DeepSeek-V4 預覽版發布:100 萬 Token 上下文、Agent 升級與開源權重
今日(4 月 24 日),DeepSeek 正式發布並開源了其全新模型系列 DeepSeek-V4 的預覽版。
DeepSeek-V4 支援高達 100 萬 (1M) token 的上下文,並在 Agent 能力、世界知識與推理方面,於國產及開源模型中達到領先水準。該系列包含兩個版本:
- DeepSeek-V4-Pro — 旗艦模型,是一個龐大的 MoE(混合專家)模型,總參數達 1.6 兆 (1.6T),但每次前向傳遞僅激活 49B — 這正是其高效的核心關鍵。
- DeepSeek-V4-Flash — 更快、更具成本效益的選擇。它採用相同的 MoE 架構,但規模更小(總參數 284B / 激活 13B),從而實現了更快、更便宜的推理。
- 兩個模型均具備相同的 1M token 上下文視窗,並完全開源,提供 API 存取權。
| 模型 | 參數總量 | 激活參數 | 預訓練數據 | 上下文長度 | 開源 | API 服務 | 網頁/App 存取模式 |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 33T | 1M | ✓ | ✓ | 專家模式 |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✓ | ✓ | 極速模式 |
即日起,您可以在 chat.deepseek.com 或官方 App 上體驗 DeepSeek-V4。API 也已同步上線 — 只需將 model_name 設置為 deepseek-v4-pro 或 deepseek-v4-flash 即可開始使用。
我們此前已報導過相關預測與發布前分析(參見我們的 DeepSeek V4 預期指南 與 技術深度解析),現在我們獲得了來自官方的第一手確認細節。以下內容涵蓋了具體發布內容、新功能亮點,以及對於當前正在建構或評估 AI 模型的開發者而言的實際意義。
DeepSeek-V4-Pro:對標頂尖閉源模型
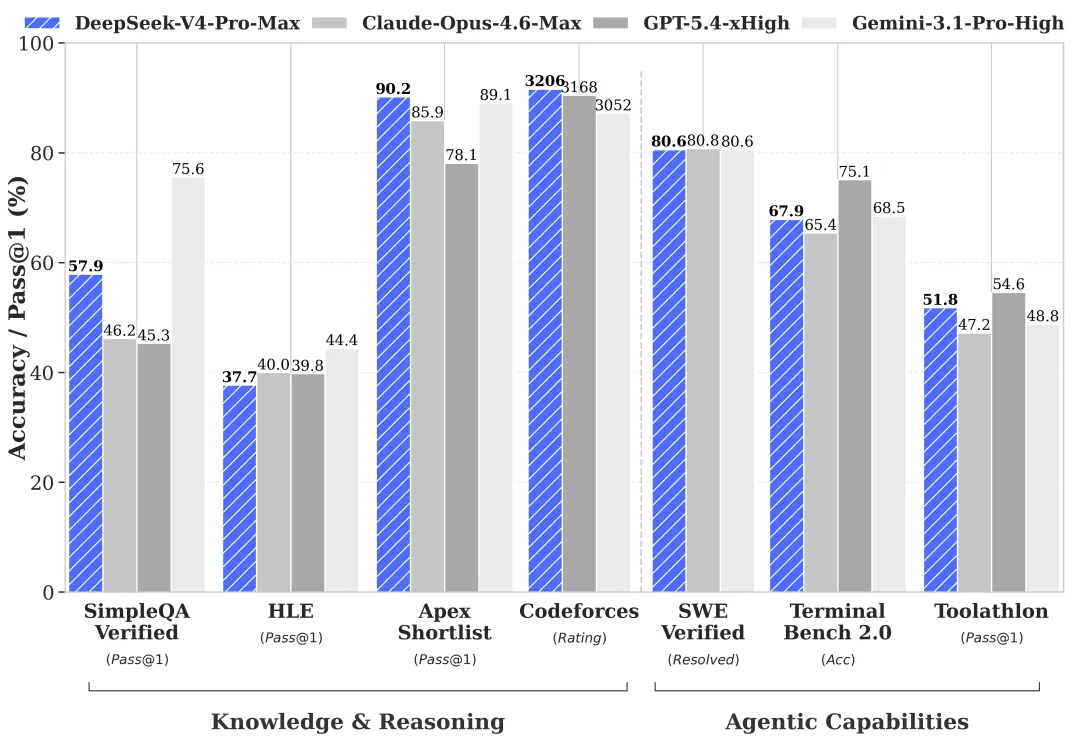
大幅增強的 Agent 能力。 與上一代產品相比,DeepSeek-V4-Pro 在 Agent 任務上展現了顯著提升。在 Agent 程式設計基準測試中,V4-Pro 目前已領先所有開源模型。DeepSeek 在內部已將 V4-Pro 作為首選編碼 Agent — 員工反饋顯示,其體驗超越了 Claude Sonnet 4.5,輸出品質接近非思考模式下的 Claude Opus 4.6,儘管在思考模式上仍落後於 Opus 4.6。
豐富的世界知識。 DeepSeek-V4-Pro 在世界知識基準測試中顯著優於其他開源模型,僅略遜於頂尖閉源模型 Gemini Pro 3.1。
世界級的推理能力。 在數學、STEM 和競技程式設計評估中,DeepSeek-V4-Pro 超越了所有此前評測過的開源模型,並達到了全球頂尖閉源模型的水平。
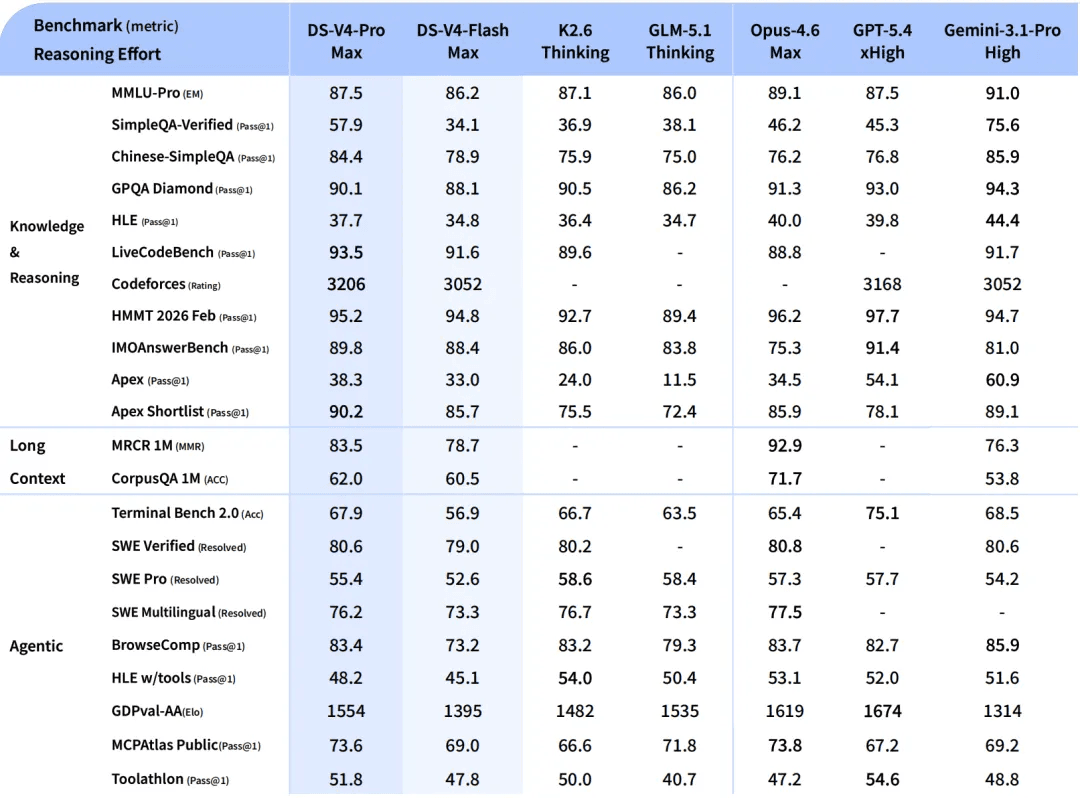
DeepSeek-V4-Flash:快速且經濟的選擇
與 V4-Pro 相比,DeepSeek-V4-Flash 在世界知識方面稍遜一籌,但在推理性能上卻不相上下。得益於更小的參數規模與更低的激活成本,V4-Flash 提供了更快的響應速度與更實惠的 API 定價。
在 Agent 基準測試中,V4-Flash 在簡單任務上與 V4-Pro 持平,但在更複雜的任務上仍有一定差距。
架構創新與極致的上下文效率
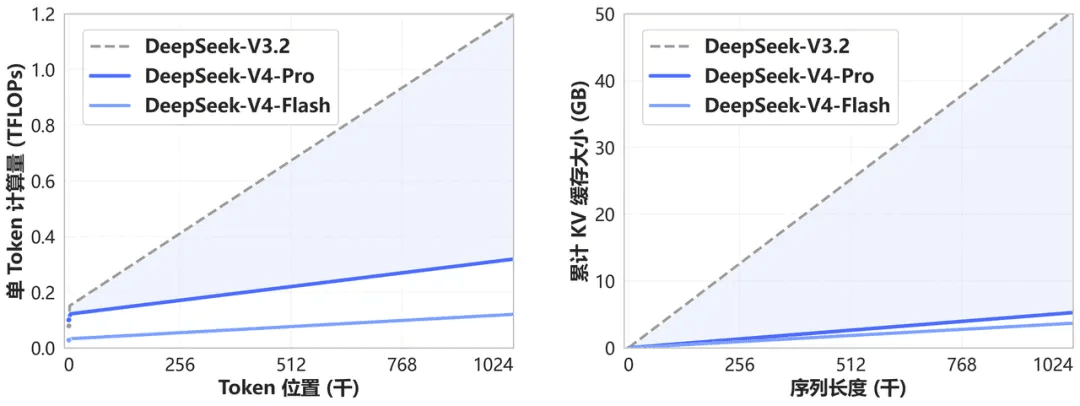
DeepSeek-V4 引入了一種全新的注意力機制,可在 token 維度上進行壓縮。結合 DSA (DeepSeek Sparse Attention),該設計實現了世界領先的長上下文性能,同時與傳統方法相比,大幅降低了計算和記憶體需求。
從現在起,100 萬 (1M) token 上下文將成為所有 DeepSeek 官方服務的標準。
針對 Agent 使用場景的專項優化
DeepSeek-V4 已針對包括 Claude Code, OpenClaw, OpenCode, 和 CodeBuddy 在內的主流 Agent 產品進行了微調與優化。在程式碼生成、文件撰寫及其他由 Agent 驅動的任務中,均觀察到了性能提升。
這種針對框架的特定調優在實踐中的重要性遠超預期。一個單獨運行良好的模型,如果無法在結構化的 Agent 循環中保持一致的表現,將難以可靠地部署。將主流 Agent 框架視為一等優化目標,反映了生產環境下 AI 使用方式的演進。
DeepSeek-V4 API 存取
V4-Pro 與 V4-Flash 現已透過 DeepSeek API 提供,並支援 OpenAI ChatCompletions 與 Anthropic 介面,這意味著現有的整合專案只需極少的程式碼改動即可切換至 V4 模型。Base_url 保持不變;只需將模型參數更新為 deepseek-v4-pro 或 deepseek-v4-flash 即可。
兩款模型均支援最高 100 萬 token 的上下文長度,並提供 非思考 (non-thinking) 與 思考 (thinking) 模式。在思考模式下,可以設置 reasoning_effort 參數為 high 或 max。對於複雜的 Agent 工作流,建議使用最大強度的思考模式。API 存取文件:https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
⚠️ 棄用通知: 舊版模型名稱
deepseek-chat與deepseek-reasoner將於 三個月後(2026 年 7 月 24 日) 正式退役。在過渡期間,它們將分別映射至deepseek-v4-flash的非思考與思考模式。如果您正在生產環境中使用這兩個名稱,請提前規劃遷移。
開源權重與本地部署
- 模型權重:Hugging Face | ModelScope
- 技術報告:DeepSeek-V4 PDF
對於考慮本地或私有化部署的團隊,值得注意的是,如此參數規模的模型(特別是總參數達 1.6T 的 V4-Pro)對硬體要求極高。開源可用性對於企業合規與客製化需求是一大優勢,但大多數團隊可能會發現雲端 API 存取是更切合實際的起點。
此次 DeepSeek-V4 發布的實際意義
此次發布有三個重點值得關注。
首先,對 100 萬 token 上下文的承諾 比看起來更有意義。DeepSeek 並非將其作為高端付費方案,而是作為所有官方服務的基礎配置。這釋放了一個關於開源前沿發展方向的信號,並對其他所有供應商形成了無形的壓力。
其次,以 Agent 為先的優化工作 — 特別是針對 Claude Code、OpenCode 等產品的適配 — 反映了 DeepSeek 在部署策略上的成熟。基準測試成績僅是門檻;對生產環境真正重要的是模型在開發者實際使用的工具內部的行為表现。
第三,相對於 Claude Opus 4.6 的誠實定位 非常值得稱道。DeepSeek 並未宣稱全面超越,而是給出了分層評估:優於 Sonnet 4.5,接近非思考模式的 Opus 4.6,在思考模式下則略遜於 Opus 4.6。這種明確性使得其聲明更具可信度。
對於正在評估 Agent 工作流、長文件處理或複雜推理任務模型的開發者而言,DeepSeek-V4-Pro 無疑是一個強大的開源競爭者。對於追求性價比或延遲敏感的管道,V4-Flash 也提供了一個可靠的輕量級替代方案。
在 Atlas Cloud 上體驗 DeepSeek-V4
Atlas Cloud 是一個生產級的 AI 平台,專為希望獲得可靠、高性價比且無需管理基礎設施的頂尖 AI 模型存取的開發者與團隊打造。透過統一的 API、透明的定價與企業級合規標準(符合 SOC 2 和 HIPAA),Atlas Cloud 讓您專注於產品構建而非維運。
DeepSeek 在 Atlas Cloud。 我們已支援 DeepSeek 模型系列,包括 DeepSeek V3.2, V3.2 Fast, V3.2 Speciale, 和 V3.2 Exp,現可透過單一 API 端點以具競爭力的價格使用。Atlas Cloud 上的 DeepSeek 模型針對長上下文工作負載與 Agent 流程進行了優化,支援完整的上下文視窗,且無量化損失。除了 DeepSeek, Atlas Cloud 還為您提供 LLM 生態中 300 多款模型 的存取權。
DeepSeek-V4 即將登陸 Atlas Cloud。 我們正積極整合 DeepSeek-V4-Pro 與 V4-Flash。請密切關注後續發布公告 — 同時,歡迎探索平台上已有的豐富功能。






