
DeepSeek API: Access V4, R1 & More Models with One OpenAI-Compatible Endpoint
Access the full DeepSeek API on Atlas Cloud! A unified OpenAI-compatible endpoint covering every model in the DeepSeek lineup. Whether you need the DeepSeek V4 API for frontier-grade reasoning, the DeepSeek V4 Pro API for 1M-token long-context tasks, the DeepSeek V4 Flash API for high-throughput low-latency workloads, the DeepSeek R1 API for chain-of-thought reasoning, or the DeepSeek V3 API and DeepSeek V3.2 API for production-grade text generation — one API key gets you instant access to all of them. No separate accounts, no rate-limit surprises, pay only for what you use.
Explore the Leading DeepSeek
Atlas Cloud provides you with the latest industry-leading creative models.
DeepSeek Models Comparison
Explore DeepSeek API models and compare their capabilities, context windows, pricing, and ideal use cases.
| Modality | Description |
|---|---|
| DeepSeek V4 Pro | DeepSeek V4 Pro is a flagship high-performance LLM designed for advanced reasoning, complex coding, and agentic workflows. Featuring a large-scale MoE architecture and 1M-token context capability, it delivers stronger intelligence for demanding tasks such as software development, research analysis, and multi-step problem solving where accuracy and reasoning depth are critical. |
| DeepSeek V4 Flash | DeepSeek V4 Flash is a high-efficiency LLM optimized for fast inference, scalable applications, and cost-sensitive production workloads. With a lightweight MoE architecture and 1M-token context capability, it provides a strong balance between performance and latency, making it suitable for AI agents, automation workflows, real-time applications, and high-volume API usage. |
| DeepSeek V3.2 | DeepSeek V3.2 is a flagship general-purpose LLM, integrating sparse attention mechanisms with robust 163.8K context processing capabilities; boasting highly competitive baseline pricing, it serves as the cornerstone for daily workflows, including complex general reasoning and building multi-step task-scheduling Agents. |
| DeepSeek V3.2 Speciale | DeepSeek V3.2 Speciale is positioned as a high-performance custom LLM, featuring a massive 163.8K context window and a premium tiered pricing structure ($0.4 input / $1.2 output), specifically designed for latency-sensitive core business nodes requiring ultimate output quality, such as intelligent customer service for high-net-worth clients or millisecond-level quantitative analysis. |
| DeepSeek V3.2 Exp | DeepSeek V3.2 Exp is a cutting-edge experimental version based on the V3.2 architecture, integrating the latest algorithmic features while maintaining a 163.8K context and comparable costs, making it ideal for R&D teams conducting technical pre-research and canary testing to preemptively validate the differentiating power of next-gen AI capabilities for future products. |
| DeepSeek-V3.1 | DeepSeek-V3.1 is the latest generation of high-performance open-source ecosystem models, achieving a new balance between performance and cost within a 131.1K context; as the top choice for commercial implementation projects, it acts as the backbone for scenarios requiring both high-quality generation and controllable costs. |
| DeepSeek V3.1 Terminus | DeepSeek V3.1 Terminus serves as the long-term stable ultimate form of the V3.1 series, DeepSeek V3.1 Terminus maintains identical parameters and pricing to the standard version, aiming to provide a perpetually stable output style and logic for seamless, consumer-facing production environment endpoint services. |
| DeepSeek-V3-0324 | DeepSeek-V3-0324 is a specific historical snapshot version featuring a 131.1K context and the lowest text input cost available, primarily applied in legacy system maintenance requiring absolute behavioral consistency, or batch processing tasks with massive input throughput but moderate output logic requirements. |
| DeepSeek-R1-0528 | DeepSeek-R1-0528 positioned as a top-tier deep reasoning model, utilizing a 131.1K context and commands the highest compute cost ($0.55/$2.15), representing the pinnacle of logical dialectic capabilities, exclusively used for critical "brainstorming" tasks like complex mathematical modeling and advanced code architecture generation. |
| DeepSeek OCR | DeepSeek OCR is a dedicated visual multimodal LLM that supports dual-track image-text input with a short 8.2K context and ultra-low usage costs, perfectly adapted for automated data entry pipeline scenarios such as the digitization of massive scanned documents and structured extraction of financial receipts. |
Key Features of DeepSeek APIs
Combining advanced models with Atlas Cloud's GPU-accelerated platform delivers unmatched speed, scalability, and creative control for image and video generation.
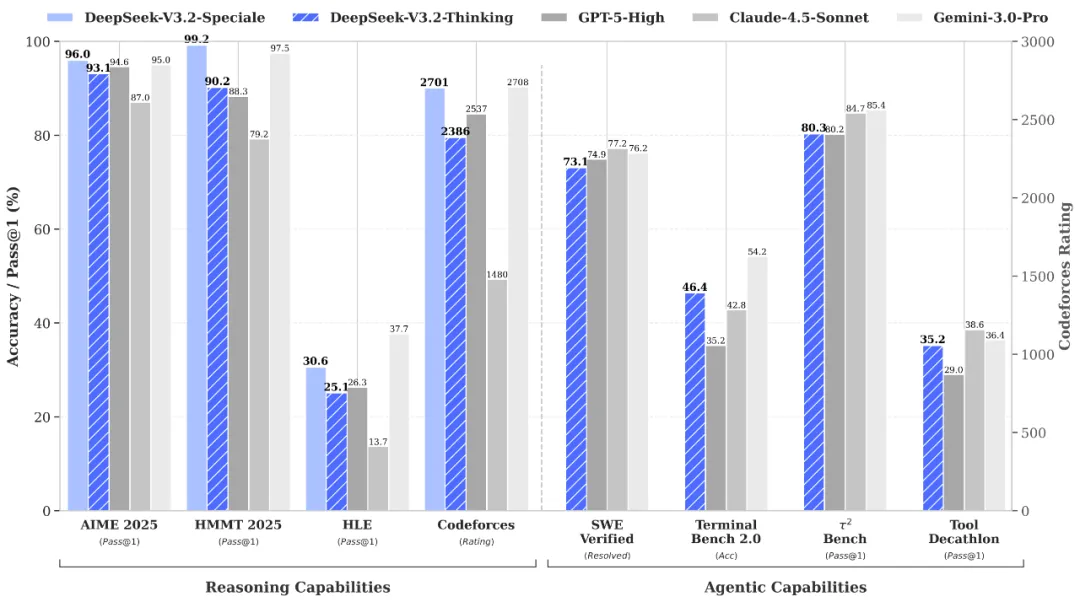
World-Class Reasoning & Verification via DeepSeek-V3.2-Speciale API
DeepSeek-V3.2-Speciale is the "long-thought" enhanced variant of the V3.2 architecture, integrating advanced theorem-proving capabilities from DeepSeek-Math-V2. Engineered for extreme precision, this model excels in rigorous mathematical proofing, complex logical verification, and superior instruction following, rivaling the performance of Gemini-3.0-Pro in mainstream reasoning benchmarks. It is the premier choice for academic research, automated formal verification, and high-stakes technical problem-solving where logical integrity is non-negotiable.
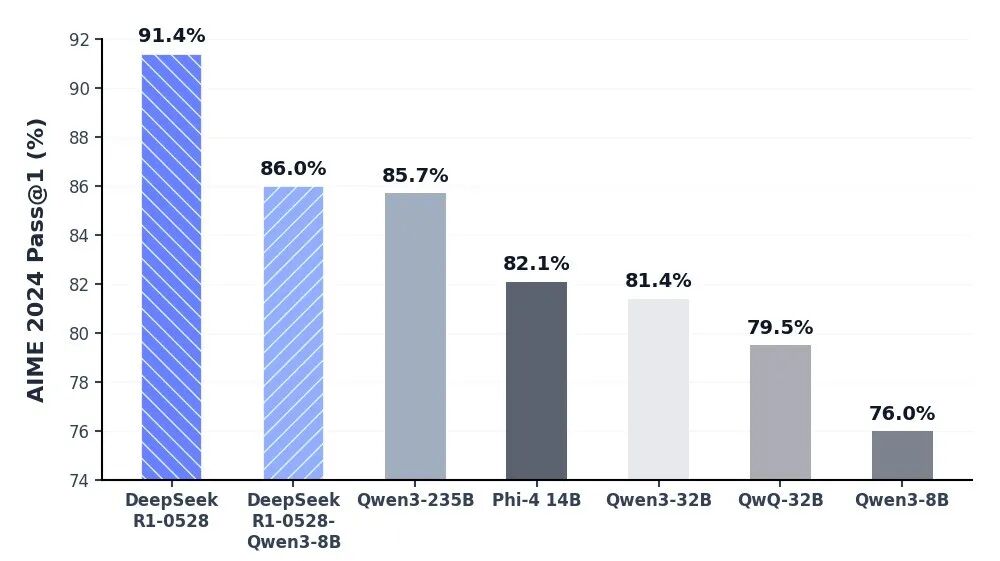
Unrivaled Cognitive Depth via DeepSeek-R1 API
The DeepSeek-R1 model stands at the forefront of reasoning AI, delivering industry-leading performance in mathematics, programming, and general logic. By achieving parity with elite global models such as OpenAI’s o3 and Gemini-2.5-Pro, R1 has redefined the capabilities of open-source intelligence. It is specifically optimized for deep-thinking tasks, including complex algorithmic development, sophisticated data synthesis, and advanced cognitive workflows that require multi-stage deductive reasoning.
What You Can Do with DeepSeek API
From chatbots to agentic pipelines, build what you need with one API.
Build Intelligent Chatbots
Integrate DeepSeek into your app to power multi-turn conversations. It handles context across long dialogues, making it suitable for customer support, virtual assistants, and internal helpdesks. Responses are fast and coherent even in complex exchanges.
Accelerate Code Generation
Use DeepSeek to write, review, and refactor code across major languages. It generates backend logic, API documentation, and unit tests from simple descriptions. Development cycles get shorter without sacrificing output quality.
Power Advanced Reasoning
DeepSeek R1 works through problems step by step before returning an answer. It performs well on math, logic, and research tasks where accuracy matters more than speed. Teams use it for data analysis, report synthesis, and technical decision support.
Automate Content Creation
Generate drafts, summaries, and structured copy at scale through a single API call. DeepSeek supports both English and Chinese natively, making it practical for global teams. Output can be templated and customized to match your brand voice.
Build Agentic Workflows
Connect DeepSeek to external tools and APIs to automate multi-step tasks. The model can plan, call tools, and adjust based on results within a single workflow. This makes it useful for autonomous research, scheduling, and process automation.
Run Cost-Efficient RAG Systems
Pair DeepSeek with your knowledge base to answer questions grounded in real data. Built-in context caching reduces token costs on repeated queries. It is a practical choice for high-volume search, document Q&A, and enterprise knowledge retrieval.
Model Comparison
See how models from different providers stack up — compare performance, pricing, and unique strengths to make an informed decision.
| Model | Context | Max Output | Input | Positioning |
|---|---|---|---|---|
| DeepSeek V4 Pro | 1M | 384K | Text | Flagship Reasoning |
| DeepSeek V4 Flash | 1M | 384K | Text | Fast & Economical |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flagship General |
| DeepSeek V3.2 Speciale | 163.84K | 163.84K | Text | High-Performance Custom |
| DeepSeek V3.2 Exp | 163.84K | 163.84K | Text | Experimental Build |
| DeepSeek-V3.1 | 131.07K | 65.54K | Text | Open-Source Backbone |
| DeepSeek V3.1 Terminus | 131.07K | 65.54K | Text | Long-Term Stable (LTS) |
| DeepSeek-V3-0324 | 131.07K | 32.77K | Text | Historical Snapshot |
| DeepSeek-R1-0528 | 131.07K | 131.07K | Text | Top-Tier Reasoning |
| DeepSeek OCR | 8.19K | 8.19K | Text | Dedicated Multimodal |
| GLM-5 | 200K | 128K | Text | Flagship Foundation Model |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA Agentic Coding |
How to Use DeepSeek on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud's platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Why Use DeepSeek on Atlas Cloud
Combining the advanced DeepSeek models with Atlas Cloud's GPU-accelerated platform provides unmatched performance, scalability, and developer experience.
Performance & flexibility
Low Latency:
GPU-optimized inference for real-time reasoning.
Unified API:
Run DeepSeek, GPT, Gemini, and DeepSeek with one integration.
Transparent Pricing:
Predictable per-token billing with serverless options.
Enterprise & Scale
Developer Experience:
SDKs, analytics, fine-tuning tools, and templates.
Reliability:
99.99% uptime, RBAC, and compliance-ready logging.
Security & Compliance:
SOC 2 Type II, HIPAA alignment, data sovereignty in US.
What People Asked about DeepSeek API
Atlas Cloud provides an OpenAI-compatible DeepSeek API that allows developers to access models such as R1, V4, V4 Pro, and V4 Flash through a single endpoint. This makes it easy to integrate DeepSeek models into existing applications without learning a new API format. Developers can use the same workflows and tooling they already use for OpenAI-based projects.
Yes. Atlas Cloud is fully compatible with the OpenAI SDK, allowing developers to connect DeepSeek models using the same client libraries and request formats. In most cases, migrating an existing application only requires updating the API key and endpoint URL rather than rewriting application logic.
To use DeepSeek API with the OpenAI SDK, simply configure your client to use the Atlas Cloud endpoint and API key. Existing code examples, integrations, and SDK workflows can typically be reused with minimal modifications. This helps developers get started quickly and reduces migration effort.
Atlas Cloud supports a growing range of DeepSeek models, including R1, V4, V4 Pro, and V4 Flash. All supported models are accessible through a unified API endpoint, making it easy to switch between models based on performance, speed, or cost requirements without changing your integration approach.
No. Atlas Cloud follows an OpenAI-compatible API structure, so most applications can continue using their existing SDK code and request patterns. Developers generally only need to update configuration settings such as the API endpoint and authentication credentials, significantly reducing migration time.
Yes. Because Atlas Cloud provides an OpenAI-compatible endpoint, it can be integrated with popular frameworks such as LangChain and LlamaIndex. Developers can usually connect DeepSeek models by updating configuration settings, enabling them to build AI agents, RAG systems, and production applications using existing workflows.
Yes. Atlas Cloud provides a consistent API interface across supported DeepSeek models, making it easy to switch between R1, V4, V4 Pro, and V4 Flash. This flexibility allows developers to optimize for reasoning quality, response speed, or cost without changing their application architecture.
Explore More Families
Seedance 2.0
The Seedance 2.0 API gives you production access to ByteDance's multimodal video model — quad-modal inputs (text, image, video, audio) and an industry-leading "Universal Reference" system that locks composition, camera movement, and character actions across shots. Integrate director-level control with one API call, a flat $0.09/s, instant key, and no waitlist — backed by enterprise-grade uptime and compliance. Seedance 2.0 Native 4K is now live!
Grok Imagine
The Grok Imagine API gives developers xAI's image, video, and audio generation in one suite. It produces up to 2K images with multilingual text rendering, plus video up to 15 seconds with native, synchronized audio and reference-based editing. On Atlas Cloud one key runs every Grok Imagine mode, so you move between image, video, and audio without separate setups, from $0.02 per image and $0.05 per second.
Gemini Omni Flash
The Gemini Omni API brings Google DeepMind's multimodal video generation and editing model, introduced at Google I/O 2026, to your stack. Gemini Omni fuses Gemini's reasoning engine with generative media, accepting any mix of text, images, video, and audio to produce consistent, knowledge-grounded output. Refine results through natural conversation, swapping objects, rewriting scenes, and shifting styles while physics, characters, and continuity stay intact. Atlas Cloud serves the full Gemini Omni Flash lineup, text-to-video, image-to-video with up to 7 reference images, and reference-to-video, through one unified API with transparent per-second pricing from $0.112 and no subscription. Start building today.
GPT Image 2
The GPT Image 2 API gives developers access to OpenAI's latest image model, the successor to GPT Image 1.5. It generates and edits images with accurate text rendering across Latin and CJK scripts, plus strong composition for posters, mockups, and infographics. On Atlas Cloud you reach it through one unified API alongside 300+ models, with free credits, 99.99% uptime, and no OpenAI organization verification required.
Google's most powerful creative models are all available on Atlas Cloud. Veo 3.1 delivers cinematic video generation, Nano Banana 2 powers high-fidelity image creation, and Gemini brings multimodal intelligence to every workflow. Access the full Google model suite through one API key with Day-0 availability and pay-as-you-go pricing.
Seedance 2.0 Mini
The Seedance 2.0 Mini API is the lightest, lowest-cost tier of ByteDance's Seedance video line, built for teams where throughput and unit cost matter more than maximum polish. Use it for batch generation, rapid prototyping, and draft passes, all through one OpenAI-compatible key on Atlas Cloud.
ByteDance
From cinematic video generation to high-fidelity image creation, ByteDance's most powerful models are live on Atlas Cloud. Run Seedance and Seedream at scale with the lowest inference pricing and zero infrastructure overhead.
Alibaba
Atlas Cloud brings together Alibaba's full model lineup under one API: Qwen for language and image tasks, Wan for video generation up to 1080p. Access every model pay-as-you-go with no subscriptions. The Alibaba API is available via a single base URL using your existing OpenAI-compatible client.
OpenAI
Atlas Cloud gives you access to the full OpenAI API lineup, from GPT Image 2 for image generation to Sora 2 for video. Every model is available pay-as-you-go with no monthly commitment. Plug in with a single base URL swap using the OpenAI-compatible API.
xAI
Build complete image and video pipelines using the xAI API on Atlas Cloud. Generate at 2K, edit with reference images, and animate images into audio-synced clips.
Kwaivgi
The Kwaivgi API at 15% off standard rates. Day-0 access to every new Kling release, pay-as-you-go, no seat limits. One account covers the full Kling lineup.
Seedream 5.0 Pro
Seedream 5.0 Pro API gives developers ByteDance's controllable image editing model on Atlas Cloud. It places edits precisely with anchors and coordinates, separates images into editable layers, fuses multiple references, and matches exact colors and materials, with multilingual text at 2K and 3K. On Atlas Cloud you reach it through one key!


