
和所有人一樣,我剛開始接觸 AI 生成圖片時也被深深吸引。但當我需要將圖片生成功能嵌入到真正的產品中時,對話的焦點就完全改變了。
大多數用戶看到的是一個提示詞輸入框。而我看到的是 API 端點、延遲預算和每月帳單。
為生產環境的流水線選擇最佳 AI 圖片 API,與挑選心儀的網頁 UI 完全不同。突然間,真正重要的問題變成了:
- 圖片品質在大規模使用下表現如何?
- 達到 10,000 次請求後的 API 定價是多少?
- 是否有可靠的開發者工具用於監控和重試機制?
Midjourney API 替代方案的爆發讓這個決定變得更難,也更有趣。每個供應商都大膽宣稱自己的優勢,但這些宣稱在面對真實的程式碼庫時往往會破滅。
我的目標很簡單:為開發者提供我當初開發時所渴望的誠實、並排的分析結果。
讓我們開始吧。
深度剖析:正面對決
A. GPT Image 2.0:智慧邏輯的領導者
在我測試過的所有 Midjourney API 替代方案中,GPT Image 2.0 之所以脫穎而出,原因只有一個:它真的會「思考」你的要求。
特色之處
大多數模型只是將你的提示詞與視覺美學進行模式匹配,而 GPT Image 2.0 能以極高的準確度處理分層的、關係性的指令。告訴它將某個物體放在另一個物體的「後面」,或者放在第三個元素的「左側」——它通常都能達成。這種空間推理能力在過去一直是影像生成器的弱點。
文字渲染是另一個真正的強項。標誌、標籤、招牌、UI 模型——這也是我在這五個競爭者中,將它的圖片品質評估始終排在第一位的地方。

為了測試 GPT Image 2.0,我設計了一個針對三個主要目標的提示詞。我檢查了分層物體的空間邏輯,使用不同字體進行長篇文字測試來檢驗文字品質,並將現代 App 設計與傳統木刻藝術相結合。
優勢概覽
| 能力 | 表現 |
| 空間/關係推理 | ★★★★★ |
| 圖片內文字渲染 | ★★★★★ |
| 複雜的多元素佈局 | ★★★★☆ |
| 風格靈活性 | ★★★☆☆ |
我注意到的取捨
它並非完美無缺。在我的 API 定價比較中,我發現高解析度輸出受到更嚴格的使用等級限制——這意味著成本比其他** AI 開發者工具**上升得更快。在 1024×1024 解析度下的延遲也明顯高於更輕量的替代方案。
適用場景
- 繪圖工具與技術插圖流水線
- 任何對圖片內文字準確度有嚴格要求的產品
- UI 模型生成器或設計輔助應用程式
如果精確的佈局控制是你的優先事項,它是你技術棧中最佳 AI 圖片 API 的有力候選者。
B. Stable Diffusion / Stability AI:客製化夢想
如果說 GPT Image 2.0 是能「理解」你提示詞的模型,那麼 Stable Diffusion 就是讓你進行「工程化」的模型。對於想要對每個輸出變數進行精細控制的開發者來說,這個生態系統在 Midjourney API 替代方案中獨樹一幟。
差異所在
這裡真正的強大之處不在於基礎模型,而在於周邊工具。特別是以下兩個功能,形塑了我處理 AI 開發者工具流水線的方式:
- ControlNet — 透過輸入參考姿勢、深度圖或邊緣線來鎖定構圖。生成圖片的一致性變得切實可行。
- LoRAs (低秩適應) — 無需完全重新訓練,即可針對特定風格、角色或產品美學對模型進行微調。對於品牌一致性的輸出,沒有其他工具能與之媲美。
這個結果展示了 Stable Diffusion 工程工作流的精確度。透過利用 ControlNet 鎖定原始構圖,並結合 LoRA 增強電影感美學,我們將一個簡單的參考轉化為高保真、風格一致的系列圖片——證明了為什麼它是精細創意控制的終極工具。
能力快照
| 功能 | SD XL | SD 3 |
| ControlNet 支援 | ✅ 成熟 | ✅ 擴展中 |
| LoRA 微調 | ✅ 廣泛 | ✅ 支援 |
| API 穩定性 | ★★★★☆ | ★★★☆☆ |
| 文件品質 | ★★★☆☆ | ★★★☆☆ |
真正的隱憂
在完成這次圖片品質評估後,我的誠實看法是:它的結果上限很高,但學習成本也很高。文件非常零散——SDXL 和 SD3 的行為方式差異很大,因此指南往往無法直接通用。請為上線準備預留比你預期更多的時間。
在觀察 API 價格時,運行自己的伺服器確實可以顯著降低每張圖片的成本。這節省了錢,但你的團隊需要花費更多精力來維護系統運行。
適用場景
- 大規模電子商務產品影像
- 建築視覺化流水線
- 任何需要在數千個輸出中鎖定品牌美學的應用程式
對於擁有深厚技術背景的團隊來說,這仍然是客製化工作流中最佳 AI 圖片 API 最強大的候選者之一。
C. Flux.1 (透過 FAL.ai / Replicate):寫實主義的新王
當我進行專注於照片寫實主義的純圖片品質評估時,Flux.1 始終名列前茅。它由 Black Forest Labs 開發,並可透過 FAL.ai 和 Replicate 等平台存取,已成為生產環境中最受關注的 Midjourney API 替代方案之一。
真正優異之處
在我的測試中,有兩個領域表現突出:
- 照片寫實主義 — 皮膚紋理、光影漸層、材質表面。Flux.1 Pro 產出的內容通常能騙過一般人的眼睛。
- 圖片內文字渲染 — 這是它與幾乎所有競爭對手區分開來的地方。在生成的圖片中實現可讀且位置準確的文字是非常困難的。Flux.1 處理得比我測試過的任何產品都要好。

Pro 版本(右)展示了更優越的提示詞遵循能力,能準確渲染複雜文字和逼真的皮膚紋理,並帶有電影般的散景效果。相比之下,Schnell(左)顯示出輕微的拼寫錯誤和一種更「AI 味」的加工美學。
模型等級比較
| 模型版本 | 速度 | 品質 | 最佳應用場景 |
| Flux.1 Pro | 較慢 | ★★★★★ | 行銷資產、主圖 |
| Flux.1 Dev | 中等 | ★★★★☆ | 原型設計、疊代 |
| Flux.1 Schnell | 快速 | ★★★☆☆ | 高吞吐量、速度優先的流水線 |
誠實的取捨
從 API 定價比較的角度來看,相較於基於 SD 的選項,Flux.1 Pro 每張圖片的運算成本很高。此外,作為一個較新的生態系統,它缺乏 Stable Diffusion 那種豐富的社群 LoRA、工作流和「配方」,這些資源使得 Stable Diffusion 對經驗豐富的團隊來說非常「隨插即用」。
圍繞它的 AI 開發者工具正在快速改進,但成熟度仍落後於較舊的生態系統。
適用場景
- 需要高視覺保真度資產的社交媒體自動化
- 圖片內文字準確度直接影響輸出品質的行銷流水線
- 優先考慮寫實主義而非微調靈活性的團隊,並尋求最佳 AI 圖片 API
D. Google Imagen (Vertex AI):企業級的工作馬
當討論從創意實驗轉向受監管的大規模部署時,Vertex AI 上的 Google Imagen 的定位就與列表中其他選項不同了。與其說它是一個創意工具,不如說它是一個具備合規性的基礎設施決策。
定義特徵
Imagen 並不試圖贏得藝術風格比賽。它是為那些審計能力、安全性和平台整合優先於風格範圍的組織所建構的。這兩個功能使它在這個 API 定價比較中處於獨特地位:
- SynthID — Google 專有的數位浮水印技術,隱形嵌入到生成的圖片中,用於來源追蹤。對於法律和合規團隊來說,這是一個重大的區別。
- 企業級安全控制 — 內容過濾、使用政策執行和存取控制,滿足受監管產業實際需要的標準。

這個整合基準測試圖片展示了 Google Imagen 的企業級精確度。它能輕鬆地將法律、醫療實驗室和汽車廣告這三個不同的領域納入一個井然有序的佈局中。最終的效果聚焦於穩定的工作氛圍、樸實的色彩和逼真的質感。這使它成為那些需要遵循嚴格規範並通過審計的產業中,安全且可靠的選擇。
企業就緒程度評分表
| 標準 | Google Imagen | 產業平均 |
| AI 浮水印 (SynthID) | ✅ 原生 | ❌ 罕見 |
| GCP IAM 整合 | ✅ 完整 | ❌ 有限 |
| 內容安全控制 | ★★★★★ | ★★★☆☆ |
| 藝術風格範圍 | ★★★☆☆ | ★★★★☆ |
真正的限制
從 AI 開發者工具的角度來看,Imagen 幾乎完全存在於 Google Cloud Platform 生態系統中。如果你的技術棧還沒有與 GCP 對接,上線阻力會很大。這也不是我會建議任何針對美學或行銷導向用例進行純圖片品質評估的對象使用的工具。
適用場景
- 需要圖片來源追蹤的財星 500 強企業內部工具
- 需要可審計 AI 輸出的醫療、金融和法律平台
- 已經在使用 GCP 並尋求具有內建治理功能的 Midjourney API 替代方案的團隊
對於受監管的產業,這很可能就是最佳 AI 圖片 API 選項——不是因為它最漂亮,而是因為它最經得起審查。
E. DALL-E 3 (OpenAI):省心的「設定後即忘」選項
在本次比較的所有選項中,DALL-E 3 是我最放心交給非技術產品團隊且無需再過問的產品。這並非貶義——在某些部署環境中,低維護的可靠性正是你所需要的。
改變一切的功能
DALL-E 3 之所以出眾,是因為它使用 GPT-4 即時重寫提示詞。它會獲取你的基礎想法並在生成圖片前自動進行修飾。它能修正混亂的措辭、釐清困惑,並為你添加缺失的細節。對於終端用戶提示詞不可預測且極度不一致的應用程式來說,這是一個真正的救星,沒有其他 Midjourney API 替代方案能原生複製這種等級的功能。

這個測試有效證實了 DALL-E 3 作為**「設定後即忘」**選項的地位。即使輸入結構鬆散,它也能優化邏輯,產生構圖良好、細節豐富且具有商業吸引力的圖片,使其成為用戶輸入提示詞品質難以預測的消費級 App 的理想選擇。
可靠性快照
| 因素 | DALL-E 3 | 備註 |
| 提示詞穩健性 | ★★★★★ | GPT-4 重寫功能緩解了糟糕輸入 |
| 安全過濾 | ★★★★★ | 有時過於敏感 |
| 單圖成本 | ★★☆☆☆ | 比大多數替代方案高 |
| 風格靈活性 | ★★★☆☆ | 紮實,但不突出 |
不足之處
我的圖片品質評估發現 DALL-E 3 表現始終如一,但很少有驚艷之處。更大的摩擦點在於它的內容過濾——它可能會對完全無害的提示詞觸發過濾,這在生產環境中會造成尷尬的用戶體驗失敗。這是設計時必須考量的實際工程問題。
從 AI 開發者工具的角度來看,OpenAI API 成熟、文件詳盡,並能乾淨地整合到大多數技術棧中。
適用場景
- 聊天機器人與對話式創意助手
- 終端用戶提示詞品質無法預測的消費級 App
- 希望獲得最少運維負擔的 最佳 AI 圖片 API 的團隊
如果你的優先事項是可靠性而非輸出品質的上限,DALL-E 3 值得在你的技術棧中佔有一席之地。
壓力測試:相同提示詞,五種模型
閱讀規格只能說明一半的故事。真正的圖片品質評估發生在對每個模型運行相同的提示詞,並讓輸出結果說明一切的時候。這正是我的做法——而且針對兩種類型完全不同的提示詞分別測試了兩次。
測試 1:照片寫實主義 + 空間推理挑戰
提示詞主題: 一個未來派醫療實驗室場景,包含醫生、機械手臂、診斷顯示器,以及特定的可讀 UI 文字。

這個測試同時針對空間構圖、照明寫實主義和圖片內文字準確度進行檢測。
| 模型 | 照片寫實主義 | 空間佈局 | 文字可讀性 |
| GPT Image 2.0 | ★★★★★ | ★★★★★ | ★★★★★ |
| Stability AI | ★★★★☆ | ★★★★☆ | ★★★☆☆ |
| Flux.1 | ★★★★★ | ★★★★☆ | ★★★★☆ |
| Google Imagen | ★★★★☆ | ★★★☆☆ | ★★★☆☆ |
| DALL-E 3 | ★★★★☆ | ★★★★☆ | ★★★☆☆ |
GPT Image 2.0 將 "SYSTEM-DIAGNOSTICS v0.2" 和 "SMART CLINIC" 渲染得近乎完美。Stability AI 的照片寫實主義令人印象深刻,但診斷螢幕上的文字在仔細觀察下顯得模糊。
測試 2:文字渲染挑戰賽
提示詞主題: 一個兒童奇幻故事書場景,包含一個木製招牌,上面有四行特定的文字以及一個導覽選單。

這是大多數模型差異顯著的地方。
| 模型 | 招牌文字準確度 | 選單標籤 | 整體可讀性 |
| GPT Image 2.0 | ✅ 4 行皆正確 | ✅ 4 個皆正確 | ★★★★★ |
| Stability AI | ❌ 正文亂碼 | ⚠️ 部分正確 | ★★☆☆☆ |
| Flux.1 | ⚠️ 輕微錯誤 | ⚠️ 部分正確 | ★★★☆☆ |
| Google Imagen | ⚠️ 部分錯誤 | ⚠️ 部分正確 | ★★★☆☆ |
| DALL-E 3 | ✅ 大致準確 | ✅ 大致正確 | ★★★★☆ |
差距十分巨大。GPT Image 2.0 準確地渲染了每一行——包括 "AD 2026"——而 Stability AI 的故事書頁面則退化為看起來像樣但毫無意義的亂碼。對於任何關心圖片內文字可讀性的 AI 開發者工具流水線來說,這些結果具有決定性。
我的總結: 當進行真實世界的 API 比較以評估輸出品質時,文字渲染仍然是最可靠的差異化因素。如果文字無法閱讀,每張圖片付出的更多費用就毫無意義。
決策矩陣:你應該選擇哪一個?
在對每個模型運行相同的提示詞並仔細審查輸出後,我想直奔核心問題:你到底應該整合哪一個 AI 圖片 API?
誠實的答案是,沒有通用的贏家——只有最適合特定用例的選擇。以下是我的分類方式。
快速決策矩陣:
| 用例 | 優先級 | 推薦 API | 原因 |
| 高吞吐量、對成本敏感的流水線 | 單圖價格 | Stable Diffusion | 自託管可大幅降低邊際成本 |
| 終端用戶提示詞不可預測的 App | 零摩擦 UX | DALL-E 3 | GPT-4 的提示詞重寫功能可自動處理混亂的輸入 |
| 帶有可讀文字的照片寫實廣告 | 視覺保真度 | Flux.1 | 同級最佳的寫實感與圖片內文字準確度 |
| 複雜的佈局、圖表、精確的文字 | 空間推理 | GPT Image 2.0 | 無與倫比的指令遵循與文字渲染能力 |
| 受監管產業或企業 GCP 技術棧 | 合規性 | Google Imagen | SynthID 浮水印與企業級安全控制 |
用例 A:最大吞吐量、最低成本
如果你每天生成數千張圖片,每張圖片的成本會迅速累積。Stable Diffusion——特別是透過 Replicate 或你自己的 GPU 基礎設施進行自託管——是此列表中唯一能讓邊際成本在規模化時接近零的 AI 圖片 API。
用例 B:精美藝術、無需用戶介入
對於用戶不是提示詞工程師的消費級創意工具,DALL-E 3 的自動提示詞優化功能消除了最大的故障點:垃圾輸入導致垃圾輸出。
用例 C:帶有文字的照片寫實廣告
行銷流水線的成敗取決於視覺品質和品牌準確的文案。Flux.1 Pro 是這裡的答案——它是我測試過在結合寫實感與清晰、拼寫正確的圖片內文字方面最可靠的模型。
沒有單一的 AI 圖片 API 在各個維度上都能佔據統治地位。挑選一個在你可以承受的弱點方面較弱,但在你的產品若沒有它就會崩潰的關鍵領域表現最強的模型。
開發者整合提示
選擇正確的 AI 圖片 API 只是工作的一半。你的整合方式決定了你的流水線是健壯的,還是隨時會發生凌晨 3 點事故的未爆彈。這是我用慘痛教訓學到的心得。
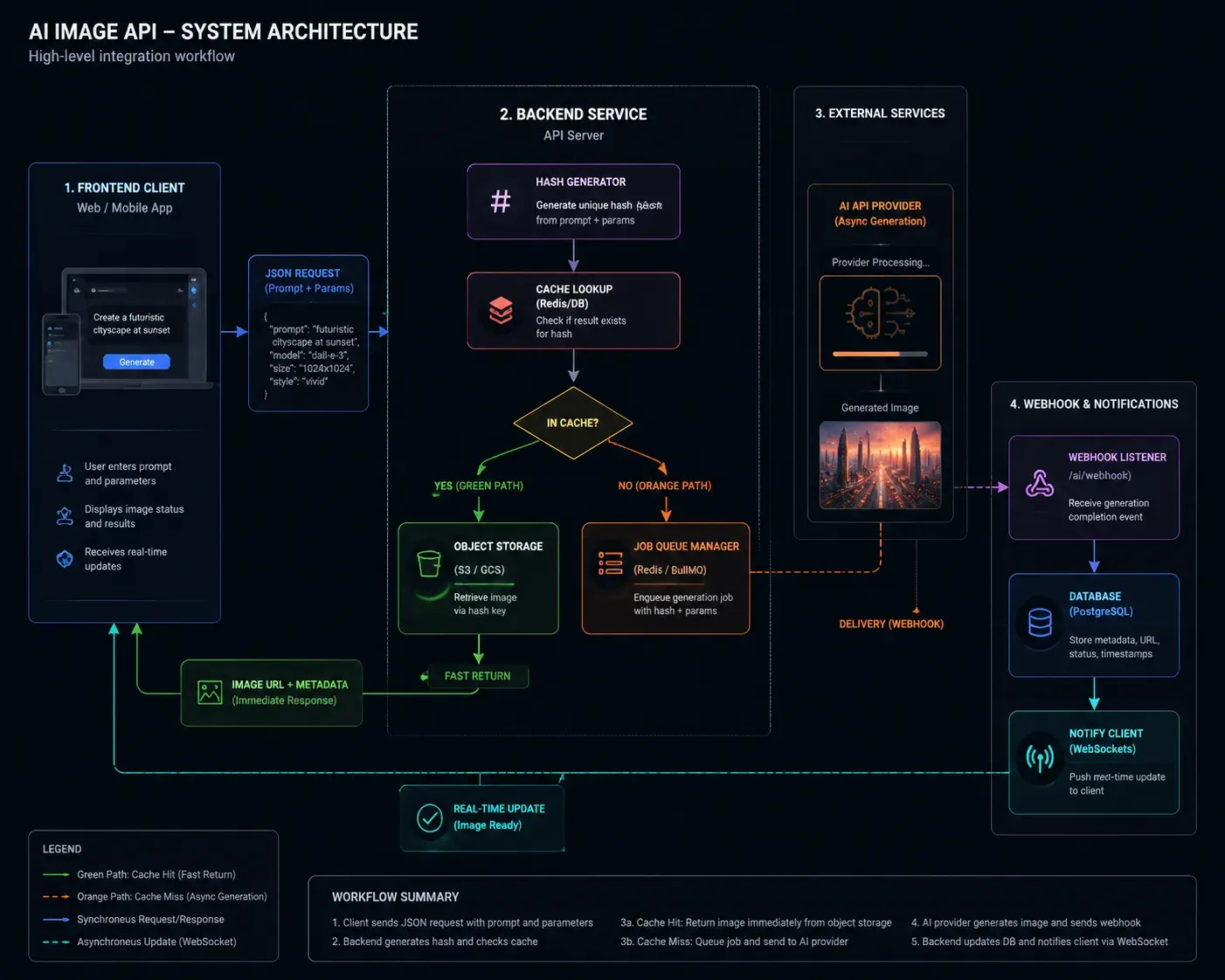
快取策略:別再為同一張圖片付兩次錢
圖片生成既昂貴又經常重複。如果你的 App 生成產品影像、頭像或基於模板的資產,很大一部分請求在語義上是完全一樣的。
我的建議做法:
- 將提示詞 + 參數(模型、解析度、隨機種子)雜湊(Hash)為快取鍵
- 將輸出儲存在物件儲存(S3, GCS)中,並以雜湊值作為檔案名稱
- 在每次 API 呼叫前檢查快取——在生產環境的模板流水線中,30–40% 的快取命中率是很常見的
- 根據內容類型設定 TTL:長青資產(較長),依賴趨勢的內容(較短)
這一模式可以在不影響輸出品質的情況下,大幅降低你的每月 API 帳單。
Webhook 處理:不要阻塞非同步生成
大多數高品質模型——特別是 Flux.1 Pro 和高解析度下的 Stable Diffusion——都是非同步的。生成可能需要 10–30 秒。阻塞一個同步輪詢的用戶前端執行緒是一個可靠性反模式(Anti-pattern)。
更好的架構:
- 提交生成請求 → 取得 Job ID
- 將 Job ID 與用戶工作階段(Session)儲存在資料庫中
- 處理 Webhook 回呼以更新狀態
- 當準備好時,透過 WebSocket 或 SSE 通知前端
成本管理:在需要之前設定硬性上限
遞迴迴圈——即失敗的生成無限重試——是意外 API 帳單的最常見來源。我曾見過測試環境一夜之間累積了四位數的費用。
在正式上線前執行這些措施:
- 在伺服器端強制執行每用戶每日生成上限
- 帶有最大重試次數上限的指數退避(Exponential backoff)(3 次,而非無限)
- 在每月預算達到 50%、80% 和 100% 時觸發支出警報
開發者評估架構
在評估任何 AI 圖片 API 時,我會根據五個維度進行評分,而不僅僅是輸出的美學效果:
| 維度 | 我實際衡量的是什麼 |
| 延遲與吞吐量 | 在負載情況下,1024×1024 圖片的首位元組時間 (TTFB) |
| 提示詞遵循度 | 是否能準確遵循多子句、關係性指令? |
| 營運難易度 | SDK 品質、認證流程複雜度、文件完整性 |
| 功能表面 | Inpainting、Outpainting、Image-to-Image、ControlNet 支援 |
| 成本效益 | 每 1,000 張可用(非被過濾)圖片的加權成本 |
最後一個指標是大多數開發者忽略的。一個過濾器拒絕率高達 15% 的廉價 API,在實踐中比一個稍貴但拒絕率近乎為零的 API 更昂貴——因為你一直在為那些永遠無法送達給用戶的生成結果付費。
請根據生產環境的現實,而非基準測試截圖來建立你的評估體系。
結論:圖片 API 的未來
在將每個模型都經過相同的提示詞、定價試算表和生產場景測試後,一個結論不斷浮現:沒有單一的 AI 圖片 API 能贏得一切。
我在成熟的開發者流水線中看到的智慧架構,不是對單一模型的承諾,而是多模型路由層:
- Flux.1 用於照片寫實的行銷資產
- DALL-E 3 用於不可預測的消費者提示詞
- Stable Diffusion 用於高容量、成本敏感的工作負載
- GPT Image 2.0 用於精確佈局和文字關鍵的輸出
- Google Imagen 當合規性不可妥協時
這不是過度設計。這是將圖片生成視為成熟團隊處理資料庫的方式——透過簡潔的內部 API 抽象,為正確的工作選擇正確的工具。
模型會持續改進,定價會持續變動。不會變的是,親自測試這些模型,而不是盲目信任供應商基準測試頁面的價值。
這正是本文中壓力測試存在的目的——真實的提示詞、真實的輸出、真實的差異。使用它們來做出比我第一次嘗試時更好的建置決策。






