
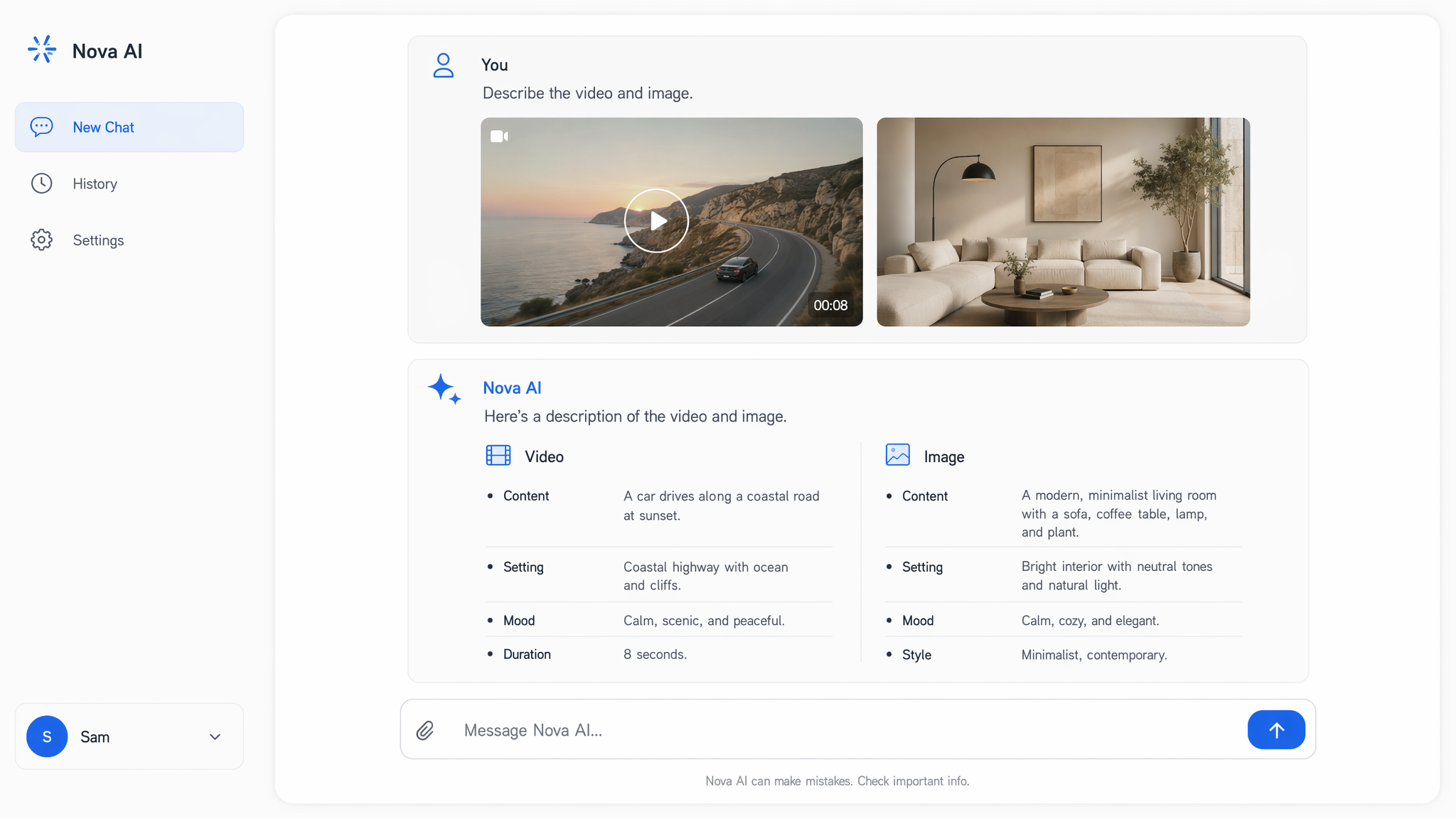
Kimi API for Vision-to-Code Generation
Kimi API 是 Moonshot AI 的开放权重 K2 系列,涵盖原生多模态的 K2.5 以及专为代码场景优化的 K2.7 Code。由于视觉能力内置于模型中,你可以将截图、UI mockup 和短视频转化为可运行的前端代码,协调最多 100 个并行 sub-agent,并在 256K token 上下文中进行推理。Atlas Cloud 通过一个统一 endpoint 提供整个系列,并采用透明的 pay-as-you-go 定价。立即开始构建。
探索领先模型
Atlas Cloud 为您提供最新的行业领先创意模型。
为你的工作负载匹配合适的 Kimi API 模型
一目了然地比较每个 Kimi endpoint 的侧重点和标准百万 token 定价。
| 模态 | 描述 |
|---|---|
| Kimi K2.7 Code API(文本到文本) | 该 endpoint 专为工程工作打造,可将自然语言提示和现有源文件转化为可运行的代码、修复方案和开发者自动化流程。它面向编程、调试和 AI 开发者工作流,适合以可靠代码生成为优先目标的场景;标准计费为每百万输入 token $0.95、每百万输出 token $4。 |
| Kimi K2.6 API(文本到文本) | 输入文本提示后,Kimi K2.6 可在日常生产力任务中返回经过推理的答案、代码和结构化输出。它同时强化了推理和编码能力,适合希望用一个通用模型完成分析、撰写和软件开发的团队;重复上下文的 cached input 价格为每百万 token $0.16。 |
| Kimi K2.5 API(文本到文本) | 当任务涉及长文档或多步骤流水线时,Kimi K2.5 可摄取扩展文本输入,并返回连贯且具备上下文感知能力的响应。它面向长上下文理解和智能工作流而构建,采用透明的按量付费定价:每百万输入 token $0.60、每百万输出 token $3,让大规模分析更具成本效益。 |
Kimi API:从 256K 上下文到 300-Agent 集群
Kimi API 将 Moonshot AI 的万亿参数 K2 models 接入到一个 endpoint,将 262,144-token context window 与原生图像和视频输入、自主 agent swarms,以及面向编码、调试和长周期推理调优的专用 models 结合在一起。
原生图像与视频理解
K2.6 在一个原生多模态架构中处理文本、图像和视频,无需外部插件即可接受从 PNG、WebP 到 MP4、MOV 和 WebM 的格式。其 MoonViT vision encoder 可直接读取屏幕录制、设计文件和图表。相比早期 K2.5 处理文本和图像,K2.6 将同一技术栈扩展到完整视频理解,让视觉上下文成为另一种普通输入。

通过 Kimi API 实现自主 Agent Swarms
Kimi API 提供自主 agent swarm,可扩展到 300 个 sub-agents,并在约 4,000 个协调步骤中协同工作。K2.6 不是在单一线程上推理,而是将一个大型目标拆解为并行分支,并编排它们直至完成。每个 sub-agent 承担任务中的一个切片,然后回报到共享计划中。该设计适合长周期自动化,尤其是项目跨越多个相互依赖阶段的场景。
内置编码与调试能力
编码是该系列的核心,Kimi K2.7 Code 专为编程、调试和开发者 agent 工作流打造。在 SWE-Bench Pro 编码基准上,K2.6 达到 58.6,在真实仓库修复任务中略胜多个前沿 models。将任一 model 指向失败的测试套件,它会追踪故障、提出 patch,并持续迭代直到构建变绿。
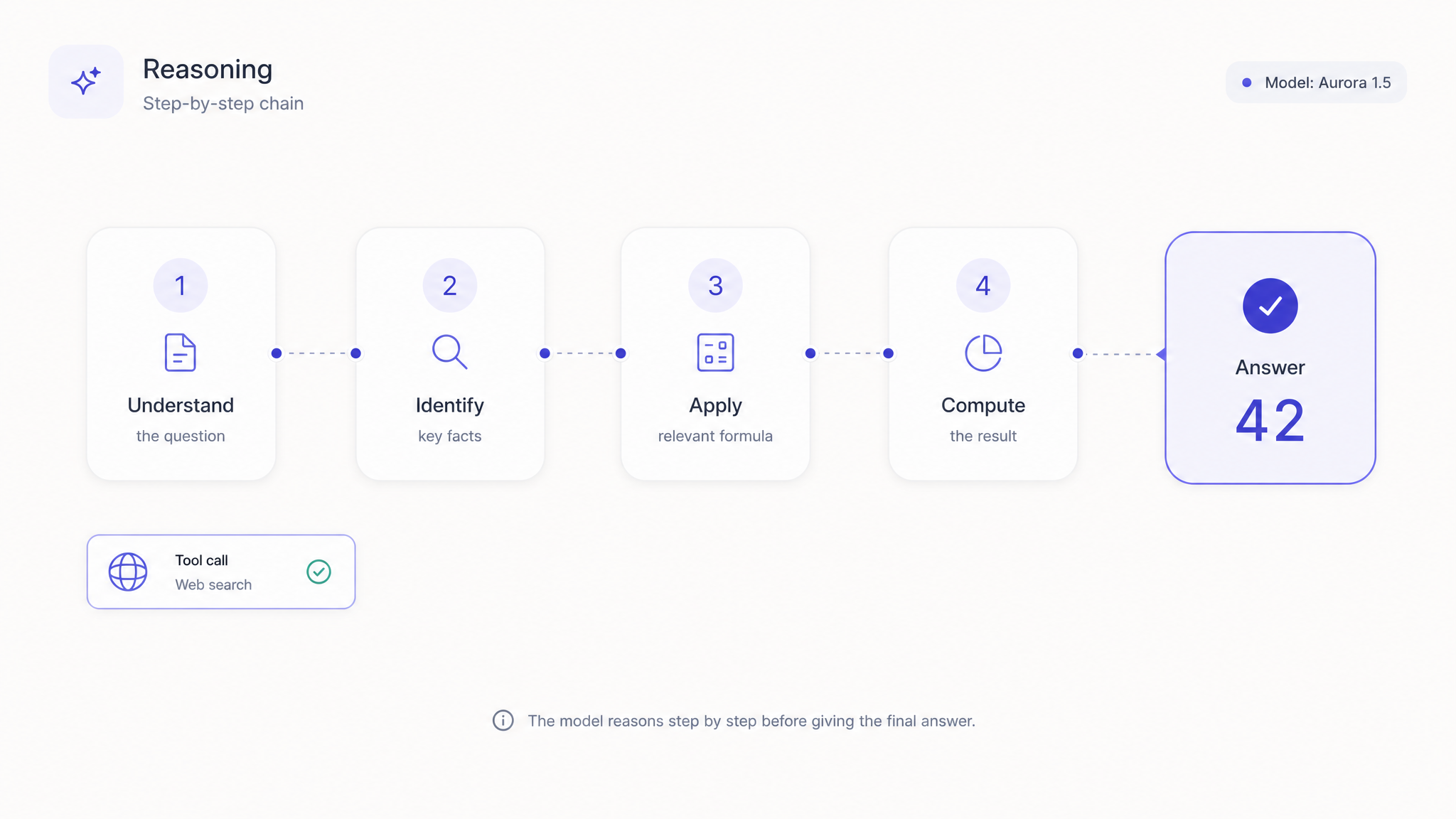
通过一个 Kimi API Key 实现 Agentic Reasoning
需要透明推理?启用可配置的 thinking mode,model 会在给出答案前展示其逐步 chain,并同时支持原生 tool 和 function calling。在 Atlas Cloud 上,整个 Kimi API 都通过一个 OpenAI-compatible key 运行,采用按调用付费定价,并在 Day-0 即可访问每个新版本。只需替换 base URL,现有代码即可继续工作。
Kimi API 对决:一个提示词,三个模型
向 Kimi API 和两个竞品模型发送同一份完全相同的需求简述,然后比较它们各自基于同样指令构建出的交互式 HTML 页面。
构建一个完整的单文件 HTML 页面,实现一款可玩的贪吃蛇街机游戏,所有 CSS 和 JavaScript 均内联,且不依赖任何外部依赖、CDN、图片或字体。在 canvas 上渲染棋盘,采用现代的暗色霓虹配色、平滑移动效果,并在蛇身后方添加柔和的发光拖尾。支持方向键和 WASD 控制,并支持触摸设备上的滑动手势;显示实时分数和持久化最高分;随着分数提升逐步加快游戏速度。每次吃到食物时触发一个小型粒子爆发效果,显示带动画的游戏结束叠层和重新开始按钮,并保持响应式布局,使棋盘在桌面端和移动端都能居中且清晰可读。
Generated with Kimi K2.7 Code on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Generated with Kimi K2.6 on Atlas Cloud
创建一个单一、完全自包含的 HTML 文件(所有 CSS 和 JavaScript 均内联,绝对不使用外部依赖、CDN、图片或 Web 字体),渲染一个交互式“活体数字生态瓶”——一个位于屏幕中央的密封玻璃罐,内部包含一片会实时生长、自我维持的微型雨林。在任何现代浏览器中打开后都必须立即以 60fps 运行,无需构建步骤。 核心场景与布局:将构图对称居中,把玻璃罐作为深色暗角背景上的主舞台(从柔和苔藓光照中心向近黑边缘过渡的径向渐变),让所有注意力都集中在罐体上。所有内容绘制在全窗口 HTML5 Canvas 上,并叠加真实的玻璃拟态 DOM/CSS 装饰层:罐壁必须呈现真实玻璃质感——弯曲折射高光、明亮的镜面边缘轮廓光、淡淡的磨砂模糊,以及带细微透镜效果的散落冷凝水珠——通过分层径向/线性渐变、backdrop-filter blur、半透明白色描边和柔和 box-shadow 实现。罐内底部是深色潮湿壤土,并有一层缓慢漂移的淡淡体积雾气。 必须堆叠并共存的三层技术效果(这正是弱模型与强模型拉开差距的地方——弱模型只会生成静态图片,强模型会让整个罐子活起来): 1. 递归 L-system 生长:藤蔓、蕨叶和苔藓由 L-system / 递归分枝算法生成,并随时间播放展开动画——茎干伸长、枝条细分、蕨叶舒展、叶片以缓动方式缩放出现。生长过程要有机自然,并在每个分枝上略带随机性(角度抖动、粗细渐细、长度衰减),使每次重新加载时没有两株植物看起来完全相同。 2. 粒子系统:数十个琥珀色萤火虫般的光点在雾气中漂移和上下浮动,带有柔和的加色发光和轻微视差;同时包含上升的冷凝/花粉微粒;粒子会对新长出的植物产生细微反应。 3. 昼夜光照循环:连续的环境光循环让自上而下的主光在冷白黎明 → 温暖金色黄昏 → 深靛蓝夜晚之间往复扫过,并相应地重新着色整个场景、玻璃高光、雾气和植物色调。植物表现出向光性——茎干会随着当前光照方向移动而弯曲,并让顶端朝光源倾斜。 主要交互:点击罐壁/内部任意位置,会在点击的 x 坐标处向壤土中投下一颗种子;这颗种子会按顺序播放完整且可见的生命周期——种子落下并停住,萌发成幼芽,幼芽通过 L-system 递归分枝,成熟后开出一朵小小的发光花——每个阶段都使用缓动且清晰可读,并在落地时产生柔和的涟漪/尘埃 puff。多次点击会生成多株共存并持续生长的植物,逐渐把生态瓶填成更浓密的灌丛。包含几个轻量的内联控件,采用玻璃拟态胶囊按钮(例如“Reset terrarium”和“Day/Night: auto ⇄ drag”切换,允许用户拖动调节一天中的时间,另可选暂停)。提供一行淡淡的提示文字(“tap the glass to plant a seed”),在首次交互后淡出。 调色与氛围:森林墨绿色和苔藓黄绿色的叶片,光点与花朵使用琥珀/蜂蜜色光泽,罐体带冷色青绿色玻璃色调,昼夜变化中交替出现暖金色与冷靛蓝色洗光。整体感受应安静、有呼吸感、冥想式——缓慢柔和的运动,没有生硬过渡。 技术要求:使用 requestAnimationFrame 和 delta-time,使动画与帧率无关;让 canvas 能响应窗口大小变化,并使用正确的 devicePixelRatio 缩放,同时保持玻璃罐居中;合理限制粒子/分枝数量,确保运行流畅;所有随机性都要按单株植物设定种子,使生长效果自然。所有内容——几何、发光、玻璃、雾气、光照、粒子和递归植物——都必须通过代码绘制或计算,零外部资源。只交付完整的 HTML 文档,可直接保存为一个 .html 文件并打开。
Generated with Kimi K2.7 Code on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Generated with Kimi K2.6 on Atlas Cloud
让 Kimi API 在你的技术栈中发挥作用
无论你是在庞大代码库中交付代码、将设计稿转换为界面,还是编排智能体集群,Kimi API 都能把长上下文推理和原生工具调用能力带入真实的生产工作负载。

使用 Kimi API 进行仓库级编码
Kimi K2.7 Code 可在 262K-token 窗口内读取整个代码仓库,一次完成重构、调试和代码扩展。团队依靠它来现代化改造遗留系统,并在不丢失项目上下文的情况下交付多文件功能。

将设计转为前端代码
向 Kimi K2.5 提供截图、原型图或简短演示视频,它就能根据视觉输入返回可运行的前端代码。设计师和产品团队可在几分钟内把静态概念转化为交互式页面和原型。

分析长文档和数据
当报告或合同长达数百页时,Kimi 模型可在 256K-token 上下文中处理它们,提炼趋势并发现冲突。分析师无需逐页手动阅读,即可提取带引用的结构化答案。

通过 Kimi API 编排智能体集群
智能体集群可让 Kimi K2.5 将一个目标拆分为最多 100 个并行子智能体,将执行时间最多缩短 4.5x。团队可自动化完成单个模型无法完成的批量分析和长篇构建任务。

驱动会使用工具的自主智能体
Kimi 模型经过智能体式工具使用训练,能够调用外部函数、API 和搜索,在无需逐步提示的情况下完成任务。开发者可以构建代表用户在真实系统中进行预订、查询和执行操作的助手。

几分钟内迁移到 Kimi API
由于 Kimi API 兼容 OpenAI,你只需替换 base URL 和一个密钥,就能将流量路由到 Moonshot models。初创团队无需重写应用逻辑即可采用 Kimi,并按透明的每次调用价格付费。
Kimi API 与竞品 LLM API 对比:上下文、模态与成本
在 Atlas Cloud 上将 Kimi API 与其他旗舰语言模型 API 进行对比,了解其在上下文长度、输入灵活性和按 token 计费价格方面的优势。
| 模型 | 上下文窗口 | 输入类型 | 输入价格($/1M tokens) | 输出价格($/1M tokens) |
|---|---|---|---|---|
| Kimi K2.7 Code | 256K tokens | 文本、图像 | $0.95 | $4.00 |
| Kimi K2.6 | 256K tokens | 文本、图像、视频 | $0.95 | $4.00 |
| Kimi K2.5 | 256K tokens | 文本、图像、视频 | $0.60 | $3.00 |
| DeepSeek V4 Pro | 1M tokens | 文本 | $1.74 | $3.45 |
| GLM 5.2 | 1M tokens | 文本 | $1.40 | $4.40 |
| Grok 4.5 | 500K tokens | 文本 | $2.00 | $6.00 |
| Doubao Seed 2.1 Pro | 256K tokens | 文本 | $0.90 | $4.50 |
如何在 Atlas Cloud 上使用 Kimi
几分钟即可上手 — 按照以下简单步骤,通过 Atlas Cloud 平台集成和部署模型。
创建 Atlas Cloud 账户
在 atlascloud.ai 注册并完成验证。新用户可获得免费额度,用于探索平台和测试模型。
为何在 Atlas Cloud 使用 Kimi
将先进的 Kimi 模型与 Atlas Cloud 的 GPU 加速平台相结合,提供无与伦比的性能、可扩展性和开发体验。
性能与灵活性
低延迟:
GPU 优化推理,实现实时响应。
统一 API:
一次集成,畅用 Kimi、GPT、Gemini 和 DeepSeek。
透明定价:
按 Token 计费,支持 Serverless 模式。
企业与规模
开发者体验:
SDK、数据分析、微调工具和模板一应俱全。
可靠性:
99.99% 可用性、RBAC 权限控制、合规日志。
安全与合规:
SOC 2 Type II 认证、HIPAA 合规、美国数据主权。
Kimi API 常见问题解答
Kimi API 让开发者能够以编程方式访问 Moonshot AI 的 Kimi 大语言模型系列,用于推理、编码和长上下文理解。在 Atlas Cloud 上,你可以通过一个兼容 OpenAI 的 endpoint 使用它,因此一个密钥即可覆盖所有 Kimi 版本,并按调用量随用随付计费。
Atlas Cloud 托管了多个版本,包括适用于长上下文和 agentic 工作流的 Kimi K2.5、Moonshot 最智能的通用模型 Kimi K2.6,以及用于编程和调试的 Kimi K2.7 Code。由于它们共享相同的请求格式,在模型之间切换只需更改一个 model 字符串。
这些模型擅长复杂编码、多文件代码库分析、文档密集型推理,以及 agentic 工具调用。当任务同时需要大容量工作记忆和强大的逐步逻辑能力时,团队通常会选择 Kimi,例如重构整个代码库或审计冗长报告。
计费方式为随用随付,无订阅费,也无最低消费。Kimi K2.5 的价格为每百万 input tokens $0.60、每百万 output tokens $3.00;Kimi K2.6 和 Kimi K2.7 Code 的价格为每百万 input tokens $0.95、每百万 output tokens $4.00。上下文缓存可降低重复或共享 prompt 的成本。
由于 Atlas Cloud 通过兼容 OpenAI 的 API 暴露 Kimi,你可以将当前的 OpenAI SDK 指向 Atlas endpoint,并替换为 Kimi model name。无需重写应用逻辑,因此它可以真正无缝接入聊天、编码和 agent 流水线。
Kimi K2.5、K2.6 和 K2.7 Code 均支持 262,144 token 的上下文窗口,约为 256K tokens。这样的容量让你无需手动分块,就能在单次请求中输入整个代码库、长篇技术手册或数百页报告。
近期的 Kimi 版本是原生多模态模型,而不是仅支持文本。Kimi K2.6 接受文本、图像和视频输入,Kimi K2.5 能对组合的视觉和文本 tokens 进行推理,因此你可以传入截图、设计文件或录屏,让模型结合你的 prompt 一并理解。
开发者最常因为成本和上下文能力而选择它。社区反馈显示,在编码质量相当的情况下,它相比领先的专有模型可显著节省成本;同时 256K 上下文窗口能够处理短上下文模型无法胜任的整个代码库和完整文档任务。立即开始构建。
探索更多系列
Seedance 2.0
Seedance 2.0 API 为您提供 ByteDance 多模态视频模型的生产级访问权限——支持四模态输入(文本、图像、视频、音频),以及行业领先的“Universal Reference”(通用参考)系统,可在不同镜头间锁定构图、运镜和角色动作。只需一次 API 调用即可集成导演级控制,固定费率为 $0.09/秒,即时获取密钥,无需排队——由企业级正常运行时间和合规性提供保障。Seedance 2.0 原生 4K 现已上线!
Grok Imagine
Grok Imagine API 为开发者提供 xAI 的图像、视频和音频生成一站式套件。它可以生成分辨率高达 2K 且支持多语言文本渲染的图像,以及长达 15 秒且带有原生同步音频和基于参考图像编辑功能的视频。在 Atlas Cloud 上,只需一个密钥即可运行每个 Grok Imagine 模式,因此您可以在图像、视频和音频之间无缝切换,无需单独设置,每张图像 0.02 美元起,每秒 0.05 美元起。
Gemini Omni Flash
Gemini Omni API 将 Google DeepMind 在 Google I/O 2026 上发布的多模态视频生成与编辑模型带入你的技术栈。Gemini Omni 将 Gemini 的推理引擎与生成式媒体融合,可接受文本、图像、视频和音频的任意组合输入,生成一致且以知识为依据的输出。通过自然对话不断打磨结果:替换物体、重写场景、切换风格,同时保持物理规律、角色形象和画面连贯性不变。Atlas Cloud 通过统一的 API 提供完整的 Gemini Omni Flash 系列——文生视频、支持最多 7 张参考图的图生视频,以及参考图生视频——按秒计费、价格透明,低至 $0.112 起,且无需订阅。立即开始构建。
GPT Image 2
GPT Image 2 API 为开发者提供了访问 OpenAI 最新图像模型的途径,它是 GPT Image 1.5 的继任者。该模型可生成和编辑图像,能够在拉丁和 CJK 文字上实现准确的文本渲染,并在海报、样机和信息图表方面具备强大的排版能力。在 Atlas Cloud 上,您可以通过一个统一的 API 与 300 多个模型一起访问它,并享受免费额度、99.99% 的正常运行时间,且无需 OpenAI 组织验证。
Google最强大的创意模型现已在Atlas Cloud上全面可用。Veo 3.1提供电影级别的视频生成,Nano Banana 2支持高保真图像创建,而Gemini为每个工作流带来多模态智能。通过单一API key即可访问完整的Google模型套件,提供Day-0可用性和按需付费(pay-as-you-go)定价。
Seedance 2.0 Mini
Seedance 2.0 Mini 将 ByteDance 的多模态视频生成技术引入到对速度和成本要求极高的工作流中。它以更轻量的占用空间提供 Seedance 2.0 的核心能力——更快的生成速度、更低的单条视频成本,并且使用您现有的同款 API 集成。对于运行高吞吐量流水线或进行大规模原型设计的团队来说,Mini 是最实用的默认选择。
ByteDance
从电影级视频生成到高保真图像创建,ByteDance 最强大的模型现已在 Atlas Cloud 上线。以最低的推理定价和零基础设施开销,大规模运行 Seedance 和 Seedream。
Alibaba
Atlas Cloud 将 Alibaba 的全系模型阵容整合至同一个 API 中:Qwen 用于语言和图像任务,Wan 用于高达 1080p 的视频生成。所有模型均采用按需付费模式,无需订阅。您可以使用现有的 OpenAI 兼容客户端,通过单一的 base URL 访问 Alibaba API。
OpenAI
Atlas Cloud 为您提供访问完整 OpenAI API 产品线的权限,从用于图像生成的 GPT Image 2 到用于视频的 Sora 2。每个模型均采用按需付费模式,无月度消费限制。使用兼容 OpenAI 的 API,只需简单替换基础 URL 即可轻松接入。
xAI
在 Atlas Cloud 上使用 xAI API 构建完整的图像和视频处理工作流。以 2K 分辨率生成、使用参考图像进行编辑,并将图像动画化为音画同步的视频片段。
Kwaivgi
Kwaivgi API 价格低于标准定价 15%。Atlas Cloud 提供对最新 Kling 版本的零日(Day-0)访问权限,采用按需付费定价且无席位限制。一个账户,一个密钥,畅享从标准版到大师版的所有 Kling 模型。
Seedream 5.0 Pro
Seedream 5.0 Pro API 为开发者在 Atlas Cloud 上提供了字节跳动的可控图像编辑模型。它通过锚点和坐标精确定位编辑,将图像分离为可编辑图层,融合多个参考,并精准匹配颜色和材质,支持 2K 和 3K 分辨率的多语言文本。在 Atlas Cloud 上,您只需一个密钥即可访问!


