Gemini Omni 是傳統 AI 系統的一大轉變。它作為一種多合一 AI 模型,從設計之初就能自然地處理資訊。它並非將不同的工具拼湊在一起來處理各類媒體,而是完全運行在單一的通用神經引擎上。透過在一個單一的跨模態向量空間內處理文字、圖像、音訊和視訊,它徹底消除了傳統資料孤島和通訊瓶頸。
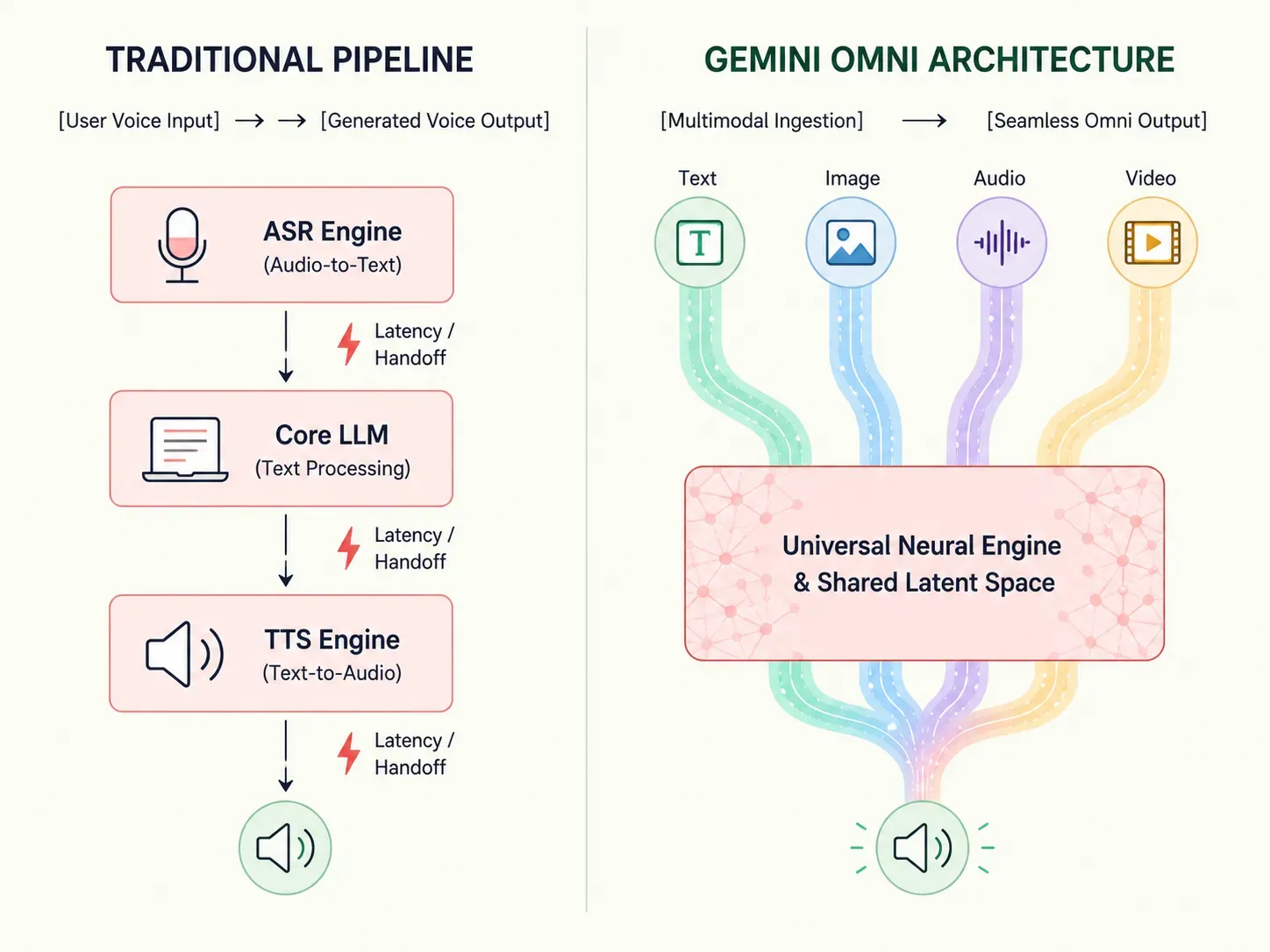
傳統人工智慧依賴交錯的管線——必須先將語音轉換為文字,語言模型才能開始處理答案。Gemini Omni 從根本上重新定義了這個工作流程。
- 原生攝取 (Native Ingestion): 系統可同時處理文字 Token、圖像像素、音訊頻率和視訊影格。
- 上下文保留 (Context Preservation): 端到端的資料處理確保細微的情感、視覺提示和細節不會在不同層級之間遺失。
這種架構上的轉變提升了處理效率,並將延遲降低至接近人類反應的速度。開發人員和企業現在可以跳過複雜的多模型配置,轉而依賴專為真正的多感官運算而構建的單一穩健系統。
單一模型如何同時運算四種模態
要了解 Gemini Omni 功能 如何同時處理文字、圖像、音訊和視訊,我們必須直接觀察其核心資料層。傳統系統透過分離且孤立的子模型來路由不同的檔案類型;而 Gemini Omni 完全繞過了這種碎片化的方法。它實作了一個統一的分詞框架 (Unified tokenization framework),將所有輸入原生轉換為 AI 核心能理解的單一語言。
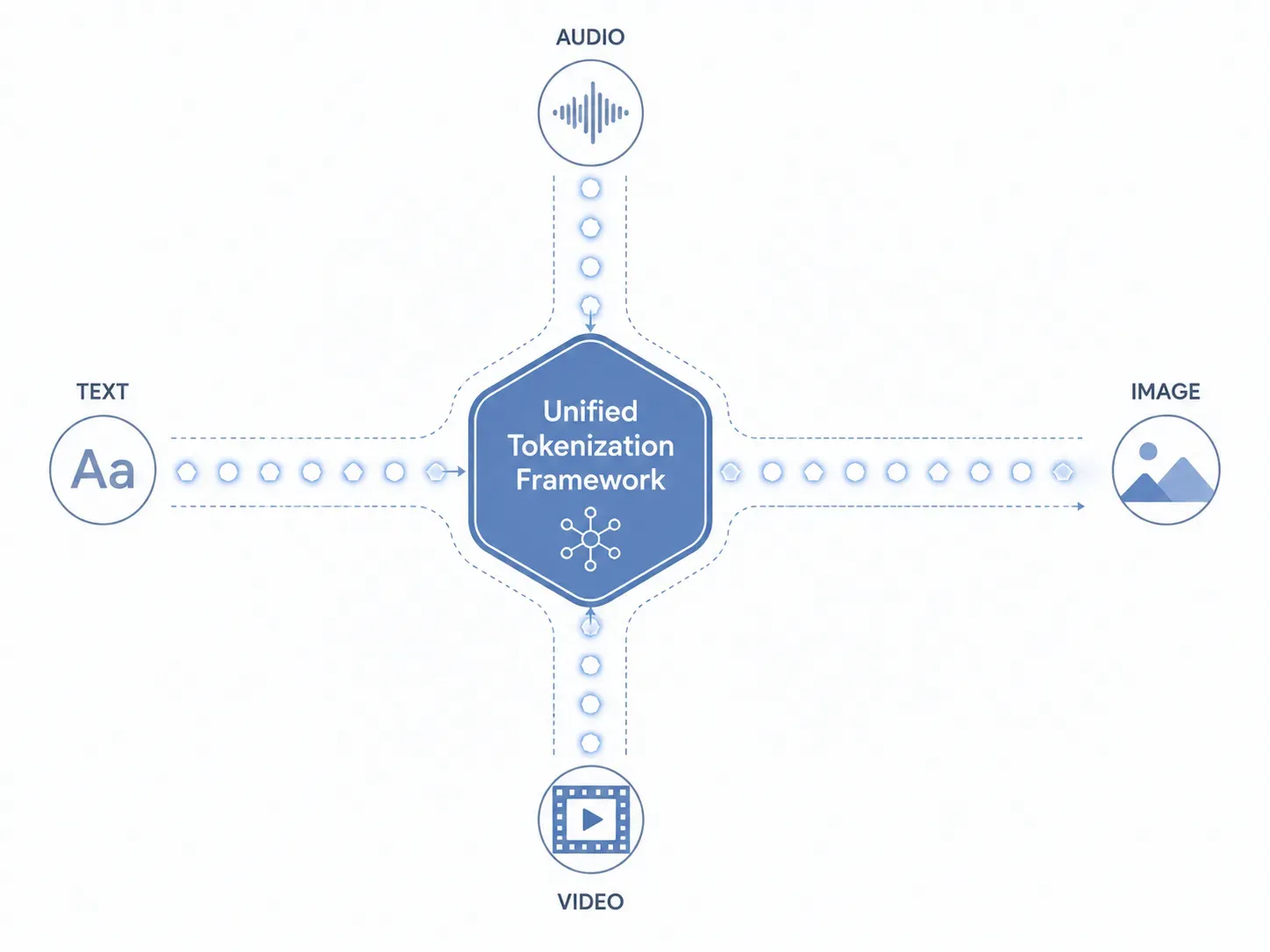
統一分詞的運作機制
Gemini Omni 如何在沒有獨立子模型的情況下處理不同的檔案類型?答案在於資料在推理開始前的攝取與解析方式:
- 文字: 將字母數字字元轉換為標準語意文字 Token。
- 圖像: 將視覺元素切分為小的像素區塊,並映射為視覺 Token。
- 音訊: 對連續聲波進行取樣,擷取頻率與音調,並轉換為聲學 Token。
- 視訊: 將移動影像視為時間影格的連續序列,建立時空 Token。
共享權重與原生張量處理
一旦這種多樣化的多模態資料攝取完成,所有資料類型都會進入一個共享權重架構。模型不需要透過引發延遲的橋接器在個別專業編碼器之間來回傳遞資料,而是由單一核心神經網路統一處理所有 Token。
透過原生張量處理,模型在相同的矩陣層內對文字、音訊和視覺 Token 執行數學運算。由於一切都在同一個運算空間內共享,網路無需任何轉換步驟,即可直接理解口語、書面句子、圖像像素和視訊影格之間的關係。
欲了解這些工程原理與原生分詞如何在現實場景中大規模部署,請觀看 MIT 媒體實驗室 (MIT Media Lab) 的研究願景簡報。該簡報概述了產業長期趨勢,即將 AI 模型與豐富的物理與多感官世界訊號直接連接:
核心模態支柱:跨媒體處理映射
要真正掌握 Gemini Omni 的強大之處,必須超越簡單的資料攝取。該模型利用統一架構,讓文字、圖像、音訊和視訊存在於一個共享的潛在空間映射 (Latent space mapping) 中。當其中一種模態發生輸入變化時,它不僅僅觸發孤立的反應,還會同時動態調整其他三種格式的數學參數。
多模態相互依賴矩陣
這種即時的跨媒體推理依賴相互依賴的資料流。模型不是以連續區塊來處理資料,而是持續同步所有四大支柱,以達成無縫的多模態對齊。
下方的處理映射表概述了這些即時輸入如何在通用神經網路中相互影響:
| 主要媒體輸入 | 共同處理模態 | 系統操作 | 深層技術意圖 |
| 聲學波形 | 文字 + 視訊影格 | 追蹤語音節奏以索引時間視訊序列 | 即時感官對齊 |
| 靜態圖像 | 原始音訊 + 文字 | 將視覺色彩頻譜轉換為匹配的語境音訊 | 跨模態合成 |
| 字母數位代碼 | 視訊陣列 + 文字 | 透過程式邏輯直接修改結構化視訊變數 | 生成式程式碼執行 |
| 時間視訊序列 | 音訊軌 + 代碼 | 在多層資料軌道上計算時空更新 | 統一視訊音訊解析 |
即時參數同步的運作
當 Gemini Omni 處理即時視訊串流時,它不會將影像與背景音軌分離。如果音訊輸入偵測到頻率突然飆升(例如有人在大喊),模型會立即更新其視覺 Token 的預期,並在物理動作發生前,預測到視訊影格的快速變動或轉移。
這種深度的交叉影響防止了上下文漂移。由於整個網路同時平衡這些變數,無論模型是在生成同步的視訊摘要,還是即時翻譯多感官串流,輸出結果都能保持完美的連貫性。
消除延遲與上下文漂移:統一權重的優勢
要體會 Gemini Omni 的速度,不妨看看傳統「縫合式」AI 管線的數學低效之處。過去,要構建語音或視訊助手,需要將獨立的單一用途軟體層串接起來。
plaintext1[使用者語音輸入] 2 │ 3 ▼ 4 1. ASR 引擎(音訊轉文字轉錄) 5 │ 6 ▼ 7 2. 核心 LLM 層(文字生成處理) 8 │ 9 ▼ 10 3. TTS 引擎(文字轉音訊合成) 11 │ 12 ▼ 13[生成的語音輸出]
這種多步驟的協調迫使資料在連續的軟體橋接中傳輸,從而增加了執行延遲。獨立的文字轉語音引擎無法「聽見」原始的錄音。這導致不同媒體類型之間的資料大量流失。當一切被扁平化為純文字時,重要的語音線索(例如使用者的諷刺語氣、猶豫或情緒困擾)就會完全消失。
實現真正的管線延遲降低
Gemini Omni 透過在統一神經權重上運行,繞過了這些邊界。由於單一神經網路能在同一個數學基礎下原生評估文字、音訊和像素,因此大幅提升了執行速度。這種佈局帶來了顯著的管線延遲降低。
根據 Google DeepMind 的基準測試報告,執行即時音訊串流的原生多模態架構,將端到端回應時間縮短至 150 毫秒以內。這種轉變有效地匹配了人類即時對話的自然節奏。
上下文保留優化
除了純粹的速度,統一執行確保了高度的上下文保留優化。當您與模型對話時,權重會同時處理您的音訊頻率與定義的文字內容。
- 語調處理: 網路直接擷取語音調變,並以適當的同理心或緊迫感回應。
- 視覺同步: 視訊影格中細微的臉部微表情或空間動作,無需解析錯誤即可直接轉譯為對話輸出。
透過移除中間的轉換步驟,Gemini Omni 防止了小細節的遺失。這為人類與機器之間在不同感官上的流暢、自然互動奠定了堅實基礎。
使用 Omni-Channel AI 系統構建企業工作流程
這種轉向原生多模態的趨勢改變了公司構建和擴展數位工具的方式。透過使用單一的多合一 AI 配置,企業可以用統一的工作流程取代混亂、分離的軟體組件,從而輕鬆大規模運行互動式混合媒體系統。
單一 API 架構
開發人員不再需要協調用於語音辨識、文字分析和影像處理的離散雲端功能。相反地,單一的統一 API 整合將應用程式層直接連接到核心網路(如 Atlas Cloud AI 模型 API)。這種精簡路徑允許團隊透過單一請求框架建構先進的跨媒體管線。
plaintext1 ┌─────────────────────────────────┐ 2 │ 統一 Gemini API │ 3 └────────────────┬────────────────┘ 4 │ 5 ┌─────────────────────────┼─────────────────────────┐ 6 ▼ ▼ ▼ 7┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ 8│ 即時程式碼 │ │ 混合媒體資料 │ │ 多感官控制台 │ 9│ & 資產同步 │ │ 自動化層 │ │ Dashboards │ 10└──────────────────┘ └──────────────────┘ └──────────────────┘
例如,企業培訓平台可以同時處理即時視訊串流、追蹤說話者的音訊節奏、翻譯對話,並動態更新視覺資料儀表板——所有這些都由一個後端系統驅動。
策略部署優勢
切換到多合一模型架構有哪些部署優勢?
從舊有的多模型配置切換到單一神經網路,可為公司 IT 系統帶來直接且穩定的效益:
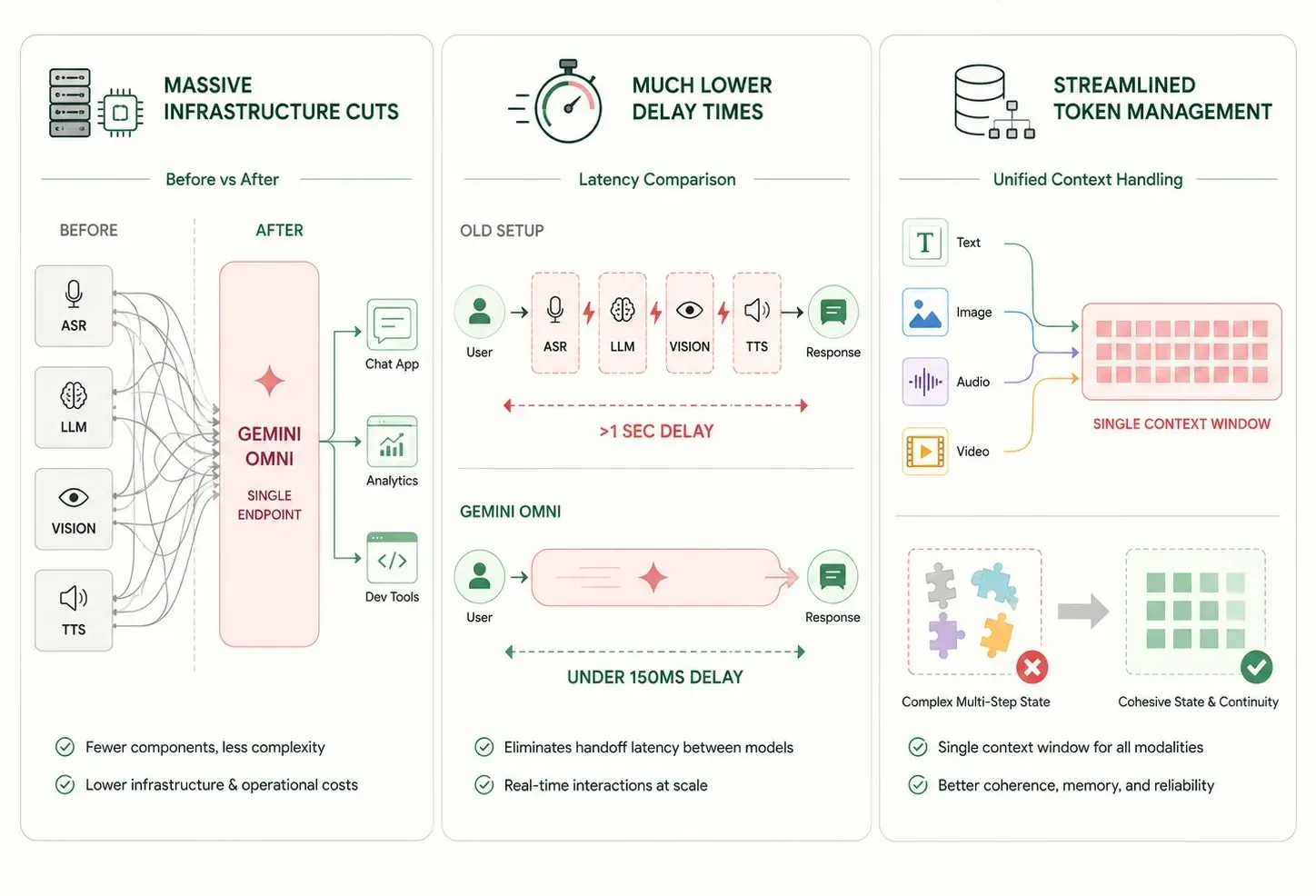
- 大規模基礎設施精簡: 將文字、視覺和聲音任務整合至一個模型,減少了獨立軟體端點的數量,使長期維護變得簡單許多。
- 大幅降低延遲時間: 跳過小型專業工具之間的額外網路步驟,將回應時間縮短至一秒以內,實現真正的即時使用者體驗。
- 精簡的 Token 管理: 單一上下文視窗均勻追蹤所有模態,減少了多步驟過程中複雜的狀態管理問題。
實現可擴展的多模態部署
透過像 Gemini Enterprise Agent Platform 這樣的框架,企業可以無縫協調自主子代理網路。這個單一系統簡化了大規模多媒體專案的執行,利用託管配置來追蹤持續數天的流程中的背景上下文和使用者身份。透過將不同的輸入保持在同一個安全空間內,企業可以從頭到尾自動化處理跨媒體任務,而不會遺失資料或失去對主旨的追蹤。
全球 AI 推理的運算限制與硬體優化
雖然在統一網路架構下處理四個獨立的資料流開啟了無縫跨媒體工作流程,但也對現代硬體基礎設施提出了前所未有的需求。在這個環境中導航需要嚴謹的運算資源管理,以克服全球範圍內同時進行多感官處理所帶來的極端物理代價。
多模態分詞的開銷
最主要的工程挑戰源於多模態 Token 開銷。與標準字母數字文字資料集不同,高畫質圖像、原始音訊頻率和連續視訊檔案會產生大量的數值資料。
- 文字處理: 單頁文字約轉換為 1,000 個密集的有意義 Token。
- 視覺處理: 一分鐘的原始視訊素材,在切分為穩定的影格步驟和像素區塊後,會拆解成數十萬個視覺 Token。
當單一模型核心同時處理這些媒體類型時,會導致上下文視窗密度呈指數級激增。系統的注意力 (Attention) 機制必須評估每個 Token 與其他所有 Token 的關聯,這將威脅到晶片上的高頻寬記憶體 (HBM) 並導致處理層飽和。
透過 TPU 叢集擴展加速工作負載
為了解決此瓶頸,企業基礎設施依賴專為多感官運算而設計的專業硬體平台。Google 的最新架構利用 TPU 叢集擴展 (TPU cluster scaling),將這些密集的統一 Token 工作負載分配到多層資料中心環境中。
plaintext1 ┌─────────────────────────┐ 2 │ 統一 Gemini Token │ 3 └────────────┬────────────┘ 4 │ 5 ┌───────────────────────┴───────────────────────┐ 6 ▼ ▼ 7┌─────────────────────────────────┐ ┌─────────────────────────────────┐ 8│ TensorCore 陣列 │ │ TensorCore 陣列 │ 9│ (平行矩陣算術運算) │ │ (平行矩陣算術運算) │ 10└────────────────┬────────────────┘ └────────────────┬────────────────┘ 11 │ │ 12 └───────────────┬───────────────────────┘ 13 ▼ 14 ┌─────────────────────────┐ 15 │ 光學互連 │ 16 │ (超低延遲 ICI) │ 17 └─────────────────────────┘
像 Trillium TPU v6e 平台這類的硬體配置,與舊一代硬體相比,單晶片峰值運算效能提升了 4.7 倍。這種專業架構透過結合優化的矩陣執行單元與深層物理基礎設施佈局,處理了這些巨大的需求:
| 硬體引擎層 | 架構規格 | 核心系統功能 |
| 擴展 TensorCore 陣列 | 矩陣乘法單元 (MXU) 面積加倍 | 對密集視訊張量執行密集的平行算術運算。 |
| 高頻寬 HBM | 每晶片高達 32 GB HBM | 將海量 Token 陣列完全置於矽片上以防止記憶體瓶頸。 |
| 新一代晶片互連 | 800 GBps 雙向頻寬 | 在數萬個晶片間同步參數變數,無延遲。 |
透過結合客製化光學網路結構與這些深層記憶體配置,雲端基礎設施可以動態擴展以處理數百萬個 Token 的輸入參數。這使企業能夠在全球範圍內部署先進的即時 AI 代理,而無需冒記憶體停滯或系統運行時失敗的風險。
用於生成式影片生產的統一 API
雖然 Google 在 Gemini 應用程式和 Google Flow 中向終端使用者推出了 Gemini Omni Flash,但開發人員和產品團隊若想將相同的多模態視訊引擎嵌入到自己的工作流程中,則需要一個穩定、可預測的 API 層。
Atlas Cloud 透過與 OpenAI 相容的統一 API 提供 Gemini Omni Flash,同時支援 300 多種圖像、視訊和 LLM 模型——因此您可以整合 Google 的原生多模態模型,而無需同時管理多個供應商帳戶、帳單入口網站或 SDK。
兩種 Gemini Omni Flash 變體現已在 Atlas Cloud 上線:
| 變體 | 最佳適用於 | 輸入 | 解析度 | 時長 | 起步價 |
| Gemini Omni Flash 文字轉影片 (開發者) | 純提示詞驅動的電影級生成 | 文字 (最高 20,000 字元) | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | USD0.2 + USD0.1/秒 |
| Gemini Omni Flash 圖像轉影片 (開發者) | 基於真實參考的主體一致性影片 | 文字 + 最多 7 張參考圖 | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | USD0.2 + USD0.1/秒 |
快速入門 — 用 5 行程式碼生成 Gemini Omni Flash 影片:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "黃金時刻的霧氣森林,電影級推軌鏡頭", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
API 會立即回傳一個預測 ID — 輪詢 /api/v1/model/prediction/{id} 即可取得渲染後的 MP4 URL。完整的結構描述、7 種語言的程式碼範例,以及免程式碼 Playground 皆可在上述連結的模型頁面上取得。
結論:為統一機器智慧進行未來佈局
Gemini Omni 的到來從根本上改變了開發人員的設計範式,推動產業從拼湊分離的工具轉向部署統一的單層解決方案。工程師無需再管理孤立 API 之間複雜的整合橋接,現在可以依賴下一代機器學習框架,在同一個數學架構下自然處理相互依賴的資料流。
plaintext1[傳統軟體管線] 2分離的文字 API ──┐ 3分離的音訊 API ─┼──► 手動管線磚塊 ──► 脆弱的生產環境 4分離的視訊 API ──┘ 5 6[統一 Omni 架構] 7通用 Token ──► 原生單層模型 ──► 無縫自動化
這種結構上的轉變需要對我們構建數位產品的方式進行全面徹底的改革。為了保持競爭力,技術團隊必須遠離靜態的資料孤島,並準備好標準軟體生態系以迎接原生多感官系統。
企業可以直接在像 Google Cloud AI 基礎設施這樣高度優化的雲端骨幹上運作,擴展這些密集的 Token 工作負載,而無需承擔系統性上下文漂移或延遲懲罰的風險。最終,讓您的開發管線經得起未來考驗,意味著圍繞一個旨在全面理解物理世界的單一、具凝聚力的引擎來設計解決方案。






