
多年来,创作者们一直从事着一项非常枯燥的工作:他们必须先制作静音视频,然后再花数小时去后期添加声音。这通常会导致严重的同步问题——人物嘴巴动了,但声音却慢了一拍。这种不协调感显得虚假且生硬,让观众很难专注于视频内容。
Vidu Q3 通过内置音频的 AI 视频生成技术解决了这些老问题。与其他工具不同,它能一次性生成包含音视频的 16 秒片段。这种智能方法确保了每一个字都能与人物的唇形完美匹配,同时也保证了画面中的每一次碰撞或点击声都能与动作精准同步。
**2026 年 AI 唇形同步(AI lip-sync 2026)**标准现在优先考虑“单次生成(One-Pass)”,以降低延迟并提高真实感。通过将对话和背景音乐直接集成到生成过程中,Vidu Q3 消除了语音不同步带来的“恐怖谷”效应,显著提升了社交媒体和营销内容的观众留存率。
Vidu Q3 的“原生音频”有何不同?
与传统先生成视觉画面再“叠加”声音的模型不同,Vidu Q3 采用了单次生成架构。这意味着模型可以同步合成:
- 音效 (SFX): 如脚步声或落叶声等环境音。
- 背景音乐 (BGM): 贴合场景情感走向的背景音乐。
- 对话: 精准定时的语音模式。
通过同时生成这些元素,物理动作与声音之间的时间差在数学上被锁定,消除了后期音频带来的“恐怖谷”效应。
16 秒的里程碑
Vidu Q3 现在支持长达 16 秒的视频片段。这个时长是一个极佳的平衡点,主要原因如下:
- 社交媒体广告: 提供了足够的时间来吸引注意力、阐述价值并添加行动号召 (CTA)。
- 叙事流畅度: 这一长度允许 AI 唇形同步在自然停顿处进行调整,使 2026 年的视频项目看起来平滑自然,而非断断续续。
性能对比
为了了解 Vidu Q3 在同类产品中的表现,我们考察了视听延迟——即视觉动作与其对应声音之间的延迟。
| 功能 | Vidu Q3 (首选) | Kling 2.6 | Veo 3.1 |
| 同步架构 | 原生单次生成 (统一) | 原生单次生成 | 原生单次生成 |
| 最大时长 | 16 秒 (行业领先) | 10 秒 | 8 秒 |
| 长文本对齐 | 卓越 (100+ 字符) | 一般 (易漂移) | 高 (偏向视觉) |
| 物理音效保真度 | 高 (基于材质) | 平衡 | 氛围感 |
| 镜头间连续性 | 无缝音频切换 | 基础 | 高级 |
| 延迟 / 音频漂移 | < 30ms | < 15ms | ~10ms |
虽然竞争对手的延迟可能略低,但 Vidu 是唯一能提供完整 16 秒创作空间的模型。它生成同步环境的能力使其成为追求电影级真实感、又不想处理手动对齐技术难题的创作者的首选。
实现完美音频的“导演提示词”公式
要达到 2026 年高保真 AI 唇形同步标准,仅靠简单的描述是不够的。为了充分利用 原生音频 AI 视频,创作者必须在单个提示词中架起视觉动作与听觉反应之间的桥梁。
单次生成中的“主体-音频桥接”掌握
在 Vidu Q3 中,“主体-音频桥接”是一种将特定声音锚定到视觉线索的技术。由于模型采用“单次生成”,它会寻找语义链接——在提示词中对齐 原生音频 AI 视频 数据。例如,如果你描述“玻璃破碎”,该桥接会触发特定的工作流:
- 时间精度: AI 识别撞击的确切帧。
- 声学映射: 它准备一个高频音频峰值(“叮”或“哗啦”声)以占据该特定时间戳。
- 环境背景: 它根据视觉场景是小房间还是大厅来调整混响。
这种集成方法与模块化 AI 系统相比,显著降低了漂移。
提示词配方:三层结构法
为了确保模型捕捉到场景的每一层,请遵循以下结构层级:
[视觉描述] + [运镜方式] + [音频层:对话/音效/背景音乐]
提示词组件拆解
| 组件 | 功能 | 示例 |
| 视觉描述 | 定义主体、纹理和动作 | 一位铁匠正在敲打烧红的铁剑 |
| 运镜方式 | 设置视角和深度 | 极度特写,火花飞向镜头 |
| 音频层 | 指定声音类型和强度 | 音效:清脆的金属撞击声,嘶嘶的蒸汽声 |
案例研究:高同步执行
让我们拆解一个旨在实现最大同步效果的提示词:
这是我的参考图:

这是我的视频提示词:

接下来,让我们看看视频生成结果:
视频信息:1080p, H264, Flash
- 在 Flash 模式下,基于音素的唇形同步依然如此精确,这非常了不起。通常,“快速”或“轻量”模型为了节省计算时间会牺牲微表情。然而,“Loved”和“Real”等词的对齐依然稳定,证明了 Vidu Q3 的原生音频架构即使在剥离了高端迭代采样后依然稳健。
- H.264 是一种有损格式,通常难以捕捉雨水或胶片颗粒等微小细节。它经常在黑暗、颗粒感强的区域留下“宏块”或难看的像素方块。尽管有这些限制,但“明暗对照法”的灯光效果依然出色。阴影保持锐利,没有变成浑浊的模糊一片,这显示了模型在处理调色方面的功力。
- 背景中的湿润纹理和锐利的雨水是受压缩影响最明显的地方。如果使用 ProRes 或更高码率的 Pro/高分辨率输出,这些细节会清晰得多。
免费计划非常适合简单的项目或尝鲜。但如果你想要真正的电影质感——通过高码率和清晰画质克服“恐怖谷”效应,你应该将工作转移到 Atlas Cloud。
通过使用 Atlas Cloud 上的 Vidu Q3 Turbo,你可以绕过本地计算瓶颈,生成无水印、高保真的内容,保留每一个微小细节。
完美唇形同步的专业秘籍:“精通”章节

在 2026 年 AI 唇形同步中实现电影级真实感,需要的不仅仅是好的提示词,还需要对引擎如何解读人类语音有技术层面的理解。通过优化脚本和视觉环境,你可以最大限度地提高 原生音频 AI 视频 生成的精度。
音素优先脚本
锁定 Vidu Q3 追踪引擎的秘诀在于音素。具体来说,让你的句子以“爆破音”开头——即通过阻断气流产生的音,如 M、B 和 P。这些声音需要清晰可见的唇部闭合。当模型在序列开头检测到爆破音时,它会为嘴部几何结构建立一个高置信度的锚点,从而显著降低初始“含糊不清”或帧对齐错误的几率。
5-9 词规则
为了保持一致性,专业创作者遵循 5-9 词规则。虽然 Vidu Q3 支持更长的持续时间,但“AI 漂移”(即嘴部动作随时间逐渐与音频失去同步)往往会在长且不间断的对话串中增加。将语音拆分为 5 到 9 个词的片段,可以让模型在每个自然停顿处“重置”其追踪参数。
| 功能 | 片段长度 | 结果 |
| 理想 | 5-9 个词 | 帧级完美对齐和自然的节奏。 |
| 次优 | 15+ 个词 | 增加“漂移”或唇边模糊的风险。 |
视觉清晰度与灯光
唇形同步引擎需要清晰、无遮挡的下半脸视图,以便将音素映射到像素。为确保高保真追踪:
- 避免遮挡: 确保手、麦克风或散落的头发不会遮挡嘴部区域,因为这些“视觉噪声”元素会干扰潜在空间映射。
- 高对比度灯光: 确保下巴和嘴唇轮廓分明。平淡的灯光会导致 AI 在处理嘴部内部深度时遇到困难。
多语言节奏:英语 vs. 普通话
Vidu Q3 对不同的语音节奏使用不同的逻辑。英语遵循重音计时,因此引擎专注于宽阔的元音形状。普通话是音节计时且带有声调,需要更快、更精确的唇部动作。为了获得自然的普通话语音,请使用能保持“头部位置稳定”的提示词。这有助于引擎更好地专注于那些细微、快速的嘴部调整。
遵循这些视觉和布局规则,可以让你的视频和音频在整个 16 秒片段中保持稳定。
多镜头叙事与音频设计
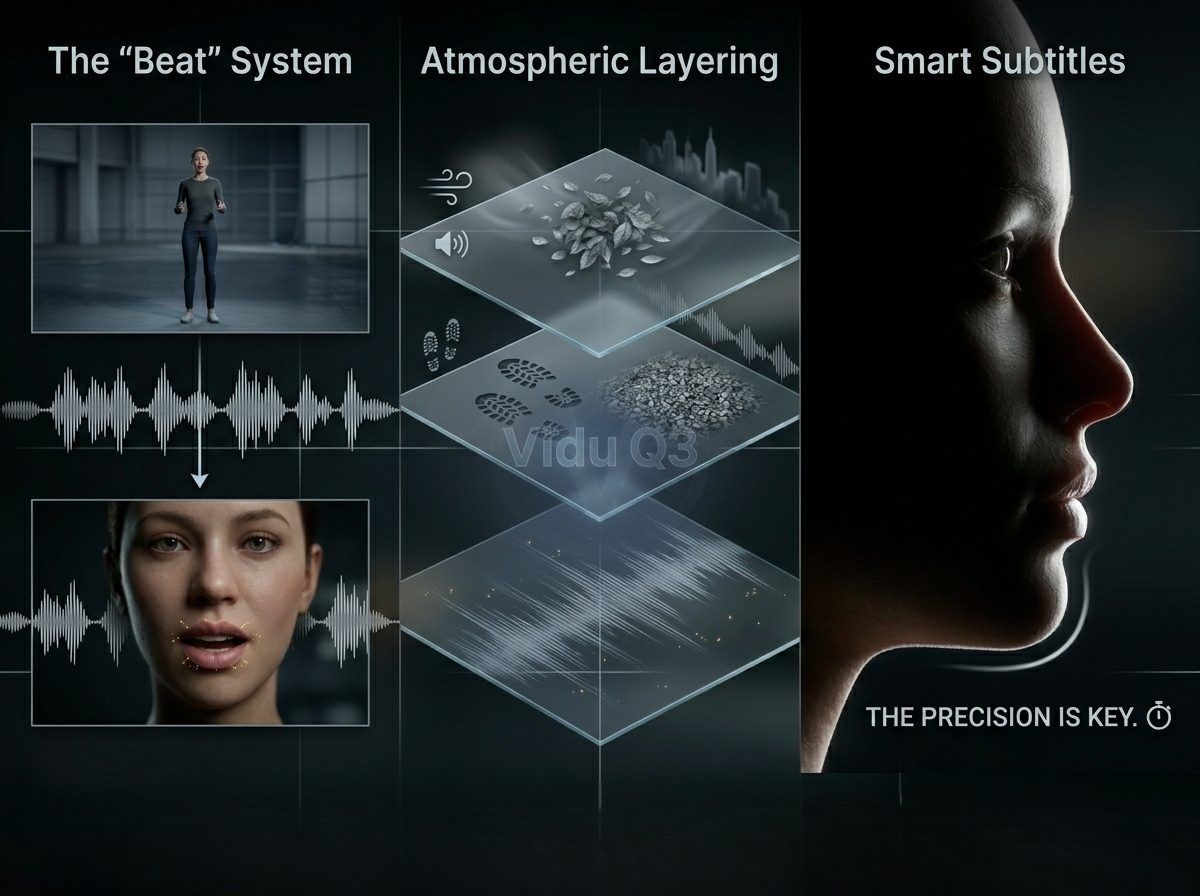
保持故事在不同角度间流畅推进是专业创作者的标志。Vidu Q3 通过智能多镜头工具让这一切变得简单。这些功能即使在摄像机视角切换时,也能让你的 AI 视频和音频保持完美同步。
“节拍”系统:编排音频连续性
Vidu Q3 引入了“节拍 (Beat)”系统,允许用户在不中断音频流的情况下定义特定的镜头切换。通过编写“节拍”脚本,你可以指挥从广角建立镜头到紧凑特写的切换,同时对话或背景音乐 (BGM) 无缝持续。这种连续性避免了模块化 AI 工具中常见的刺耳“音频重置”。
管理多镜头切换:
| 镜头类型 | 目的 | 音频表现 |
| 广角镜头 | 建立环境 | 高混响,强调环境音 |
| 中景镜头 | 聚焦动作 | 平衡对话和音效 |
| 特写镜头 | 增强情感 | 干声,优先唇形同步 |
氛围分层:让视觉落地
为了让 AI 生成的画面具有真实感,创作者必须超越对话,融入“纹理”。氛围分层涉及提示生成与环境互动的次级和三级声音。
- 环境纹理: 指定风吹过树木的声音或远处城市的嗡嗡声。
- 物理纹理: 包括“丝绸的摩擦声”或脚步下“碎石的嘎吱声”。
- 声学深度: Vidu Q3 的单次生成会计算主体与摄像机的距离,自动调整这些声音的音量和“空气感”,以匹配视觉深度。
智能字幕:精准文本同步
自动视频制作中的一个大问题是字幕与语音不匹配。Vidu Q3 通过直接从生成的对话轨道触发其内部文本渲染引擎来解决这个问题。由于文本与 原生音频 AI 视频 在同一通道中渲染,时间精度达到帧级。这确保了观众的眼睛和耳朵在同一毫秒接收到相同的信息,这是 2026 年 AI 唇形同步高可访问性标准的必要条件。
利用这些集成功能可将后期制作时间缩短约 60%,从而实现保持电影级质量的“直接发布到社交媒体”工作流。
常见陷阱及解决方法
创作者在首次使用 Vidu Q3 时经常会遇到技术摩擦。实现完美的 原生音频 AI 视频 需要排查文本提示词与声学输出之间微妙的相互作用。
问题:嘴巴在动,但发出的声音听不清
这是一个常见障碍,视觉上的唇形同步看起来很活跃,但发声却无法辨认。
- 解决方法:转录文本清理。 Vidu Q3 引擎对对话块的格式高度敏感。确保你的转录文本中没有非语言填充词(如“嗯”或“啊”),除非它们是特定角色特征所必需的。使用标准标点符号来提示 AI 何时停顿换气,这会重置唇形追踪的对齐。
问题:声音太大或有杂音
当视频的能量与设定的音量水平不匹配时,会出现噪音破裂和失真。
-
解决方法:调整情感关键词。 不要仅仅在提示词中增加“音量”(AI 可能会将其解释为增益提升),而应使用描述性的发声风格。
- 低强度: 使用“低声耳语”或“喃喃自语”来降低峰值水平。
- 高强度: 使用“大声喊叫”或“响亮的宣告”来确保 AI 平衡音频余量。
问题:音乐与情绪不符
由于 Vidu Q3 在生成视频的同时生成 BGM,像“快乐的音乐”这样通用的提示词往往会导致音调不协调。
- 解决方法:BPM 和流派特定的锚点。 把 AI 当作作曲家对待。提供特定的节奏 (BPM) 或子流派有助于模型将 BGM 锚定到视觉帧率上。
故障排除快速参考表
| 症状 | 主要原因 | 建议调整 |
| 语音乱码 | 转录文本不干净/俚语 | 使用干净、带标点的文本字符串 |
| 音频削波 | 音调不匹配 | 使用“耳语”或“喊叫”描述符 |
| 情绪漂移 | BGM 提示词模糊 | 添加 BPM(如 120 BPM)或流派(如 Lofi) |
这些微调改变了模型映射声音的方式。它们能确保你的音频水平符合专业广播要求。当你掌握了这些修复方法,你就不再只是在玩弄 AI,而是在制作看起来和听起来都专业的作品。
结论:AI 内容的未来是“全栈式”的
掌握 Vidu Q3 意味着进化为一名“全栈”创作者——一个明白真正沉浸式的 原生音频 AI 视频 是建立在同步像素与声波协同效应之上的创作者。
优先考虑音频架构的创作者在拥挤的数字市场中获得了显著优势。通过利用“单次生成”,你将受益于:
- 缩短制作时间: 无需外部配音工具。
- 提高留存率: 精准的唇形同步和环境纹理带来更高的观众参与度。
- 平台通用性: 内容无需额外母带处理即可直接用于高保真广播。
准备好引领“有声”革命了吗? 在评论区分享你的第一个 Vidu Q3 作品,或者持续关注我们关于高级 Vidu 视频转视频编辑技术的深度解析!
常见问题解答
“单次生成”与传统 AI 视频工作流有何不同?
在传统工作流中,创作者生成静音视觉画面,并使用 ElevenLabs 或 SyncLabs 等第三方工具进行后期配音。单次生成(由 Vidu Q3 和 Veo 3.1 等模型使用)在单个推理周期内合成音频和视频。这种多模态方法确保了环境声音和语音模式在数学上锁定在视觉帧上,根据 2026 年行业基准,将手动“拼接”时间减少了约 60%。
目前哪些 AI 视频模型在原生音频同步方面处于领先地位?
到 2026 年中期,市场分化为两条路径。一些模型专注于高端视觉效果,而另一些则致力于实现逼真的“有声”功能。
| 模型 | 最大时长 | 音频集成 | 最适合 |
| Vidu Q3 | 16 秒 | 原生 (单次生成) | 叙事与社交广告 |
| Kling 3.0 | 15 秒 | 原生 (双语) | 电影级叙事 |
| Veo 3.1 | 8-10 秒 | 原生 (高保真) | 商业品牌内容 |
哪些技术因素会导致 AI “唇形同步漂移”?
“漂移”发生在嘴部几何结构的潜在空间映射随时间与音频信号失去对齐时。关键因素包括:
- 片段长度: 如果角色说话超过 10 秒而没有停顿,嘴部动作就会开始失去追踪。
- 光影: 当下巴和嘴唇上的光线过于平淡时,系统无法清晰地看到嘴部形状。
- 屏幕细节: 720p 制作的视频往往会丢失在清晰的 1080p 视频中才能看到的细微面部动作。
AI 能在没有提示词的情况下创建自然音效吗?
虽然 Vidu Q3 等现代模型利用 声学环境映射 来自动生成环境音(如雨声或脚步声),但专业效果仍然需要“锚定提示词”。通过在提示词中明确定义 [音频层]——指定 BGM 的强度或音效的纹理——你可以引导模型的“声学映射”层,防止音频听起来脱节或平庸。






