
1부에서는 TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk, Helios 등 6가지 장편 비디오 생성 접근 방식을 조사했으며, 14B 모델의 재학습 없이 즉시 배포 가능한 유일한 경로로 SVI를 선정했습니다. 이번 포스팅에서는 실제 구축 과정, 즉 클립 이어 붙이기 루프의 작동 원리, Error-Recycling이 중요한 이유, 그리고 TurboWan에 첫 배포 시 얻은 프로덕션 수치를 다룹니다.
선택: SVI (Stable Video Infinity)
SVI의 핵심 철학은 무한 길이 생성을 신중하게 설계된 메모리 전송을 통해 유한한 수의 짧은 클립을 이어 붙이는 방식으로 전환하는 것입니다. 단순해 보이지만, 이 방식은 베이스 모델 재학습 불필요(TurboWan에 작은 LoRA 탑재), 일정한 VRAM 사용, 기존 속도 증류(speed-distillation)와의 호환성, 공개된 공식 LoRA 가중치 활용 등 대부분의 엔지니어링 문제를 한 번에 해결합니다.
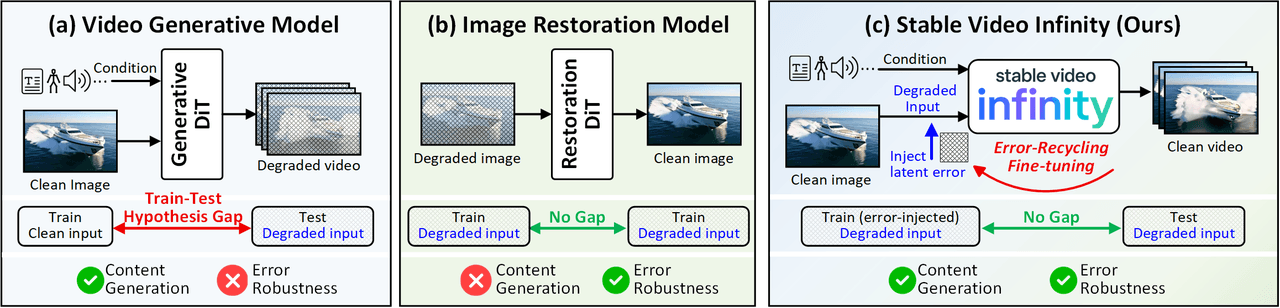
SVI의 멘탈 모델. (a) 표준 비디오 생성 모델은 학습-테스트 가설 격차(Train-Test Hypothesis Gap)가 있음. 학습 시에는 깨끗한 입력을 사용하지만 추론 시에는 노이즈와 오차가 누적된 입력을 마주함. (b) 이미지 복원 모델은 오차에 강건하지만 새로운 콘텐츠를 생성할 수 없음. (c) SVI의 Error-Recycling 파인튜닝은 두 모델의 가교 역할. 스스로 생성한 오차를 감독 신호로 사용하여 모델이 자신의 생성 오류를 식별하고 수정하는 법을 학습함.
클립 이어 붙이기 작동 원리
각 클립은 81프레임(5초 @ 16fps)으로 구성됩니다. 생성은 루프 방식으로 이루어집니다. 글로벌 ID 앵커와 이전 클립의 단기 모션 브리지를 기반으로 다음 클립을 조건화한 뒤 연결합니다.
클립 1. 입력: 참조 이미지 + 빈 모션 메모리. 출력: 5초 클립. 모션 메모리 추출: 마지막 4프레임의 잠재 표현(latent). 클립 2. 입력: 참조 이미지 + 클립 1의 모션 메모리. 출력: 5초 클립. 끝부분에서 모션 메모리 추출. ... N개의 클립까지 반복한 뒤, 클립 1 + 클립 2 + … + 클립 N을 연결하여 장편 비디오를 만듭니다.
DiT 어텐션 수정이 필요 없다는 점이 핵심입니다. 과거 컨텍스트는 잠재 표현 수준에서 입력 시 연결되며, 작은 LoRA가 모델에게 이 접두사를 실제로 활용하는 방법을 가르칩니다.
앵커 잠재 표현(Anchor latent). 사용자가 제공한 참조 이미지로, VAE로 인코딩되어 피사체/캐릭터 외형의 글로벌 일관성을 유지합니다. 모션 잠재 표현(Motion latent). 이전 클립의 마지막 4/8/12프레임의 잠재 표현으로, 이전 세그먼트가 어떻게 끝났는지 모델에 알려줍니다. 패딩(Padding). DiT가 깔끔하게 연결된 시퀀스(앵커 + 모션 + 패딩)를 볼 수 있도록 입력 형태를 조정합니다.
Error-Recycling 파인튜닝
SVI가 많은 클립에 걸쳐 일관성을 유지하는 비결은 LoRA 학습 방식에 있습니다. 표준 추론은 항상 순수한 가우시안 노이즈에서 디노이징을 시작하지만, 장편 비디오 합성에서는 이전 클립의 오차가 다음 클립의 조건화에 영향을 미칩니다. 깨끗한 참조 입력으로만 학습하면 학습-추론 격차가 발생합니다.
표준 학습: 모든 클립의 참조 입력이 깨끗한 정답(ground truth)임 → 모델은 추론 시 마주하는 노이즈 섞인 과거 컨텍스트를 본 적이 없으므로 불연속성이 누적됨.
Error-Recycling: 학습 중 모델이 과거에 생성한 오차를 참조 입력에 의도적으로 주입하여, LoRA가 노이즈 섞인 과거 컨텍스트를 처리하는 법을 명시적으로 학습하도록 함. 클립 경계에서의 시각적 불연속성이 급격히 감소함.
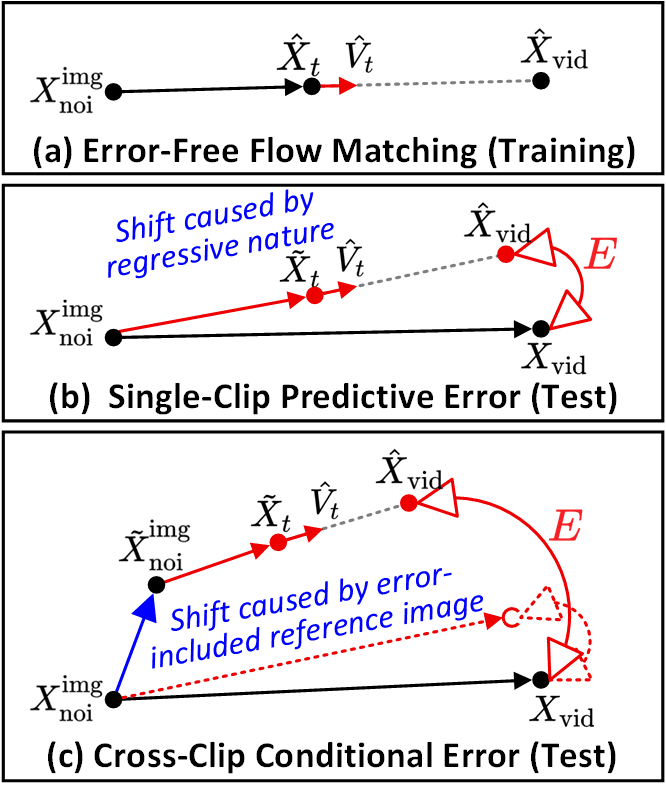
SVI의 두 가지 핵심 오차 유형 식별. (a) 오차 없는 Flow Matching(학습 시 궤적). (b) 단일 클립 예측 오차(Single-Clip Predictive Error) — 디노이징 경로와 이상적인 궤적 간의 드리프트. (c) 클립 간 조건부 오차(Cross-Clip Conditional Error) — 오차 섞인 참조 이미지가 다음 클립으로 넘어가며 발생하는 연쇄적 드리프트. Error-Recycling은 이 두 가지를 명시적으로 주입함.
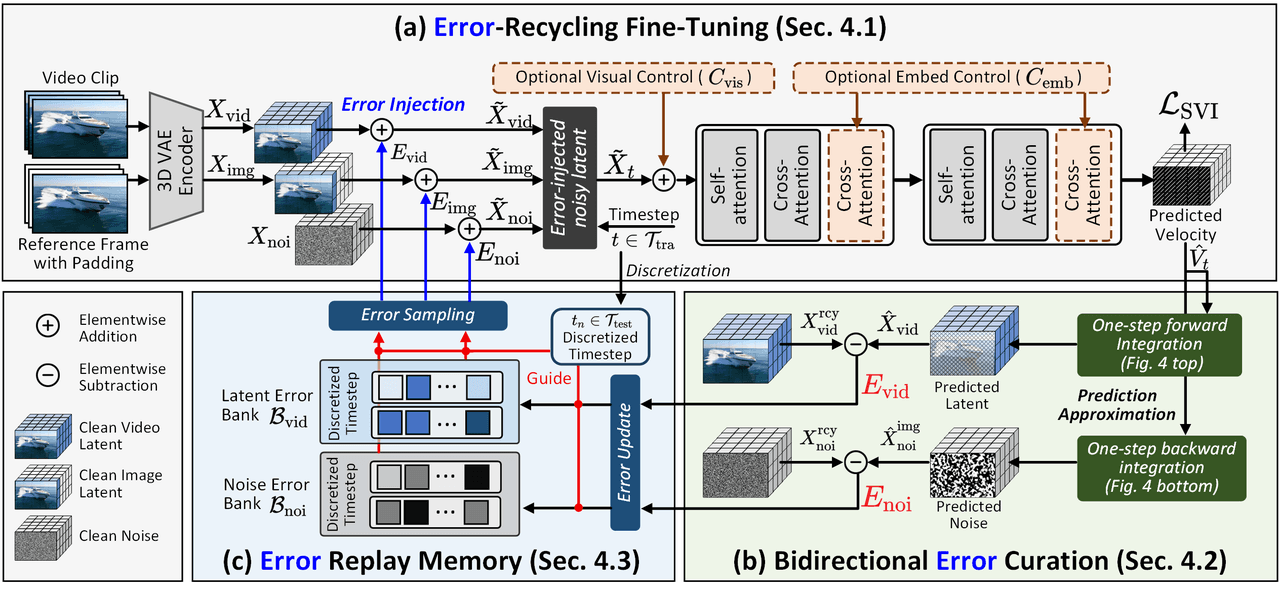
SVI 학습 프레임워크. (a) DiT가 스스로 생성한 오차를 잠재 공간에 주입하여 오차 없는 가정 파괴. (b) 1단계 순방향/역방향 통합을 통한 양방향 오차의 효율적 계산. (c) 오차를 Replay Memory에 저장하고 동적으로 리샘플링하여 재사용, 닫힌 루프 형태의 오차 감독 사이클 형성.
LoRA 변형
SVI는 세 가지 버전을 제공합니다. 정지 이미지 → 짧은 클립을 위한 SVI-Shot, 인간 모션(포즈 시퀀스 입력 가능)을 위한 SVI-Dance, 멀티 샷/장면 전환 장편 비디오를 위한 _SVI-Film_입니다. 하이퍼파라미터: 클립당 81프레임, 모션 프레임 수 {4, 8, 12}, LoRA 랭크는 일반적으로 16~64입니다.
TurboWan에 스택 구성
Atlas가 최적화한 TurboWan(Wan의 속도 향상 버전) 위에 SVI LoRA를 탑재하고, 스타일 제어를 위해 전용 LoRA를 함께 사용합니다. 추론 시 여러 LoRA 가중치가 동시에 적용됩니다.
베이스: TurboWan LoRA 1: 콘텐츠/스타일 제어용 전용 LoRA. LoRA 2: 장편 비디오 일관성용 SVI LoRA. 결합: TurboWan 속도 + SVI 장편 비디오 연속성 + 개성 있는 스타일을 단일 추론 패스에서 실행.
전체 추론 흐름: 참조 이미지를 앵커 잠재 표현으로 인코딩 -> 이전 클립의 모션 잠재 표현 및 패딩과 연결 -> TurboWan 디노이징 실행 -> 디코딩 및 추가 -> 새로 생성된 클립 끝부분에서 모션 잠재 표현 업데이트. N번 반복 후 하나의 비디오로 연결합니다.
프로덕션 수치
표준 테스트: 참조 이미지 1개와 프롬프트 3개로 약 15초(5초 x 3 클립) 출력 생성:
| 지표 | 수치 |
|---|---|
| 생성 시간 | 15초 (3개 클립) |
| 클립당 추론 시간 | 약 14초 (TurboWan fp8, 단일 GPU) |
| 총 추론 시간 | 약 42초 |
| 피사체 일관성 | 양호 |
사례 연구: 고양이 모험
교차 클립 동작을 구체화하기 위해 참조 1개와 샷 3개로 15초 분량의 영상을 제작했습니다. 픽사 스타일의 따뜻한 조명, 호기심 많은 눈을 가진 오렌지색 태비 새끼 고양이를 주인공으로, 창틀에서 보도블록으로, 그리고 골든 리트리버를 만나는 과정을 각기 다른 카메라 앵글로 담았습니다.
 클립 1 (0~5초): 창틀 위의 오렌지색 픽사풍 새끼 고양이, 클로즈업에서 서서히 줌아웃. 스타일과 캐릭터가 프레임 전반에 걸쳐 안정적임.
클립 1 (0~5초): 창틀 위의 오렌지색 픽사풍 새끼 고양이, 클로즈업에서 서서히 줌아웃. 스타일과 캐릭터가 프레임 전반에 걸쳐 안정적임.
 클립 2 (5~10초) 경계: 고양이의 외형은 클립 1과 일치하며, 뛰어내릴 때 자세를 변경함. 모션 잠재 표현이 모션 상태를 경계 너머까지 전달함.
클립 2 (5~10초) 경계: 고양이의 외형은 클립 1과 일치하며, 뛰어내릴 때 자세를 변경함. 모션 잠재 표현이 모션 상태를 경계 너머까지 전달함.
 클립 3 (10~15초): 골든 리트리버가 등장하며 실내/외 경계로 전환. 모든 클립에서 고양이의 픽사 스타일이 안정적으로 유지됨.
클립 3 (10~15초): 골든 리트리버가 등장하며 실내/외 경계로 전환. 모든 클립에서 고양이의 픽사 스타일이 안정적으로 유지됨.
전체 결과 지표:
| 지표 | 수치 |
|---|---|
| 총 시간 | 15초 (3개 클립 x 5초) |
| 총 프레임 | 240프레임 (16fps) |
| 총 추론 시간 | 33초 (TurboWan, 단일 GPU) |
| 영상 생성 비율 | 2.2 s/s |
| 피사체 일관성 | 픽사풍 오렌지 고양이 일관성 유지 |
| 클립 경계 불연속성 | 눈에 띄는 점프 컷 없음 |
단일 GPU에서 33초 만에 15초짜리 장편 영상을 생성했으며, 교차 클립 피사체 일관성까지 확보했습니다(목표 대기 시간 60초 이내). 내부 테스트 14건 중 9건에서 별다른 문제 없이 성공(64% 성공률)했습니다.
결론적으로 비디오 생성에서 속도, 길이, 품질은 '철의 삼각형'과 같습니다. 현재 이 세 가지를 모두 완벽히 잡은 접근 방식은 없습니다. 흥미로운 과제는 현 하드웨어와 학습 예산 내에서 무엇을 최소한으로 포기할지 선택하는 것입니다. SVI는 길이와 경계 품질을 일부 희생하는 대신, 현재 사용 가능한 단일 GPU에서 Wan2.2 수준의 충실도를 갖춘 장편 비디오를 제작할 수 있게 해줍니다.






