大多数人仍然认为更好的词汇就等于更好的图像。那是两年前的事了。现在已经不是这样了。
在 2026 年,真正的差距不在于模型之间。而在于“描述者”和“构建者”这两类用户之间。前者输入的是“电影感光效、4K、超精细”;而后者构建的是场景——光照方向、深度图层、拍摄角度。
如果你的图像看起来仍然很平,问题大概率不在模型本身,而在于你没有告诉它什么。
为什么你的提示词(Prompt)不再够用了(2026 年视角)
通用的提示词已经失效了。模型已经看过数百万次“最高质量”和“高细节”这类短语。这些词现在几乎无法产生任何实质性的改变。
什么才是真正重要的?结构化输入。光线从哪里来?前景和背景各有什么?你用的是什么镜头?现代模型会对这些变量做出响应。它们会忽略那些修饰性的废话。
这是一个常见的模式:有人写道“一张光线柔美的精美肖像”。模型输出的效果往往很平淡。为什么?因为缺乏光照方向,没有深度分隔,也没有相机角度。模型只能靠猜。而靠猜的结果就是平庸。
你需要做出的转变很简单:停止描述结果,开始构建场景。
7 个进阶技巧
-
指导光线的去向
“柔和光线”太模糊了。侧光、逆光、顶光——这些才能给模型提供具体的指令。方向产生阴影,阴影产生深度,深度赋予图像真实感。
试着把“柔和的肖像光”换成:
一位女性的肖像,左侧侧光,脸部右侧有柔和阴影,背景带有微妙的环境光

你可以立刻看出区别。模型现在清楚地知道光线的位置。
-
使用真实的摄影布光方案
三点布光、轮廓光、伦勃朗光。这些不仅仅是花哨的术语,更是模型在训练过程中见识过成千上万次的模式。使用它们,你的输出会变得更加稳定。
示例:
运动鞋产品照,三点布光设置,强主光,柔和补光,细微的轮廓光将产品与深色背景隔开

这比“戏剧性光效”每次都管用。
-
按层级构建深度
平面的图像通常意味着所有元素都在同一个平面上。通过明确指定前景、中景和背景来修复它。
示例:
咖啡杯在木桌上(前景),一个人正在笔记本电脑前工作(中景),背景是带有暖光的柔焦咖啡馆内部(背景)

现在模型有了可以利用的空间关系。
-
使用相机术语,而非风格标签
“赛博朋克风格”很模糊。“35mm 镜头,低角度,广角拍摄”则是精准的。相机设置直接对应图像的构建方式。
记住这些:
- 35mm:自然、日常的视觉感
- 85mm:带压缩感的肖像
- 广角:展现戏剧性和规模感
- 低角度、平视、顶视:改变视角
示例:
特写肖像,85mm 镜头,浅景深,平视角度,柔和背景模糊

这比“美学肖像”给模型的指令清晰得多。
-
通过对比引导注意力
到处都是高细节不是目标,对比才是。光与影、暖与冷、清晰的主体与模糊的背景。
三种有效的对比方式:
- 光影对比:明亮的主体对比暗色背景
- 色彩对比:冷色调背景上的暖色聚光灯
- 细节对比:清晰的主体对比模糊的环境
示例:
暖色聚光灯照射下的主体,背景为冷色调,高对比度布光,强主体聚焦
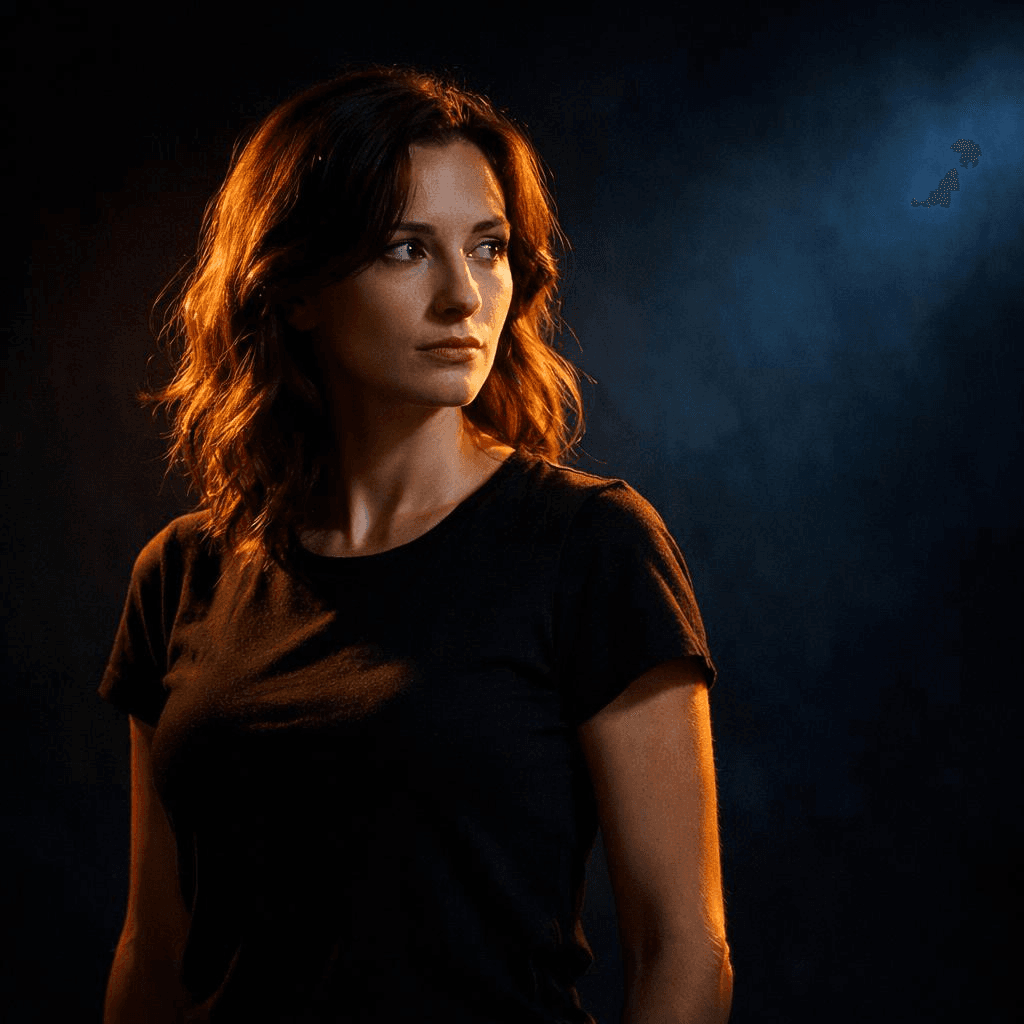
观众的视线会精准地落在你想让他们看的地方。
-
添加约束以清理混乱
长提示词往往会变得杂乱。与其添加更多细节,不如增加限制。告诉模型你不需要什么:无杂乱,无畸变,无多余物体。
示例:
极简主义产品照,居中构图,干净的白色背景,无杂乱,无文字,无畸变

约束条件往往比额外的描述更有用。
-
像导演一样迭代,而不是像赌徒一样尝试
没有人能一次就得到最终图像。专业人士的做法是:生成、微调、再生成。
简单的工作流:
- 第一步:基础构图,确定主体和环境
- 第二步:添加方向光和对比度
- 第三步:细化细节,去除杂乱
每一轮迭代都在提升结果。这就是从“靠运气”进阶到“可控性”的方法。
总结:构建专业的提示词框架
不要再把提示词写成长句子,将其作为模块化的系统来编写。
这是一个行之有效的结构:
plaintext1[主体] + [环境] + [光照] + [相机] + [构图] + [色彩] + [约束]
看看基础提示词和结构化提示词之间的区别。
示例:从基础提示词到专业提示词
基础提示词(典型用户):
女性模特穿着白色夏裙,干净的背景,影棚光,高细节,电商风格

专业提示词(结构化):
女性模特穿着白色夏裙(主体),站在极简影棚中,背景为柔和的米色纹理(环境),右侧侧光在身体左侧形成柔和阴影,微妙的轮廓光将轮廓与背景分开(光照),85mm 镜头拍摄,平视角度(相机),主体略微偏离中心,浅景深,柔和的前景模糊增加了深度(构图),暖色调自然光,柔和对比度(色彩),干净的构图,无杂乱,无畸变,无多余物体(约束)

结论:从提示词到导演思维
得到一张精美的图像固然好,但真正的项目需要成百上千张风格统一的高质量视觉素材。手动输入提示词是无法规模化的。
你会遇到实际问题:延迟、单张成本、保持跨批次的视觉风格一致性。仅靠提示词设计无法解决这些问题,你需要一套系统。
这就是基于 API 的图像生成至关重要的原因。你无需每次都在界面上输入提示词,而是将生成流程集成到工作流中。结构化的提示词可以重复使用、自动化,并随着时间推移不断优化。
像 Atlas Cloud 这样的平台为此提供了一个统一的 API 层。
如果你是: • 需要轻松、经济的 AI 访问权限的开发者。 • 需要在多个领域应用 AI 的团队。 • 需要可靠 AI 来完成重要业务的企业。 • 使用 ComfyUI 和 n8n 等工具的用户。
尝试 AtlasCloud,你将发现自己从单纯的尝试转变为真正的生产。无需从零开始构建基础设施。
未来不在于孤立地编写更好的提示词,而在于构建可控、可重复、生产就绪的视觉系统。
常见问题
为什么我的 AI 图像看起来还是平的?
图像显平通常是因为缺失了深度线索。想想摄影的原理,深度源于阴影、物体的遮挡关系以及对焦的差异。你的提示词必须明确写出这些内容。
以简单的提示词为例:“一个人坐在桌子旁”。这几乎没有告诉模型任何关于深度的信息。试着换成:“一个人坐在桌子旁(中景),窗外有模糊的城市灯光(背景),对焦在前景的咖啡杯上”。现在,模型有了可以发挥的层次。
光照是另一个人们常犯错的地方。许多提示词只提到了环境光,这会导致整张图像受光均匀且平淡。添加一个方向光源吧,侧光、逆光或轮廓光,任选其一。模型会开始投射阴影,你的图像立刻就会有体积感。
还有一点,不要试图用细节填满画面的每一个角落。留白和模糊非常有用,它们告诉观众该看哪里。有时,细节更少反而能带来更强的深度感。
AI 能取代产品摄影吗?
在很多情况下是可以的。但我们需要坦诚地看待它的适用范围。
如果你需要一张高端奢华腕表的“英雄图”——那种金属上的每一处反射都必须考究、皮带纹理必须丝毫不差的照片——传统摄影仍然是首选。在这方面,你无法超越真正的摄影棚。
但对于其他几乎所有内容,AI 都更快、更便宜。目录图、生活场景、季节性变体、A/B 测试素材,你可以在几秒钟内生成一张纯白背景的干净产品照,然后利用 AI 产品摄影生成器将其放入海滩、冬日小屋或现代厨房场景中。
无需租用影棚,无需布光设备,无需修图,每张图只需几美分。
对于小品牌和 DTC 初创公司来说,这是颠覆性的。他们现在可以生产出与拥有大预算的公司相竞争的视觉素材。这在两年前是不可想象的。
OpenAI 的视觉生成模型与之前版本有什么不同?
新模型 GPT‑image‑1.5 在底层架构上有几处改变。它使用了扩散 Transformer(Diffusion Transformer),这意味着它能更好地处理空间关系。
旧版本通常会将复杂的场景拆解成碎片,导致拼接不自然。例如,手可能漂浮在杯子旁边而不是握住它,阴影的方向可能完全错误。新版本保持了元素间的连贯性——手会真正握住杯子,阴影落在它该有的位置。
文本渲染是另一个巨大的飞跃。早期的模型生成的字符往往像乱码或随机符号。GPT‑image‑1.5 可以生成多种语言的可读文字。你甚至可以在同一张图中混合使用中文和英文。现在,这些真的可以实现了。
该模型还原生支持更高的分辨率——无需放大即可达到 2K。伪影更少,细节更锐利。
当然,也有缺点:该模型对模糊的提示词包容度更低。你不能只说“一张好看的肖像”就指望奇迹发生。你必须更加谨慎。但当你给它结构化的指令——光照方向、深度层级、相机设置时,其输出质量远超以往任何一代产品。






