
몇 달 전, 우리는 기만적일 정도로 간단한 목표를 세웠습니다. 단일 GPU에서 1분 미만의 연산 시간으로 15초 이상의 고품질 일관성 있는 영상을 생성하는 것입니다. Wan2.2와 같은 오늘날의 영상 확산 모델은 3~5초 길이의 클립 생성에는 능숙합니다. 하지만 이를 10초, 30초, 또는 1분으로 확장하는 지점이 바로 흥미로운 도전이 시작되는 곳입니다.
이 게시물은 우리가 실제로 선택한 경로를 기록합니다. 우리는 TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk, Helios와 같이 최근 논문과 기술 보고서에 등장한 6가지 접근 방식을 조사하고, 각 방식의 장단점을 측정했습니다. 최종적으로 우리는 DiffSynth Engine에서 TurboWan과 결합된 SVI(Stable Video Infinity)를 선택했습니다. 이 글에서는 각 경로를 살펴본 뒤 SVI의 작동 원리와 실제 운영 지표를 공유하겠습니다.
긴 영상 생성이 어려운 이유
5초가 넘어가면 크게 세 가지 문제가 발생합니다.
VRAM 한계
Wan2.2는 잠재 토큰 수에 대해 O(n²)의 비용이 발생하는 Full Attention을 사용합니다. 수학적 한계는 냉혹합니다.
5초 (81 프레임): 약 32.7k 토큰, 어텐션 행렬 약 10 GB.
10초 (165 프레임): 약 65.5k 토큰, 어텐션 행렬 약 40 GB — 이미 단일 GPU 용량을 초과하기 시작합니다.
30초 (약 500 프레임): 약 200k 토큰, 구현 불가능.
실제로 Self Forcing만으로도 KV 캐시를 위해 165 프레임에서 H200의 129 GB VRAM 대부분을 차지합니다.
시간적 드리프트(Temporal drift)
메모리 문제가 해결되더라도 세 가지 형태의 드리프트가 나타납니다. Helios 논문에서는 이를 위치 이동(position shift) (피사체가 프레임 내에서 배회함), 색상 이동(color shift) (색조와 밝기가 점진적으로 변함), 복원 이동(restoration shift) (모델이 과도하게 보정하여 시각적 불연속성을 생성함)으로 정의했습니다.
인과적 일관성(Causal consistency)
표준 영상 확산 모델은 양방향(bidirectional) Full Attention을 사용하므로 모든 프레임이 서로를 참조합니다. 즉, 프레임 N이 완료될 때까지 프레임 1을 보여줄 수 없어 실시간 스트리밍이 불가능합니다.
우리의 구체적인 목표는 소박했습니다. 15초 이상의 영상, 매끄러운 시각적 연속성, 전체 클립에 걸친 안정적인 피사체 유지, 60초 미만의 총 대기 시간, 최소한의 학습, 그리고 기존 가중치 재사용을 우선시하는 것이었습니다.
조사 결과
우리는 6가지 계열을 살펴보았습니다. 이름은 주로 논문 제목에서 따왔으며, 범주는 나중에 중요해집니다.
경로 1 · TTT (Test-Time Training)
논문: One-Minute Video Generation with Test-Time Training (arXiv 2504.05298, 2025년 4월).
핵심 아이디어는 추론 과정에서 모델을 파인튜닝하여 이미 생성된 내용을 기억하게 하는 것입니다. 모든 Transformer 블록의 Attention 뒤에 작은 TTT 레이어(2계층 MLP, 게이트, 로컬 어텐션)를 삽입하고, 짧은 클립에서 1분 전체 영상으로 이어지는 커리큘럼으로 모델을 학습시킵니다.
블록별 삽입: 표준 어텐션 뒤에 게이트, TTT 레이어, 로컬 어텐션을 삽입하고 LayerNorm을 추가합니다.
커리큘럼: 3초 → 9초 → 18초 → 30초 → 60초로 점진적으로 긴 윈도우에서 학습합니다.
비용: H100 256대로 약 50시간.
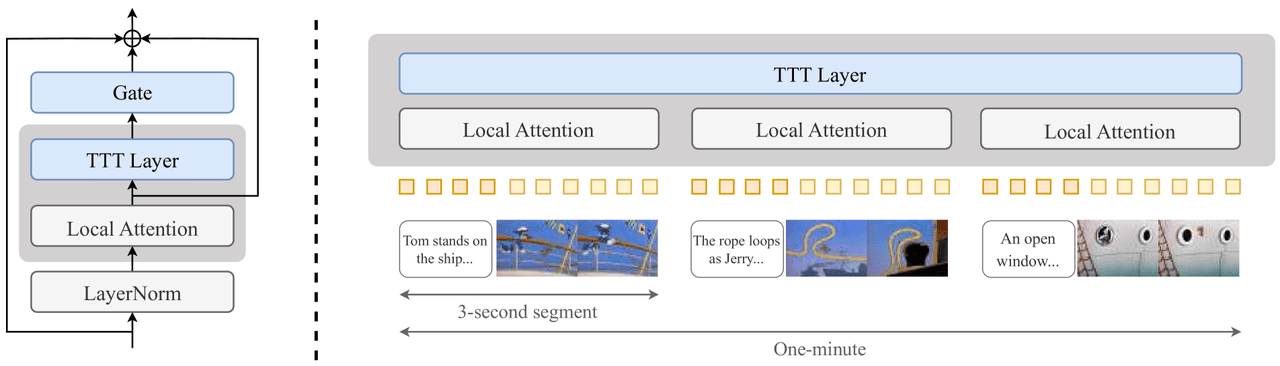
TTT — 왼쪽: 삽입 지점(표준 어텐션 이후 잔차 연결을 통해 게이트 + TTT 레이어 + 로컬 어텐션 + LayerNorm 삽입). 오른쪽: 영상을 3초 단위로 분할하고, 로컬 어텐션이 내부적으로 처리하며 TTT 레이어가 세그먼트 간의 글로벌 메모리를 전달함.
작동은 잘 되며 논문에서는 1분 생성을 달성합니다. 하지만 학습 비용이 매우 크고, 실험이 CogVideoX 5B에 한정되어 있으며(Wan2.2 14B로의 전이는 검증되지 않음), 삽입된 TTT 레이어가 우리가 의존하는 커널 최적화와 충돌합니다. 결론: 미선택.
경로 2 · LoL (Longer than Longer)
논문: LoL: Longer than Longer, Scaling Video Generation to Hour (arXiv 2601.16914, 2026년 1월).
LoL은 자기회귀식 장편 영상 생성의 특정 실패 모드인 *싱크 붕괴(sink-collapse)*를 겨냥합니다. 다중 헤드 어텐션이 앵커 프레임에만 집중되어 영상이 주기적으로 초기 상태로 되돌아가는 현상입니다. 해결책은 Multi-Head RoPE Jitter로, 헤드별로 무작위 위상 섭동을 주어 헤드 간의 동질성을 깨뜨리는 방식입니다. 학습이 필요 없는 플러그인 방식입니다.
실패 모드: 싱크 붕괴 — 자기회귀 RoPE 하에서 먼 프레임의 위치 위상이 주기적으로 앵커와 재정렬되고 어텐션이 집중되어 콘텐츠가 앵커 프레임으로 튀어 오름.
해결책: 각 어텐션 헤드에 고유한 작은 무작위 위상 이동을 부여함. 헤드들이 같은 열로 붕괴될 수 없음. 재학습 불필요, 기존 모델에 바로 적용 가능.
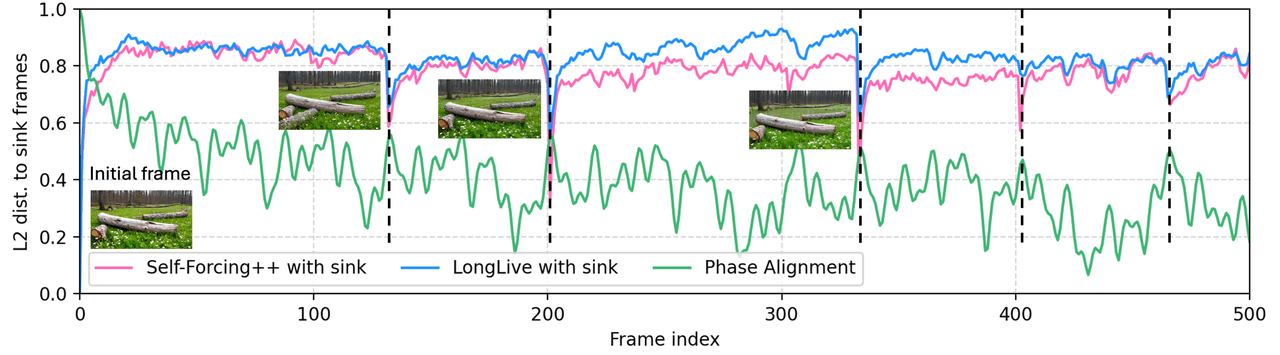
앵커와의 L2 거리 vs 프레임 인덱스. Self-Forcing++(빨간색)와 LongLive(파란색) 모두 싱크 붕괴로 인해 특정 프레임 위치에서 계속 튀어 오름. LoL의 위상 정렬(녹색)은 이 튀어 오름 현상을 제거함.
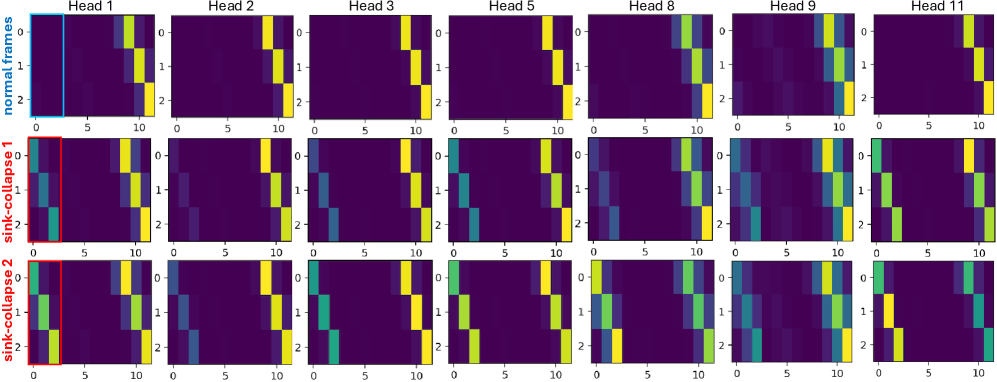
헤드별 어텐션 맵. 상단: 일반 프레임 — 헤드별로 명확히 다른 패턴. 하단: 싱크 붕괴 발생 시 — 모든 헤드가 동일하게 앵커 프레임 열로 붕괴됨. RoPE Jitter는 헤드별 다양성을 복원함.
LoL은 품질 저하를 최소화하며 CogVideoX/HunyuanVideo에서 12시간 영상을 생성합니다. 단, 데모는 대부분 정적인 장면이며 댄스나 스포츠 같은 강한 움직임에서 어떻게 작동할지 알 수 없습니다. 게다가 Wan2.2의 어텐션을 수정해야 합니다. 결론: 움직임 콘텐츠에 대한 검증되지 않은 이득을 위해 감수하기엔 비용이 너무 큼. 미선택.
경로 3 · Self Forcing (Causal Wan2.2)
논문: Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (arXiv 2506.08009, NeurIPS 2025 Spotlight).
Self Forcing은 Wan2.2의 양방향 Full Attention을 인과적(causal) 어텐션으로 대체합니다. 즉, 프레임은 이전 프레임만 참조합니다. 이 변경 하나만으로 스트리밍 생성이 가능해집니다. 첫 번째 청크가 완료되면 즉시 디코딩하여 출력할 수 있습니다.
양방향: 모든 프레임이 서로 참조 → 프레임을 보여주기 전에 40번의 노이즈 제거 단계를 모두 마쳐야 함. 인과적: 프레임이 과거만 참조 → 첫 번째 청크는 완료되는 즉시 스트리밍 가능.
학습 트릭이 논문의 핵심입니다. 깨끗한 정답 컨텍스트(Teacher Forcing)나 커스텀 마스크(Diffusion Forcing) 대신, 롤링 KV 캐시를 사용하여 실제 추론 경로를 그대로 학습시켜 학습과 추론 분포를 일치시킵니다.
생성 루프: 이미 생성된 프레임들로 구축된 롤링 KV 캐시를 조건으로 하여, DMD의 압축 단계 일정을 사용해 다음 작은 프레임 청크를 노이즈 제거합니다.
스트림: 청크가 완료되는 즉시 VAE로 디코딩하여 출력합니다.
전달: 새로운 청크의 잠재값(latent)을 다음 청크가 참조할 수 있도록 KV 캐시에 푸시합니다.
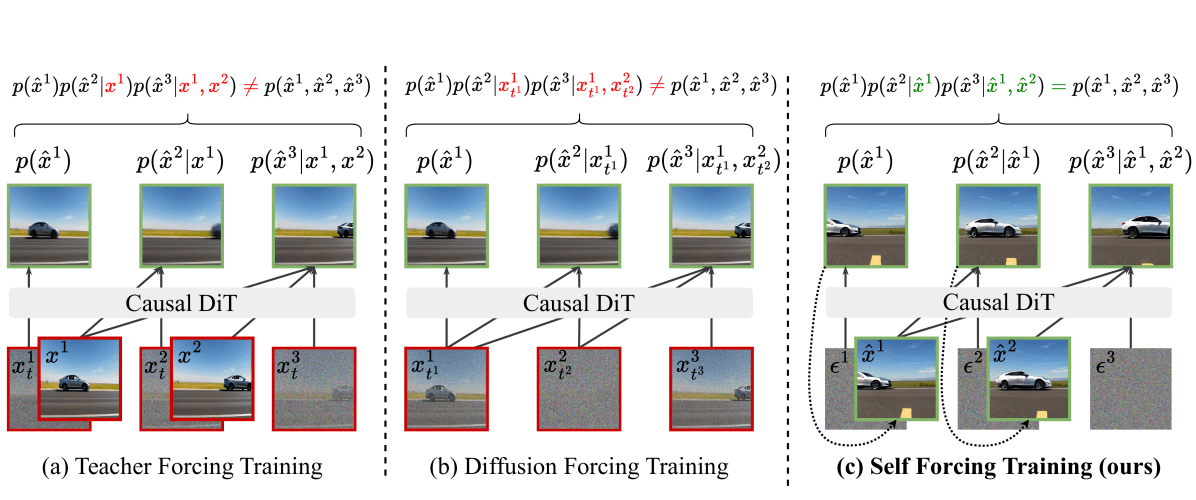
3가지 학습 패러다임 비교: (a) Teacher Forcing은 깨끗한 프레임으로 학습하여 추론 시 분포 차이 발생; (b) Diffusion Forcing은 커스텀 마스크를 쓰지만 여전히 학습-추론 불일치; (c) Self Forcing은 롤링 KV 캐시를 사용하여 실제 추론 과정을 재현함으로써 학습과 추론을 완벽히 정렬.
FastVideo 프레임워크와 단일 H200에서 측정값입니다:
| 길이 | 프레임 | 시간 | VRAM |
|---|---|---|---|
| 5초 | 81 프레임 | 70초 | — |
| 10초 | 165 프레임 | 168초 | 129 GB (용량 근접) |
| 20초 | 321 프레임 | 287초 | 129 GB (KV 캐시 42 프레임 제한) |
이 방식은 아키텍처 측면에서 가장 깔끔한 해결책입니다. 하지만 10초만 되어도 H200의 VRAM을 채우며, 165 프레임 이상에서 품질이 떨어집니다. 또한 원본 모델에 인과적 어텐션 파인튜닝이 필요하며, 진정한 스트리밍을 위해서는 VAE에 Causal Conv3D가 필요합니다.
결론: 커뮤니티가 VRAM과 품질 문제를 해결할 때까지 대기. 현재는 미채택.
경로 4 · Self Forcing++
논문: Self-Forcing++: Towards Minute-Scale High-Quality Video Generation (arXiv 2510.02283, 2025년 10월).
Self Forcing을 기반으로 세 가지를 추가합니다. 후방 노이즈 초기화(Backward Noise Initialization) (각 새 청크는 이전 프레임에서 역통합된 노이즈로 시작하여 청크 경계 불연속성 제거), 확장된 DMD 정렬, 그리고 더 역동적인 움직임을 위한 광학 흐름 보상을 활용한 GRPO 단계입니다.
1단계. 롤링 KV 캐시를 사용하여 5초보다 훨씬 긴 초안을 생성합니다. 2단계. 초안에서 임의의 5초 윈도우를 슬라이싱하고 교사의 짧은 윈도우 분포와 비교하여 Extended DMD로 정렬합니다. 3단계. 광학 흐름 크기를 보상으로 사용하여 GRPO로 정제하고 모델이 더 역동적인 움직임을 갖도록 유도합니다. 트릭. 각 새 청크는 새로운 가우시안 노이즈가 아닌, 이전 청크에서 역통합된 노이즈로부터 시작하여 청크 경계가 튀지 않습니다.
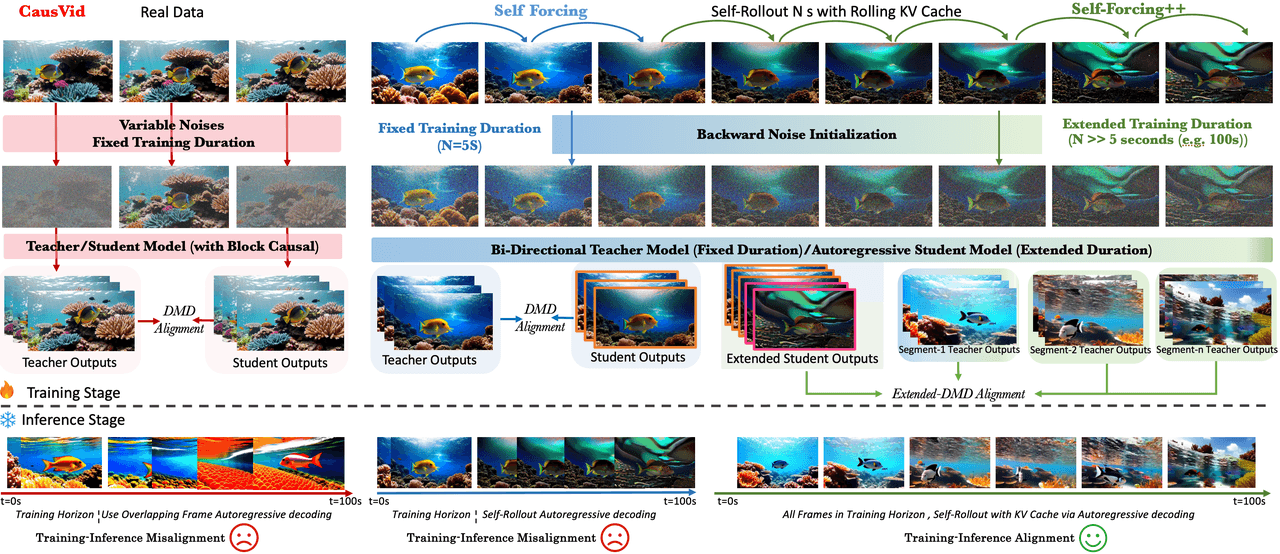
왼쪽에서 오른쪽으로: CausVid → Self Forcing → Self-Forcing++. 하단 열은 학습 단계와 추론 단계의 대응 관계를 보여줌.
결과: 1.3B Wan2.1에서 분 단위 영상 생성 가능. 훌륭한 논문입니다. 다만 실제 프로덕션 적용 시 두 가지 한계가 있습니다. 콘텐츠가 주로 정적(낮은 움직임)이고 베이스 모델이 1.3B(Wan2.2 14B에 비해 매우 작음)이며, 부트스트랩할 수 있는 코드나 가중치가 공개되지 않았습니다. 결론: 미선택.
경로 5 · Infinite Talk (A2V)
문제의 성격이 완전히 다른 오디오-투-비디오(A2V) 방식입니다. 오디오가 연속적인 대화 영상 생성을 주도합니다.
청크별 입력 번들: 새 청크의 노이즈 잠재값, 해당 시간 윈도우의 오디오 특징, 사용자 제공 참조 이미지, 이전 청크의 마지막 프레임, 소프트 컨디셔닝 가중치. 참조 정체성: 참조 이미지가 장기적인 외형을 안정적으로 유지합니다. 적응형 제약: 소프트 가중치가 유사도 드리프트에 따라 참조를 강화하거나 완화합니다. 움직임 브리지: 이전 청크의 마지막 프레임이 경계 너머로 움직임을 전달합니다.
대화 영상 생성용으로는 훌륭하지만, Wan2.2와는 아키텍처 차이가 커 전용 학습이 필요하며 일반 장면으로 범용화되지 않습니다. 결론: 특정 분야에서는 가치 있으나 일반적인 장편 영상 솔루션은 아님.
경로 6 · Helios
논문: Helios: Real Real-Time Long Video Generation Model (PKU-YuanGroup, arXiv 2603.04379, 2026년 3월).
글 작성 시점 기준으로 Helios는 장편 영상 생성의 SOTA(최고 수준)입니다. 14B 파라미터로 단일 H100에서 초당 19.5 프레임의 실시간 생성이 가능합니다. 핵심은 과거 프레임을 3단계 피라미드로 압축하여 현재 프레임의 노이즈 제거에 주입함으로써, 영상 길이에 상관없이 토큰 예산을 일정하게 유지하는 것입니다.
다중 기간 메모리: 단기 기록(최근 3 프레임)은 전체 해상도 유지, 중기(최근 20 프레임)는 중간 압축, 장기(그 이전 모든 프레임)는 고압축. 가이던스 어텐션: DiT 블록 내에서 깨끗한 과거 KV와 노이즈가 있는 현재 QKV를 분리 처리하여 과거 노이즈가 현재 노이즈 제거를 오염시키지 않도록 함. 피라미드 샘플링: 낮은 해상도에서 구조를 정의하고 고해상도로 정제하여 세부사항을 추가함으로써 토큰 수를 약 2.3배 줄임.
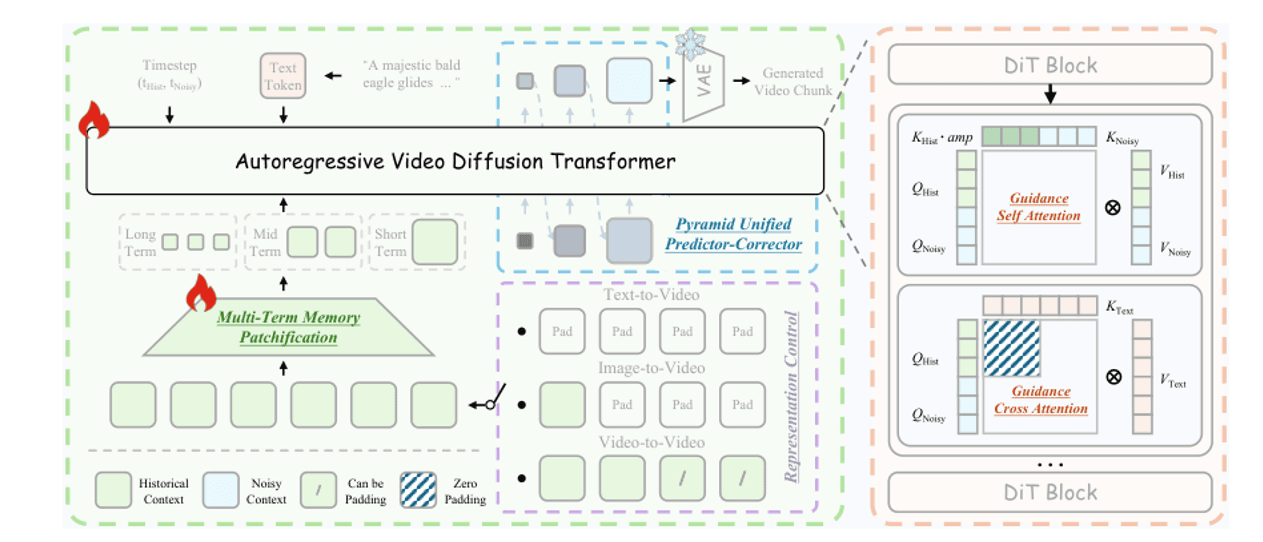
Helios 아키텍처. 왼쪽: 통합 기록 주입. 오른쪽: 피라미드 통합 예측-보정기.

Helios 논문은 장편 영상 생성에서 발생하는 세 가지 드리프트(위치, 색상, 복원)를 체계적으로 정의하고 시각화합니다. 가이던스 어텐션은 이를 해결하기 위해 설계되었습니다.
H200에서의 측정 처리량은 매우 인상적입니다:
| 길이 | 시간 | 처리량 |
|---|---|---|
| 240 프레임 (10초) | 24초 | ~10 FPS |
| 480 프레임 (20초) | 42초 | ~11.4 FPS |
| 960 프레임 (40초) | 82초 | ~11.7 FPS |
| H100 단일 GPU (Helios-Distilled) | — | 19.5 FPS |
다만 Multi-Term Memory Patchification은 14B 모델의 전체 재학습이 필요합니다. 공개된 가중치가 없어서 LoRA를 단순히 덧붙일 수 없습니다. 결론: 중장기적인 방향성이나 현재는 도입 불가.
경로 비교 요약
우리가 최종적으로 선택한 SVI를 포함한 6가지 경로 비교입니다:
| 방식 | 최대 길이 | 품질 | 학습 필요 | 엔지니어링 난이도 | 범용성 | 추천 |
|---|---|---|---|---|---|---|
| TTT | 1분 | 높음 | 매우 필요 | 높음 | 중간 | ★★☆ |
| LoL | 시간 단위 | 중간 | 필요 | 중간 | 중간 | ★★☆ |
| Self Forcing | 이론상 무제한 | 중간 | 기존 모델 | 높음 (VRAM) | 높음 | ★★★ |
| Self Forcing++ | 1분 단위 | 낮음 | 필요 | 매우 높음 | 높음 | ★☆☆ |
| Infinite Talk | 무제한 | 높음 | 필요 | 높음 | 낮음 | ★★☆ |
| Helios | 이론상 무제한 | 높음 | 전체 재학습 | 매우 높음 | 높음 | ★★★☆ |
| SVI | 무제한 | 중상 | 오픈소스 LoRA | 중간 | 높음 | ★★★★ |
조사에서 도출된 분류 체계
우리가 조사한 모든 방식은 크게 세 가지 범주로 나뉩니다.
타입 A — 어텐션 범위 확장: 모델이 직접 긴 시퀀스를 처리하게 합니다. 이론적 품질은 가장 높으나 VRAM이 제곱으로 증가하여 현재 10초 정도가 한계입니다.
타입 B — 계층적 기록 압축: 과거 프레임을 압축하여 조건으로 주입합니다. VRAM 한계를 우회하지만 14B 모델의 전면 재학습 비용이 듭니다.
타입 C — 상태 기반 롤링 생성: 긴 영상을 겹치는 상태를 가진 짧은 클립으로 분해합니다. VRAM이 일정하고 길이가 무제한이며 LoRA만으로 학습 가능합니다. 단점은 클립 경계에서의 불연속성과 장기적인 드리프트 관리 문제입니다.
이번 분기 우리는 타입 C를 선택했습니다. 내년에는 타입 B를 유심히 지켜볼 예정입니다.
다음 게시물에서는 실제 운영이 어떠했는지, 15초 이상 영상 생성을 위한 6가지 접근 방식과 우리가 왜 SVI를 선택했는지, 그리고 구체적인 운영 지표에 대해 다루겠습니다. 2부 읽기 →






