
Seedream 5.0 Lite API with Search and Reasoning
Seedream 5.0 Lite API 将 ByteDance 推理优先的图像模型引入 Atlas Cloud。这是首个将实时网络搜索与视觉推理相结合的图像模型,使其生成过程基于实时信息和现实世界的物理规律,并支持原生编辑。在 Atlas Cloud 上,只需一个兼容 OpenAI 的密钥即可运行,单张图像价格低至 0.032 美元,并支持最多 15 帧连贯图像的序列输出。
探索领先模型
Atlas Cloud 为您提供最新的行业领先创意模型。




峰值速度
最低成本
| 模态 | 描述 |
|---|---|
| Seedream v5.0 T2I Lite API(Text To Image) | Seedream v5.0 T2I Lite API 赋能创作者将文本描述即时转化为高保真视觉图像。它具备 PNG 输出和快速提示词优化模式,简化了快速原型设计、UI/UX 概念化以及高速创意迭代的设计流程,专为追求速度与清晰度的场景打造。 |
| Seedream v5.0 I2I Lite Edit API(Image To Image) | Seedream v5.0 I2I Lite Edit API 为开发者提供了通过文本提示词和参考图像转换现有图像的工具。它支持无缝风格迁移和精确内容编辑,非常适合迭代设计和品牌资产定制。 |
| Seedream v5.0 T2I Lite Sequential API(Text To Image) | Seedream v5.0 T2I Lite Sequential API 通过在单次请求中生成多达 15 张相关图像,彻底改变了批量内容创作。它专为大批量资产生产、故事板扩展和全面的视觉世界构建进行了优化。 |
| Seedream v5.0 I2I Lite Edit Sequential API(Image To Image) | Seedream v5.0 I2I Lite Edit Sequential API 使用户能够同时对一系列图像应用一致的编辑。通过在一个批次中处理多达 15 个相关视觉内容,它确保了视觉和谐与风格的连续性,使其成为角色设计变体、序列编辑和复杂视觉叙事的理想解决方案。 |
Seedream 5.0 Lite API 的主要特性
探索 Seedream 5.0 Lite API 提供的功能,从实时网络搜索和视觉推理,到精确编辑、多参考合成以及序列化生成。

基于 Seedream 5.0 API 的实时网络搜索能力
Seedream 5.0 引入了业界首创的“搜索即生成”工作流,弥合了实时信息与视觉合成之间的鸿沟。通过捕捉热点新闻、全球事件和实时数据,它为模型注入了广阔的“通用知识”库。这是创作时效性编辑内容、数据驱动的可视化图表以及具有文化相关性的营销资产的终极工具。

使用 Seedream 5.0 API 实现智能逻辑推理与物理一致性
该版本集成了深厚的垂直行业知识——从生物科学到建筑设计——以确保严谨的结构完整性。它在严格遵守现实世界物理定律(包括空间布局和光照一致性)的同时,精准解读复杂的逻辑关系。它为科学可视化、工业原型设计和超逼真环境渲染提供了基础解决方案。

使用 Seedream 5.0 API 实现精准控制与可编辑性
Seedream 5.0 API 拥有先进的指令跟随和多模态参考能力,能实现对视觉输出的前所未有的控制。利用复杂的学习算法,它可以自动重用特定的视觉元素,并在不同的上下文中保持主体一致性(Identity Persistence)。它是品牌一致性资产创建、角色一致性和迭代创意优化的强大引擎。

序列生成
Seedream 5.0 Lite API 可以在单次请求中生成多达15张相关图像,并在整个图像集中保持主题、风格和身份的一致性。这非常适合角色世界构建、时尚画册以及统一的品牌资产套件。

多参考合成
将多张源图像分别引用为图1、图2等,Seedream 5.0 Lite API 即可将其元素融合为一幅完整的合成作品。它支持角色融合、场景构建以及精准的风格迁移。
Seedream 5.0 vs Other Models - One Prompt
相同的提示词,由 Seedream 5.0 及其他领先的图像模型生成:UI界面和中式产品海报
Create a polished mobile app home screen for a blind-box collectible toy app. Screen details: Top bar: - Time: 9:41 - Search bar with placeholder text: “Search toys” - Bell icon on the right Main banner: Title: “Mystery Drop” Subtitle: “New designer toys every Friday” A cute 3D vinyl bunny toy standing beside a gift box. Sections: 1. “New Arrivals” with three toy cards 2. “Limited Series” with two wider cards 3. Bottom navigation with four tabs: Home, Shop, Collection, Profile Style: Purple and white gradient UI, glossy 3D toy elements, clean rounded cards, modern mobile app design, readable interface text, no random letters, no broken icons.
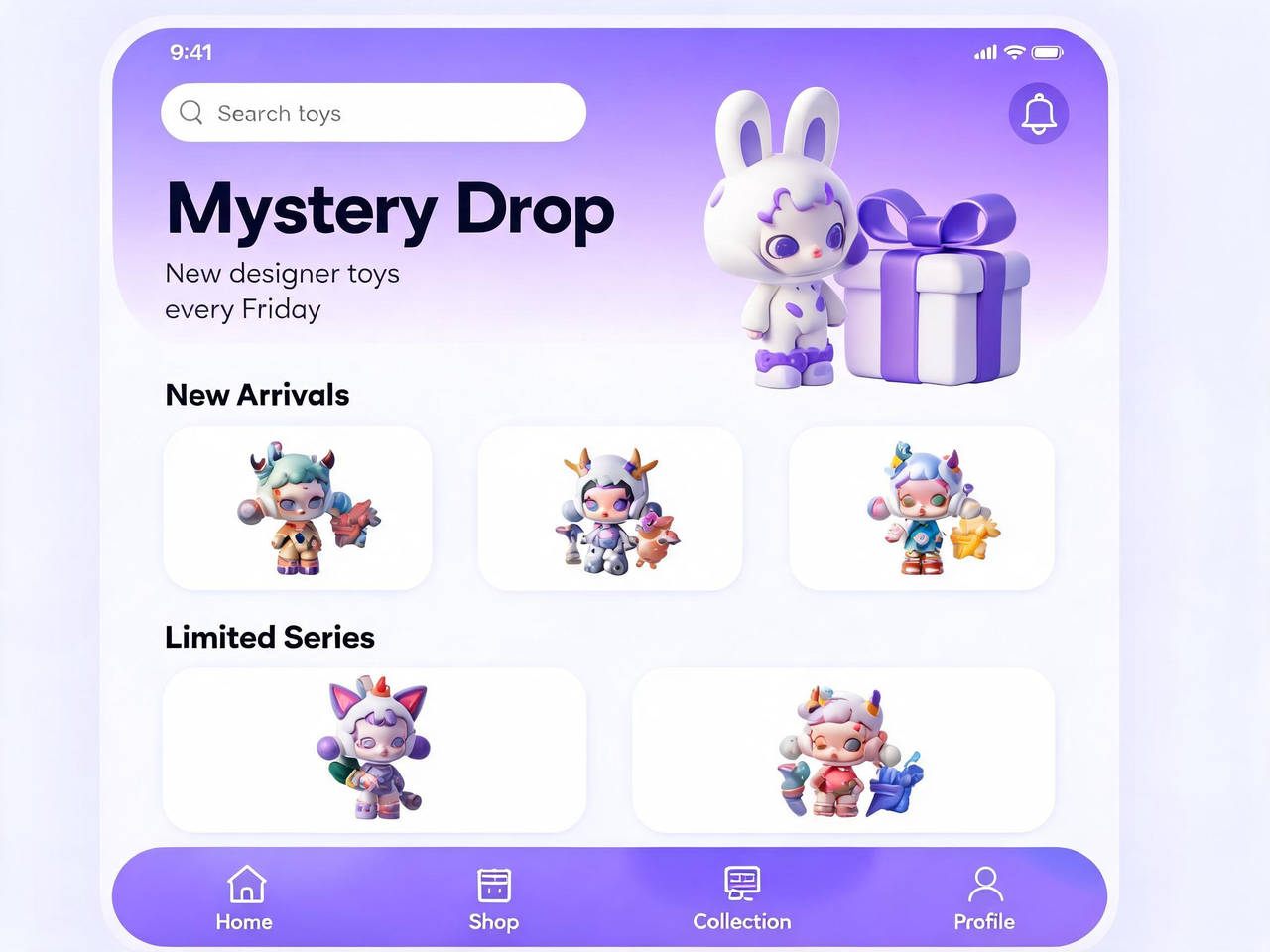
Seedream 5.0
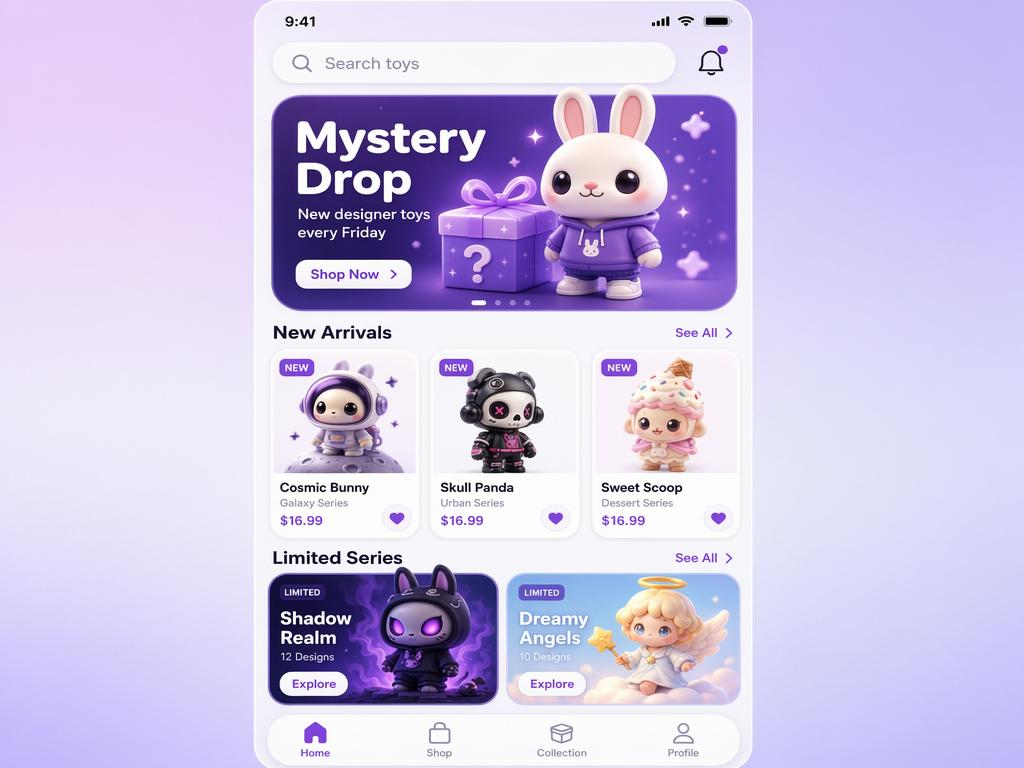
GPT-image-2
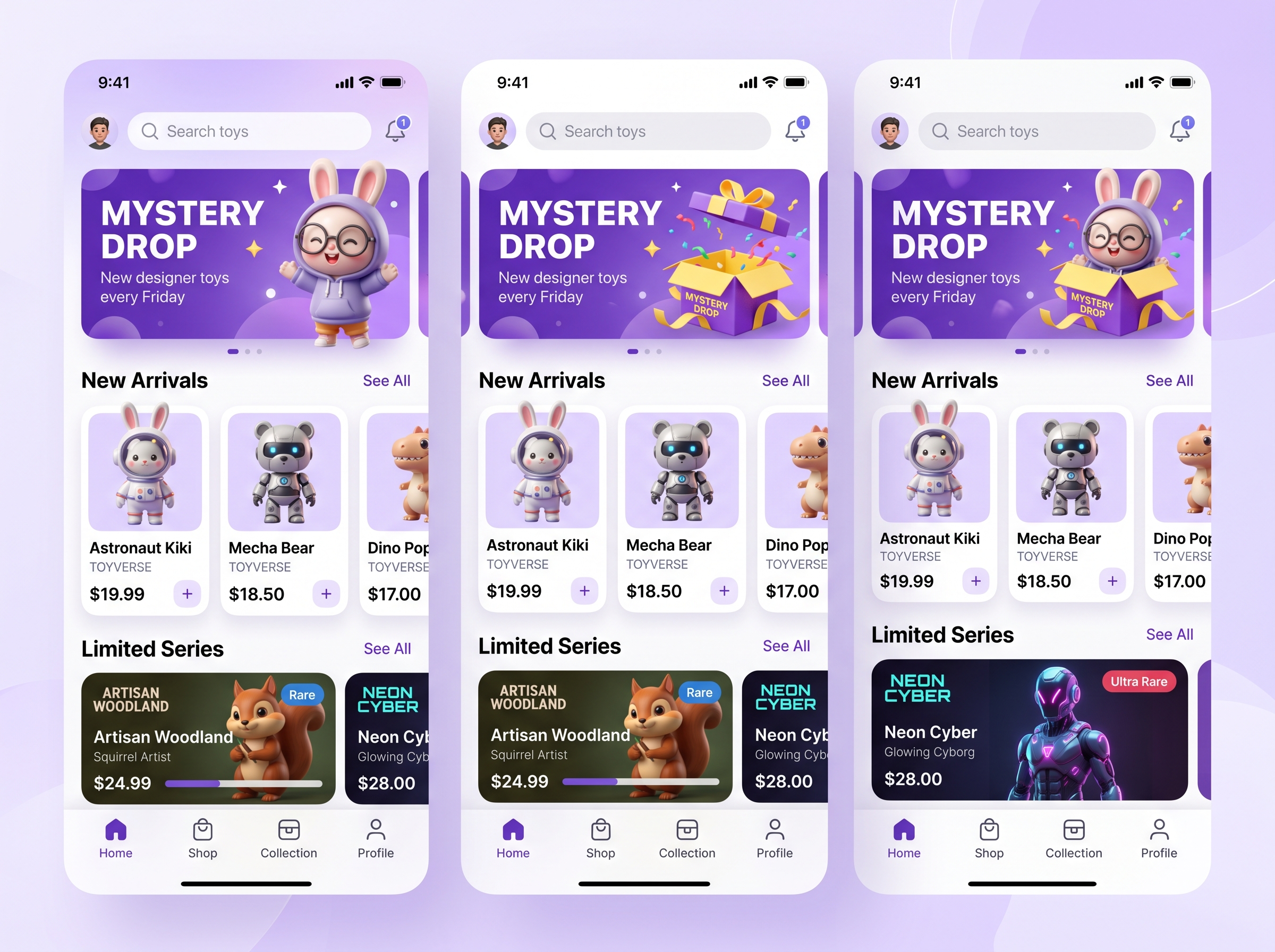
Nano Banana2
Create a poster for a Chinese new-style tea brand. Brand Name: Shan Yue Tea Affairs Main Title: A Bite of Spring Mountains Subtitle: Limited-time release of Pre-Qingming Longjing tea Image content: In a transparent glass cup, there’s light green Longjing tea placed on a bamboo tea tray. Nearby lie a few fresh tea leaves, an open book bound in thread, and faint wisps of steam. The background features a light beige texture reminiscent of rice paper, with faint shades of green mountains in the background. Layout requirements: The main title should be placed slightly to the left of the top of the screen, using an elegant Chinese calligraphy style. It must still be legible. The subtitle is placed below the main title, in a smaller font size. Add a small seal in the lower right corner with the text “Spring Limited Edition”. Style: New Chinese style, elegant and minimalist, with elements of Eastern aesthetics. It combines the feel of commercial advertising with a sophisticated yet unpretentious appearance. All Chinese text must be accurate, without any garbled characters or unnecessary words.

Seedream 5.0

GPT-image-2

Nano Banana2
您可以使用 Seedream 5.0 Lite API 实现的功能
探索您可以使用 Seedream 5.0 Lite API 构建的内容,从上下文感知营销和产品视觉效果,到信息图表、图像编辑、科学原型设计以及连贯的品牌叙事。
基于 Seedream 5.0 的动态上下文感知营销
Seedream 5.0 API 赋能品牌生成与现实世界同频共振的视觉内容。通过集成业界首创的实时网络搜索(Real-Time Web Search),它能捕捉流行美学和实时数据,制作出具有文化相关性的图像。它是新闻响应式社交活动、数据驱动型编辑内容以及任何需要最新全球语境和视觉叙事项目的终极解决方案。
使用 Seedream 5.0 进行高精度工业与科学原型设计
对于要求结构完整性的项目,Seedream 5.0 可提供内嵌垂直逻辑和严格遵循物理规律的图像。它能驾驭复杂的空间布局、一致的照明和材质准确性。该用例适用于建筑可视化、工业产品设计和科学插图,在这些领域,精确度和现实世界的物理定律与审美质量同样重要。
使用 Seedream 5.0 实现统一的品牌叙事与角色一致性
Seedream 5.0 通过其顺序生成(Sequential Generation)和先进的参考功能,提供了无与伦比的视觉持久性控制。通过学习和重用特定的视觉元素,创作者可以在多帧之间保持完美的身份一致性。非常适合角色世界构建、高端时尚 Lookbook 以及需要在每次请求中保持统一风格的连贯品牌资产套件。
电子商务与产品可视化
在多种背景、光照设置和构图下生成同一产品,同时保持其形状、颜色和Logo一致。Seedream 5.0 Lite API 帮助在线商店无需摄影棚即可生成生活场景图和变体集。
信息图表与数据可视化
凭借视觉推理和实时网络搜索,Seedream 5.0 Lite API 能够渲染出带有准确标签和最新数据的图表、示意图与信息图。这非常适用于报告、教育视觉资料以及数据驱动的编辑内容。
图像编辑与合成
Seedream 5.0 Lite API 可通过自然语言编辑现有图像,并通过多图参考将多个来源融合到一个场景中。它支持风格迁移、物体编辑和角色融合,以生成精美且可重用的资产。
模型对比
查看不同厂商的模型表现 — 对比性能、价格和独特优势,做出明智决策。
| 模型 | 参考图像限制 | 输出数量 | 分辨率 | 纵横比 |
|---|---|---|---|---|
| Seedream 5.0 Lite | 14 | 1~15 | 2K~4K+ | 1:1 3:2 2:3 3:4 4:3 4:5 5:4 9:16 16:9 21:9 |
| Seedream 4.5 | 10 | 1~15 | 1080P~4K+ | Width[1440, 4096]px; Height[1440, 4096]px |
| Nano Banana 2 | 14 | 1 | 4K, 2K, 1K | 1:1 3:2 2:3 3:4 4:3 4:5 5:4 9:16 16:9 21:9 |
| Qwen-Image | 3 | 1~6 | 512P~2K | Width[512, 2048]px; Height[512, 2048]px |
| Wan 2.6 I2I(Image To Image) | 4 | 1 | 580P~1080P+ | 1:1 3:2 2:3 3:4 4:3 4:5 5:4 9:16 16:9 21:9 9:21 |
如何在 Atlas Cloud 上使用 Seedream 5.0 Lite
几分钟即可上手 — 按照以下简单步骤,通过 Atlas Cloud 平台集成和部署模型。
创建 Atlas Cloud 账户
在 atlascloud.ai 注册并完成验证。新用户可获得免费额度,用于探索平台和测试模型。
为何在 Atlas Cloud 使用 Seedream 5.0 Lite
将先进的 Seedream 5.0 Lite 模型与 Atlas Cloud 的 GPU 加速平台相结合,提供无与伦比的性能、可扩展性和开发体验。
性能与灵活性
低延迟:
GPU 优化推理,实现实时响应。
统一 API:
一次集成,畅用 Seedream 5.0 Lite、GPT、Gemini 和 DeepSeek。
透明定价:
按 Token 计费,支持 Serverless 模式。
企业与规模
开发者体验:
SDK、数据分析、微调工具和模板一应俱全。
可靠性:
99.99% 可用性、RBAC 权限控制、合规日志。
安全与合规:
SOC 2 Type II 认证、HIPAA 合规、美国数据主权。
Seedream 5 Lite 常见问题解答
Seedream 5.0 Lite API 通过一个兼容 OpenAI 的密钥,为开发者提供 Atlas Cloud 上 ByteDance 的推理优先图像模型。它是首个将实时网络搜索与视觉推理相结合的图像模型,并在单个 API 中涵盖了文本生成图像和图像编辑功能。
Seedream 5.0 Lite API 是首个将实时网络搜索与思维链视觉推理相结合的图像模型。这使其能够将图像建立在最新信息和现实世界物理规律的基础上,从而保持复杂场景、空间逻辑和光影的一致性。
在 Atlas Cloud 上,Seedream 5.0 Lite API 的定价为每张图像 0.032 美元起,低于标准的 0.035 美元费率。计费透明且无需订阅,您只需为您生成的图像付费。
是的。Seedream 5.0 Lite API 支持在图像生成的同时进行原生图像编辑,只需使用自然语言指令和多张参考图像。您可以进行风格迁移、调整元素,并将多个素材合成到一个场景中。
Sequential API 可以在单次请求中生成多达 15 张相关图像,并在整个图像集中保持主题、风格和身份的一致性。这使其非常适合用于角色集合、宣传画册和连贯的品牌资产套件。
Seedream 5.0 Lite API 支持多种宽高比的 2K 和 3K 输出。更高的分辨率适合打印和注重细节的商业作品,而 2K 能够在处理大批量任务时保持成本和速度的高效。
Seedream 5.0 Lite 新增了 Seedream 4.5 所不具备的实时网络搜索、视觉推理和原生编辑功能,并具有更强的一致性和提示词对齐能力。它的定价也低于 4.5 版本,让您以更低的价格获得更强大的功能。
是的。通过 Seedream 5.0 Lite API 生成的图像可以在 Atlas Cloud 的标准条款下用于商业项目。请查阅适用于您特定用例的相关条款。
是的。Atlas Cloud 提供了一个兼容 OpenAI 的 API,因此您可以将 OpenAI SDK 指向 Atlas Cloud 的基础 URL,添加您的密钥,并使用您现有的代码调用 Seedream 5.0 Lite API。文本到图像和编辑功能均通过同一个端点运行。
探索更多系列
Seedance 2.0
Seedance 2.0 API 为您提供字节跳动多模态视频模型的生产级访问权限——支持四模态输入(文本、图像、视频、音频),以及业界领先的“通用参考”(Universal Reference)系统,可在不同镜头间锁定构图、运镜和角色动作。只需一次 API 调用即可集成导演级控制,统一费率 $0.09/秒,即刻获取密钥,无需排队等待——由企业级正常运行时间与合规性提供保障。Seedance 2.0 原生 4K 现已于 2026 年 6 月正式上线!
Grok Imagine
Grok Imagine API 为开发者提供 xAI 的图像、视频和音频生成一站式套件。它可以生成分辨率高达 2K 且支持多语言文本渲染的图像,以及长达 15 秒且带有原生同步音频和基于参考图像编辑功能的视频。在 Atlas Cloud 上,只需一个密钥即可运行每个 Grok Imagine 模式,因此您可以在图像、视频和音频之间无缝切换,无需单独设置,每张图像 0.02 美元起,每秒 0.05 美元起。
Gemini Omni Flash
The Gemini Omni Flash API gives developers Google DeepMind's reasoning-driven video model, now in public preview. It generates video from any mix of text, image, video, and audio, produces synchronized sound in a single pass, and lets you edit through natural conversation while keeping continuity intact. On Atlas Cloud you call it with one key and no Google Cloud setup, at 720p from $0.112 per second.
Happy Horse
HappyHorse 在 Artificial Analysis Video Arena 排行榜的文本生成视频和图像生成视频领域均位居榜首。HappyHorse 1.0 API 和 HappyHorse 1.1 API 使开发者能够直接访问 Alibaba 的统一视频模型——无需多阶段处理流程,只需一次集成即可支持两种模态。直接从您的代码中生成带有同步音频的 1080p 视频。
GPT Image 2
GPT Image 2 API 为开发者提供了访问 OpenAI 最新图像模型的途径,它是 GPT Image 1.5 的继任者。该模型可生成和编辑图像,能够在拉丁和 CJK 文字上实现准确的文本渲染,并在海报、样机和信息图表方面具备强大的排版能力。在 Atlas Cloud 上,您可以通过一个统一的 API 与 300 多个模型一起访问它,并享受免费额度、99.99% 的正常运行时间,且无需 OpenAI 组织验证。
Google最强大的创意模型现已在Atlas Cloud上全面可用。Veo 3.1提供电影级别的视频生成,Nano Banana 2支持高保真图像创建,而Gemini为每个工作流带来多模态智能。通过单一API key即可访问完整的Google模型套件,提供Day-0可用性和按需付费(pay-as-you-go)定价。
Seedance 2.0 Mini
Seedance 2.0 Mini 将 ByteDance 的多模态视频生成技术引入到对速度和成本要求极高的工作流中。它以更轻量的占用空间提供 Seedance 2.0 的核心能力——更快的生成速度、更低的单条视频成本,并且使用您现有的同款 API 集成。对于运行高吞吐量流水线或进行大规模原型设计的团队来说,Mini 是最实用的默认选择。
ByteDance
从电影级视频生成到高保真图像创建,ByteDance 最强大的模型现已在 Atlas Cloud 上线。以最低的推理定价和零基础设施开销,大规模运行 Seedance 和 Seedream。
Alibaba
Atlas Cloud 将 Alibaba 的全系模型阵容整合至同一个 API 中:Qwen 用于语言和图像任务,Wan 用于高达 1080p 的视频生成。所有模型均采用按需付费模式,无需订阅。您可以使用现有的 OpenAI 兼容客户端,通过单一的 base URL 访问 Alibaba API。
OpenAI
Atlas Cloud 为您提供访问完整 OpenAI API 产品线的权限,从用于图像生成的 GPT Image 2 到用于视频的 Sora 2。每个模型均采用按需付费模式,无月度消费限制。使用兼容 OpenAI 的 API,只需简单替换基础 URL 即可轻松接入。
xAI
在 Atlas Cloud 上使用 xAI API 构建完整的图像和视频处理工作流。以 2K 分辨率生成、使用参考图像进行编辑,并将图像动画化为音画同步的视频片段。
Kwaivgi
Kwaivgi API 价格低于标准定价 15%。Atlas Cloud 提供对最新 Kling 版本的零日(Day-0)访问权限,采用按需付费定价且无席位限制。一个账户,一个密钥,畅享从标准版到大师版的所有 Kling 模型。


