Die Weltweit Führenden LLMs.
Bereit für Jede Konversation.
Antrieb für Argumentation, Programmierung und natürliche Sprache mit unternehmensklassigen großen Sprachmodellen.
Erkunden Sie Unsere Umfassenden LLM-Modelle
The latest Qwen reasoning model.
Qwen3 VL 30B A3B Thinking
The latest Qwen reasoning model.
Qwen3 VL 8B Instruct
The latest Qwen reasoning model.
Qwen3 VL 30B A3B Instruct
MiniMax-M2.7 is a lightweight, state-of-the-art large language model optimized for coding, agentic workflows, and modern application development. With only 10 billion activated parameters, it delivers a major jump in real-world capability while maintaining exceptional latency, scalability, and cost efficiency.
MiniMax M2.7
Qwen3.5 represents a significant leap forward, integrating breakthroughs in multimodal learning, architectural efficiency, reinforcement learning scale, and global accessibility to empower developers and enterprises with unprecedented capability and efficiency.
Qwen3.5 122B A10B
Qwen3.5 represents a significant leap forward, integrating breakthroughs in multimodal learning, architectural efficiency, reinforcement learning scale, and global accessibility to empower developers and enterprises with unprecedented capability and efficiency.
Qwen3.5 35B A3B
Qwen3.5 represents a significant leap forward, integrating breakthroughs in multimodal learning, architectural efficiency, reinforcement learning scale, and global accessibility to empower developers and enterprises with unprecedented capability and efficiency.
Qwen3.5 27B
Qwen3 Coder represents a significant leap forward, integrating breakthroughs in multimodal learning, architectural efficiency, reinforcement learning scale, and global accessibility to empower developers and enterprises with unprecedented capability and efficiency.
Qwen3 Coder Next
Der Atlas Cloud Vorteil:
Geschwindigkeit, Skalierung und Einsparungen
Unsere Modellbibliothek ist nicht nur die größte. Sie ist die kosteneffizienteste, zuverlässigste und produktionsbereiteste. Bewährte Leistung, unterstützt durch Daten.
300+ Modelle, Eine Einheitliche API
Multimodal, Open-Source, proprietär: alles über einen konsistenten Endpunkt.
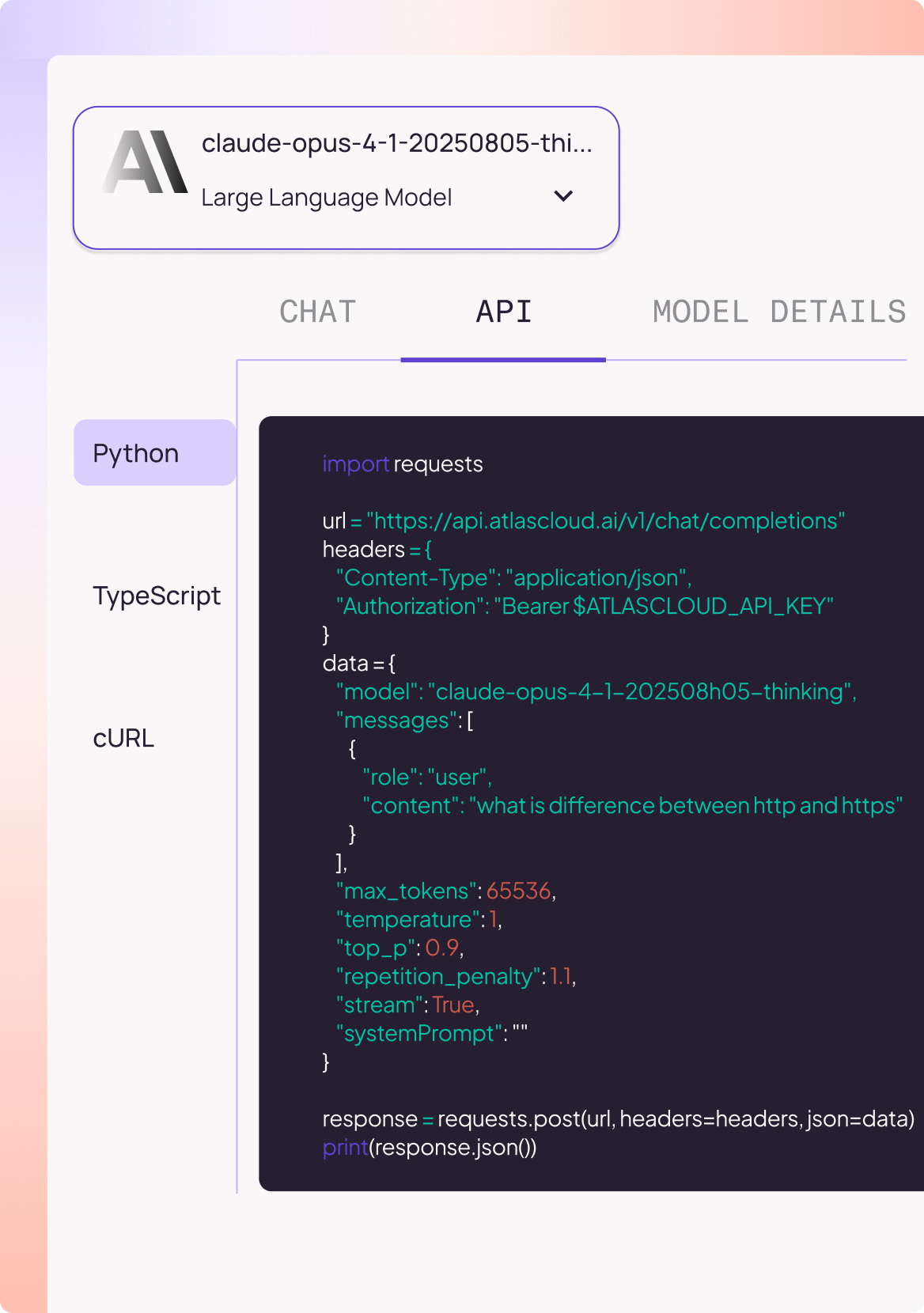
Serverless API-Zugriff
Starten Sie sofort mit Python, TypeScript oder cURL, ohne Infrastruktur-Setup.
Bewährte Leistung im Maßstab
10M+ API-Aufrufe/Monat, 70+ TPS-Stabilität, bereitgestellt in 12 globalen Regionen.
Transparente & Flexible Preisgestaltung
Pay-as-you-go. Unternehmensrabatte bis zu 50%.