AI 视频的真正瓶颈不在于输出效果看起来“不对劲”,而在于它让人感觉“节奏太慢”。
1. 为什么 15 秒的 AI 动作片总是缺乏张力
任何真正深入使用过 Seedance 2.0 的人都遇到过同样的瓶颈:当你要求生成 15 秒的片段时,模型只会给你三四个镜头——仅此而已。
你输入一段格斗场景,出来的结果却是:“角色走入 → 举起武器 → 画面定格”。有铺垫,有动作,结束。演职员表开始滚动。
但这并非格斗在银幕上的真实呈现方式。在拳头击中目标之前,肩膀会先转动。闪避之后,反击动作已经蓄势待发。全景追逐会剪辑到极近的特写,随后再剪辑到慢动作撞击。张力来源于剪辑密度,而不是让单个镜头看起来更精致。
无论你怎么提示,模型本身都不会主动给你十六个镜头。
这就是问题所在。下面是我们解决这一难题的方法。
2. 改变工作流的三个关键转折点
在对单角色动作演示进行完整测试后,我们总结了三个核心点:
① 动作张力来自剪辑密度,而非单镜头质量。 别再执着于追求一个完美的镜头。先将 15 秒内容拆解为 16 格分镜,然后再交给视频模型。
② GPT Image 2 的真正优势在于脚本理解和镜头布局,而非风格统一。 我们最初希望 GPT Image 2 在整个流程中锁定单一风格。经过测试,我们发现从参考图到视频的生成过程会自然向 CG 风格偏移,强行干预无法得到理想结果。但 GPT Image 2 真正擅长的是:阅读脚本、规划镜头、排布 16 格分镜,这是我们库中其他模型无法比拟的。
③ 整个管线运行在同一个 AtlasCloud API Key 下。 GPT Image 2、Nano Banana 2 和 Seedance 2.0 都位于 AtlasCloud 的同一个模型池中。一个 Key,一个端点,一份账单,一个配额。无需对接多家供应商。
3. 单角色压力测试
为了彻底测试 GPT Image 2 的性能,我们挑选了一个最具挑战性的角色。
Ranx —— 一名赛博战术特工。沙金色双丸子头。并且拥有四处完全不对称的装备:
- 仅右腿有黑色过膝袜
- 仅右大腿有红色硬壳枪套
- 仅右膝盖有青色镶边
- 一根厚重的黑色线缆从腰带右后方绕至左小腿
我们仅给模型提供了一张后侧方的参考图。模型必须逆向推导出正面、侧面、表情和武器细节,且不能镜像翻转上述任何一个不对称细节。
结果: 一次生成。六个姿态转面、四个头部特写、四种表情、武器细节、手部、脚部——全部在一张图上呈现。四个不对称点全部锁定。零镜像翻转。


我们将其环境设定为成型的设计参考(赛博朋克潮湿小巷,类似《Stray》的美学风格):

4. A/B 测试证明该方法的有效性
这是整个工作流赖以生存的实验:相同的脚本、相同的角色表、相同的场景参考。唯一的变量是是否存在分镜稿。
对照组:仅使用文字提示,无分镜稿
输入给 Seedance 2.0 参考图转视频功能:
- 1× 角色表
- 1× 场景参考
- 详细的 15 秒文字提示,描述了四次硬切
片段清晰且工艺精良,但整个视频只有约 3 个缓慢的节拍——走入巷子、举起武器、定格。这看起来像是一段角色演示,而不是格斗。
测试组:使用 16 格分镜稿
我们要求 GPT Image 2 将相同的脚本拆解为 4×4 = 16 格的分镜稿,每一格都标注了:
- 镜头编号 (① ② ③ … ⑯)
- 镜头景别 (WIDE / MS / CU / ECU)
- 运镜方向 (→ ↘ ↙ ↑ ↓ ↗)
- 节奏标记 ("静止起幅" / "硬切" / "冲击" / "致命一击" / "淡出")
- 手写中文导演备注——这纯粹是出于密度考虑,中文能在小分镜格中承载更多导演意图(GPT Image 2 和 Seedance 2.0 对中英文的理解能力同样出色)
随后将提示词输入 Seedance 2.0 的参考图转视频模型:
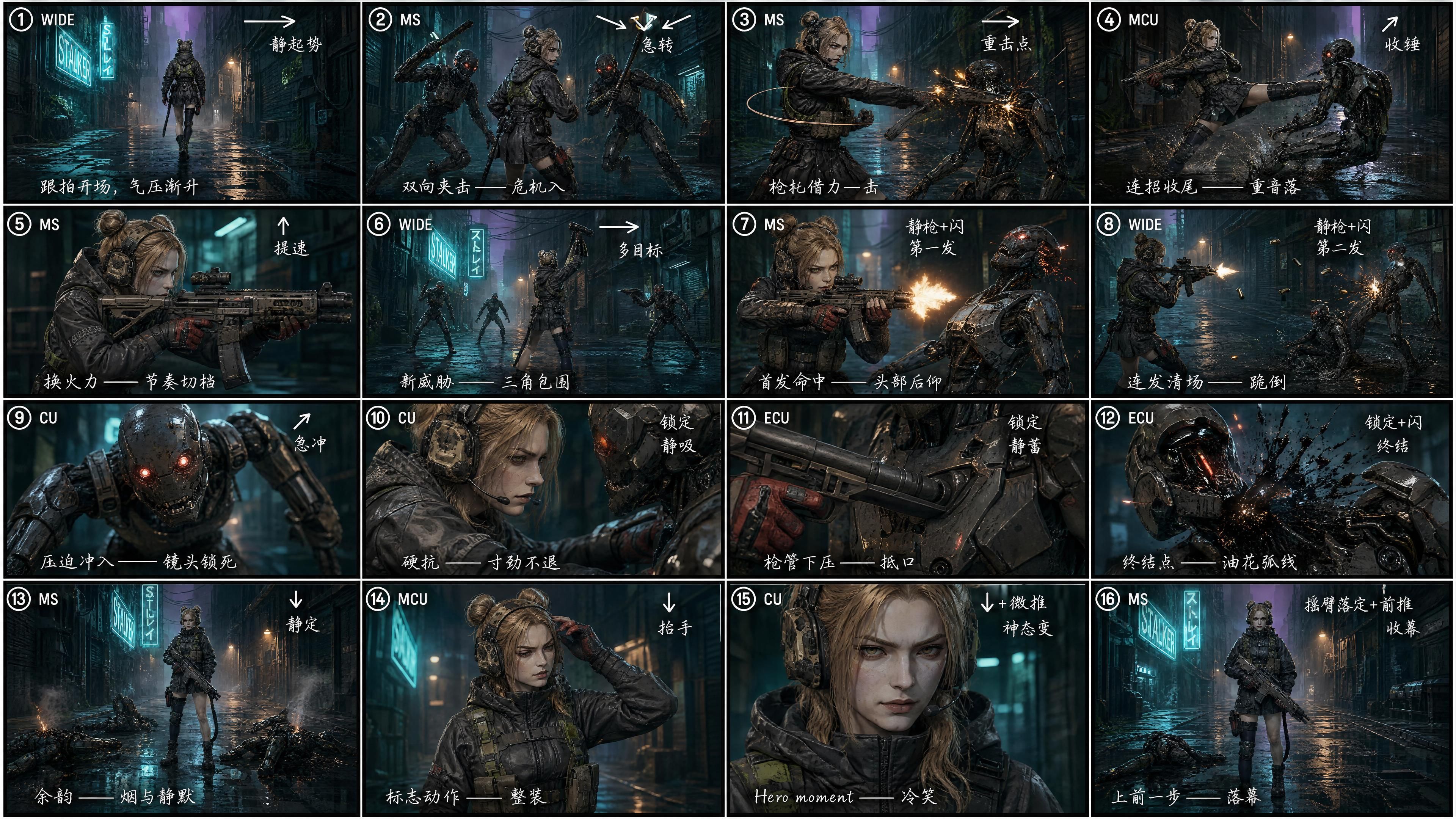
"生成一个严格遵循参考图 3 分镜结构的视频。具有强烈的电影感和镜头语言,动态夸张,动作打击感强。"
无需测量,差异显而易见。剪辑密度提升了约 4 倍。 从全景追逐到中景肩托拍摄,再到极近的枪口特写,最后以英雄姿态结尾——15 秒内塞满了内容。相同的脚本,不同的节奏。第一个版本看起来像演示,第二个版本看起来像预告片。
这就是本工作流的核心论点:GPT Image 2 不是为了锁定风格,而是为了将脚本拆解为高密度的镜头序列。
5. 规模化扩展:双人对决
在单人版本流程完善后,我们扩展到了双人对决。双人格斗最难的部分在于同时锁定四样东西——角色 A、角色 B、环境以及动作节奏。
我们没有生成四张不同的图片再尝试拼接,而是要求 GPT Image 2 在一张图片内处理所有四项内容:
- 角色 A (A-27):Ranx 的微调版本——沙金色马尾辫战术特工,身着短款作战外套
- 角色 B:原创男性雇佣兵设计——黑红长外套,扎发,腰挂阔剑
- 环境:一座名为“灰烬之城”的工业废土要塞——琥珀色黄昏光影,远处的熔炉辉光,烟雾缭绕
- 十个手绘动作节点:试探 → 冲刺 → 格挡 → 闪避 → 勾拳 → 反击 → 压制 → 膝撞 → 贴身 → 倒地

需要强调的是:仅角色 A 使用了参考图(即之前的 Ranx)。角色 B、整个环境以及所有十个动作节点,都是由 GPT Image 2 自行设计的。我们描述了氛围,它完成了其余工作。
风格、双方身份、环境和十个动作节点,全部在单次生成中锁定。图像之间没有漂移,中途也没有出现角色服装的变换。
随后直接导入 Seedance 2.0 的参考图转视频功能:
以平台地板上的两个阵营徽记为锚点的屋顶对峙、中段缠斗以及终结投掷——十五秒的双人动作编排一次性完成。
6. 为什么这个管线仅需一个 API Key
过去,实现“角色 → 场景 → 分镜 → 视频”这条链路意味着要在多家供应商之间反复切换 API Key、SDK、文档、计费和速率限制。你懂的。
而在 AtlasCloud 上,所有这一切都整合在一个端点之下:
| 步骤 | 模型 | 平台 |
|---|---|---|
| 角色表 | GPT Image 2 | AtlasCloud |
| 场景概念 | Nano Banana 2 | AtlasCloud |
| 分镜稿 | GPT Image 2 | AtlasCloud |
| 视频 | Seedance 2.0 | AtlasCloud |
一个 Key。一个端点。一个配额。一份账单。集成和运营开销降至几乎为零。
7. 结语:别再强求跨模型风格统一,发挥每个模型的特长
我们曾投入大量精力试图在链路的每一步都锁定单一风格。但在“参考图转视频”模式下,这场仗是赢不了的——你提示得越强硬,输出质量就越差。
一旦放弃了这个念头,工作流就豁然开朗了。让每个模型发挥它真正的长处。
- GPT Image 2 — 拆解脚本,排布镜头
- Seedance 2.0 — 展开时间,渲染动作
- AtlasCloud — 一个 Key,一条链路
如果你正在使用 AI 制作动作短片、格斗场景或双人对决编排,这就是我们推荐的工作流程。
立即体验
所有模型均在同一个 AtlasCloud 模型池中——一个 API Key 即可运行整个链路:
- Seedance 2.0 (参考图转视频) → atlascloud.ai/collections/seedance2
- GPT Image 2 (角色表 + 分镜稿) → atlascloud.ai/collections/gpt-image-2
- Nano Banana 2 (场景概念) → atlascloud.ai/collections/nanobanana-2
完整的操作步骤及本文使用的所有提示词均已随 YouTube 视频教程一并发布。
去创作属于你的作品吧。






