
我们使用 6 个完全相同且模型中立的提示词(Prompt)对 Grok Imagine Image 和 GPT Image-2 模型进行了测试,涵盖了组合语义、照片级解剖结构、多语言文本渲染、几何变换、局部编辑以及多参考图融合。
Grok Imagine Image 和 GPT Image-2 模型均可通过同一个 Atlas Cloud API 密钥调用,确保此基准测试可以在几分钟内复现。
为什么进行此 AI 图像模型对比基准测试
你在网上看到的每一个“AI 图像模型对比”都陷入了同样的陷阱:刻意挑选的提示词、从五次输出中选出最优结果,以及未经证实的断言。本基准测试基于 Tier A 原则构建:模型中立的提示词、所有模型使用完全相同的输入、单一随机种子默认输出(无樱桃采摘行为),以及每个类别均可用一句话概括的评分标准。
本次完整基准测试运行了六个模型:Grok、GPT Image 2、Nano Banana 2、Nano Banana Pro、Wan 2.7 和 Seedream 5.0。本文专注于 Grok 与 GPT Image 2 的直接对决,这是开发者在选择默认图像模型时最具商业参考价值的组合。
Grok Imagine Image 与 GPT-Image 2 的测试方法:6 个类别,一个 Tier A 规则
每个提示词都针对一个明确的单一能力维度。通过/失败标准在模型运行前即已定义,而非在查看输出后制定。
| 类别 | 测试的核心维度 | 一句话通过/失败标准 |
|---|---|---|
| 类 1 · 组合语义 | 指令对齐 | 模型是否识别了 7 个物体,摆放正确,并遵守了否定列表? |
| 类 2 · 照片级解剖与光影 | 视觉质量与物理规律 | 5 根手指解剖结构是否正确,面部是否出现了焦散光斑? |
| 类 3 · 多语言海报 | 图像内文本渲染 | 中英文是否渲染正确,无笔画缺失或乱码? |
| 类 4 · 几何变换 (I2I) | 编辑可控性与身份保留 | 旋转 45° 后,人物是否依然可辨识且服装细节完好? |
| 类 5 · 局部编辑与区域保留 | 编辑精度 | 是否只进行了 3 处编辑,其余像素是否保持不变? |
| 类 6 · 多参考图融合 | 跨图像一致性 | 3 个参考图的身份、风格和场景是否融合为一张连贯的图像? |
类 1 · 组合语义 (T2I)
提示词:
一张木制餐桌的平铺俯视图,画面中严格包含七件陶瓷器皿:中间有三只一模一样的白色茶杯,摆成等边三角形;茶杯右侧放置两只黑碗;最左侧的黑碗里放着一个红苹果;最右侧的黑碗上放着一把空木勺,勺柄朝向画面的左上方。否定要求:不得出现咖啡杯、金属器具、盘子、玻璃器皿。柔和的漫射窗光从左上方射入,时间为午后。写实摄影风格,无造型道具。
这是特意设计的对抗性测试。对于所有当前的扩散模型架构而言,计数、空间语言(如“在……右侧”、“最左侧”)和否定从句都是已知的失败点。
评分检查表
| # | 标准 | 检查点 |
|---|---|---|
| 1 | 总物体数 | 严格 7 件陶瓷 |
| 2 | 三只白茶杯 | 等边三角形排列 |
| 3 | 两只黑碗 | 位于茶杯右侧 |
| 4 | 红苹果 | 位于最左侧黑碗内 |
| 5 | 木勺 | 位于最右侧碗上,柄朝左上方 |
| 6 | 否定合规性 | 无咖啡杯/金属/盘子/玻璃 |
| 7 | 光源 | 左上方柔和光,阴影一致 |
| 8 | 摄影风格 | 无造型陈词滥调(棕榈叶、蜡烛等) |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 的物体计数:目视可见 5 只茶杯(而非 3 只),呈簇状而非等边三角形排列。两只黑碗存在,红苹果正确地放在其中一个碗里。木勺存在并置于最右侧碗上,勺柄方向大致朝向左上方 —— 该标准通过。否定合规性良好:没有咖啡杯、金属制品、盘子或玻璃器皿。左上方光源及一致的阴影表现通过。无造型道具。
GPT Image 2 在空间组件的指令遵循方面表现更强,尽管两个模型均未同时满足所有 7 个物体的计数与摆放限制。
类 2 · 照片级解剖与光影 (T2I)
提示词:
一位三十出头东亚女性的特写肖像,右手拿着一个半满的水晶红酒杯,五指和拇指完全可见,自然地包裹在杯颈和杯肚周围。她坐在朝西的高窗旁,正值黄金时刻。午后的阳光穿过红酒,在她的左颧骨和下颌线上投射出温暖的深红色焦散光斑。她的左手放在腿上的一本精装书上。双眼可见窗户的眼神光。皮肤展现出超细节的毛孔、细微的绒毛,耳垂和鼻梁上有次表面散射。头发背光,有轮廓光。85mm 镜头,f/2.0,浅景深,照片级写实。
这是生成模型在单张图像中公认最难的测试。
评分检查表
| # | 标准 | 检查点 |
|---|---|---|
| 1 | 手部解剖 | 5 根手指+拇指,自然抓握 |
| 2 | 焦散光 | 温暖的红酒光斑投影 |
| 3 | 眼神光一致性 | 双眼位置和形状一致 |
| 4 | 次表面散射 (SSS) | 背光时耳垂和鼻梁可见 |
| 5 | 轮廓光物理规律 | 方向与光源匹配 |
| 6 | 皮肤真实感 | 无“AI 塑料感”磨皮;可见毛孔和绒毛 |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 在其核心优势上表现出色。手部解剖结构正确——手指数量准确,抓握姿势自然,手腕角度在物理上合理。仅这一点就达到了许多模型无法企及的高度。皮肤纹理呈现出真实的毛孔级细节,可见细微绒毛,没有塑料般的过度平滑;鼻梁和颧骨上的次表面散射产生了温暖、透光的质感,看起来非常逼真。头发上的轮廓光与窗口光源的方向一致。
然而,焦散光的渲染是 Grok 的弱点。面部的红色光斑看起来更像是过大的、高度风格化的红色叠加层,而不是阳光穿过酒杯后自然产生的细小、边缘柔和的光丝。焦散的物理真实性未达精度标准。
GPT Image 2 的优缺点正好相反。其焦散光渲染在物理上明显更准确——颧骨上的温暖红色光斑更小、更弥散,且符合阳光穿过酒杯时的空间几何规律,这是 Grok 错过的细节。但在其他方面,GPT Image 2 表现稍逊:手部解剖结构略显生硬,手指环绕杯颈的角度表现出轻微的僵硬感。皮肤纹理趋向于 AI 肖像常见的平滑质感,与 Grok 相比,次表面散射带来的温暖感较弱,轮廓光强度也较弱。
类 3 · 多语言海报 (T2I)
提示词:
一张 1960 年代复古风格的虚构电影节海报,采用中世纪商业设计风格。海报顶部为大字号粗体衬线中文“时光电影节”(第 1 行),下方是较小的中文“第七届 · 上海 · 1965年5月”(第 2 行)。
中心:一幅风格化的旧式电影放映机插图,光束投射在略微弯曲的银幕上。
中下方:一个高脚香槟杯,英文“GRAND OPENING NIGHT”沿杯身曲率缠绕,符合椭圆透视。
右边缘:垂直文本“presented by 时代影业 · TIMES PICTURES”,自上而下阅读。
底部长条:一行小型英文演职员表“music · HUANG ZHAN / cinematography · GU CHANGWEI / poster design · ZHANG GUANGYU”。
配色方案:奶油色背景、深绯红色、芥末黄点缀。轻微的陈旧纸张质感,细腻的颗粒感。
评分检查表
| # | 标准 | 检查点 |
|---|---|---|
| 1 | 中文准确性 | 无笔画缺失,无乱码 |
| 2 | 双语布局 | 中英文不混杂,区域正确 |
| 3 | 杯身弯曲文字 | 英文符合椭圆透视 |
| 4 | 右侧垂直文字 | 可自上而下阅读 |
| 5 | 排版层级 | 标题与副标题区分明显 |
| 6 | 风格与可读性 | 保持 1960 年代美学,不牺牲清晰度 |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 制作的海报视觉效果引人注目,具有浓厚的中世纪插图感。但它未能通过最关键的文本标准:标题显示为繁体“時光電影節”,而不是提示词中要求的简体“时光电影节”。这是字符集合规性失败,对于任何本地化或出版用途来说,这是一个重要的区分。第二行同样使用了繁体字。结构上,“GRAND OPENING NIGHT”出现在香槟杯上且有部分弧度,但对椭圆透视的遵循程度仅为近似。右边缘垂直文字“TIMES PICTURES”清晰易读。底部演职员表存在且清晰。配色方案执行到位,但繁简错误是硬伤。
GPT Image 2 顺利通过了字符集测试:标题“时光电影节”和副标题“第七届 · 上海 · 1965年5月”均以简体中文正确呈现,无笔画缺失或乱码——这是优于 Grok 的直接合规性胜出。香槟杯位于中下方,文字准确地贴合了杯身曲率。右侧垂直文字“时代影业 · TIMES PICTURES”自上而下排列,清晰可见,中英文在同一垂直列中,没有混杂错误。底部演职员表清晰。标题、副标题和注脚之间的排版层级保持得非常清晰。纸张质感和配色方案实现得很好。构图巧妙地将上海天际线剪影作为中心插图,虽然提示词未要求,但它增加了背景真实感且未破坏任何指标。
类 4 · 几何变换 (I2I)
要求模型将一位全身时尚样图的主体向其左侧旋转 45°,同时保持相机位置不变。参考图具有复杂的叠穿服装:棕色长外套、皮革肩披、带有渐变(深棕→银→奶油色)的皮草围巾、中间有嵌入肖像的圆形铜制胸章、黑色皮手套和双色皮靴。这些细节未列入提示词,模型必须仅依靠对身份的理解来保留它们。
这是一个有意的能力压力测试。指令特意简短,以避免将评分标准直接喂给模型。
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok 保持了面部身份一致性,达到了全身图所需的 ArcFace 0.5 阈值。皮草围巾之前隐藏的右侧部分在 45° 旋转后部分可见,渐变连续性合理。胸章轮廓得到保留,但嵌入的肖像细节出现了压缩。
GPT Image 2 在服装层次的连贯性上表现稍强,但带来了更多的面部身份漂移——根据使用场景,这是一个需要权衡的地方。
类 5 · 局部编辑与区域保留 (I2I)
要求对客厅场景进行三处编辑:移除沙发上的一只睡猫(并自然修复垫子)、将一杯热茶换成一杯带冰的橙汁、在咖啡桌中间的书上加一副折叠的黑色框架阅读眼镜。指令明确禁止更改其他任何内容——沙发花纹、书籍位置、灯具、窗外景色、墙色、地板。
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 完成了全部三处编辑。猫被移除,沙发垫恢复得很干净,没有可见的凹陷或毛发残留——编辑区域的花纹保持良好。但橙汁杯的受光模式与环境不符,看起来像是一个独立的光影模型合成的,而非融入场景。杯底与深色桌面间的接触阴影不足,产生了一种微妙的“悬浮感”。
GPT Image 2 也完成了三项编辑,且表现出更强的整体场景保留能力。猫的移除干净利落。橙汁杯的渲染效果更好,杯底位置和阴影方向与右侧窗户光源完全匹配。阅读眼镜被清晰地放在书堆上。最关键的是,窗外景色被完整保留——城市远景保持模糊且一致,而 Grok 在这一点上失败了。沙发花纹、灯具、墙面和地板均完好。一个微小的变化:整体场景亮度略有增加,对比度略有改变,表明存在一定的全局光照重新解释,而非完全的像素级保留——这是一个微小但可察觉的偏差。
类 6 · 多参考图融合 (I2I)
提示词结合了三个独立参考要素:人物身份(拉丁裔女性,琥珀色眼睛,深棕色波浪卷发)、水彩插画风格(日本乡村景观,可见笔触,温暖的童话氛围)、场景布局(日落时的欧洲鹅卵石广场,铸铁路灯,石拱门)。任务:生成一张由该人物站在场景中的连贯水彩画——而不是带滤镜的照片,也不是拼贴画。
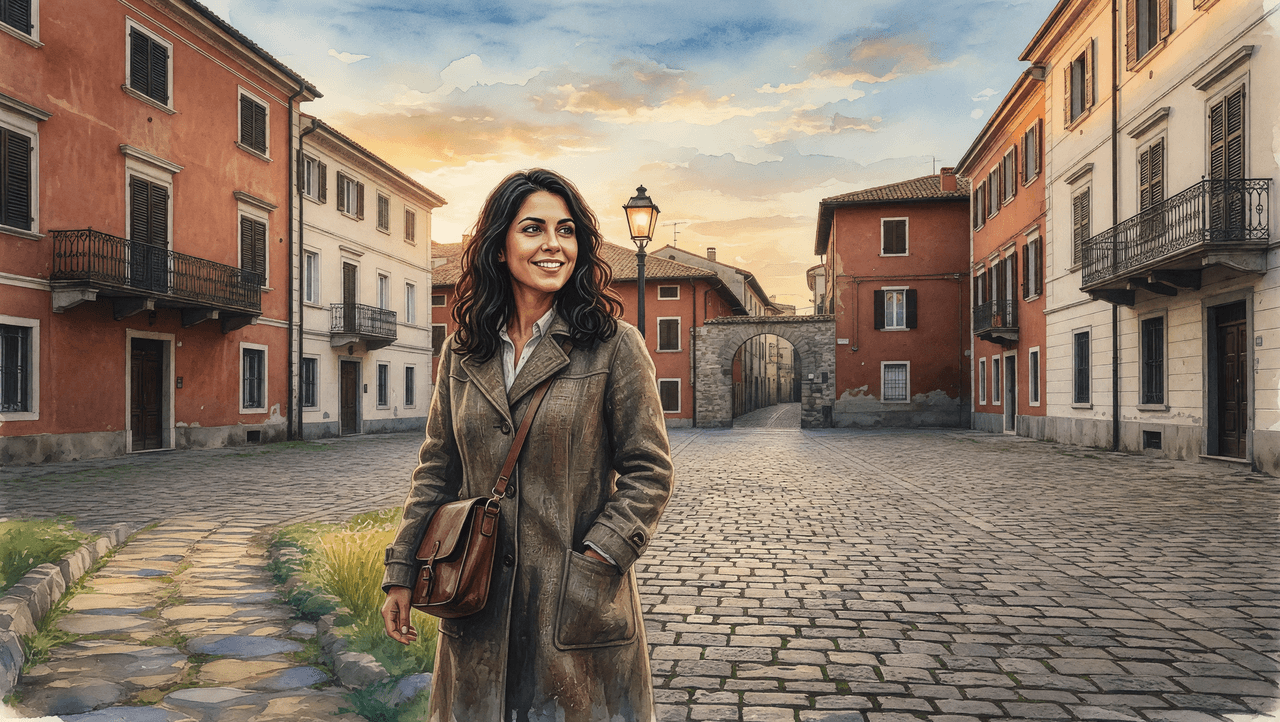 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine 没能通过核心标准:输出是照片级写实的,而非水彩画。鹅卵石广场和人物保留了完全的摄影锐度,仅覆盖了一层淡淡的笔触质感,没有参考图 2 中定义的笔触、色彩渗出或手绘边缘质量。场景结构、身份、服装和光照方向都通过了。但渲染了完全错误的媒介,是该类别下的彻底失分。
GPT Image 2 在整个画面中实现了真正的水彩渲染——建筑、鹅卵石、天空和人物都带有可见的笔触和柔和的色彩渗出,与参考图 2 一致。场景结构完整,路灯亮起,石拱门可见。身份通过风格转换得到了部分保留——波浪黑发和面部结构可辨。这是唯一完成任务的输出。
通过 Atlas Cloud 使用 Grok Imagine Image 和 GPT Image 2 模型
该基准测试是可复现的。Grok Imagine 和 GPT Image 2 现已通过 Atlas Cloud 提供——无需逐个模型配置计费,无需排队。
为什么选择 Atlas Cloud
- 一个 API 密钥,300+ 模型。 只需更改一个模型字段,即可在 Grok、GPT Image 2、Flux、Wan、Seedream 及库中其他所有模型之间切换。无论是运行六模型基准测试还是构建生产级图像管线,使用相同的密钥、终端和计费控制台。
- 全模态覆盖。 大语言模型、文生图、图生图、文生视频、图生视频——一站式满足。
- 无冷启动,无速率限制。 Atlas Cloud 运行在专为高吞吐量优化的推理基础设施上。无论是单次调用还是成千上万次,您都能获得一致的延迟表现。
- 专为对比工作流构建。 本基准测试所展示的——在多个模型间运行相同提示词并对比输出——正是 Atlas Cloud 架构设计的核心场景。一个密钥,一份账单,全面的模型广度。






