프롬프트가 거부 벽에 부딪혔습니다. 유해해서가 아니라, 특정 키워드가 필터를 작동시켰기 때문입니다.
Ollama 커뮤니티의 개발자들은 이를 "거부 벡터(refusal vectors)"라고 부릅니다. 실제 유해성과는 무관하게 키워드에 의해 차단되는 현상이죠. 보안 연구를 위한 멀웨어 리버스 엔지니어링, 의료 사례 연구 문서화, 성인 콘텐츠 제작, 다크 픽션 집필 등이 이에 해당합니다. 주류 AI는 이 모든 것을 차단합니다. 이 리스트는 마케팅 문구가 아닌, 실제 커뮤니티 데이터를 바탕으로 2026년 최고의 검열 없는(uncensored) AI 모델 순위를 선정했습니다. 텍스트 및 코드용 검열 없는 LLM, 개인 하드웨어 배포를 위한 2026년 최고의 로컬 AI 모델, API를 통한 이미지 및 영상 생성을 위한 2026년 검열 없는 AI 모델 등 세 가지 카테고리를 다룹니다. 모든 수치는 2026년 5월 기준으로 출처와 날짜가 명시되어 있습니다.
광범위한 도구 환경에 대한 입문 정보는, 특정 모델을 선택하기 전 검열 없는 AI 이미지 생성기 가이드를 먼저 확인하면 유용합니다.
2026년 최고의 검열 없는 AI 모델 선정 방식
2026년에는 보도자료를 위해 선별된 벤치마크 점수보다 Ollama 커뮤니티의 다운로드 횟수가 실제 성능을 더 확실하게 보여주는 지표가 됩니다(Ollama, uncensored model search, 2026). 수백만 건의 풀(pull)은 수천 가지의 하드웨어 설정과 프롬프트 유형을 대변합니다. 이는 인위적인 평가 세트보다 훨씬 조작하기 어렵습니다.
본 기사에서는 세 가지 순위 기준을 사용했습니다. Ollama 검열 없는 모델의 경우, 2026년 5월 기준 ollama.com의 풀 횟수를 주 지표로 삼았습니다. OpenRouter 모델의 경우 풀 횟수가 공개되지 않아 파라미터 수와 컨텍스트 윈도우를 기준으로 순위를 매겼습니다. 이미지 및 영상 모델은 출력당 비용을 기준으로, 각 그룹 내에서 비용이 저렴한 순으로 나열했습니다.
대부분의 2026년 검열 없는 AI 모델은 파인튜닝(fine-tuned)과 애블리터레이션(abliterated)이라는 두 가지 기술적 범주에 속합니다. Dolphin 시리즈와 같은 파인튜닝 모델은 거부 행동을 강화하지 않는 데이터셋으로 학습됩니다. 애블리터레이션 모델은 거부 가중치를 외과적으로 제거한 모델입니다. 커뮤니티에서는 파인튜닝 모델이 다양한 프롬프트 유형에서 더 안정적이라고 평가합니다.
실제로 다운로드 횟수는 모델 안정성과도 상관관계가 있습니다. 100만 회 이상의 풀을 기록한 모델은 수많은 하드웨어 구성에서 테스트를 거쳤기에, 소규모 테스트 그룹이 놓치는 버그나 불안정성이 표면화된 상태입니다.
Ollama에서 가장 많이 다운로드된 검열 없는 모델 Top 5
2026년, 가장 많이 다운로드된 Ollama 검열 없는 모델 5종은 총 920만 회 이상의 풀을 기록했으며, llama2-uncensored가 260만 회로 선두를 달리고 있습니다(Ollama, uncensored model search, 2026). 이는 벤치마크가 아닌 커뮤니티 검증을 통해 선정된 2026년 최고의 Ollama 검열 없는 모델입니다. 사용자가 가장 먼저 확인하는 필터는 하드웨어 사양이며, VRAM 요구량은 4GB 미만에서 40GB까지 다양합니다.
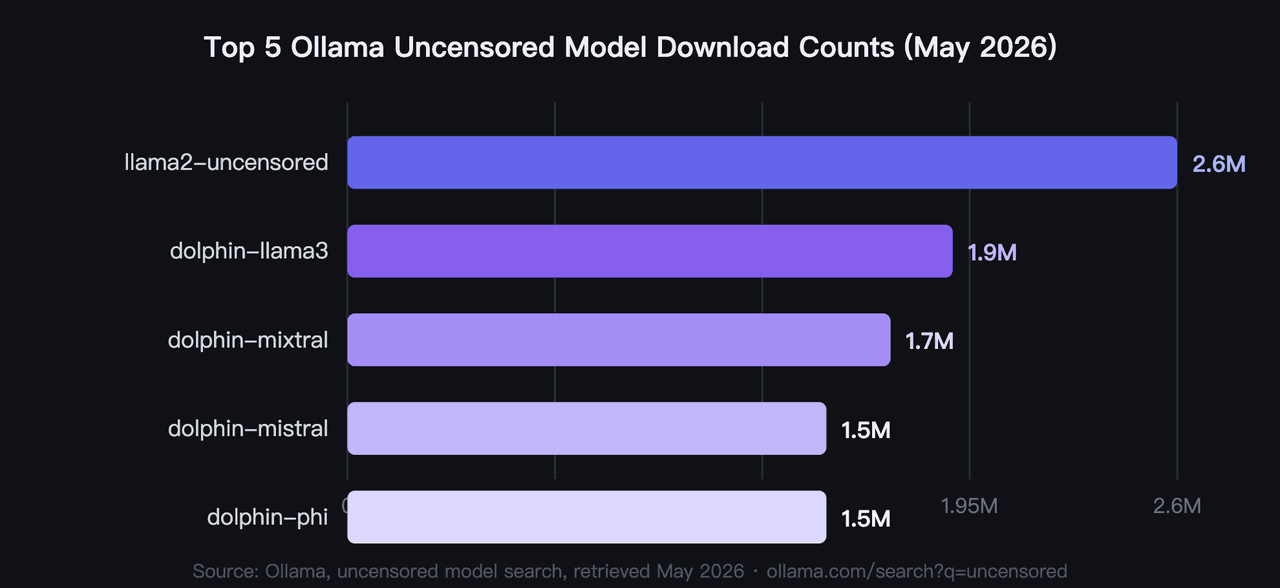
1. llama2-uncensored: Ollama에서 가장 많이 다운로드된 검열 없는 AI 모델
검열 없는 로컬 AI의 오리지널 커뮤니티 벤치마크입니다. George Sung과 Jarrad Hope가 Llama 2의 일반적인 성능을 저하시키지 않으면서 거부 행동만 제거하기 위해 내놓은 파인튜닝 모델입니다. 대부분의 개발자가 시작하는 모델이며, 260만 회의 풀 횟수는 2년 이상의 실제 사용 경험을 반영합니다. 이 정도 다운로드 볼륨을 기록한 검열 없는 LLM은 없습니다.
- 파라미터: 7B 또는 70B
- VRAM: 약 6GB (7B); 약 40GB (70B)
- 용도: 범용 비제한 채팅 및 콘텐츠 생성
- 플랫폼: Ollama
2. dolphin-llama3: 에이전트 워크플로우를 위한 최고의 검열 없는 Llama 3 LLM
Llama 3 기반의 Eric Hartford표 Dolphin 모델은 최신 아키텍처를 기반으로 한 모델 중 가장 많은 190만 회의 풀을 기록했습니다(Ollama, dolphin-llama3 model page, 2026). 함수 호출(function calling)을 지원하며 설정에 따라 8K에서 256K 토큰까지의 컨텍스트 윈도우를 제공합니다. 8B 버전은 4.7GB로 대부분의 중급 소비자용 GPU에 적합합니다.
- 파라미터: 8B 또는 70B
- VRAM: 약 5GB (8B); 약 40GB (70B)
- 용도: 코딩, 에이전트 워크플로우, 함수 호출
- 플랫폼: Ollama
3. dolphin-mixtral 8x7B: 복합 추론을 위한 검열 없는 MoE AI 모델
전문가 혼합(MoE) 아키텍처를 사용하여 각 토큰을 8개의 전문가 레이어 중 일부를 통해 라우팅합니다. 이는 동일한 파라미터 수의 밀집(dense) 모델보다 낮은 추론 비용으로 70B급의 추론 품질을 제공합니다. Eric Hartford의 파인튜닝은 코딩에 강점을 둡니다.
- 파라미터: 8x7B (추론 패스당 활성 파라미터는 전체보다 훨씬 적음)
- VRAM: 양자화 적용 시 약 12-16GB
- 용도: 복잡한 코딩 작업, 기술적 추론, 긴 명령 체인
- 플랫폼: Ollama
4. dolphin-mistral: 빠른 응답을 위한 검열 없는 7B 로컬 AI 모델
CPU 기반 하드웨어에서 dolphin-mixtral보다 가볍고 빠릅니다. 고사양 GPU 없이 코드 완성을 위한 반응성 좋은 로컬 모델을 원하는 개발자들에게 150만 회의 선택을 받았습니다. Mistral 기반 아키텍처는 7B 모델로서 우수한 성능 대비 크기 비율을 제공합니다.
- 파라미터: 7B
- VRAM: 약 5-6GB
- 용도: 가벼운 코딩 지원 및 빠른 채팅 응답
- 플랫폼: Ollama
5. dolphin-phi 2.7B: 가장 가벼운 검열 없는 로컬 AI 모델
Microsoft의 Phi 기반 아키텍처는 2.7B 파라미터 안에 유능한 추론 능력을 담았습니다. Eric Hartford의 파인튜닝은 그 효율성을 보존합니다. 4GB 미만의 VRAM으로도 외장 GPU가 있는 대부분의 노트북에서 실행 가능하여, 2026년 최고의 로컬 AI 모델 입문용으로 적합합니다.
- 파라미터: 2.7B
- VRAM: 4GB 미만
- 용도: 노트북 배포, 빠른 테스트, 하드웨어 제약 환경
- 플랫폼: Ollama
검열 없는 LLM 모델 6~10위: 코딩, 역할극, 긴 컨텍스트
2026년 현재, Dolphin 시리즈는 Ollama 검열 없는 모델 카탈로그 상위 10위권 중 5개를 차지하고 있으며, 이는 서로 다른 기본 아키텍처에 적용된 Eric Hartford의 일관된 파인튜닝 방법론을 보여줍니다(Ollama, hermes3 model page, 2026). 6위에서 10위 모델들은 주류 AI의 거부 반응으로 방해받기 쉬운 역할극, 일반 대화, 개발자 도구, 지시 따르기, 확장된 컨텍스트를 다룹니다.
6. hermes3: 역할극 및 에이전트 작업을 위한 검열 없는 AI 모델
Nous Research는 역할극의 깊이와 구조화된 도구 사용을 위해 hermes3를 제작했습니다. 3B부터 405B까지 4가지 크기로 제공되어 본 리스트 중 가장 폭넓은 선택지를 제공합니다. 130만 회의 풀을 기록한 8B 변형 모델은 창작과 에이전트 플래닝 워크플로우에 실용적입니다(Ollama, hermes3 model page, 2026).
- 파라미터: 3B, 8B, 70B, 또는 405B
- VRAM: 약 2GB (3B); 약 5GB (8B); 약 40GB (70B)
- 용도: 역할극, 창작, 에이전트 작업 계획
- 플랫폼: Ollama
7. wizard-vicuna-uncensored: 범용 다중 크기 AI 모델
Llama 2 기반의 검증된 모델로, 최대 30B까지 3가지 크기로 제공됩니다. 120만 회의 풀은 폭넓은 파라미터 선택이 가능한 신뢰할 수 있는 모델을 찾는 사용자들로부터 기인합니다. dolphin-llama3의 컨텍스트 윈도우 성능에는 미치지 못하지만, 일반 대화와 창작 콘텐츠 처리에 일관적입니다.
- 파라미터: 7B, 13B, 또는 30B
- VRAM: 약 5GB (7B); 약 9GB (13B); 약 20GB (30B)
- 용도: 다양한 크기 옵션을 통한 범용 대화 및 창작 콘텐츠
- 플랫폼: Ollama
8. dolphincoder: StarCoder2 기반의 검열 없는 AI 코딩 모델
StarCoder2를 기반으로 하여 dolphincoder는 전문성을 띱니다. 다른 Dolphin 모델들이 검열이 제거된 범용 모델이라면, 이 모델은 소프트웨어 개발을 타겟으로 합니다. 94만 3천 회의 풀은 창작 사용자가 아닌 개발자들로부터 나왔습니다. 15B 버전은 7B보다 더 큰 코드베이스를 처리합니다.
- 파라미터: 7B 또는 15B
- VRAM: 약 5GB (7B); 약 10GB (15B)
- 용도: 코드 생성, 디버깅, 기술 문서 작성
- 플랫폼: Ollama
9. wizardlm-uncensored: 연구 워크플로우용 지시 따르기 LLM
61만 회의 풀을 가진 13B 지시 따르기 모델입니다. 복잡한 다단계 지시를 거부 없이 수행하는 데 강점이 있습니다. 거부 한 번이 긴 체인을 깨뜨릴 수 있는 연구 워크플로우에서 이러한 신뢰성은 직접적인 생산성 가치를 갖습니다. 최신 dolphin-llama3와 같은 베이스는 아니지만 지시 이행 작업은 일관되게 수행합니다.
- 파라미터: 13B
- VRAM: 약 9GB
- 용도: 복잡한 다단계 지시 체인 및 연구 워크플로우
- 플랫폼: Ollama
10. everythinglm: 16K 컨텍스트 윈도우를 갖춘 검열 없는 LLM
가장 두드러진 특징은 Llama 2 기반의 16K 컨텍스트 윈도우입니다. 대부분의 7B 모델은 4K 또는 8K 토큰이 한계입니다. 이 추가적인 컨텍스트를 통해 everythinglm은 전체 코드베이스, 긴 문서, 긴 대화 기록을 잘림 없이 처리할 수 있습니다. 53만 6천 회의 풀 기록은 이 리스트의 기준치치고는 작지만, 다른 모델들이 다루지 않는 영역을 채워줍니다.
- 파라미터: 13B
- VRAM: 약 9GB
- 용도: 긴 문서 분석, 확장 컨텍스트 채팅, 전체 코드베이스 검토
- 플랫폼: Ollama
Ollama 다운로드 수에서 Dolphin 시리즈의 압도적인 우세는 커뮤니티가 기록한 패턴을 반영합니다: 단일 작성자가 일관된 방법론으로 제작한 파인튜닝 모델이 일회성 애블리터레이션보다 성능이 우수하다는 것입니다. 애블리터레이션은 단일 모델에서 거부 가중치를 제거하지만, 파인튜닝은 다양한 프롬프트 유형에서 안정적인 행동을 구축합니다. 이것이 Eric Hartford의 모델들이 10위권 중 5개를 차지하는 이유입니다.
로컬에서 Ollama 검열 없는 모델을 설치하는 방법은?
2026년, Mac, Linux 또는 Windows에서 Ollama 모델을 설치하는 명령어는 세 단계입니다: ollama.com에서 Ollama 설치, ollama pull [model-name] 실행, ollama run [model-name] 실행(Ollama 문서, 2026). API 키는 필요 없으며 외부 콘텐츠 조정도 적용되지 않습니다. 프롬프트는 하드웨어를 벗어나지 않습니다.
dolphin-llama3를 예로 들면, ollama pull dolphin-llama3가 4.7GB 8B 파일을 다운로드하고, ollama run dolphin-llama3가 인터랙티브 프롬프트를 엽니다. 전체 추론 과정은 로컬 GPU나 CPU에서 실행됩니다.
터미널보다 GUI를 선호하는 사용자를 위해 LM Studio가 있습니다. 이는 Ollama가 사용하는 것과 동일한 GGUF 모델 파일을 사용하며 모델 선택과 파라미터 조정을 위한 시각적 인터페이스를 제공합니다. llama.cpp는 이 두 도구의 기본 추론 엔진으로, 양자화 레벨과 컨텍스트 길이를 더 정밀하게 제어해야 할 때 직접 명령줄 사용을 지원합니다.
소비자용 GPU에서 2026년 최고의 검열 없는 로컬 AI 모델을 구동하기 위한 하드웨어 요구사항과 양자화 설정을 원하는 개발자들은 전체 로컬 설정 가이드에서 최소 VRAM 구성과 흔한 오류를 상세히 확인할 수 있습니다.
로컬 GPU 없이 사용할 수 있는 OpenRouter 검열 없는 모델은?
2026년, OpenRouter는 API를 통해 검열 없는 LLM을 호스팅하여 GPU 요구사항을 완전히 제거합니다. venice/uncensored 모델은 100만 입력 및 출력 토큰당 0달러의 무료 티어로 이용 가능합니다(OpenRouter, venice/uncensored model page, 2026). 이는 전용 하드웨어가 없는 사용자들에게 실용적인 진입점이 됩니다.
대가는 간단합니다. OpenRouter가 프롬프트를 인프라를 통해 라우팅하므로, 로컬 모델처럼 대화가 완벽히 비공개는 아닙니다. 로컬 Ollama 모델은 모든 데이터를 기기에 보관합니다. 두 방식 모두 장단점이 있으며, 위협 모델과 하드웨어 가용성에 따라 선택이 달라집니다.
11. venice/uncensored: 무료 검열 없는 OpenRouter 모델
OpenRouter 무료 티어의 Venice Uncensored 모델입니다. 24B Mistral-Small 기반으로 Venice.ai와 협업하여 Cognitive Computations가 검열 없이 파인튜닝했습니다. 32K 컨텍스트 윈도우, 토큰당 0달러입니다. OpenRouter 무료 티어는 플랫폼 전체에서 하루 200회 요청 제한을 적용합니다.
- 파라미터: 24B
- VRAM: 필요 없음 (클라우드 호스팅)
- 용도: 로컬 하드웨어 없이 검열 없는 LLM 테스트; 플랫폼 제한 내 무료
- 플랫폼: OpenRouter
12. Sao10K: Llama 3.3 Euryale 70B: OpenRouter를 통한 대규모 검열 없는 모델
Sao10k가 제작한 70B 크기의 창작 역할극 및 지시 이행 모델입니다. 131K 컨텍스트를 가진 Llama 3.3 70B 기반입니다. OpenRouter에서 활발히 사용되고 있으며 플랫폼 내 전역 검색으로 찾을 수 있습니다.
- 파라미터: 70B
- VRAM: 필요 없음 (클라우드 호스팅)
- 용도: 로컬 하드웨어 없이 복잡한 창작, 역할극, 긴 지시 체인
- 플랫폼: OpenRouter
13. Sao10K: Llama 3 8B Lunaris: OpenRouter를 통한 경량 검열 없는 모델
Lunaris 8B는 Llama 3 8B 기반의 다재다능한 범용 및 역할극 모델입니다. 창의성과 논리력, 일반 지식의 균형을 맞추기 위해 여러 모델을 전략적으로 합쳤으며, Stheno v3.2보다 뛰어난 창의성과 추론 능력을 제공합니다. OpenRouter에서 토큰당 0.04/0.05달러라는 가장 저렴한 옵션이며, 플랫폼 내 60억 토큰 이상의 실사용 기록을 가지고 있습니다.
- 파라미터: 8B
- VRAM: 필요 없음 (클라우드 호스팅)
- 용도: 최소 비용으로 즐기는 경량 검열 없는 대화 및 창작
- 플랫폼: OpenRouter
14. TheDrummer: Cydonia 24B V4.1: OpenRouter를 통한 검열 없는 창작 모델
Cydonia 24B V4.1은 Mistral Small 3.2 24B 기반의 검열 없는 창작 모델입니다. 훌륭한 회상 능력과 프롬프트 준수력, 지능을 갖췄으며 131K 컨텍스트 윈도우를 지원합니다.
- 파라미터: 24B
- VRAM: 필요 없음 (클라우드 호스팅)
- 용도: 로컬 하드웨어 없이 검열 없는 창작 및 역할극
- 플랫폼: OpenRouter
Atlas Cloud를 통해 검열 없는 이미지 및 영상 모델에 접속하는 방법
2026년, 대부분의 검열 없는 이미지 및 영상 모델은 메인스트림 클라우드 제공업체가 추론 레벨에서 NSFW 출력을 차단하기 때문에 로컬 GPU 하드웨어 또는 전용 API 플랫폼이 필요합니다. Atlas Cloud는 텍스트, 이미지, 영상, 오디오 전반에 걸쳐 300개 이상의 선별된 모델을 제공하며 그 제약을 제거하기 위해 구축된 모델 API 플랫폼입니다.
시작하는 3단계:
- atlascloud.ai에서 계정 생성
- 대시보드에서 API 키 생성
- 키를 사용하여 모델 엔드포인트 호출 — 이미지 및 영상 모델은 자체 REST 형식을 사용하며, LLM 엔드포인트는 OpenAI Chat Completions 형식을 따릅니다.
검열 없는 환경에서 Atlas Cloud가 가지는 가치:
- 플랫폼 개인정보 보호정책: "생성된 콘텐츠는 학습에 절대 사용되지 않으며, 누구에게도 검토되지 않습니다." 이는 기본 가정치가 아니라 명시된 약속입니다.
- 카탈로그 내 어떤 모델에도 일일 생성 제한이 없습니다.
- 검열 없는 이미지 카탈로그는 33개의 텍스트-투-이미지 모델을 이미지당 0.003달러부터 제공합니다.
- 검열 없는 영상 카탈로그는 10개 이상의 NSFW 영상 모델을 초당 0.01달러부터 제공합니다.
전체 모델 카탈로그는 Uncensored AI에서 확인할 수 있습니다. 본 리스트의 15번부터 20번 모델은 단일 Atlas Cloud API 키를 통해 액세스할 수 있습니다.
NSFW 및 성인 콘텐츠 생성을 위한 최고의 검열 없는 AI 이미지 모델
2026년, FLUX 아키텍처는 고품질 검열 없는 이미지 생성의 주류이며, Atlas Cloud API를 통해 가격 및 품질 티어별로 제공됩니다(Atlas Cloud, text-to-image model list, 2026). 사용 사례에는 순수 예술, 캐릭터 디자인, 검열 없는 란제리 모델 및 성인 초상화 생성, 게임 에셋 제작, 대량 일러스트레이션 등이 포함됩니다.
best uncensored NSFW AI image generators guide에서는 브라우저 기반 및 API 검열 없는 이미지 도구들을 비교했습니다. FLUX 아키텍처에 집중하는 개발자들은 FLUX 검열 없는 이미지 생성기 가이드를 통해 파인튜닝 및 워크플로우 상세 정보를 확인할 수 있습니다.
15. FLUX Schnell: 대량 생성을 위한 가장 빠른 검열 없는 AI 이미지 모델
Atlas Cloud 이미지 카탈로그에서 가장 저렴한 옵션입니다. 이미지당 0.003달러로, 디테일보다 속도와 볼륨이 중요한 배치 생성 워크플로우에 적합합니다. 일일 제한은 없으며, 학습을 위해 저장되는 콘텐츠도 없습니다.
- 가격: 이미지당 0.003달러
- VRAM: 필요 없음 (API 접속)
- 용도: 배치 이미지 생성, 빠른 프로토타이핑, 대용량 검열 없는 출력
- 플랫폼: Atlas Cloud API
이미지당 0.003달러라면 3달러로 1,000장의 이미지를 생성할 수 있습니다. 이는 대부분의 서비스에서 결과 파일을 저장하는 클라우드 스토리지 비용보다 저렴합니다. 이는 과거 밤새 비싼 로컬 GPU를 돌리던 스튜디오의 경제성을 완전히 뒤바꾸어, 이제는 API 방식이 대량 작업에 더 저렴하고 빠릅니다.
16. FLUX Dev: 최종 프로덕션을 위한 최고 품질의 검열 없는 AI 이미지 모델
FLUX Schnell 가격의 4배이지만, 해부학, 조명, 텍스처 디테일이 눈에 띄게 좋습니다. 개별 이미지의 품질이 중요한 최종 작업의 경우 이미지당 0.012달러는 합리적인 선택입니다. 포트폴리오, 상업적 성인 콘텐츠, 제작 에셋에 적합합니다.
- 가격: 이미지당 0.012달러
- VRAM: 필요 없음 (API 접속)
- 용도: 고품질 단일 이미지, 포트폴리오, 최종 프로덕션 에셋
- 플랫폼: Atlas Cloud API
17. FLUX Dev LoRA: 사용자 지정 스타일 학습이 가능한 검열 없는 이미지 모델
LoRA 파인튜닝은 FLUX Dev 베이스에 사용자 지정 스타일, 캐릭터 외형, 피사체를 삽입합니다. 배치 간 캐릭터 일관성이 필요하거나 세트 내 모든 이미지에 하우스 스타일을 적용하고 싶을 때 사용하는 모델입니다. Atlas Cloud가 서버 측에서 LoRA 로딩을 처리합니다.
- 가격: 이미지당 0.015달러
- VRAM: 필요 없음 (API 접속)
- 용도: 캐릭터 일관성, 사용자 지정 스타일 학습, 브랜드 이미지 시리즈
- 플랫폼: Atlas Cloud API
18. Z-Image Turbo: 미드 티어 품질의 보급형 검열 없는 AI 이미지 모델
가격과 품질 곡선에서 FLUX Schnell과 FLUX Dev 사이에 위치합니다. 이미지당 0.01달러인 Z-Image Turbo는 Schnell의 낮은 가격에서 발생하는 이미지 단순화 없이 속도에 최적화된 아키텍처를 제공합니다. Schnell의 품질이 부족하고 FLUX Dev 비용이 부담될 때의 현실적인 선택지입니다.
- 가격: 이미지당 0.01달러
- VRAM: 필요 없음 (API 접속)
- 용도: 품질과 비용의 균형이 필요한 중간 규모 생성
- 플랫폼: Atlas Cloud API
2026년 NSFW 애니메이션을 위한 최고의 검열 없는 AI 영상 모델
2026년, 검열 없는 영상 생성은 이미지 생성과는 분리된 파이프라인이 필요합니다. 주류 영상 플랫폼은 이미지 생성 시 사용된 출처와 무관하게 동일한 콘텐츠 필터를 적용해 NSFW 콘텐츠를 애니메이션화하는 것을 거부하기 때문입니다(Atlas Cloud, uncensored model catalog, 2026).
19. Wan 2.2 Turbo Spicy Infinite I2V: 가장 저렴한 검열 없는 영상 모델
정지 이미지에서 NSFW 애니메이션을 만드는 입문용 옵션입니다. 초당 0.01달러로 가장 비용 효율적입니다. 해상도는 1080p에 도달하며 가변적인 클립 시간을 지원하여 예산을 중시하는 프로덕션 파이프라인의 시작점으로 적합합니다.
- 가격: 초당 0.01달러
- 해상도: 1080p
- 시간: 가변적
- 용도: 비용 효율적인 NSFW 애니메이션 및 동작 개념 미리보기
- 플랫폼: Atlas Cloud API
20. Seedance v1.5 Spicy: 최종 출력을 위한 최고 품질의 검열 없는 영상 모델
카탈로그 내 시네마틱 품질 옵션입니다. 초당 0.049달러로 Wan 2.2 Turbo Spicy Infinite보다 약 2.5배 비싸지만, 더 부드러운 움직임, 프레임 간 피사체 일관성, 자연스러운 전환을 제공합니다. 시각적 충실도가 최우선인 최종 품질 NSFW 영상 출력을 위한 최고의 옵션입니다.
- 가격: 초당 0.049달러
- 해상도: 720p
- 시간: 5초
- 용도: 최종 품질 NSFW 영상, 전문가용 성인 콘텐츠
- 플랫폼: Atlas Cloud API
검열 없는 AI 모델 요약 선택 가이드
| 필요 사항 | 추천 모델 |
|---|---|
| 최고의 전체 검열 없는 LLM | llama2-uncensored 또는 dolphin-llama3 |
| 코딩 작업 | dolphin-mixtral 8x7B 또는 dolphincoder |
| 역할극 및 창작 | hermes3 |
| 4GB VRAM 미만 | dolphin-phi 2.7B |
| 검열 없는 이미지 생성 | Atlas Cloud를 통한 FLUX Schnell (이미지당 $0.003) |
| 이미지 기반 NSFW 영상 | Atlas Cloud를 통한 Wan 2.2 Turbo Spicy Infinite (초당 $0.01) |
검열 없는 AI 모델 FAQ
2026년 가장 검열 없는 AI 모델은 무엇입니까?
Ollama 다운로드 수 기준 260만 회를 기록한 llama2-uncensored가 커뮤니티에서 가장 검증된 옵션입니다(Ollama, uncensored model search, 2026). 순수 성능 면에서는 함수 호출, 최대 256K 컨텍스트, Llama 3 기반 아키텍처를 제공하는 dolphin-llama3가 더 뛰어납니다. 사용 사례에서 검증된 안정성이 중요한지, 최신 기능이 중요한지에 따라 달라집니다.
Ollama에서 실행되는 검열 없는 모델은 무엇입니까?
본 리스트 중 10개 모델이 Ollama에서 실행됩니다: llama2-uncensored, dolphin-llama3, dolphin-mixtral, dolphin-mistral, dolphin-phi, hermes3, wizard-vicuna-uncensored, dolphincoder, wizardlm-uncensored, everythinglm. 커뮤니티 모델인 jaahas/qwen3.5-uncensored 또한 다국어 용도로 사용 가능합니다. 모두 ollama pull [model-name]으로 설치됩니다.
OpenRouter에서 사용 가능한 검열 없는 모델은 무엇입니까?
OpenRouter는 API를 통해 검열 없는 LLM을 호스팅합니다. 100만 토큰당 0달러의 무료 티어 venice/uncensored 모델을 포함하여, Sao10K Euryale 70B, Lunaris 8B, TheDrummer Cydonia 24B 등의 유료 모델을 이용할 수 있습니다. 이 모델들은 로컬 GPU가 필요 없습니다.
애블리터레이션(abliterated)과 파인튜닝된 검열 없는 모델의 차이는 무엇입니까?
애블리터레이션은 모델의 가중치 레벨에서 거부 가중치를 외과적으로 제거합니다. 반면 Dolphin 시리즈와 같은 파인튜닝된 검열 없는 모델은 애초에 거부 행동을 강화하지 않는 데이터셋으로 학습됩니다. 커뮤니티에서는 파인튜닝 모델이 더 안정적이라고 평가합니다: 애블리터레이션은 다양한 프롬프트 유형에서 일관되지 않은 출력을 보일 수 있는 반면, 파인튜닝은 안정적인 결과를 냅니다. 이것이 Dolphin 모델이 Ollama 검열 없는 모델 순위를 점령한 이유입니다.
노트북에서 로컬로 검열 없는 AI 모델을 실행할 수 있습니까?
네. dolphin-phi 2.7B는 4GB VRAM 미만에서 실행되므로 외장 GPU가 있는 노트북에서 입문하기 좋습니다. 6~8GB VRAM이 있다면 본 리스트의 모든 7B 모델을 실행할 수 있습니다. 내장 그래픽은 작동하지 않습니다.
결론
2026년 최고의 검열 없는 AI 모델은 사용자의 목적에 따라 다릅니다. 일반 LLM 작업에는 dolphin-llama3, 노트북에는 dolphin-phi, 하드웨어 없이 클라우드 접근을 원하면 OpenRouter의 venice/uncensored 무료 티어를 권장합니다. 대규모 이미지 생성에는 Atlas Cloud API를 통한 FLUX Schnell이 이미지당 0.003달러로 적합하며, NSFW 영상에는 Atlas Cloud 카탈로그가 학습 및 검토 없는 정책으로 초당 0.01달러부터 시작합니다.






