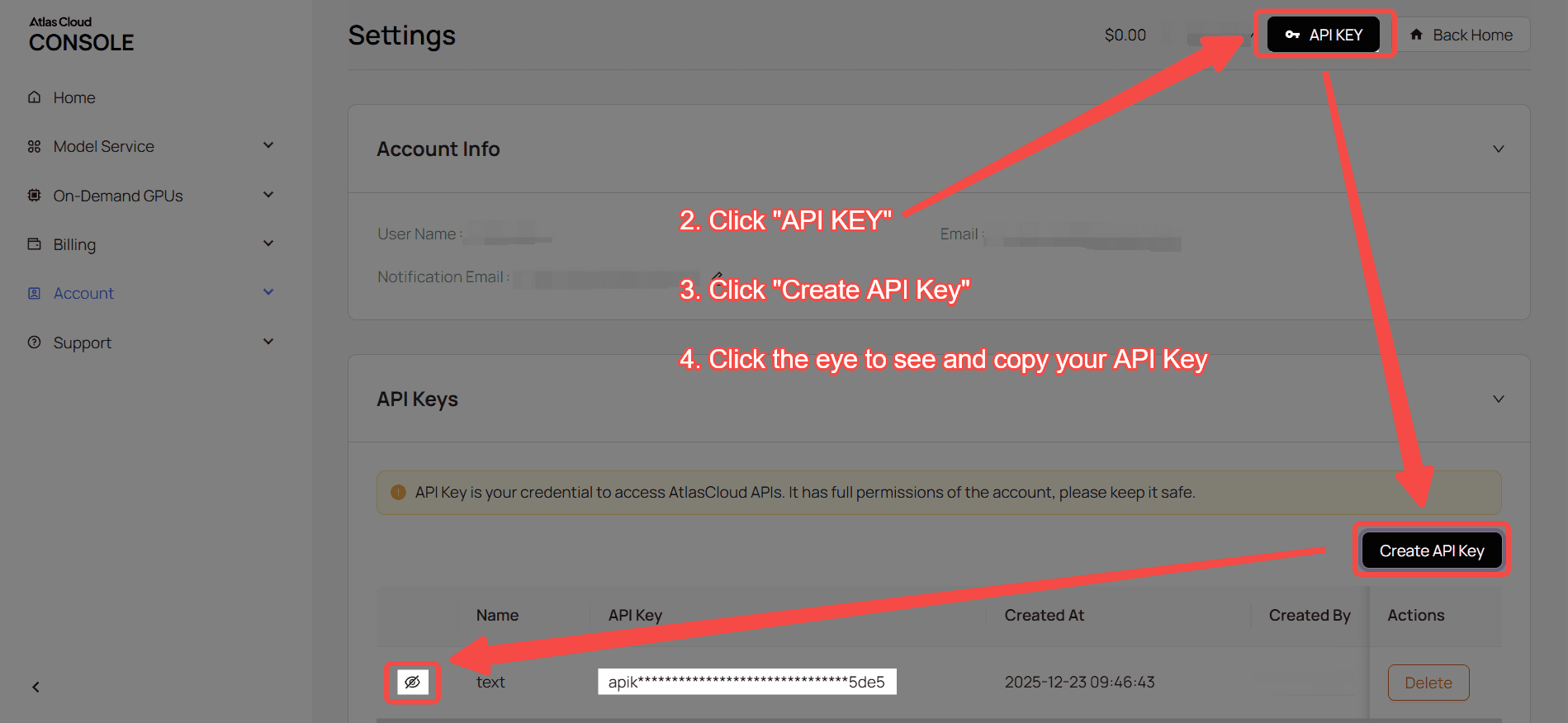
步骤 1:获取您的 API 密钥
在您的 控制台 中创建一个 API 密钥,并复制以备后用。
步骤 2:查看 API 文档
在我们的 API 文档 中查看端点、请求参数和身份验证方法。
步骤 3:进行您的第一个请求(Python 示例)
以 seedance 1.5 pro 文本到视频为例。
python1import requests 2import time 3 4# Step 1: Start video generation 5generate_url = "https://api.atlascloud.ai/api/v1/model/generateVideo" 6headers = { 7 "Content-Type": "application/json", 8 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 9} 10data = { 11 "model": "bytedance/seedance-v1.5-pro/text-to-video", 12 "aspect_ratio": "16:9", 13 "camera_fixed": False, 14 "duration": 5, 15 "generate_audio": True, 16 "prompt": "Shot 1 (establishing): Wide aerial of a quiet coastal cliff at sunrise, low fog rolling over the ocean, golden light breaking through thin clouds. A lone runner appears as a small silhouette on the winding path. Camera: smooth drone-like glide forward, slow and steady, cinematic pacing. Shot 2 (character): Medium tracking shot at ground level beside the runner, shoes crunching gravel, breath visible in the cool air, wind tugging at a lightweight jacket. Camera: gimbal-stable side-tracking, shallow depth of field, keep the runner's face and jacket details consistent. Shot 3 (emotion): Close-up on the runner's face—focused eyes, subtle micro-expressions, a quick swallow, determination building. Camera: gentle push-in, soft background bokeh, natural handheld micro-shake kept minimal. Shot 4 (end beat): The runner reaches the cliff overlook and slows to a stop; fog parts to reveal a vast sunlit ocean. The runner exhales and smiles slightly. Camera: slow tilt up from the runner to the horizon, hold for a calm finish. Style: photoreal live-action, natural sunrise lighting, filmic color grading, realistic wind and fabric motion, crisp facial detail. Continuity: same runner, same outfit, consistent sunrise direction and color temperature across shots; avoid warping, duplicate limbs, flicker, jump cuts, text overlays, logos.", 17 "resolution": "720p", 18 "seed": -1 19} 20 21generate_response = requests.post(generate_url, headers=headers, json=data) 22generate_result = generate_response.json() 23prediction_id = generate_result["data"]["id"] 24 25# Step 2: Poll for result 26poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 27 28def check_status(): 29 while True: 30 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 31 result = response.json() 32 33 if result["data"]["status"] in ["completed", "succeeded"]: 34 print("Generated video:", result["data"]["outputs"][0]) 35 return result["data"]["outputs"][0] 36 elif result["data"]["status"] == "failed": 37 raise Exception(result["data"]["error"] or "Generation failed") 38 else: 39 # Still processing, wait 2 seconds 40 time.sleep(2) 41 42video_url = check_status()
FAQ
Q: 该模型支持哪些语言和语音格式?
A: Seedance 1.5 Pro 提供原生的视听联合生成。
- 语言支持: 涵盖七种主要语言(英语、普通话、日语、韩语、西班牙语、印度尼西亚语、葡萄牙语),并支持地区方言的准确性。
- 优势: 通过集成语音和视觉合成,它实现了自然的唇形同步和多角色流畅性,这是单独拼接工具(如 ElevenLabs 的 TTS)在单一工作流程中无法比拟的。
Q:用户对镜头运动和场景指导有多大程度的控制权?
A: Seedance 1.5 Pro 提供精细的电影级控制,包括平移、缩放和跟踪。
- 精度: 它严格遵循用户关于角色表演和布局的提示,非常适合故事板规划。
- 差异化: 至关重要的是,它将这些视觉运动与音频节奏对齐,提供了标准视频生成模型中常常缺失的导演连贯性。
Q:视觉输出是否适合商业广播或大屏幕?
A: 是的。Seedance 1.5 Pro 提供的照片级真实感质量可与 OpenAI 的 Sora 和 Kling AI 相媲美。
- 视觉保真度: 它生成清晰的纹理和专业的照明,最大限度地减少了早期架构(如 **Stable Video Diffusion (SVD)**)中常见的"闪烁"或时序不一致问题。
- 商业用途: 其在长篇内容中保持风格一致性的能力,使其成为高端品牌叙事和高风险演示的可行解决方案。



