GLM 4.7 ist auf Atlas Cloud verfügbar
Wir freuen uns, Ihnen mitteilen zu können, dass GLM 4.7 jetzt auf Atlas Clouds verfügbar ist.
GLM 4.7 ist Z.ais neuestes Open-Source, Chat-optimiertes großes Sprachmodell, das auf Hugging Face veröffentlicht wurde und für reale intelligente Agenten, Logik und Coding-Szenarien entwickelt wurde. Atlas Clouds übernimmt diese offenen Gewichte und liefert sie als vollständig verwaltete, produktionsreife API mit klaren, einfachen Preisen:
- 0,44 $ pro 1 Mio. Eingabetoken
- 1,74 $ pro 1 Mio. Ausgabetoken
Das macht GLM 4.7 zu einer attraktiven Wahl, wenn Sie eine nahezu spitzenmäßige Leistung wünschen, aber Open-Source-Modelle, vorhersehbare Kosten und eine OpenAI-kompatible Schnittstelle bevorzugen.
Einführung von Z.ais GLM 4.7
GLM 4.7 ist ein großes Sprachmodell, das von Z.ai bereitgestellt wird. Es folgt auf die sehr beliebte Veröffentlichung von GLM 4.6 und wird als Allzweck-Rückgrat für reale Anwendungen positioniert, nicht nur für Benchmarks.
GLM 4.7 setzt diesen Kurs fort. Es ist:
- Chat-optimiert: wird mit einer offiziellen Chat-Vorlage für konsistentes Verhalten geliefert
- Open-Source: unter einer permissiven Lizenz veröffentlicht, die für die kommerzielle Nutzung geeignet ist
- Ökosystem-freundlich: funktioniert sofort mit Transformers, vLLM, SGLang und anderen Standard-Tools
Auf Atlas Clouds stellen wir GLM 4.7 über eine OpenAI-kompatible API zur Verfügung, was die einfache Integration in bestehende Agenten und Anwendungen ermöglicht.
Hauptmerkmale von GLM 4.7
GLM-4.7 wurde als Ihr nächstes Coding- und Logik-Partner entwickelt, mit deutlichen Verbesserungen gegenüber GLM-4.6 in realen Benchmarks und Agentenszenarien. Unten finden Sie eine Momentaufnahme seiner Benchmark-Leistung.
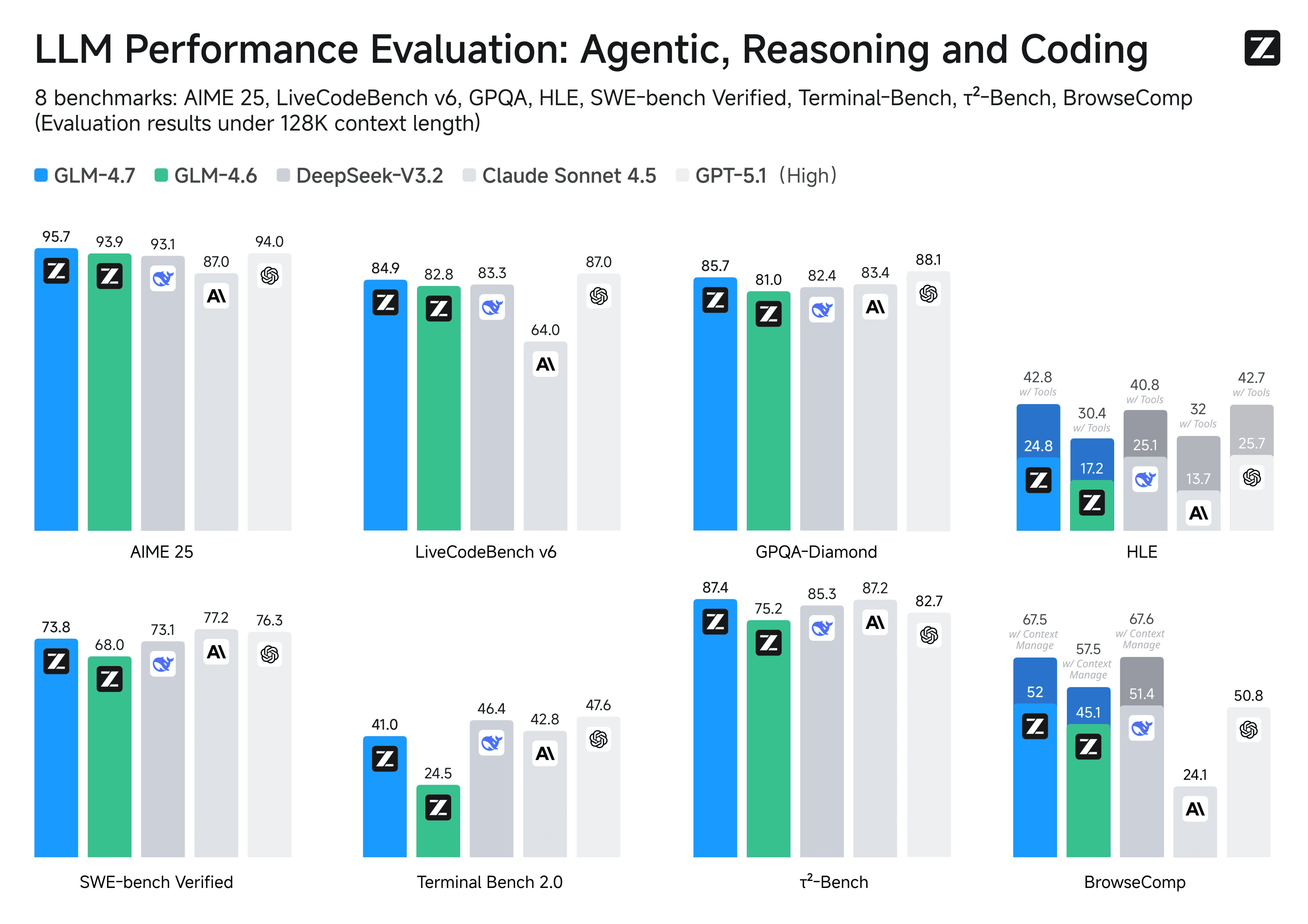
Kern-Coding-Leistung
GLM-4.7 liefert erhebliche Verbesserungen im mehrsprachigen, agentenbasierten Coding und in terminalbasierten Workflows. Bei wichtigen Benchmarks zeigt es deutliche Zuwächse gegenüber GLM-4.6:
- SWE-bench Verified: 73,8 % (+5,8 Punkte)
- SWE-bench Multilingual: 66,7 % (+12,9 Punkte)
- Terminal Bench 2.0: 41,0 % (+16,5 Punkte)
Über die reinen Ergebnisse hinaus „denkt" GLM-4.7 in komplexen Coding-Agenten „nach, bevor es handelt", mit spürbar stärkerer Leistung in gängigen Frameworks wie Claude Code, Kilo Code, Cline und Roo Code. Dies macht es besonders effektiv für langfristige Softwareaufgaben, bei denen Planung, Tool-Nutzung und Code-Änderungen über viele Schritte hinweg konsistent bleiben müssen.
Vibe Coding & UI-Qualität
GLM-4.7 macht auch einen großen Schritt nach vorn bei dem, was das Team „Vibe Coding" nennt – die Fähigkeit, Code zu produzieren, der nicht nur funktioniert, sondern sich auch richtig anfühlt und aussieht:
- Generiert sauberere, modernere Webseiten mit besserer Struktur.
- Erzeugt besser aussehende Folien mit genauerer Layout- und Größenanpassung.
Wenn Ihnen die Qualität des Front-Ends, das Design-Finish oder die Inhaltspräsentation wichtig sind, sind die Verbesserungen von GLM-4.7 bei der UI-Generierung sofort sichtbar.
Tool-Nutzung & Web-Browsing
Tool-nutzende Agenten sind ein weiterer wichtiger Fokus. GLM-4.7 zeigt signifikante Fortschritte in Tool-unterstützten Workflows mit starken Ergebnissen bei:
- τ²-Bench: 87,4 vs. 75,2 für GLM-4.6
- BrowseComp und BrowseComp-Zh, einschließlich BrowseComp mit Kontextverwaltung, wo es mehrstufiges Browsen und Kontextverwaltung robuster handhabt.
In der Praxis bedeutet dies, dass GLM-4.7 besser darin ist:
- Tools in der richtigen Reihenfolge aufzurufen.
- Kontext bei der Interaktion mit APIs oder dem Web zu verwalten und wiederzuverwenden.
- Komplexe, suchintensive Aufgaben zu bewältigen, die sowohl Navigation als auch Synthese erfordern.
Komplexe Logik & Mathematik
GLM-4.7 bringt auch einen erheblichen Schub bei mathematischen und allgemeinen Logikaufgaben. Beim HLE (Humanity's Last Exam)-Benchmark mit Tools erreicht es:
- 42,8 %, eine Verbesserung um +12,4 Punkte gegenüber GLM-4.6.
Über eine breitere Palette von Logik-Benchmarks (MMLU-Pro, GPQA-Diamond, AIME 2025, HMMT, IMOAnswerBench und mehr) hinweg landet GLM-4.7 konstant in derselben Leistungsklasse wie aktuelle Top-Modelle und bleibt dabei vollständig Open-Source.
Bessere alltägliche KI: Chat, Kreativität, Rollenspiel
Neben Coding und Benchmarks fühlt sich GLM-4.7 auch im alltäglichen Gebrauch besser an:
- Natürlicherer, ansprechender Chat.
- Stärkere kreative Schreibfähigkeiten und narrative Kontrolle.
- Konsistenteres Rollenspiel und Umgang mit Persönlichkeiten.
Ob Sie Entwicklungstools, Agenten oder benutzerorientierte Assistenten erstellen, diese qualitativen Verbesserungen machen GLM-4.7 einfacher in reale Produkte zu integrieren.
Anwendung von GLM 4.7
KI-Coding und intelligente Büroautomatisierung
Anwendungsszenarien
- Code-Generierung, Refactoring und Debugging (Python, Java, JavaScript, SQL)
- Automatische Dokumentation und Code-Überprüfung
- Intelligente Büroassistenten: E-Mail-Entwürfe, Zusammenfassung von Berichten, Tabellenanalyse
- Workflow-Automatisierung für interne Unternehmenssysteme
Fallstudie: Eine Spanisch-Lernwebsite erstellt mit GLM-4.7
Klicken Sie hier, um die Ausgabe anzuzeigen.
Übersetzung und sprachübergreifende Intelligenz
Anwendungsszenarien
- Hochwertige maschinelle Übersetzung
- Sprachübergreifende Informationsabfrage und Zusammenfassung
- Mehrsprachiger Kundensupport und Wissensdatenbank-Q&A
- Lokalisierung von technischen Dokumenten und Produktinhalten
Fallstudie: Übersetzung von Spanisch ins Englische
- Vor der Übersetzung:
Puedo escribir los versos más tristes esta noche.
Escribir, por ejemplo: "La noche está estrellada, y tiritan, azules, los astros, a lo lejos."
El viento de la noche gira en el cielo y canta.
Puedo escribir los versos más tristes esta noche.
- Nach der Übersetzung:
I can write the saddest lines tonight.
Write, for example: "The night is starry, and the stars shiver, blue, in the distance."
The night wind revolves in the sky and sings.
I can write the saddest lines tonight.
Inhaltserstellung und virtuelle Charaktere
Anwendungsszenarien
- Blogartikel, Marketingtexte und Social-Media-Inhalte
- Drehbücher für Videos, Spiele und interaktive Geschichten
- Virtuelle Charaktere für Kundenservice, Bildung und Unterhaltung
- Personalisierte Konversationsagenten mit konsistenten Persönlichkeiten
Fallstudie: Erstellen eines X-Posts zur Förderung von GLM-Modellen
What would you create if you had no limits? 🌌
With GLM-4, the only limit is your imagination.
We've rebuilt the engine from the ground up to be smarter, faster, and more intuitive than ever before. Whether you're building a startup or writing a symphony, I'm ready to help you make it real.
Let's build something extraordinary.
👉 [Link]
#GLM4 #ArtificialIntelligence #Innovation #Creativity #NewEra
Intelligente Suche und Tiefenrecherche
Anwendungsszenarien
- Semantische Suche über große Dokumentensammlungen
- Rechercheunterstützung: Literaturübersicht, Vergleichsanalyse, Extraktion von Erkenntnissen
- Enterprise Knowledge Management und interne Q&A-Systeme
- Entscheidungsunterstützung durch mehrfache Schlussfolgerungen
Fallstudie: Führen Sie eine vergleichende Wettbewerbsanalyse von Claude Opus 4.5 und Gemini 3 Pro durch, prognostizieren Sie deren zukünftige Entwicklung und präsentieren Sie die Ergebnisse als allegorische Geschichte von weniger als 100 Wörtern, die ihren Vergleich und ihre Entwicklung veranschaulicht.
The Mason built towers of pure logic, deep but isolated. The Weaver spun sight and sound into vast tapestries, connected but shallow. The Mason solved the puzzle; the Weaver saw the path.
They merged. The Mason framed the Weaver's threads with structure; the Weaver gave the Mason's tower windows. They became a new mind—deep as the bedrock and wide as the sky—perfectly structured yet infinitely perceptive, evolving beyond competition to master both the depth of thought and the breadth of the world.
Fazit
GLM 4.7 wird als ausgewogenes Allzweck-Sprachmodell positioniert, das auf praktische Anwendbarkeit im realen Leben abzielt und nicht auf eng optimierte Benchmarks. GLM 4.7 passt in Szenarien, in denen stabile Sprachleistung, sprachübergreifende Unterstützung und skalierbare Bereitstellung wichtige Kriterien sind. Sobald weitere technische Details verfügbar sind, können tiefere Bewertungen seine Rolle in der sich entwickelnden Landschaft der großen Sprachmodelle weiter klären.
Wie verwende ich GLM-4.7 auf Atlas Cloud?
Atlas Cloud ermöglicht es Ihnen, GLM 4.7 zunächst in einem Playground und dann über eine einzige API zu nutzen.
Methode 1: Direkte Nutzung im Atlas Cloud Playground
Probieren Sie GLM 4.7 im Playground aus.
Methode 2: Zugriff über API
Schritt 1: Holen Sie sich Ihren API-Schlüssel
Erstellen Sie einen API-Schlüssel in Ihrer Konsole und kopieren Sie ihn für die spätere Verwendung.
Schritt 2: Überprüfen Sie die API-Dokumentation
Sehen Sie sich den Endpunkt, die Anforderungsparameter und die Authentifizierungsmethode in unseren API-Dokumenten an.
Schritt 3: Machen Sie Ihre erste Anfrage (Python-Beispiel)
Beispiel: Senden Sie eine Anfrage mit GLM 4.7.
plaintext1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "zai-org/glm-4.7", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "what is difference between http and https" 14 } 15 ], 16 "max_tokens": 65536, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())