
近期行业预测显示,到2030年,80%的企业软件将内置多模态流水线(multimodal pipelines)能力,这相较于2024年不到10%的比例实现了飞跃。用户现在期待的是丰富的图像和流畅的视频,而不仅仅是智能文本块。通过统一平台整合 Flux 图像和视频技能,你可以在几分钟内添加强大的多模态功能。本指南将确切展示如何结合 Seedance-video-skill 文档 和 Flux 强大的 API,从简单的文本生成专业级视频。
为什么现在就应将多模态技术纳入你的技术栈

- 用户期望的转变: 无论是电子商务商店、社交媒体信息流还是移动应用,人们都期望获得动态的视觉体验。
- 内容格式的演变: 从文本开始,进化为图像,最终呈现为视频。
- 停滞不前的代价: 如果你的 2026 年 AI 开发技术栈 仅能处理文本,你将因团队必须手动拍摄或设计图形而错失宝贵的上市时间,同时也会失去海量内容扩展的机会。最糟糕的是,你将失去产品差异化优势。面对现实吧,如今任何人都能构建一个基础的文本包装器。真正的 全栈 AI 开发 意味着掌控整个媒体处理流程。
你可能会担心媒体生成所需的强大计算能力。但借助现代 API,可扩展推理(scalable inference) 将在后端为你处理。你无需购买昂贵的 GPU 服务器机架。
纯文本技术栈与多模态技术栈对比表
| 类别 | 纯文本技术栈(仅限 LLM) | 多模态技术栈(如:Seedance-Video-Skill + Flux) |
| 用户体验 | 静态,以阅读为主,需要专注 | 动态,视觉冲击力强,即时互动 |
| 内容产出 | 文章、代码片段、文本摘要 | 文本、图形、定制产品图、视频 |
| 参与度 | 对普通消费者来说中等到低 | 高(留存用户的时间更长) |
| 使用场景 | 聊天机器人、数据分析、文案撰写 | 电商广告、社交媒体自动化、游戏 |
| 基础设施需求 | 简单的 LLM API 访问 | 需要稳健的、可扩展推理架构 |
| 成本概况 | 每次生成成本极低 | 计算成本较高,但媒体投入产出比(ROI)极高 |
| 流程复杂度 | 直观,单步生成 | 多阶段(文本 → 图像 → 视频 → 编辑) |
那么,你该如何开始添加这些丰富的视觉效果呢?让我们看看拼图的第一块。
多模态流水线第一步:通过 Flux API 生成高保真视觉效果

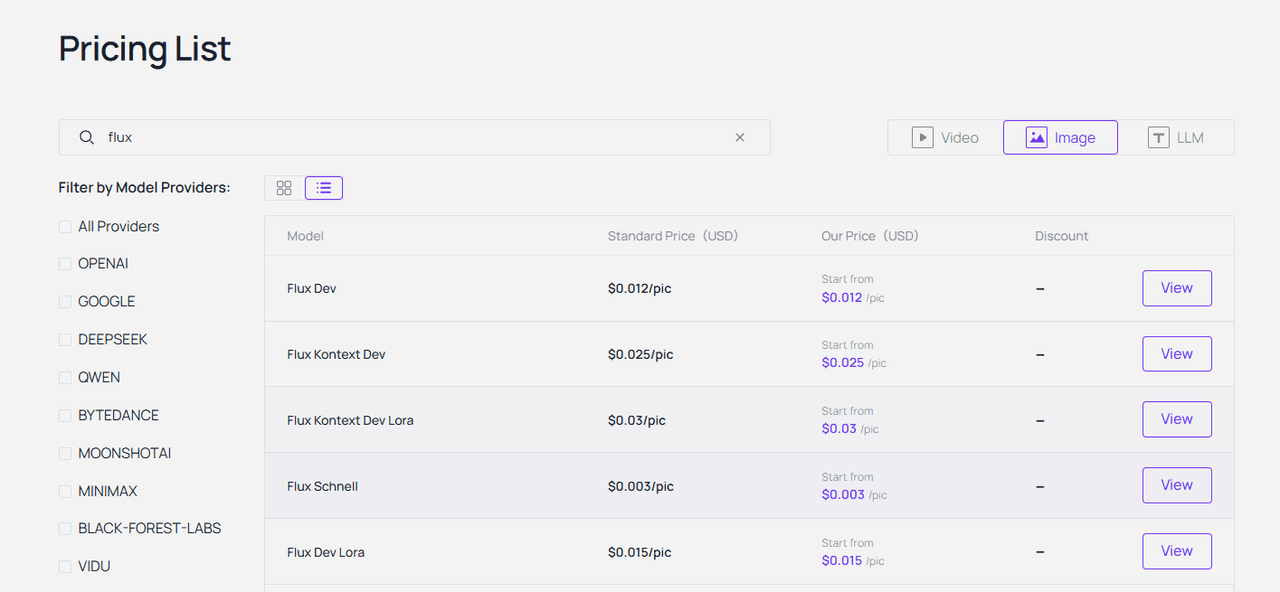
- 什么是 Flux?为什么开发者选择它? Flux 是一款高保真图像生成模型。开发者青睐它是因为它非常听从提示词。你无需猜测它的输出结果,它只会精准地交付你所要求的。
- 值得了解的模型版本: 在查看选项时,有几个版本值得关注。Flux -schnell 专为极速而生,非常适合快速原型设计。Flux dev 则在质量与效率之间提供了完美的平衡。然而,如果你在构建严肃的商业应用,连接 Flux.1 Pro API 是获取顶级、可靠结果的最佳选择。
- 关键参数: 使用该 API 非常简单。你主要调整三个关键参数。首先,设置 分辨率,例如 Web 文章常用的 1024x1024。其次,定义 步数(steps)。更多的步数会带来更丰富的细节,但会稍微增加一点时间。最后,调整 提示词一致性(prompt adherence),它控制 AI 严格遵循你指令的程度。
- 简单用例: 电商卖家通过调用 Flux Kontext(12B 参数,基于指令的编辑)API,将基础摄影素材转化为 全电商级商品目录。无需完全重新生成——只需用自然语言提示词编辑现有图像,同时保留产品细节、纹理和品牌风格。
现在你已经拥有了清晰的高质量静态图像,你可能会想:如何让它们动起来?
第二步:激活 Seedance-Video-Skill 以实现电影级 AI 视频

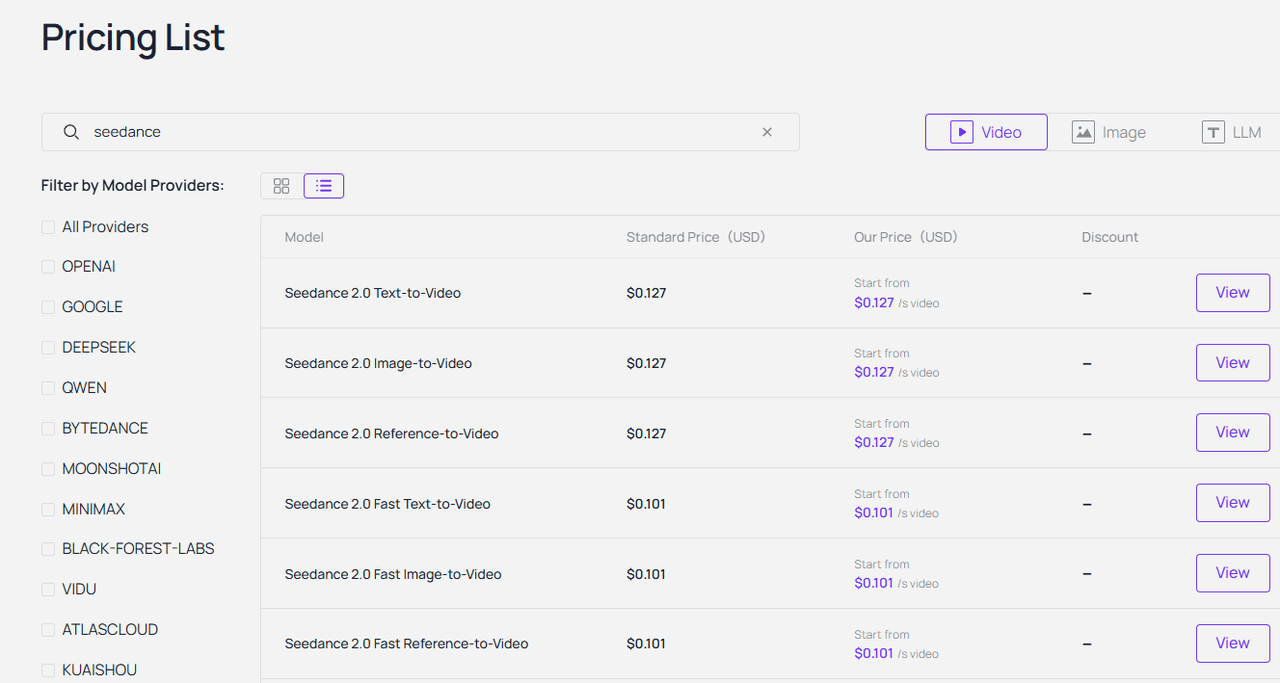
- Seedance-Video-Skill 的能力: Seedance-Video-Skill 能让你几乎瞬间将媒体从静态变为动态。它支持文本转视频以及 图像转视频(I2V) 生成,甚至可以执行高级的 视频转视频(V2V) 转换。
- 独特之处: 它真正独特的地方在于运动的一致性。你可以获得电影级的输出质量。角色在行走时不会随机变形,动作感觉非常稳定且自然。
- 文档要点:Seedance-video-skill 文档 非常清晰。端点简洁明了。你只需选择输入模式,定义视频时长并设置目标分辨率。如果你使用过标准的 REST API,会觉得非常亲切。
- 迷你用例: 一位 YouTuber 将一张 Flux 产品图直接转换为 Seedance 2.0 的图生视频模式,将其变成了 9 种以上的专业营销格式(开箱、试用、电影级广告),且保持了完美的统一性——解锁了完整的 Flux 图像和视频技能 工作流。他甚至不需要聘请视频剪辑师。
静态 → 动态流水线对比
| 能力 | 不使用 Seedance-Video-Skill | 使用 Seedance-Video-Skill |
| 将图像转视频 | 手动(需要复杂的专业软件) | API 自动化 图像转视频 (I2V) |
| 流水线集成 | 分散(大量的人工手动交接) | 统一(无缝集成到自定义后端) |
| 内容生产速度 | 缓慢(每个广告活动需要几天或几周) | 快速(分钟级生成数十个视频变体) |
| 可扩展性 | 受限于人力 | 近乎无限,由代码完全驱动 |
| 规模化成本 | 极高(需要庞大的创意团队) | 高度高效的 API 调用计费 |
| 迭代速度 | 缓慢,等待手动渲染 | 即时,只需调整参数并重新运行 |
现在你有了用于制作精美图像的 Flux 和用于流畅视频的 Seedance。但是,当把它们串联在一起时会发生什么呢?
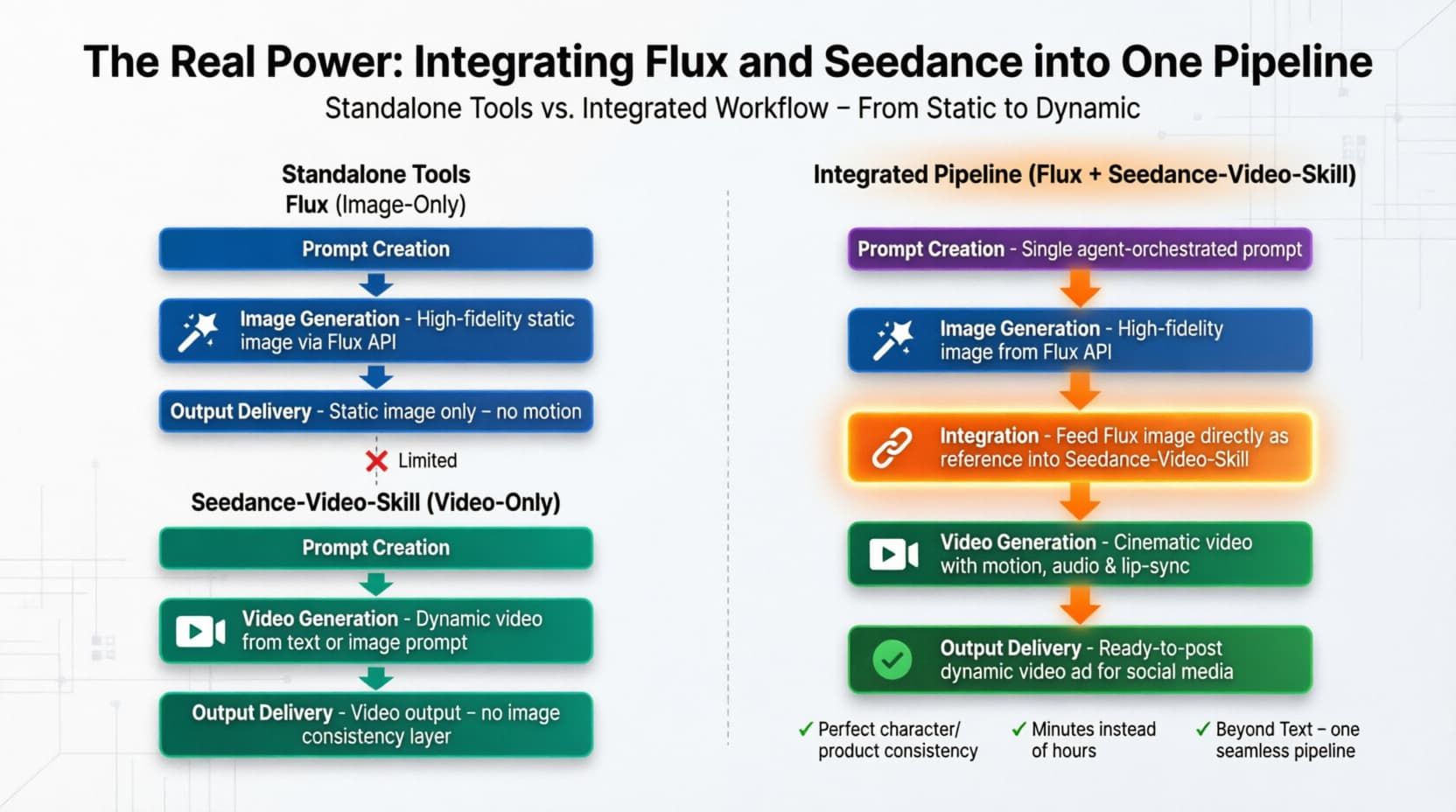
真正的威力:将 Flux 和 Seedance 集成到一条流水线中
- “图生视频”工作流: 过去构建“图生视频”工作流意味着要下载庞大的文件并处理混乱的脚本。现在,你只需要将 Flux 输出的图像 URL 直接传入 Seedance 输入端即可。它们共同构成了一个统一的 Flux 图像和视频技能。
- 我倾向于使用像 Atlas Cloud 这样的统一 API 平台。你只需要一个 API 密钥并选择一种调用模式,就可以访问两个强大的模型。你不必管理不同的账单设置。只需构建你的 多模态流水线,让平台来处理繁重的计算任务。
使用统一 API 平台显然会让代码变得非常整洁。但除了省事之外,还有哪些更深层次的商业原因呢?
为什么要使用统一 API 平台而不是直接访问
当你使用 AI 聚合平台时,你可以简化你的 全栈 AI 开发。你可以在一个平台下管理所有内容。想要更换模型?只需修改一行代码。你不必重写整个后端。这使得管理你的 可扩展推理 基础设施变得更加容易。它还让你能够在新模型发布的第一时间获得访问权限。
直接 API 与统一 API 平台对比
| 类别 | 直接集成(如:自行调用 Flux / Seedance API) | 统一 API 平台 |
| 所需 API 密钥 | 较多(多个 API、身份验证、配置) | 较少(单一入口点) |
| 模型切换 | 需要重大的代码重写 | 只需更改模型名称 |
| 账单 | 分散的账单,不同的条款 | 统一、可预测的账单(按秒或按视频计费) |
| 全球访问 | 通常需要自定义代理 | 内置全球边缘优化 |
| 新模型支持 | 手动 | 自动(发布即刻可用) |
现在你已经了解了设置原理,让我来向你展示如何从今天开始构建它。
三步入门
连接这些功能大约只需要十分钟。你只需遵循以下三个简单步骤,即可彻底升级你的 2026 年 AI 开发技术栈。
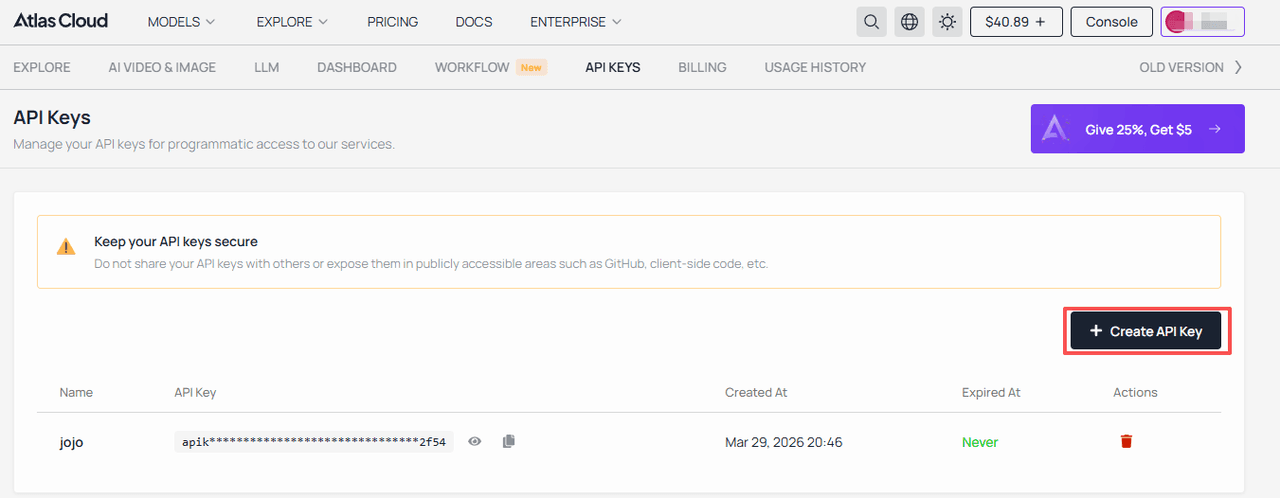
- 第一步: 从你选择的统一 API 平台 获取你的唯一 API 密钥。
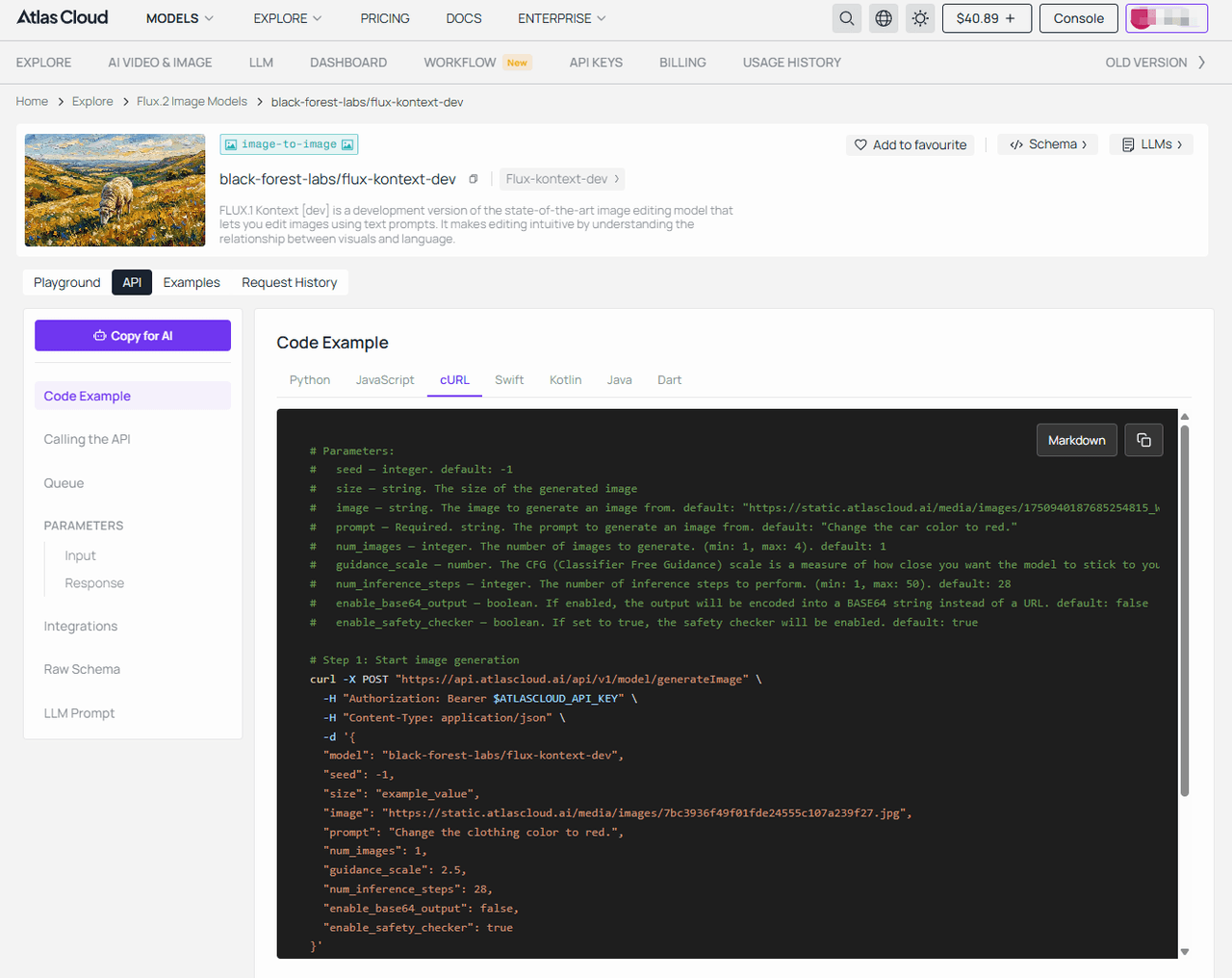
- 第二步: 调用 Flux 生成基础图像。(以 flux-kontext-dev 为例)
plaintext1# 参数说明: 2# seed — 整数。默认: -1 3# size — 字符串。生成的图像尺寸 4# image — 字符串。用于生成图像的参考图。默认: "https://static.atlascloud.ai/media/images/1750940187685254815_W4yPaBQU.jpg" 5# prompt — 必需。字符串。用于生成图像的提示词。默认: "Change the car color to red." 6# num_images — 整数。生成图像的数量 (最小: 1, 最大: 4)。默认: 1 7# guidance_scale — 数字。CFG 比例 (Classifier Free Guidance)。(最小: 1, 最大: 20)。默认: 2.5 8# num_inference_steps — 整数。推理步数。(最小: 1, 最大: 50)。默认: 28 9 10# 第 1 步: 启动图像生成 11curl -X POST "https://api.atlascloud.ai/api/v1/model/generateImage" \ 12 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 13 -H "Content-Type: application/json" \ 14 -d '{ 15 "model": "black-forest-labs/flux-kontext-dev", 16 "seed": -1, 17 "size": "example_value", 18 "image": "https://static.atlascloud.ai/media/images/7bc3936f49f01fde24555c107a239f27.jpg", 19 "prompt": "Change the clothing color to red.", 20 "num_images": 1, 21 "guidance_scale": 2.5, 22 "num_inference_steps": 28, 23 "enable_base64_output": false, 24 "enable_safety_checker": true 25}' 26 27# 响应: {"code": 200, "data": {"id": "prediction_id"}} 28 29# 第 2 步: 轮询结果 (将 {prediction_id} 替换为实际 ID) 30curl -X GET "https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" \ 31 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" 32 33# 持续轮询直到状态为 "completed" 或 "failed"
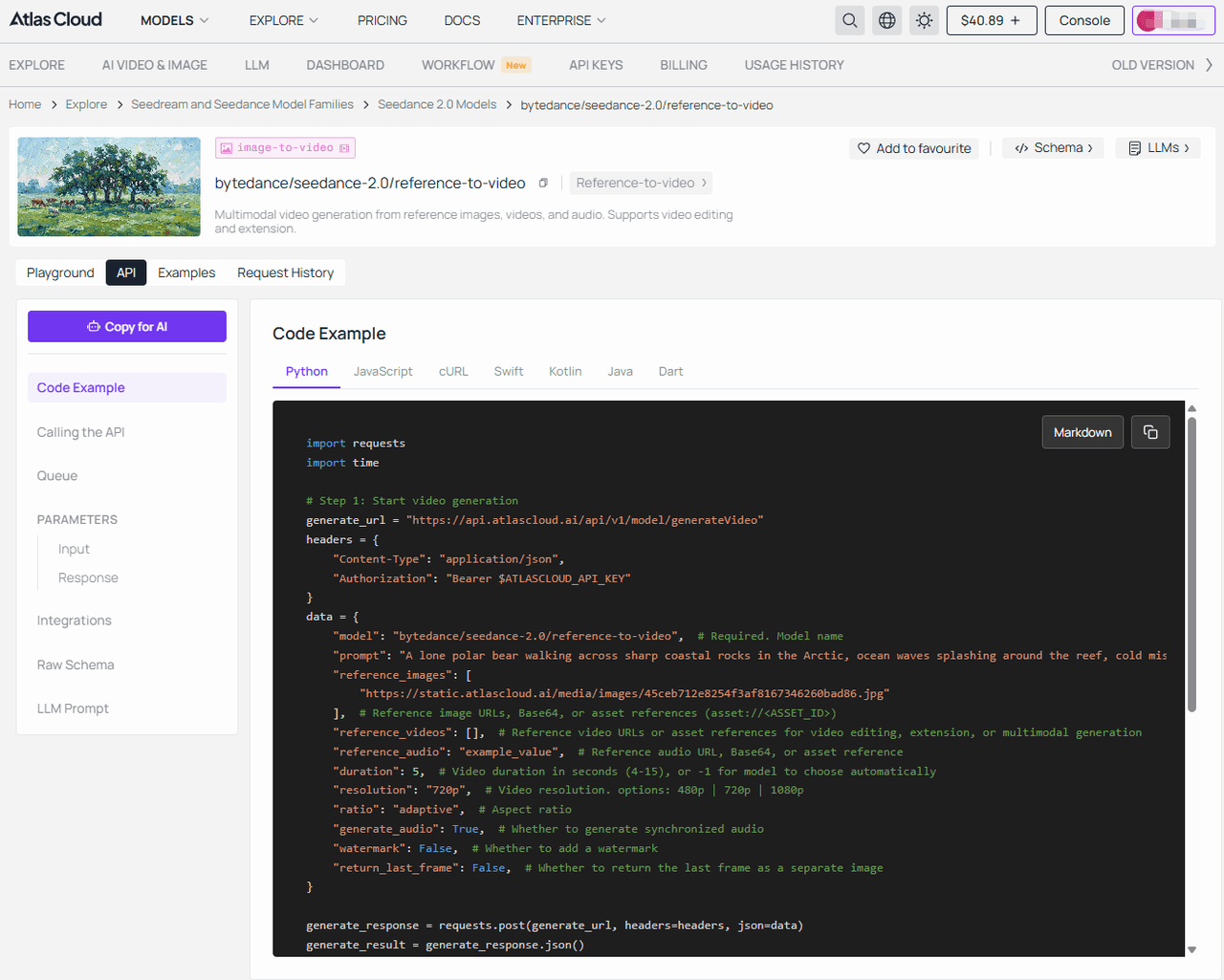
- 第三步: 将该图像 URL 直接传递给 Seedance 进行视频处理。(以 Seedance 2.0 reference-to-video 为例)
plaintext1# 参数说明: 2# prompt — 字符串。描述视频内容的提示词。 3# reference_images — 数组。参考图 URL 或资产引用。 4# duration — 整数。视频时长 (4-15秒)。默认: 5 5# resolution — 字符串。视频分辨率。默认: "720p"。 6 7# 第 1 步: 启动视频生成 8curl -X POST "https://api.atlascloud.ai/api/v1/model/generateVideo" \ 9 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 10 -H "Content-Type: application/json" \ 11 -d '{ 12 "model": "bytedance/seedance-2.0/reference-to-video", 13 "prompt": "A lone polar bear walking across sharp coastal rocks in the Arctic...", 14 "reference_images": [ 15 "https://static.atlascloud.ai/media/images/45ceb712e8254f3af8167346260bad86.jpg" 16 ], 17 "duration": 5, 18 "resolution": "720p", 19 "generate_audio": true 20}' 21 22# 响应: {"code": 200, "data": {"id": "prediction_id"}} 23 24# 第 2 步: 轮询结果 25curl -X GET "https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" \ 26 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" 27 28# 持续轮询直到状态为 "completed"
官方 Seedance-video-skill 文档 列出了所有你以后可能需要调整的高级参数。
分步转换流程
| 步骤 | 操作 | 输入 | 工具角色 | 输出 | 重要性 |
|---|---|---|---|---|---|
| 1. 生成视觉素材 | 调用 Flux API | 文本提示词 | Flux 生成高质量视觉图 | 清晰的静态图像 URL | 确立品牌视觉基准 |
| 2. 添加叙事与动作 | 将图像 URL 传给 Seedance | 静态图像 URL + 动作设置 | 图像转视频 (I2V) 引擎 | 流畅的电影级视频 | 将静态变为动态媒体 |
| 3. 编排与交付 | 向用户投放最终媒体 | 最终视频 URL | 统一聚合 API 平台 | 无缝的用户体验 | 证明你的全栈开发能力 |
在开始编写代码前还有疑问吗?让我们即刻消除它们。
常见问题解答(FAQ)
Q1:什么是“Flux 图像和视频技能”,它与传统 API 有何不同?
Flux 图像和视频技能 实际上是一个组合的多模态流水线。大多数传统 API 只输出基础的静态图片。这种方法将 Flux 的超现实图像输出直接与视频生成关联。它比传统工具更可预测,且更能精准地遵循你的提示词。
Q2:使用 Seedance-Video-Skill 我能构建什么以前做不到的东西?
比如自动化的 TikTok 广告、动态产品展示或交互式游戏资产。纯文本限制了你只能使用聊天界面,而 Seedance 让你迈向 全栈 AI 开发,在这里你可以完全掌控丰富的动态视觉媒体。
Q3:Seedance-Video-Skill 如何将静态图转换为动态视频?
它利用先进的 图像转视频(I2V) 乃至 视频转视频(V2V) 技术。你只需要输入一张图像 URL,模型就会预测自然运动帧。它能保持主体惊人的稳定性,避免你在其他地方常见的奇怪 AI 扭曲。
Q4:Flux 和 Seedance-Video-Skill 如何在同一工作流中协作?
你发送文本提示词给 Flux 生成高保真图像。然后,你的代码立即获取该图像 URL 并交给 Seedance 添加动作。这是自动化内容生产的“连环拳”。
Q5:我需要为 Flux 和 Seedance 分别使用 API 密钥吗?
使用统一 API 平台,你只需一个 API 密钥即可访问 Flux.1 Pro API 和 Seedance。这使你的账单清晰,代码极其简洁。
Q6:使用统一 API 平台对比直接集成模型有哪些好处?
它节省了大量的工程时间。你可以即刻获得全球范围内新模型的访问权限。此外,如果某个模型出现故障,你无需重写整个后端。可扩展推理 由平台为你处理,确保其在繁重负载下也能顺畅运行。
Q7:使用 Flux 和 Seedance-Video-Skill 生成图像和视频的成本是多少?
Atlas Cloud 按 API 调用严格按需计费。图像生成通常仅需几分钱。由于计算密集,视频生成成本略高,但相比聘请人类视频剪辑师,API 额度的投入产出比是巨大的。
Q8:Seedance-video-skill 文档包含什么,入门容易吗?
Seedance-video-skill 文档 非常易读。它清晰地涵盖了端点、输入模式和分辨率限制。即使你是 API 开发新手,通常也能在十分钟内运行测试。
结论
仅添加一个纯文本聊天机器人已远远不够。如果你想让你的 2026 年 AI 开发技术栈 经得起未来考验,你确实需要 多模态流水线。将 Flux 的精度与 Seedance 的动态运动相结合,可能是你今天能做的最明智的举措。
所有功能汇聚一处。一个平台。两个强大模型。零集成压力。 获取你的 API 密钥,亲眼看看从零开始生成电影级媒体是多么简单。立即开始尝试你自己的工作流吧。






