SOC I & II CERTIFIED | HIPAA COMPLIANT
© 2026 Atlas Cloud
Join the Discord community for the latest model updates, prompts, and support.
DeepSeek V4 Pro is a state-of-the-art large language model combining efficient sparse attention, strong reasoning, and integrated agent capabilities for robust long-context understanding and versatile AI applications.
DeepSeek V4 Flash is a state-of-the-art large language model combining efficient sparse attention, strong reasoning, and integrated agent capabilities for robust long-context understanding and versatile AI applications.

Tidak ada deskripsi tersedia.
Kimi K2.6 is an advanced large language model with strong reasoning and upgraded native multimodality. It natively understands and processes text and images, delivering more accurate analysis, better instruction following, and stable performance across complex tasks. Designed for production use, Kimi K2.6 is ideal for AI assistants, enterprise applications, and multimodal workflows that require reliable and high-quality outputs.
The latest Qwen reasoning model.
The latest Qwen reasoning model.
GLM-5.1 is Z.AI’s latest flagship model, featuring upgrades in two key areas: enhanced programming capabilities and more stable multi-step reasoning/execution. It demonstrates significant improvements in executing complex agent tasks while delivering more natural conversational experiences and superior front-end aesthetics.
MiniMax-M2.7 is a lightweight, state-of-the-art large language model optimized for coding, agentic workflows, and modern application development. With only 10 billion activated parameters, it delivers a major jump in real-world capability while maintaining exceptional latency, scalability, and cost efficiency.
Perpustakaan Model kami bukan hanya yang terbesar. Ini yang paling hemat biaya, andal, dan siap produksi. Kinerja terbukti, didukung oleh data.
Multimodal, open-source, proprietary: semua melalui satu endpoint konsisten.
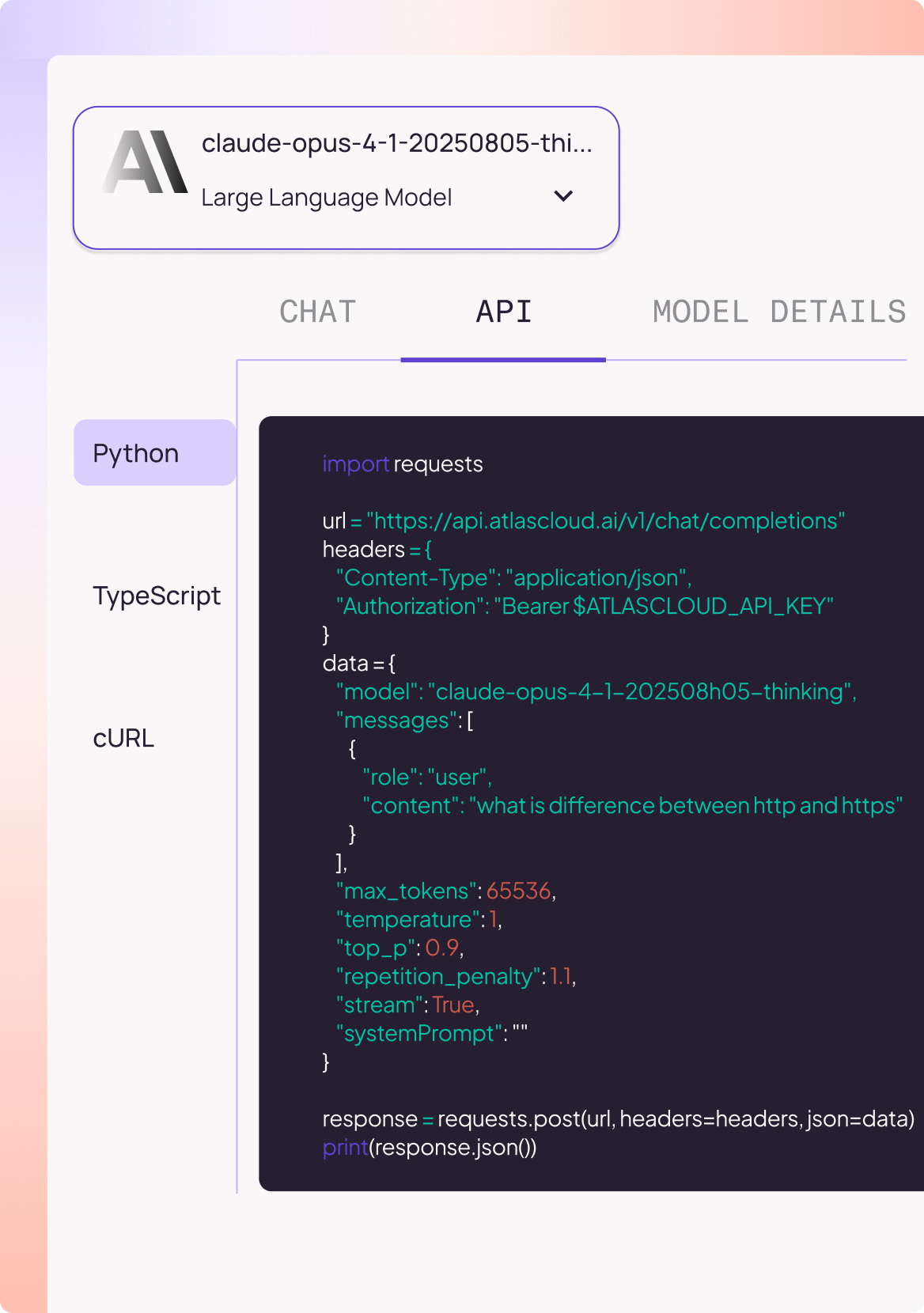
Mulai langsung dengan Python, TypeScript, atau cURL, tanpa perlu pengaturan infra.
10M+ panggilan API/bulan, stabilitas 70+ TPS, dideploy di 12 wilayah global.
Bayar sesuai penggunaan. Diskon enterprise hingga 50%.