
你一定懂那种感觉。
深夜,品牌广告片已经改到了第四版。AI 终于生成了完美的灯光效果,但模特的面部却在今晚第三次发生了微妙的变化。衣服没变,人却换了。你无法交付,也无法修复,只能推倒重来。
到了午夜,你做的已经不再是视频剪辑,而是在玩轮盘赌。
对于任何试图构建叙事连续性的人来说——无论是要在多个镜头中保持同一模特的演示视频,在不同场景中保持同一教师的教学视频,还是在不同剪辑中保持同一歌手的音乐视频——“角色漂移”(character drift)一直是所有 AI 视频工具的隐形杀手。这就是为什么 AI 视频至今仍停留在“精美演示”的炼狱,而迟迟无法真正商业化的原因。

2026 年 5 月 19 日的 I/O 大会上,Google 的 Gemini Omni 给出了终结这一时代的答案。
其核心承诺在 Google DeepMind 的产品页面上浓缩为一句话:“你所做的每一次编辑都建立在前一次的基础上——从而保持场景的一致性和连贯性。”
那段悄然创造历史的“三步小提琴手”演示
I/O 发布会上最关键的时刻既不是那个滚动的弹珠,也不是那个泡泡雕塑,而是一位小提琴手。
以下是 Google 在舞台上演示并发布在其博客上的完整序列:
- 第一步: 一段小提琴手在舞台上演奏的基本视频。
- 第二步: 提示词——“将小提琴手传送到图像环境中。”结果:演奏者被移动到了新的背景中,但面部、姿势、持弓方式甚至手腕角度都保持完全一致。
- 第三步: 再次输入提示词——“将摄像机角度改为小提琴手上方过肩视角。”结果:构图改变,但依然是同一位小提琴手,身份相同,表演一致。
三次交互,同一个主体,零漂移。
如果你曾使用过现有的 AI 视频工具,这看起来简直像作弊。但事实并非如此。这是首次公开证明,“多轮精修”(multi-turn refinement)——即电影制作人、广告商和教育工作者一直在等待的工作流——在技术上已经成为现实,且具备交付能力。
为什么多轮一致性一直是 AI 视频的“痛点”
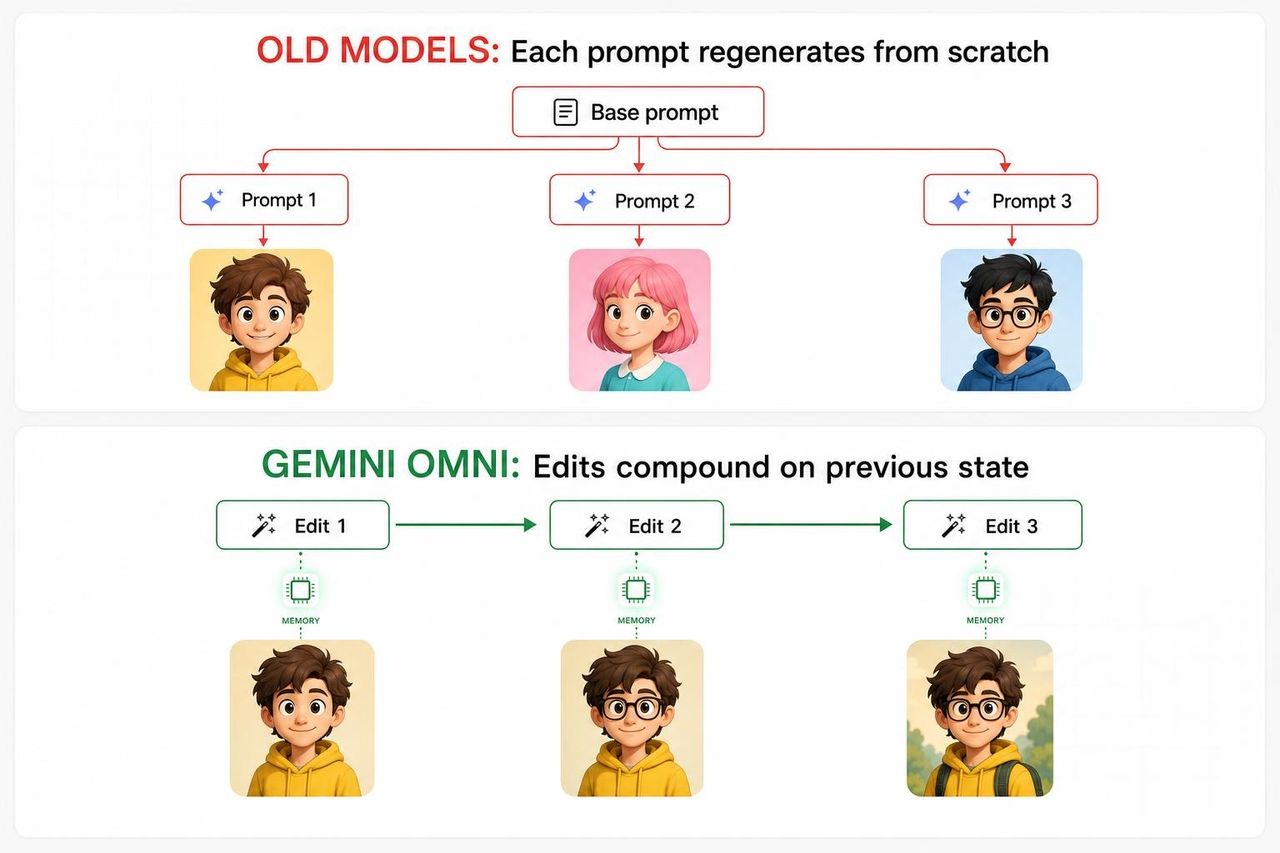
要理解为什么小提琴手演示如此重要,你需要了解其他 AI 视频模型在哪些地方失败了。
在传统的生成式视频管线中,每一个新的提示词本质上都是从零开始重新生成场景——将原始提示词与新提示词作为组合输入。模型在各轮交互之间没有真正的内部连续性。面部会漂移,背景道具会消失,灯光会突变。到了第三轮,结果往往已经偏离了最初的构思,导致创作者只能放弃并从头再来。
根本原因在于架构。大多数视频模型被训练为“单次生成器”,而非“多轮智能体”。它们被优化为从一个提示词中产生最佳输出,而不是记住上一次生成的内容并在此基础上进行精修。要求它们进行“编辑”,实际上是要求它们带着额外的上下文重新开始,而这种运算逻辑产生的不是累进式的精修,而是复合式的漂移。
Omni 的方法则不同。它被构建为一个“有状态的编辑器”(stateful editor)——这意味着每一轮交互都会更新场景的持久化表示,而不是从头重构。
“场景记忆”的真正含义
英语科技媒体们也在以各自的表述达成同样的共识。
Decrypt 最直白地描述了这一突破:“Google 表示,Omni 能够在用户更改视频后保持相同角色、背景和动作的一致性——这是许多 AI 视频模型都在挣扎解决的问题。”
Android Central 抓住了关键的技术细节:“该公司还表示,该模型能在多步修改过程中调用之前的指令,这使得迭代式编辑不再那么混乱。”
TechRadar 从电影视角进行了评价:“角色保持可识别,场景维持连贯性。动作保持一致,而不是每次更改提示词时都重置。”
而 Phandroid 将整个能力压缩为五个字:“场景记得之前的内容。”
这正是核心所在。场景有了记忆。 单凭这一特性,AI 视频就完成了从“玩具”到“工具”的蜕变。
Omni 与 Sora、Veo 及 Seedance 在一致性上的对比
截至 2026 年 5 月,各大主流 AI 视频模型在多轮一致性方面的表现对比如下:
| 模型 | ** |






