
If you're evaluating open-source models for coding, reasoning, or agentic pipelines, Kimi K2.6 and GLM 5.1 are both going to show up on your shortlist. Both come from leading Chinese AI labs, both work with OpenAI-compatible APIs, and both are capable on the kinds of complex tasks developers actually care about.
The problem is they aren't interchangeable. They have different context windows, different cost structures, and different strengths that surface in specific use cases. Picking the wrong one for your workload means you're either leaving performance on the table or overpaying for capacity you don't need.
This article breaks down the real differences between the two models: what the specs actually mean in practice, where each model holds up and where it doesn't, and what the numbers look like when you're running either one at scale.

Kimi K2.6 vs GLM 5.1: The Quick Summary
Kimi K2.6 is Moonshot AI's latest model in their K2 series, which represents their current flagship line. Moonshot is the company behind the Kimi assistant, and K2.6 is their bet on long-context reasoning and competitive pricing. The 262K context window is one of its headline features.
GLM 5.1 comes from Zhipu AI, one of China's more established AI research organizations. The GLM series (General Language Model) has been developing through several generations, and 5.1 is Zhipu's current top offering. It carries a strong reputation in the open-source community for instruction-following accuracy and structured output quality.
Both models expose an OpenAI-compatible API, which means connecting them to tools like Claude Code, Codex, or OpenClaw is straightforward. The choice between them narrows down to three real factors: how much context you need per request, what your token costs look like at your expected volume, and whether your tasks skew toward each model's relative strengths.
The Models Behind the Names
Kimi K2.6 vs GLM 5.1 Context Windows Compared
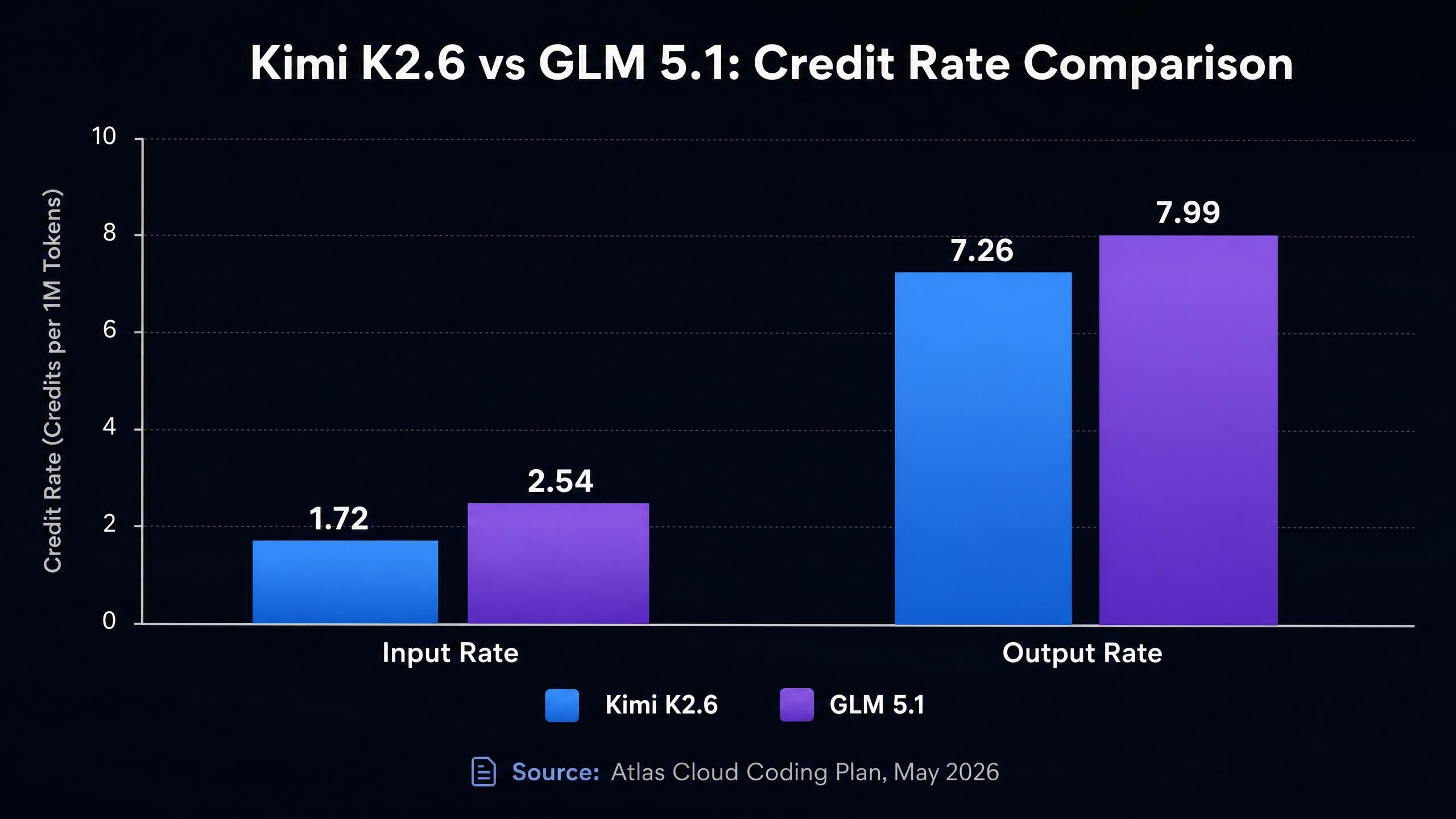
Context window is one of the clearest and most objective differentiators here. Kimi K2.6 supports a 262K token context window. GLM 5.1 supports 200K. That's a 31% gap in maximum input capacity.
For typical coding tasks, neither model hits those limits day to day. A standard code review, a debugging session, or a documentation generation request will fit comfortably within both windows. The gap becomes meaningful in specific scenarios:
- Large codebase analysis: Passing tens of thousands of lines in one request for refactoring or architecture review
- Long agentic sessions: Conversations that accumulate substantial context over many turns and tool calls
- Document-heavy pipelines: Research, summarization, or analysis tasks that require large text chunks in a single call
If your workload regularly approaches context limits with other models, Kimi K2.6's 262K window gives you more headroom before you have to implement chunking or context summarization logic. If your typical requests are under 50K tokens, both models offer more than enough capacity and the window difference stops being a real factor.

Coding and Reasoning Strengths
Both models are capable on coding tasks, though their design priorities create different behavior in practice.
Kimi K2.6 is built for long-context comprehension. This makes it well-suited for multi-file refactoring, understanding how changes in one part of a codebase affect others, and extended reasoning chains where the model needs to hold a lot of state across many steps. Moonshot AI has positioned K2.6 specifically around these use cases.
GLM 5.1 carries Zhipu AI's focus on precise instruction following and structured outputs. Tasks like generating code against a detailed specification, producing structured formats from natural language, or managing complex tool-call schemas play to its strengths. The slightly higher output rate in its pricing (7.99 vs 7.26) also hints at the model's tendency toward more thorough, detailed completions.
For most developers comparing these two, the performance difference on typical coding tasks is smaller than you'd expect from the different company branding. The clearer differentiators are in the specs and cost, where the numbers are concrete.
Kimi K2.6 vs GLM 5.1: Token Costs and Credit Rates
This is where the comparison gets specific. Both models are available through Atlas Cloud Coding Plan, and the credit rates are as follows (Atlas Cloud Coding Plan, May 2026):
| Model | Context | Input Rate | Output Rate | Cache Write | vs. Official |
|---|---|---|---|---|---|
| Kimi K2.6 | 262K | 1.72 | 7.26 | 0.290 | 45% cheaper |
| GLM 5.1 | 200K | 2.54 | 7.99 | 0.472 | 45% cheaper |
A few things stand out.
GLM 5.1's input rate (2.54) is about 48% higher than Kimi K2.6's (1.72). In coding contexts where you're passing file contents, large code histories, or long conversation accumulations, input tokens are often the majority of your cost. A pipeline running 1,000 requests per day with 10K input tokens per request would cost roughly 48% more on input alone with GLM 5.1 than with Kimi K2.6.
Output rates are closer but still favor Kimi K2.6 (7.26 vs 7.99, about a 10% gap). Cache write rates also favor Kimi K2.6 (0.290 vs 0.472), which adds up in workflows that use prompt caching for repeated system prompts or static context.
To put both together: for a request with 5,000 input tokens and 1,000 output tokens, the credit costs work out to:
- Kimi K2.6: (5,000 × 1.72) + (1,000 × 7.26) = 8,600 + 7,260 = 15,860 credits
- GLM 5.1: (5,000 × 2.54) + (1,000 × 7.99) = 12,700 + 7,990 = 20,690 credits
Kimi K2.6 is about 23% cheaper per request on this input/output ratio. At high volume, that compounds into a real budget difference.
Both models are priced 45% below their official API rates through the gateway, which is consistent across this model tier.
Kimi K2.6 vs GLM 5.1 in Agentic Coding Workflows
Agentic tools amplify every cost and capability difference between models.
In a multi-step coding agent, each tool call is a separate API request. Every request carries input context from the accumulated conversation, generates output that feeds the next step, and adds to your total compute bill. A workflow that runs 40 API calls in a session doesn't just cost 40x the single-request price; it also accumulates context fast, which pushes requests toward higher input token counts as the session progresses.
Where Kimi K2.6 tends to hold up better in agents: Long sessions where accumulated context grows large, tasks involving reading and modifying large code files, and pipelines where keeping costs reasonable across many calls matters. The larger context window also means fewer session resets, which disrupts the agent's working memory less.
Where GLM 5.1 tends to do better: Pipelines where each step requires precise, well-structured output and where instruction accuracy on each individual call matters more than context depth across the session. If your agent needs to generate code against strict type schemas, manage complex function signatures, or produce consistent formatted output on every turn, GLM 5.1's instruction-following strengths are more directly relevant.
Both models work cleanly with Claude Code, Codex, OpenClaw, and Cursor through standard OpenAI-compatible configurations. Integration is identical between the two; only the model ID changes.
How to Run Both and Pick the One That Actually Works for You
Kimi K2.6 vs GLM 5.1: Choosing the Right One Without Guessing
The most reliable way to decide between these two models isn't reading comparison articles (including this one). It's running both on your actual tasks and comparing output quality yourself. The good news is this is easy to do when both models sit behind the same API key and base URL.
Atlas Cloud Coding Plan puts Kimi K2.6 and GLM 5.1 on the same endpoint under one API key. Switching between them is a one-line config change, which means you can run your real workload on both models back to back without rebuilding any integration.
For Claude Code on macOS or Linux, the full config goes in ~/.claude/settings.json. Set it to Kimi K2.6 first:
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "moonshotai/kimi-k2.6", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "moonshotai/kimi-k2.6", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "moonshotai/kimi-k2.6", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
To switch to GLM 5.1, change moonshotai/kimi-k2.6 to zai-org/glm-5.1 in all three model fields. Everything else stays the same. Note that Claude Code's base URL is https://api.atlascloud.ai without a /v1 suffix.
For Codex, the config splits into two files. ~/.codex/config.toml:
plaintext1model_provider = "atlas_coding_plan" 2model = "moonshotai/kimi-k2.6" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
~/.codex/auth.json:
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
For OpenClaw, run openclaw onboard, choose QuickStart, then Custom Provider. Enter https://api.atlascloud.ai/v1 as the base URL, paste your Atlas key, and select the model ID you want to test.
The Atlas Cloud plan comes in two forms: a monthly subscription with daily credit refresh (best for consistent daily usage) and a pay-as-you-go pack with a 90-day window (better for variable or experimental workloads). Since you're likely testing both models, the pay-as-you-go option gives you flexibility without committing to a monthly volume.
Kimi K2.6 vs GLM 5.1: Common Questions Answered
Which model costs less to run at scale?
Kimi K2.6 is cheaper per token on both input and output. The gap is largest on input (GLM 5.1's input rate is about 48% higher), which matters most in coding workflows that send large amounts of context. At high request volumes, this compounds into a meaningful budget difference.
Which model handles Chinese language tasks better?
Both models have strong Chinese language capabilities, expected given their origins. GLM 5.1 from Zhipu AI has a particularly established track record on Chinese language tasks, built through multiple generations of the GLM series. Kimi K2.6 also handles Chinese well given Moonshot AI's product focus on Chinese users. For Chinese-primary tasks, both are solid, with GLM 5.1 having a slight edge based on track record.
Can I mix both models in the same pipeline?
Yes. Through a unified gateway, you can route different steps in the same pipeline to different models by changing only the model parameter per request. You might use Kimi K2.6 for context-heavy analysis steps (lower input cost, larger window) and GLM 5.1 for structured output generation steps (stronger instruction following), all with one API key.
Is the 262K vs 200K context difference worth paying attention to?
For most everyday coding tasks, no. Both windows are large enough for typical requests. The difference matters if your sessions regularly accumulate 150-200K tokens, if you're passing large code files for analysis, or if you're running long agentic sessions without resets. If you rarely hit 50K tokens per request, it's not a deciding factor.
Do these models need special configuration to work with Claude Code?
No special configuration beyond what's shown above. Claude Code reads its model settings from ~/.claude/settings.json, and as long as you point it to a gateway that serves these models in OpenAI-compatible format, it connects cleanly. The one thing to watch is the base URL format for Claude Code specifically: it uses https://api.atlascloud.ai without /v1, unlike most other tools.
Final Verdict: Kimi K2.6 vs GLM 5.1
The choice between these two models is more about workload fit than a clear winner.
Kimi K2.6 is the more cost-efficient default. It's cheaper per token, it handles more context per request, and it's well-suited for the kinds of large-input, long-context tasks that coding agents generate. If you're optimizing for cost at scale or regularly working with large codebases, it's the stronger choice on the numbers.
GLM 5.1 earns its slightly higher price on tasks that demand precise instruction following and consistent structured outputs. If your pipeline is less context-heavy but requires high accuracy on each individual generation step, it's worth testing against your specific task type.
The practical approach: start with Kimi K2.6 for the cost advantage and the larger context window, run your real workload through it, and compare GLM 5.1 on the same tasks if you have questions about structured output quality. With both models behind the same API key on Atlas Cloud Coding Plan at 45% off official rates, the cost of comparison is low enough to let actual performance guide the decision.
Model specifications and credit rates are based on Atlas Cloud Coding Plan documentation as of May 2026. Model capabilities reflect publicly available information from Moonshot AI and Zhipu AI. Rates are subject to change; verify current figures directly with each provider.






