DeepSeek LLM Models
DeepSeek, developed by the deepseek-ai team, is a cutting-edge series of open-source generative AI models engineered to democratize access to high-performance computing through a cost-effective and efficiency-first strategy. Its flagship reasoning model, DeepSeek-R1, made waves by rivaling top-tier proprietary models in mathematics, programming, and complex logical deduction, while the DeepSeek-V3.2, is designed for seamless daily interaction and autonomous Agent workflows. By significantly lowering the barrier to entry for advanced AI, DeepSeek has become a cornerstone for the "vibe coding" movement and a transformative tool in specialized fields like academic research and high-level technical problem-solving.
Erkunden Sie die Führenden Modelle
Atlas Cloud bietet Ihnen die neuesten branchenführenden kreativen Modelle.
Was DeepSeek LLM Models Auszeichnet
Atlas Cloud bietet Ihnen die neuesten branchenführenden kreativen Modelle.

Offene Leistung
Erstklassige Modelle, die vollständig Open Source sind und Transparenz sowie Kontrolle gewährleisten.

Architektureffizienz
Nutzt fortschrittliche Mixture-of-Experts (MoE) für führende Leistung zu einem Bruchteil der Kosten.

Eigens entwickelte Vielseitigkeit
Vom vielseitigen V3.1 bis zum spezialisierten Reasoning des R1 bietet DeepSeek Modelle für jede Aufgabe.

Entwicklerorientierte Freiheit
Mit einer permissiven Lizenz für uneingeschränkte kommerzielle Nutzung, um Innovationen ohne Barrieren zu fördern.

Bewährte Leistung
Erzielt bei Industrie-Benchmarks für Programmierung und logisches Denken konsequent Ergebnisse auf dem neuesten Stand der Technik.

Die praktische Alternative
Bietet die Leistung führender proprietärer Modelle mit der Kosteneffizienz und Flexibilität von Open Source.
Peak speed
Lowest cost
| Modalität | Beschreibung |
|---|---|
| DeepSeek V3.2 | DeepSeek V3.2 ist ein führendes Allzweck-LLM, das Sparse-Attention-Mechanismen mit robusten 163.8K-Kontextverarbeitungsfähigkeiten integriert; mit äußerst wettbewerbsfähigen Basispreisen dient es als Eckpfeiler für tägliche Arbeitsabläufe, einschließlich komplexer allgemeiner Schlussfolgerungen und der Erstellung von mehrstufigen Aufgabenplanungs-Agents. |
| DeepSeek V3.2 Speciale | DeepSeek V3.2 Speciale ist als leistungsstarkes, kundenspezifisches LLM positioniert und verfügt über ein massives 163,8K-Kontextfenster sowie eine erstklassige gestaffelte Preisstruktur ($0,4 Eingabe / $1,2 Ausgabe). Es wurde speziell für latenzkritische Kerngeschäftsknoten entwickelt, die höchste Ausgabequalität erfordern, wie z. B. intelligenter Kundenservice für vermögende Kunden oder quantitative Analysen im Millisekundenbereich. |
| DeepSeek V3.2 Exp | DeepSeek V3.2 Exp ist eine hochmoderne experimentelle Version, die auf der V3.2-Architektur basiert und die neuesten algorithmischen Funktionen integriert, während sie einen 163.8K-Kontext und vergleichbare Kosten beibehält. Dies macht sie ideal für F&E-Teams, die technische Voruntersuchungen und Canary-Tests durchführen, um die differenzierende Leistung von KI-Funktionen der nächsten Generation für zukünftige Produkte präventiv zu validieren. |
| DeepSeek-V3.1 | DeepSeek-V3.1 ist die neueste Generation von hochleistungsfähigen Open-Source-Ökosystemmodellen, die innerhalb eines 131.1K-Kontexts ein neues Gleichgewicht zwischen Leistung und Kosten erreicht; als erste Wahl für kommerzielle Implementierungsprojekte fungiert es als Rückgrat für Szenarien, die sowohl qualitativ hochwertige Generierung als auch kontrollierbare Kosten erfordern. |
| DeepSeek V3.1 Terminus | DeepSeek V3.1 Terminus dient als die langfristig stabile, ultimative Form der V3.1-Serie. DeepSeek V3.1 Terminus behält identische Parameter und Preise wie die Standardversion bei und zielt darauf ab, einen dauerhaft stabilen Ausgabestil und eine konsistente Logik für nahtlose, verbraucherorientierte Endpunktdienste in Produktionsumgebungen bereitzustellen. |
| DeepSeek-V3-0324 | DeepSeek-V3-0324 ist eine spezifische historische Snapshot-Version mit einem 131,1K-Kontext und den niedrigsten verfügbaren Texteingabekosten, die vor allem bei der Wartung von Altsystemen, die absolute Verhaltenskonsistenz erfordern, oder bei Stapelverarbeitungsaufgaben mit massivem Eingabedurchsatz, aber moderaten Anforderungen an die Ausgabelogik eingesetzt wird. |
| DeepSeek-R1-0528 | DeepSeek-R1-0528 ist als erstklassiges Deep-Reasoning-Modell positioniert, nutzt einen 131,1K-Kontext und verursacht die höchsten Rechenkosten ($0,55/$2,15). Es repräsentiert den Gipfel logisch-dialektischer Fähigkeiten und wird ausschließlich für kritische "Brainstorming"-Aufgaben wie komplexe mathematische Modellierung und die Generierung fortgeschrittener Code-Architekturen eingesetzt. |
| DeepSeek OCR | DeepSeek OCR ist ein dediziertes visuelles multimodales LLM, das Dual-Track-Bild-Text-Eingaben mit einem kurzen 8,2K-Kontext und extrem niedrigen Nutzungskosten unterstützt. Es ist perfekt an Szenarien für automatisierte Dateneingabe-Pipelines angepasst, wie z. B. die Digitalisierung massiver gescannter Dokumente und die strukturierte Extraktion von Finanzbelegen. |
Neue Funktionen von DeepSeek LLM Models + Showcase
Die Kombination fortschrittlicher Modelle mit der GPU-beschleunigten Plattform von Atlas Cloud bietet unübertroffene Geschwindigkeit, Skalierbarkeit und kreative Kontrolle für die Bild- und Videogenerierung.
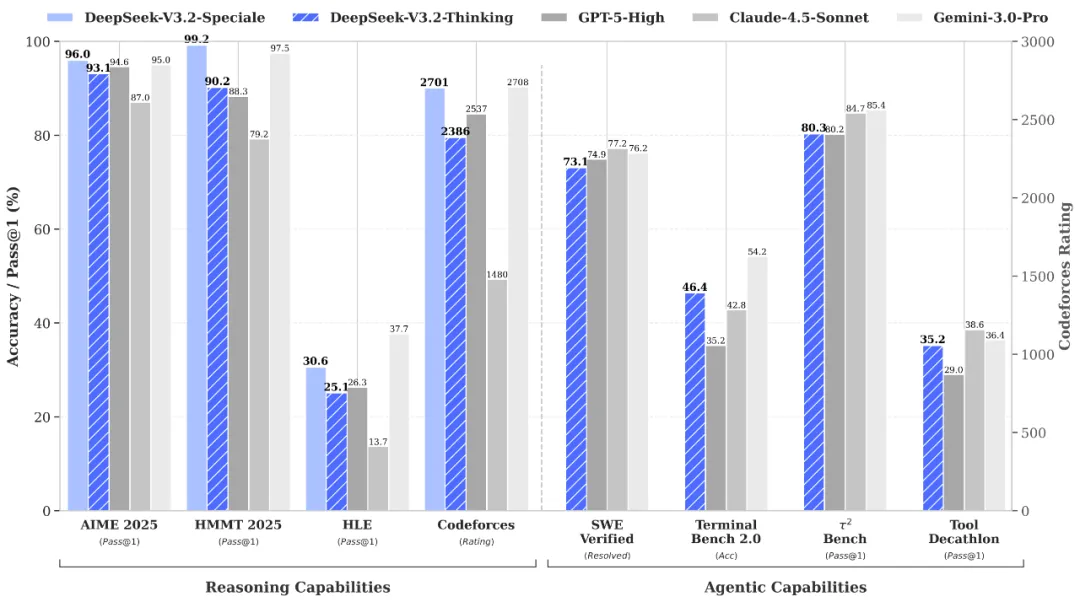
Weltklasse-Reasoning & Verifizierung über die DeepSeek-V3.2-Speciale API
DeepSeek-V3.2-Speciale is the "long-thought" enhanced variant of the V3.2 architecture, integrating advanced theorem-proving capabilities from DeepSeek-Math-V2. Engineered for extreme precision, this model excels in rigorous mathematical proofing, complex logical verification, and superior instruction following, rivaling the performance of Gemini-3.0-Pro in mainstream reasoning benchmarks. It is the premier choice for academic research, automated formal verification, and high-stakes technical problem-solving where logical integrity is non-negotiable.
Unübertroffene kognitive Tiefe via DeepSeek-R1 API
Das Modell DeepSeek-R1 steht an der Spitze der Reasoning-KI und liefert branchenführende Leistung in Mathematik, Programmierung und allgemeiner Logik. Durch das Erreichen der Gleichwertigkeit mit globalen Elite-Modellen wie OpenAIs o3 und Gemini-2.5-Pro hat R1 die Fähigkeiten der Open-Source-Intelligenz neu definiert. Es ist speziell für Aufgaben des tiefen Denkens optimiert, einschließlich komplexer Algorithmenentwicklung, anspruchsvoller Datensynthese und fortgeschrittener kognitiver Arbeitsabläufe, die mehrstufiges deduktives Denken erfordern.
Nahtlose tägliche Interaktion mit autonomen Agenten-Workflows unter Verwendung der DeepSeek V3.2 API
DeepSeek-V3.2 bietet die perfekte Balance zwischen Argumentationstiefe und Ausführungsgeschwindigkeit und wurde entwickelt, um nahtlose tägliche Interaktionen und autonome Agenten-Ökosysteme zu unterstützen. Mit deutlich reduzierter Latenz und optimierter Ausgabesteuerung dient es als robuster Motor für die Orchestrierung mehrstufiger Aufgaben und universelle KI-Assistenten. Ob bei der Bereitstellung von Automatisierung im Unternehmensmaßstab oder hochfrequenten interaktiven Tools – V3.2 sorgt für ein flüssiges, effizientes und kostengünstiges Benutzererlebnis.
Rigorose wissenschaftliche Entdeckung & formale Verifikation mit DeepSeek-V3.2-Speciale API
The DeepSeek-V3.2-Speciale API is engineered for tasks that demand absolute logical precision and multi-step reasoning. By integrating advanced theorem-proving capabilities, it enables researchers and engineers to execute complex mathematical inductions, verify formal logic, and solve high-tier competitive programming challenges. Perfect for academic R&D, automated code auditing, and cryptographic analysis, this API transforms abstract complexity into verifiable results with the performance of top-tier global models.
Advanced Algorithmic Synthesis & Strategic Reasoning using the DeepSeek-R1 API
DeepSeek-R1 empowers developers to build applications centered on deep cognitive workflows and strategic decision-making. Ranking at the forefront of global reasoning benchmarks, the R1 API excels in synthesizing sophisticated code architectures, processing dense technical documentation, and generating innovative solutions for open-ended logical puzzles. It is the ideal engine for AI-driven software engineering, long-form data synthesis, and any scenario where "thinking fast and slow" requires a powerful, reasoning-first foundation.
Nahtlose Orchestrierung autonomer Agenten mit der DeepSeek-V3.2 API
For high-velocity, sensory-driven AI applications, the DeepSeek-V3.2 API provides the perfect equilibrium between reasoning depth and ultra-low latency. It is optimized for building autonomous Agents that can navigate multi-step workflows, manage real-time user interactions, and execute general-purpose tasks with GPT-5 level intelligence. This use case is tailor-made for enterprise-scale automation, intelligent customer ecosystems, and developers looking to deploy responsive, cost-effective AI assistants at scale.
Modellvergleich
Sehen Sie, wie sich Modelle verschiedener Anbieter vergleichen — Leistung, Preise und einzigartige Stärken für eine fundierte Entscheidung.
| Modell | Kontext | Maximale Ausgabe | Eingabe | Positionierung |
|---|---|---|---|---|
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flaggschiff Allgemein |
| DeepSeek V3.2 Speciale | 163.84K | 163.84K | Text | Hochleistungs-Custom |
| DeepSeek V3.2 Exp | 163.84K | 163.84K | Text | Experimenteller Build |
| DeepSeek-V3.1 | 131.07K | 65.54K | Text | Open-Source-Backbone |
| DeepSeek V3.1 Terminus | 131.07K | 65.54K | Text | Langzeitstabil (LTS) |
| DeepSeek-V3-0324 | 131.07K | 32.77K | Text | Historische Momentaufnahme |
| DeepSeek-R1-0528 | 131.07K | 131.07K | Text | Erstklassiges Schlussfolgern |
| DeepSeek OCR | 8.19K | 8.19K | Text | Dediziertes Multimodal |
| GLM-5 | 200K | 128K | Text | Flaggschiff-Basismodell |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA agentisches Coding |
How to Use DeepSeek LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Warum DeepSeek LLM Models auf Atlas Cloud Verwenden
Die Kombination der fortschrittlichen DeepSeek LLM Models-Modelle mit der GPU-beschleunigten Plattform von Atlas Cloud bietet unübertroffene Leistung, Skalierbarkeit und Entwicklererfahrung.
Leistung & Flexibilität
Niedrige Latenz:
GPU-optimierte Inferenz für Echtzeit-Reasoning.
Einheitliche API:
Führen Sie DeepSeek LLM Models, GPT, Gemini und DeepSeek mit einer Integration aus.
Transparente Preisgestaltung:
Vorhersehbare Token-basierte Abrechnung mit serverlosen Optionen.
Unternehmen & Skalierung
Entwicklererfahrung:
SDKs, Analysen, Fine-Tuning-Tools und Vorlagen.
Zuverlässigkeit:
99,99% Verfügbarkeit, RBAC und compliance-bereite Protokollierung.
Sicherheit & Compliance:
SOC 2 Type II, HIPAA-Ausrichtung, Datensouveränität in den USA.
Häufig gestellte Fragen zu DeepSeek LLM Models
DeepSeek bietet Open-Source-Transparenz und überlegene Kosteneffizienz. Mit Reasoning-Fähigkeiten (R1 & V3.2), die mit GPT-5 konkurrieren, bietet es eine leistungsstarke, kostengünstigere Alternative mit der Flexibilität privater Bereitstellung.
Dies spiegelt die gesamte "Gehirnkapazität" des Modells wider. Das MoE-Design von DeepSeek kombiniert eine massive Gesamtparameterzahl (z. B. 671B) für tiefe Intelligenz mit einer optimierten "aktiven" Anzahl für maximale betriebliche Effizienz.
Weitere Familien Erkunden
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


