Introduction
Atlas Cloud is expanding its generative AI horizons with the imminent arrival of Qwen3-Max-Thinking.
- What it is: Developed by the Qwen team, this flagship model elevates the robust foundation of the Qwen family by introducing revolutionary Test-Time Scaling (TTS) and Native Agent architectures.
- Key Benefit: Whether it’s tackling math problems requiring deep logic, reconstructing objective truths from noisy social sentiment, or automating tasks that require the model to autonomously decide when to browse the web or write code, Qwen3-Max-Thinking delivers execution capabilities that exceed expectations.
- Status: Available now!
Qwen3-Max-Thinking is set to be the next game-changer in holistic AI generation. It marks a formal shift from "probabilistic generation" to "logical deduction and autonomous execution," giving you a trustworthy intelligent partner for your most challenging tasks.
Let’s dive into its three core technical breakthroughs to uncover the secrets behind its powerful "slow thinking" capability and how it redefines the limits of intelligence.
Core Breakthroughs: The Perfect Fusion of TTS and Native Agents
Deep Reasoning Architecture Based on Test-Time Scaling (TTS)
- Core Mechanism: Unlike traditional Majority Voting, Qwen3-Max-Thinking introduces Iterative Self-Improvement. During inference, the model "learns from experience" in previous steps, performing multiple rounds of self-reflection and path correction.
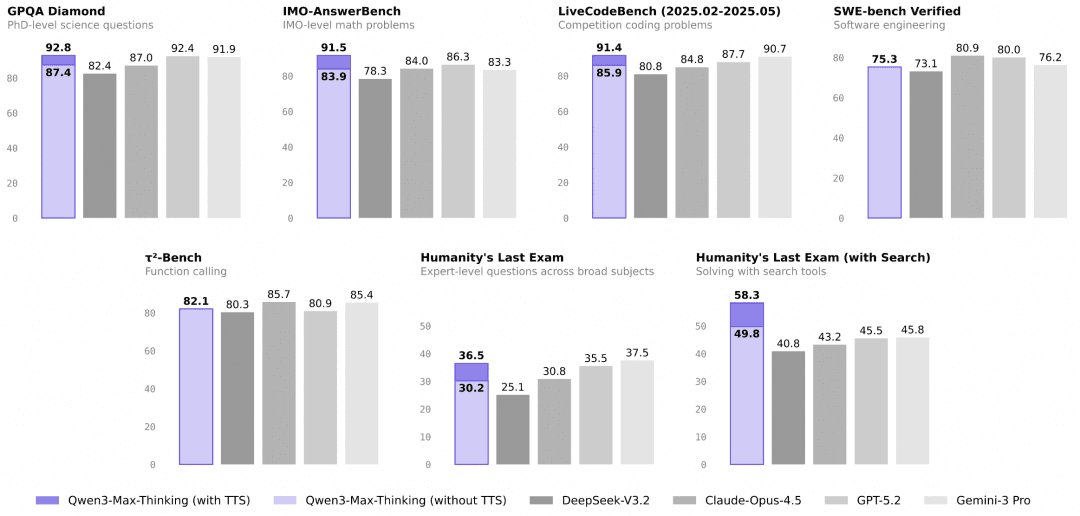
- The Effect: This "slow thinking" mechanism effectively prevents repetitive errors in difficult problems, significantly boosting accuracy in advanced mathematics (IMO-AnswerBench) and research-grade QA (GPQA Diamond). It represents a generational leap from probability to logic.
- Complex Fact "Denoising": It excels at filtering noise. In Reddit community tests involving historically noisy topics like the "2002 World Cup Controversy," Qwen3 utilized deep reasoning to filter out bias and cross-reference sources to reconstruct the objective truth—avoiding the hallucinations and bias parroting common in ordinary models.
Natively Integrated Adaptive Agent Capabilities
- Core Mechanism: The model is no longer a passive text generator but an executor with autonomous judgment. It proactively decides whether to "browse the web" for real-time info or call a "code interpreter" for precise calculations, seamlessly blending this process with its Chain of Thought (CoT).
- The Effect: This solves common "hallucination" and "calculation gap" issues, delivering high execution power in complex, multi-step tasks.
SOTA Performance Smashing Top Benchmarks
- Core Data: Trained on over 1 Trillion parameters and 36 Trillion tokens. Most notably, in the Humanity's Last Exam (HLE) benchmark, Qwen3-Max-Thinking scored a massive 58.3, leading GPT-5.2-Thinking (45.5) and Gemini 3 Pro (45.8) by over 10 points, proving its dominance in tool use and complex scenarios.
Summary: With comprehensive leaps in factual knowledge, complex reasoning, instruction following, human preference alignment, and agent capabilities, its performance across 19 authoritative benchmarks rivals current top-tier models like GPT-5.2-Thinking-xhigh, Claude Opus 4.5, and Gemini 3 Pro.
Applications: Unlocking "Expert-Level" AI Productivity in Three Scenarios
Benchmark numbers are impressive, but for Atlas Cloud developers, the real value lies in deployment. The following practical scenarios show how to utilize "deep reasoning" to solve problems where traditional models often fail.
"Zero Trial-and-Error" Complex System Refactoring
- The Pain Point: Developers often suffer through the "generate code -> run -> error -> feed error back -> regenerate" loop. On Atlas Cloud, Qwen3 uses its "deep reasoning" to mentally dry-run the code in its chain of thought before outputting it.
- Scenario: Refactoring Legacy Code
- Instead of just asking for comments on spaghetti code, you can command: "Analyze potential deadlock risks in this 10-year-old code and propose a refactoring plan based on modern async architecture. Explain why the new plan avoids the original race conditions."
- Thanks to Iterative Self-Improvement, it acts like a senior architect: deducing dependencies, spotting logic holes, and correcting its own plan internally before delivering a "runs-on-first-try" version to your Atlas Cloud terminal.
The True "Auto-Pilot" Data Analyst (Text-to-Insight)
- The Pain Point: Developers usually have to write tedious "glue code" to connect Search APIs, databases, and Python environments. Qwen3’s Native Agent capabilities turn this into a "black box delivery."
- Scenario: One-Sentence Market Report
- Input a fuzzy command: "Analyze Q3 2024 SE Asia e-commerce shifts and compare them with our internal sales data (CSV uploaded)."
- The model automatically deconstructs the task. You no longer need to define complex flowcharts like "If A then call Tool B." The model becomes an independent employee that knows how to find missing data, write Python scripts to clean it, fix its own coding errors, and present the final conclusion.
High-Precision Auditing and Decision Making in "Grey Areas"
- The Pain Point: In content moderation, legal consulting, or complex customer service, traditional RAG (Retrieval-Augmented Generation) often struggles when retrieved fragments contradict each other (noise), leading to incoherent answers. Qwen3’s "denoising" capability handles these grey areas effectively.
- Scenario: Handling Complex Disputes
- A user files a messy complaint: "The merchant says shipped, logistics says delivered, I didn't get it, and Platform Rule A conflicts with Rule B regarding refunds."
- Ordinary models robotically recite rules. Qwen3 acts like a judge: extracting timelines, identifying logical contradictions (denoising), and weighing context to decide which rule applies effectively. It generates a compliant yet empathetic resolution.
- For Atlas Cloud users, this means you can confidently automate "long-tail, high-difficulty tickets" via API, drastically reducing operational costs.
Guide: How to Use Qwen3-Max-Thinking on Atlas Cloud
Whether it’s refactoring code or making complex decisions, powerful capabilities are now at your fingertips. Now, let’s look at how to immediately enable this new flagship model on the Atlas Cloud platform with just a few simple steps.
Atlas Cloud lets you use models side by side — first in a playground, then via a single API.
Method 1: Use directly in the Atlas Cloud playground
Method 2: Access via API
Step 1: Get your API key
Create an API key in your console and copy it for later use.


Step 2: Check the API documentation
Review the endpoint, request parameters, and authentication method in our API docs.
Step 3: Make your first request (Python example)
Example: generate a video with Qwen3-Max-Thinking
plaintext1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "qwen/qwen3-max-2026-01-23", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "what is difference between http and https" 14 } 15 ], 16 "max_tokens": 16000, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())


