AI 视频生成 API 以其“脾气古怪”而闻名,这并非没有道理。文本生成任务在出错时会立即返回 400 错误,而视频渲染则更加不可预测。一个任务可能会在没有任何警告的情况下在 GPU 队列中无限期挂起;或者只返回请求剪辑片段的一半;有时渲染看似完美完成,但最终视频看起来却不符合物理规律或严重畸变。
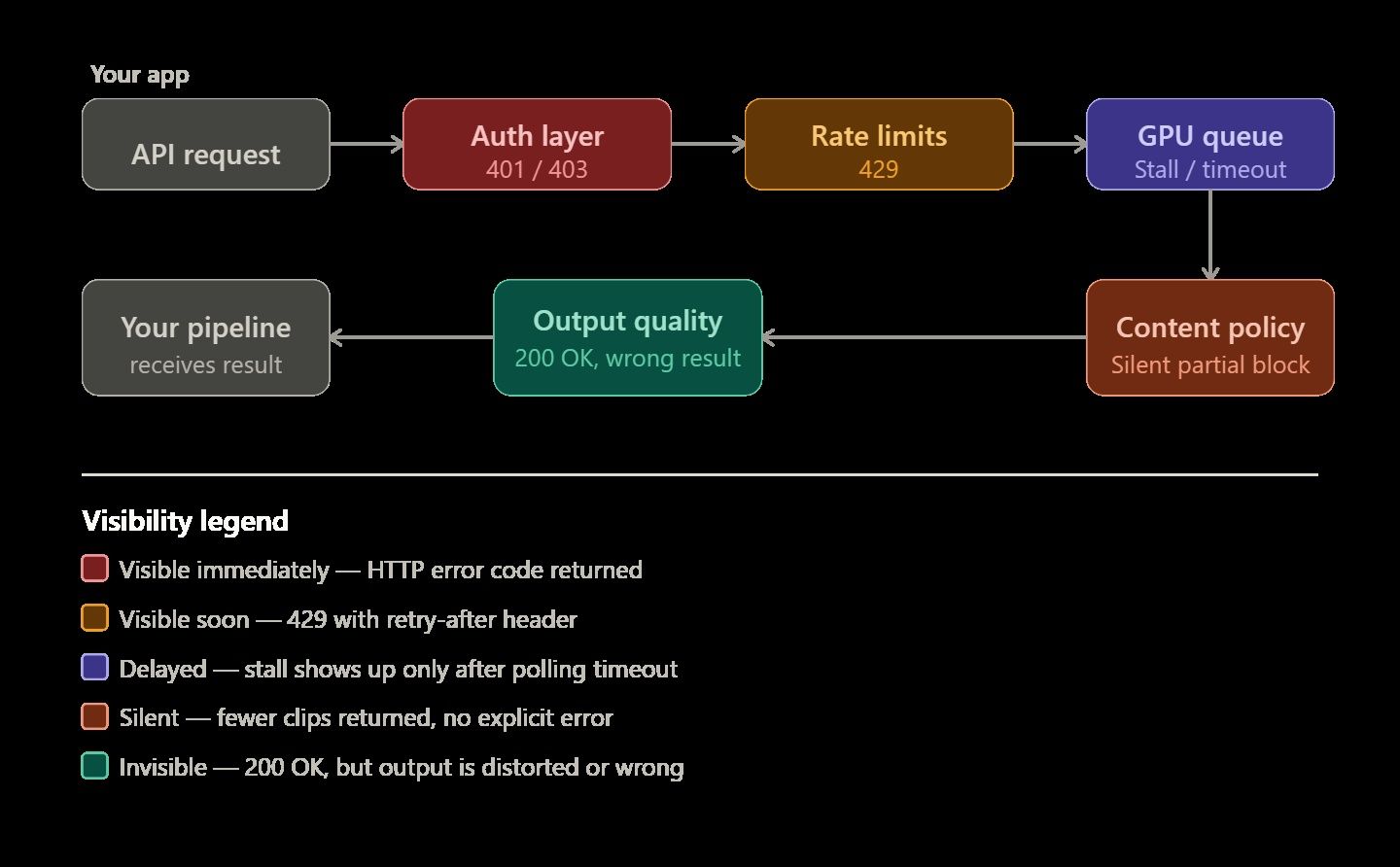
要构建一个可靠的系统,你必须了解这些特定错误产生的原因。这种认知是简单 Demo 与能真正服务于实际用户的视频处理流水线之间的核心区别。
本指南将深入探讨最常见的故障模式、如何准确解读 API 响应,以及构建成本更低、故障率更低的视频渲染流水线的具体策略。代码示例将使用 Atlas Cloud API,这是一个统一的推理平台,可通过单个端点访问 300 多种视频和多模态模型,非常适合作为多模型应用模式的参考。
AI 视频 API 错误的五大分类
AI 视频流水线错误通常属于五个特定类别。准确归类有助于你更快地解决问题,无论是修改代码、重写提示词,还是只需等待。
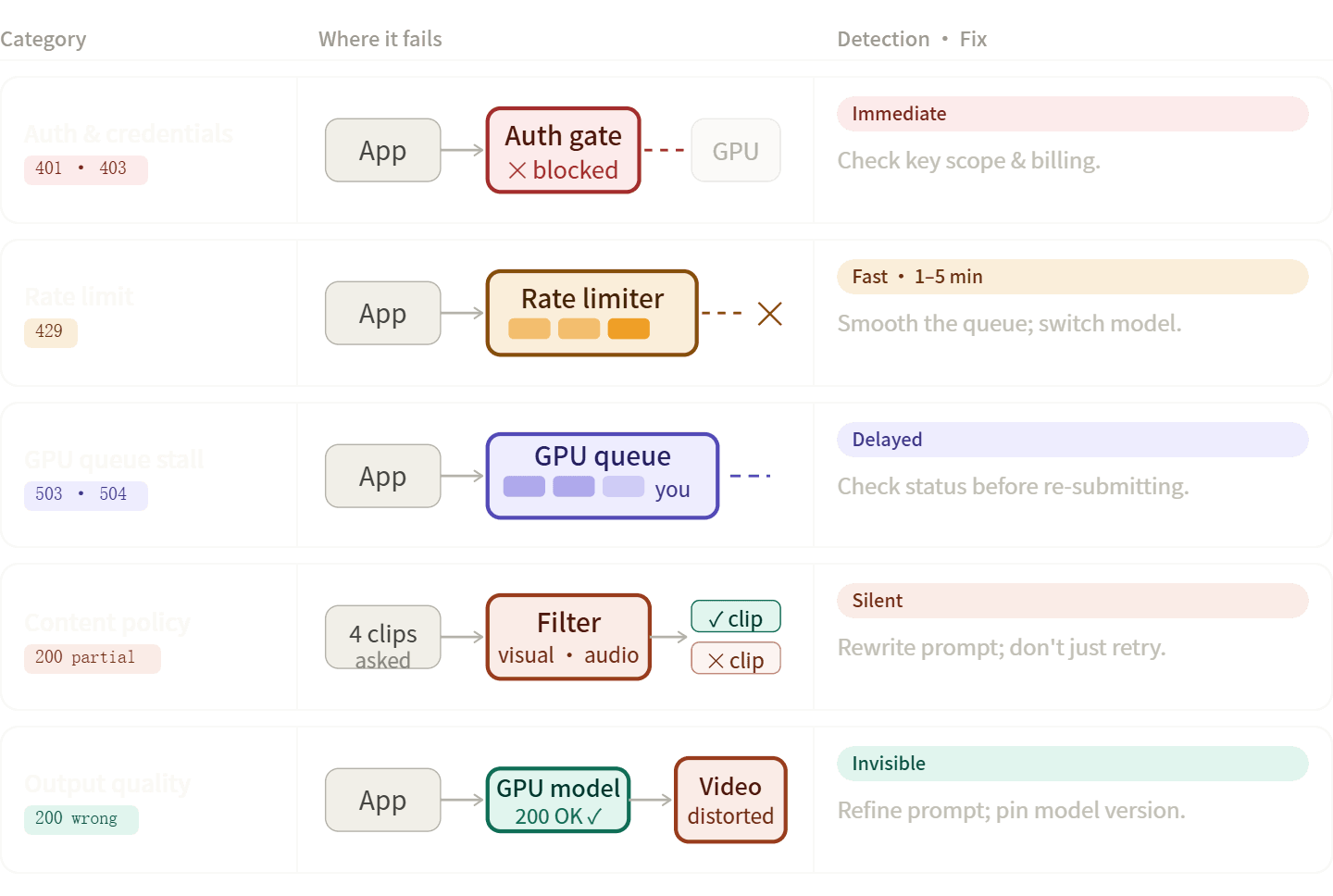
认证与凭证错误 (401, 403)
| 代码 | 常见原因 | 修复方法 |
| 401 Unauthorized | Authorization: Bearer 头部缺失或格式错误 | 确保密钥从环境变量加载,而非硬编码 |
| 403 Forbidden (配额) | API 额度已用尽 | 充值或升级套餐 |
| 403 Forbidden (权限) | 密钥缺乏访问目标模型的权限 | 生成带有正确权限的新密钥 |
人们常在此处感到困惑。配额超限和权限被拒都返回 403,但解决方法完全不同。不要只看状态码,务必查看响应体中的完整错误信息以排查原因。
在 Atlas Cloud 等平台上,单个 API 密钥即可涵盖所有模型,因此不会出现“A 提供商的密钥能用,但 B 提供商的密钥已过期”这种认证漂移问题。
速率限制错误 (429)
视频 API 的速率限制比文本 API 更为严苛,因为每个请求都会占用 GPU 槽位 30-90 秒。少量的并发请求就可能导致你原本看似充足的配额被瞬间占满。
首先需要明确的关键区分:
- RPM (每分钟请求数): Google Veo 3.1 API 的生产模型允许 50 RPM;预览模型限制为 10 RPM,且每个项目最多支持 10 个并发请求。
- 并发请求限制: 即使在 RPM 配额内,触及并发上限也会触发 429 错误。
- TPM (每分钟 Token 数): 虽然在视频 API 中较少见,但在支持多模态统一计费的平台上依然相关。
真正有效的应对策略:
| 方法 | 适用场景 | 不适用场景 |
|---|---|---|
| 指数退避 + 重试 | 由瞬时流量波动引起的 429 | 当并发上限是真正的瓶颈时 |
| 流量平滑 / 请求队列 | 大规模批量流水线 | 交互式、对延迟敏感的用户体验 |
| 非高峰期调度 (夜间批处理) | 内容预生成工作流 | 实时生成需求 |
| 路由到负载较小的模型变体 | 拥有多个同类模型的统一平台 | 单提供商设置 |
内容合规与安全过滤器拦截
这类错误容易被误诊,因为 API 响应有时并不明确 — 仅仅是返回的视频片段少于你请求的数量。Google Veo 的文档明确指出,如果返回的视频少于请求数,部分输出可能是被安全过滤器拦截了,而非请求在传输层失败。
两个不同的触发维度:
- 视觉提示词: 主题内容、场景背景,或暗示性的暴力/成人内容。
- 音频/对话提示词: 语音内容、歌曲请求和密集的声景会触发独立的过滤栈。
如果你的剪辑仅在音频包含在提示词中时失败,请将音频与视觉场景分开调试。重试被策略拦截的提示词几乎无效 — 必须修改提示词本身。
传输与基础设施错误 (500, 503, 504)
| 代码 | 典型恢复时间 | 处理方式 |
|---|---|---|
| 429 RESOURCE_EXHAUSTED | 1–5 分钟 | 退避并重试 |
| 503 Service Unavailable | 30–120 分钟 | 等待;查看状态仪表板 |
| 504 Gateway Timeout | 不定 | 重试前检查渲染任务是否仍在处理中 |
| 500 Internal Server Error | 不定 | 记录预测 ID;未确认状态前严禁自动重试 |
处理 500/504 错误的关键规则是:在重新提交之前,务必检查渲染任务是否仍在处理中。盲目重试 504 错误会导致重复渲染并造成费用翻倍。
输出质量失败
这类问题不是 HTTP 错误 — API 返回 200,但结果不对。常见形式如下:
- 视觉瑕疵或几何形状不准确: AI 视频本质是概率性的,模型是在解释输入而非物理计算。
- 支持音频的模型缺失音频: 通常是提示词或参数问题,而非基础设施故障。
- 持续时间或分辨率错误: 由不支持的组合引起 — 并非所有模型都支持所有时长/分辨率的搭配。
- 流水线静默丢弃: 某些编码流水线会静默丢弃特定格式下的视频,仅在质量保证 (QA) 环节发现。
读取异步响应:预测 ID 与状态轮询
AI 视频生成本质上是异步的。请求-响应周期分为两个阶段:
- POST 到生成端点 → 接收一个
prediction_id - GET 结果端点并传入该 ID → 轮询直至达到终端状态
Atlas Cloud 的响应模式展示了已完成的预测结果:
plaintext1{ 2 "id": "pred_abc123", 3 "status": "completed", 4 "model": "bytedance/seedance-2.0/text-to-video", 5 "outputs": ["https://storage.atlascloud.ai/outputs/result.mp4"], 6 "metrics": { "predict_time": 45.2 }, 7 "created_at": "2025-01-01T00:00:00Z", 8 "completed_at": "2025-01-01T00:00:45Z" 9}
三个终端状态:
| 状态 | 含义 | 后续操作 |
|---|---|---|
| completed | 渲染成功;可获取输出 | 在过期时间内下载 |
| failed | 渲染失败;查看 error 字段 | 记录错误信息;决定是否重试 |
| expired | 输出已不再可用 | 若仍需要,请重新提交 |
最常见的轮询错误
开发者常检查 status === "failed",却从未阅读随后的 error 字段。该字段包含可操作的信息——没有它,你只知道失败了,却无法判断是该改提示词、查配额还是等待基础设施恢复。
生产级轮询模式
plaintext1import time 2import requests 3 4def poll_prediction(prediction_id: str, api_key: str, max_wait: int = 600) -> dict: 5 url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 6 headers = {"Authorization": f"Bearer {api_key}"} 7 terminal_states = {"completed", "failed", "expired"} 8 wait = 5 9 10 for _ in range(max_wait // wait): 11 resp = requests.get(url, headers=headers).json() 12 status = resp.get("status") 13 14 if status in terminal_states: 15 if status == "failed": 16 print(f"Render failed: {resp.get('error')}") 17 return resp 18 19 time.sleep(wait) 20 wait = min(wait * 1.5, 60) # 将退避时间上限设为 60s 21 22 raise TimeoutError(f"Prediction {prediction_id} did not complete within {max_wait}s")
在每次成功渲染后记录 metrics.predict_time。该数值的飙升是基础设施性能退化的领先指标,在出现大规模失败前是一个非常有用的信号。
构建弹性渲染流水线
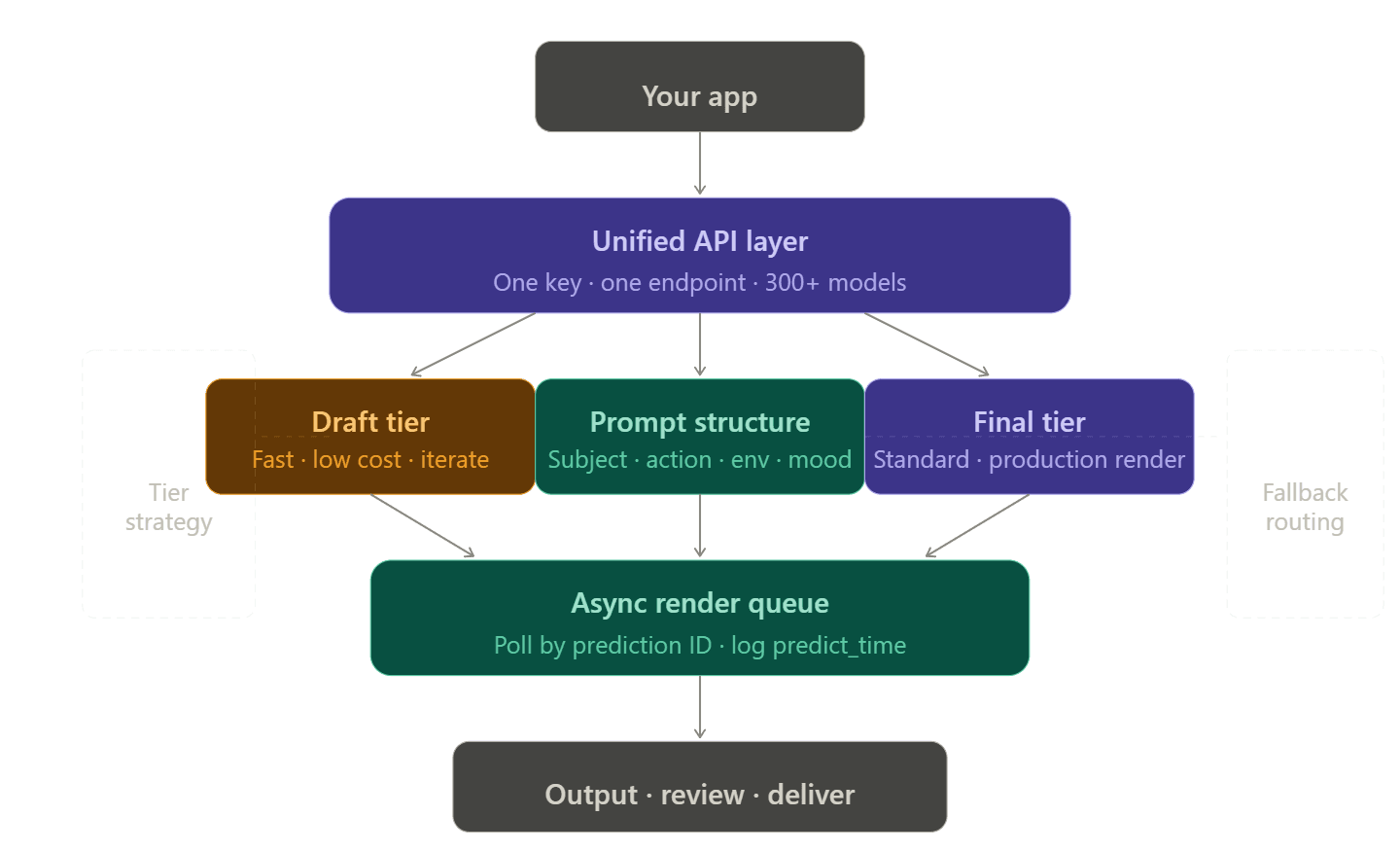
单一供应商 vs. 统一 API 架构
为每个视频提供商管理不同的账号、令牌和账单页面是非常痛苦的。开发者通常称之为“集成税”,而且随着扩展,情况会迅速恶化。一旦某个模型达到限额,你需要备用方案。而该备用方案又需要单独的 API 密钥、账单设置和错误处理代码。
统一 API 平台通过单个端点路由多个提供商,从而消除了这种负担。在 Atlas Cloud 上,将 openai/sora-2/text-to-video 切换为 bytedance/seedance-2.0/text-to-video 只需更改一个字符串,头部信息、认证和计费逻辑保持完全一致。
草稿至成品的分层管理
提高成本效益和可靠性最有效的手段之一,是根据工作流阶段选择合适的模型分层:
| 阶段 | 推荐分层 | 理由 |
|---|---|---|
| 提示词探索 / 概念测试 | 快速/经济层 | 比标准层节省 78%+ 成本;错误排查更廉价 |
| 内部评审草稿 | 快速层 | 足以满足利益相关者评审 |
| 最终成品渲染 | 标准/专业层 | 质量差异足以抵消成本 |
| 批量内容 (社交媒体/营销) | 快速层 | 大规模使用下成本差异显著 |
在 Atlas Cloud 上,Seedance 2.0 的“快速”层价格为每秒 USD0.081,而“标准”层为 USD0.10,在大规模应用下差异非常可观。一个每月生成 200 个 10 秒视频片段的团队,使用“快速”层只需花费 USD162,而“标准”层则需 USD200。
以提示词工程预防错误
模糊的提示词是导致流水线失败的隐性元凶。像“一个人在走路”这样的提示词会强迫模型做出过多的随机选择,导致产出不一致,从而引发更多重试。
可靠的四段式提示词结构:
plaintext1[主体 + 细节] + [动作 + 运动风格] + [环境 + 光照] + [相机 + 氛围] 2 3示例: 4"一位穿着红色大衣的女性在雨后的东京街道上快步走着, 5夜晚霓虹灯倒映在潮湿路面上,中景追踪镜头,电影感且紧张"
在使用支持多模态输入的模型时(如 Seedance 2.0 支持最多 12 个参考文件,包括图像、视频片段和音频),提供视觉参考可以显著降低导致输出质量下降的歧义。
选择合适的模型
并非所有 AI 视频工具的失败原因都相同,因为它们的目标各异。针对特定任务使用错误的模型是一个重大错误,这会导致看起来像技术故障的低质量产出,而实际上模型本身并不适合该任务。
模型能力参考
| 模型 | 优势 | 注意点 | 定价 (Atlas Cloud) |
|---|---|---|---|
| Wan 2.7 | 物理模拟、逼真的物体交互 | 仅支持单图参考;成本较高 | USD0.1/秒 |
| Kling 3.0 | 高分辨率输出;原生口型同步;免费额度 | 最高分辨率生成耗时较长 | USD0.071–0.143/秒 |
| Veo 3.1 | 电影级质量;合规性强 | 预览版模型速率限制 (10 RPM) | USD0.05–0.20/秒 |
| Seedance 2.0 | 多参考输入控制;原生音频 | 需要更精细的提示词构建 | USD0.081–0.10/秒 |
| Wan 2.6 | 最低成本;高容量内容生成 | 无原生音频;最大 1080p | USD0.018–0.07/秒 |
定价数据源自 Atlas Cloud 2026 年 4 月文档。如需具体定价,请查阅官网。
何时切换模型 vs. 修改请求
以下情况切换模型:
- 仅在提示词包含音频或对话时稳定失败,该模型可能不支持音频能力
- 物理或物体交互质量是失败主因,而非提示词问题
- 你正在使用的预览版模型触及了生产版不会遇到的速率限制
以下情况修改提示词:
- 输出风格不符但结构正确
- 特定语言触发了安全过滤器
- 时长或分辨率参数被拒绝
锁定特定的版本字符串(例如 kling-v3.0-std 而非 kling-latest)。静默的模型更新可能引入质量倒退,不锁定版本几乎无法调试。
调试工具包
每个阶段的日志建议
日志是缩短调试时间最快的方法。一个有效的最小化日志包含:
请求时:
- 模型 ID 和版本
- 提示词 Hash(而非全量提示词,保持日志紧凑)
- 时长、分辨率和模式参数
- 时间戳
响应时:
- 预测 ID
- 初始状态
- 任何即时的错误信息
轮询完成时:
- 最终状态
- metrics 中的
predict_time - 错误字段内容(如果失败)
- 输出 URL(如果成功)
解析基础设施与应用错误
当生成失败时,快速诊断流程可节省时间:
- 首先检查 API 健康状态仪表板 — 如果平台本身状态不佳,你就查错方向了。
- 读取
x-deny-reason响应头 — 出口代理拦截会出现在这里,如果不检查此头,看起来就像是模型错误。 - 如果是从前端调用,检查 CORS 错误 — 在浏览器开发者工具中,这与认证失败的症状一致。
- 验证文件约束 — 大多数平台强制要求最大输入文件大小(通常为 16MB)和有限的接受格式列表。
Atlas Cloud 的监控面板会显示自动缩放状态和按请求的用量数据,这有助于区分基础设施缓慢的特定日期与提示词或代码本身的问题。
成本优化
三大杠杆
渲染成本是三个变量的乘积。同时优化这三个维度(而非仅仅寻找更便宜的模型)能带来最大的成本节约:
| 杠杆 | 低成本选择 | 高成本选择 | 典型倍数 |
|---|---|---|---|
| 模型分层 | 快速层 | 标准/专业层 | 3–5 倍 |
| 时长 | 4–5 秒 | 12–15 秒 | 3 倍 |
| 分辨率 | 720p | 4K | 2–4 倍 |
单个 8 秒 4K 标准渲染的成本可能比同等时长的快速 720p 渲染高出 6–8 倍。如果你的分发渠道是社交媒体或 Web,终端用户通常看不出 720p/1080p 与 4K 的区别。
按量付费 vs. 订阅制
消费者 AI 套餐(如 Google AI Pro 或 Ultra)提供的是 AI 界面内的有限生成,并不包含 API 访问权限。这是团队从消费者工具转向生产流水线时常见的预算规划失误。
Atlas Cloud 采用按量付费,使成本与你的实际构建量挂钩。如果你的项目需求每周都在变,这种模式最合适。你应该追踪成品视频每秒的成本,这是公平比较不同模型和定价层级的最佳方式。
复用参考素材
如果你生成的许多剪辑涉及相同的角色、场景或风格参考,请预先注册这些素材:
- 上传参考图片或视频一次,并存储返回的
asset_id - 在后续请求中传入
asset://<ark_asset_id>,而非重复上传 - 大多数平台对参考文件上传不计费,仅按生成输出的时长收费
生产就绪清单
在将视频生成流水线投入生产之前,请验证以下事项:
认证
- API 密钥从环境变量加载,而非硬编码
- 密钥拥有所有使用模型的正确权限范围
- 已实施轮换策略
速率限制与并发
- 确认每个模型层级的 RPM 和并发请求限制
- 批量工作流已配置流量平滑或队列
- 配置了针对速率限制场景的降级/备份模型
错误处理
- 已处理所有终端状态 (completed, failed, expired)
- 失败状态下已捕获并记录 error 字段
- 针对长渲染任务将子进程/请求超时设置为 ≥ 10 分钟
- 在检查状态前,对 500/504 错误不进行盲目自动重试
内容与提示词
- 提示词已针对平台内容准则进行预审
- 在测试中分离了音频和视觉触发条件
- 已采用四段式提示词结构作为团队标准
模型配置
- 锁定特定版本字符串(而非 latest)
- 模型层级与工作流阶段匹配(草稿用快速层,成品用标准层)
- 已确认所选模型的所有必需参数(时长、分辨率、音频)
成本控制
- 已配置带有预警功能的按量付费仪表板
- 非最终渲染默认使用快速层
- 复用参考素材 ID 以减少上传次数
可观测性
- 每次渲染都记录预测 ID、状态和
predict_time - 已收藏 API 健康仪表板并在调试前优先检查
- 已配置针对
predict_time飙升的预警
一个能够处理错误的视频流水线并不比容易崩溃的流水线更难构建。你只需要在每一步处理失败时足够机敏。确保日志记录稳健并坚持使用特定模型版本。在考虑其他问题之前,先搭建一个从快速草稿到最终渲染的闭环流水线,其余一切都会水到渠成。
常见问题解答
Premium 套餐下的 429 Resource Exhausted 错误是什么原因引起的?
429 错误仅表示你触及了速率限制 (Rate Limits)。为了保持系统平稳运行,提供商会限制你的请求数和 Token 数。
- 修复方法: 在代码中添加指数退避 (Exponential Backoff),帮助系统在失败时自动等待并重试。同时检查仪表板中的“使用层级”,你可能需要增加预算以解锁更高的速率。
如何避免“内容审核”误判?
安全过滤器经常将专业提示词误解为违规内容。
- 修复方法: 优化你的提示词,将模糊词替换为技术术语。不要说“混沌能量”而应说“高速相机移动”。你也可以使用 LLM 来清洗提示词,使其转化为机器能理解的明确描述,从而避免误判。
如何降低渲染流水线的延迟?
延迟通常源于糟糕的轮询机制或模型尺寸过大。使用 Webhooks 代替手动轮询来接收完成数据。如果是自托管,应用 FP8 量化可加速推理。对于 API 用户,切换到异步处理,以便并行处理多个生成任务,而非串行处理。






