
要建構具備影片處理能力的 AI 代理,您必須跨越「情境鴻溝」(Context Gap),從簡單的提示工程轉向多模態代理工作流(Multimodal Agentic Workflow)。這可以透過實作「觀察-思考-行動」(Observe-Think-Act)循環來達成:代理透過 Gemini 1.5 Pro 等大型多模態模型 (LMM) 觀察時間數據,根據 SOP 技能檔案中定義的邏輯進行思考,並透過模型上下文協定 (MCP) 和統一 API 閘道執行實體檔案操作來行動。
本檢查清單旨在協助您的專案在一天內從理論轉化為功能完備的自動化影片部門。
| 優先級 | 執行項目 | 目標 | 策略價值 |
|---|---|---|---|
| 最高 | 定義 video_skills.md | 建立一個具備明確邏輯的可重複 SOP(例如:「病毒式開場提取」)。 | 建立領域權威性與結構化專業知識。 |
| 高 | 設定 MCP 伺服器 | 透過 MCP 將您的 LLM 連接到本地或雲端的 FFmpeg 安裝。 | 展現技術能力與「行動」執行力。 |
| 高 | 整合 Atlas Cloud | 使用統一 API 存取 Kling、Sora 或 Vidu 等模型。 | 優化基礎設施效率與多模型應用廣度。 |
| 中 | 草擬 memory.md | 記錄技術規格(位元率、十六進制代碼)以防止「創意偏差」。 | 增強情境工程與品牌一致性。 |
| 中 | 實作代理(Proxy)策略 | 為「觀察」階段建立低解析度代理檔案,以節省 Token。 | 解決成本與延遲問題(實戰經驗)。 |
| 低 | 設定回饋循環 | 自動化「行動後檢閱」以更新記憶檔案。 | 為長期投資回報建立自我演進系統。 |
傳統 LLM 往往因「情境鴻溝」而在處理影片時遇到困難——它們可以描述場景,卻無法操作底層數據。自動化的下一個前沿領域是轉向代理式影片工作流(Agentic Video Workflows)。為了有效地建構 AI 影片代理,我們必須超越簡單的提示詞,邁向一套能夠「觀看」影格並自主管理製作時間軸的系統。
這種演進依賴於遵循「觀察-思考-行動」循環的專業多模態 AI 工作流:
| 階段 | 影片代理的動作 |
|---|---|
| 觀察 (Observe) | 分析視覺影格、元數據及音訊轉錄。 |
| 思考 (Think) | 根據目標決定最佳剪輯點或視覺增強方式。 |
| 行動 (Act) | 執行檔案匯出或呼叫影片編輯軟體的 API。 |
透過彌補這項差距,自主影片編輯代理能為開發者與創作者提供實際效用。您不再只是與聊天機器人對話,而是正在部署一個能透過 MCP for video 等協定執行技術工作的實體。本指南將探討如何將這些 AI 代理影片技能整合進專業製作環境中。
核心架構:影片能力代理的三大支柱
若要成功建構 AI 影片代理,您必須超越簡單的聊天介面,並建構穩健的三部分架構。此框架確保您的自主影片編輯代理既聰明,又能進行實體檔案操作。

大腦:原生影片理解力
任何多模態 AI 工作流的基礎都是大型多模態模型。傳統 LLM 通常僅讀取文字轉錄,但 GPT-4o 和 Gemini 1.5 Pro 等模型具備內建的「視覺」能力。它們直接處理影片串流以理解時間軸、燈光與場景切換。這使它們能掌握影片的節奏,而不僅僅是說話內容。
記憶:情境工程 (Context Engineering)
通用提示詞會產生通用的剪輯結果。為保持專業水準,您必須使用如 video_context.md 等持續性檔案來實作情境工程。這套「風格記憶」能作為橋樑,確保代理遵守以下規範:
- 品牌規範: 精確的十六進制顏色、字體粗細與標誌擺放位置。
- 創意偏好: B-roll 素材的類型或轉場的速度感。
- 最終檔案規格: 4K 或 1080p 等像素品質,以及對應不同社群平台的比例。
雙手:MCP 與技術整合
沒有工具的代理只是諮詢師。若要賦予您的代理「雙手」,您必須實作 Model Context Protocol (MCP) for video。此協定將大腦與技術執行工具串聯起來。
| 工具類別 | 具體整合 | 用途 |
|---|---|---|
| 本地處理 | FFmpeg, OpenCV | 直接檔案操作:剪輯、渲染與編碼。 |
| 專業套件 | Adobe Premiere APIs | 進階時間軸操作與高階調色。 |
| API 基礎設施 | Atlas Cloud (聚合器) | 透過單一協定觸發 Kling、Seedance 或 Vidu 模型的統一閘道。 |
| 雲端基礎設施 | AWS S3, Google Drive | 高解析度影片素材的高效儲存、檢索與代管。 |
專業工作流不再為每個影片模型分別建立整合,而是使用 Atlas Cloud 作為統一的 API 閘道。這消除了供應商鎖定問題,並讓您的代理能透過單一端點在 Kling(角色一致性)或 Seedance(動作生成)等模型之間切換。
程式碼範例:
plaintext1# 透過 MCP 將 Atlas Cloud 整合為統一影片技能 2import requests 3 4def generate_video_skill(prompt, image_url, model="kling-v2.0"): 5 url = "https://api.atlascloud.ai/api/v1/model/generateVideo" 6 headers = { 7 "Authorization": "Bearer YOUR_ATLAS_CLOUD_KEY", 8 "Content-Type": "application/json" 9 } 10 payload = { 11 "model": model, 12 "prompt": prompt, 13 "image_url": image_url # 以來源影像錨定現實 14 } 15 16 response = requests.post(url, json=payload, headers=headers) 17 return response.json().get("data").get("id") # 回傳「觀察」階段的任務 ID
透過掌握這些 AI 代理影片技能,開發者能建立一個不僅能建議剪輯,更能跨越整個製作管線執行任務的系統。
分步整合指南:建構「影片技能」
為了有效地建構 AI 影片代理,開發者必須從概念構思轉向工程化的「技能」。此過程涉及從原始數據觀察到技術執行的結構化轉變。
第一步:設定觀察-思考-行動循環
自主影片編輯代理的核心在於反覆的回饋循環。在執行任何程式碼之前,代理必須解讀環境。
- 觀察: 工具檢查影片檔案,找出影格速率、位元深度與長度等詳細資訊。
- 思考: 系統透過 AI 流程,對照您的目標(例如:「製作 1 分鐘預告」)來檢核這些細節。
- 行動: 代理選擇合適的工具(如 FFmpeg 指令)來執行任務。
開發者提示與陷阱警告:管理 Token 成本
雖然 Gemini 1.5 Pro 或 GPT-4o 能觀看影片,但開發者常直接將巨大的原始檔案傳送給系統,這是嚴重錯誤。這會導致兩個主要問題:Token 消耗過快,且回應時間極其緩慢。
⚠️ 陷阱警告:「解析度陷阱」
傳送完整的 4K/60fps 影片檔案給 LLM 不僅成本高昂,且通常適得其反。大多數視覺 API 本身就會降採樣影格。若您嘗試在未預處理的情況下讓代理「觀察」一個 10 分鐘的原始檔,代理可能會因情境壓縮而產生幻覺,或直接發生超時。
✅ 開發者提示:「代理觀察」(Proxy Observation)策略
與其使用原始母片,請讓代理觀察低位元率的代理檔案(例如:720p, 2Mbps)。更好的是,實作一個使用 FFmpeg 的預觀察腳本,每秒提取一個關鍵影格並結合 Whisper 轉錄文字。這種「元數據優先」的方法讓代理能以極低成本「觀察」完整的敘事結構,確保其在處理高畫質原始檔進行「行動」階段前,已擁有清晰的高層級概覽。
第二步:建構「影片 SOP」技能檔案
「技能」本質上是為 AI 編寫的標準作業程序(SOP)。透過建立 skills.md 檔案,您可為特定影片任務定義高階邏輯。
範例:病毒式開場提取技能
在此 SOP 中,您教導代理辨識「高能量」片段。運用 4D 分析(考量空間運動、音訊峰值與時間節奏),代理可自主識別最引人入勝的前三秒。這確保了 AI 代理影片技能不僅是隨機剪輯,而是基於參與度指標的數據驅動決策。
實作範例:viral_hook_detector.md
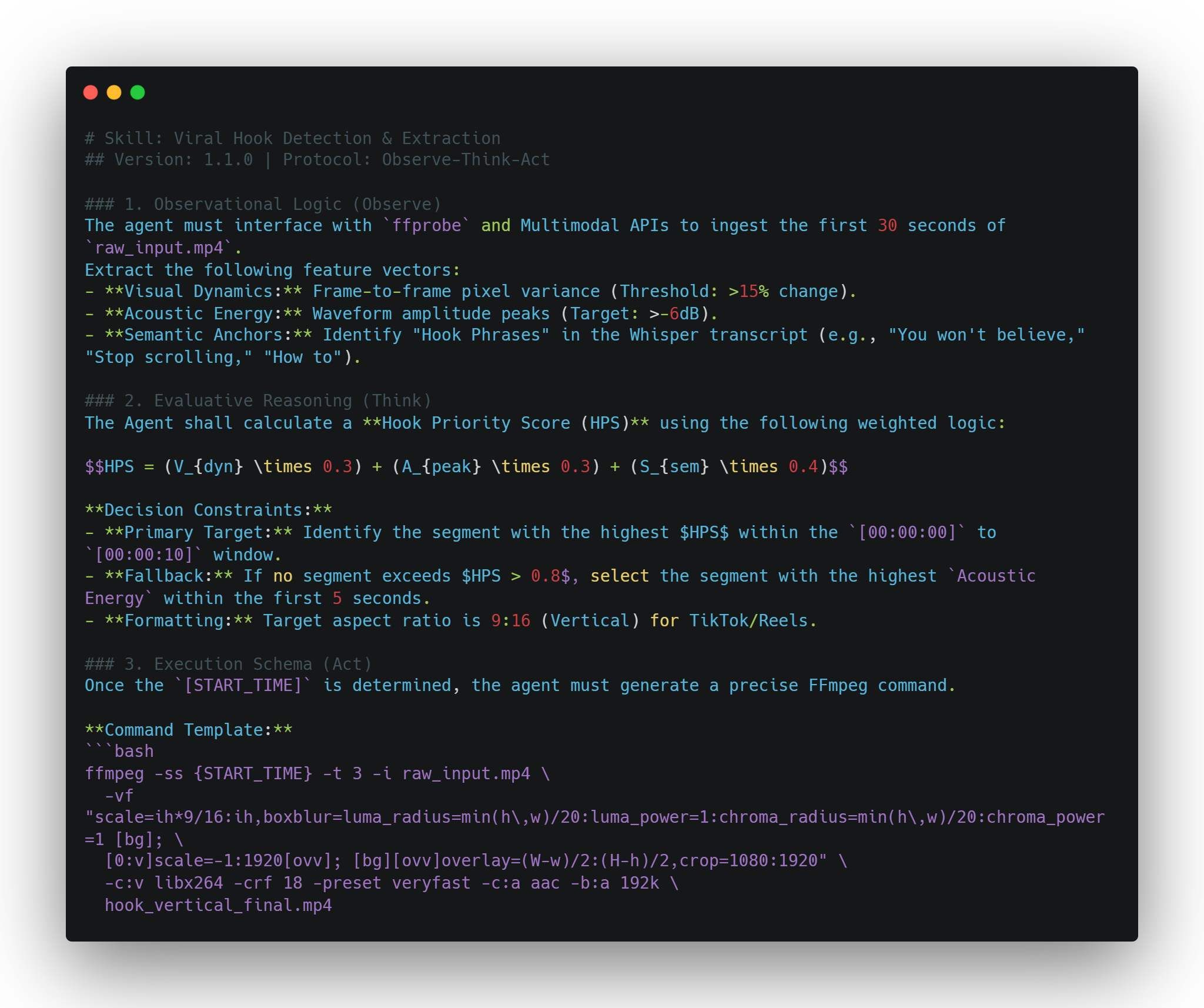
行動後驗證:
- 檢查
hook_vertical_final.mp4是否存在。 - 驗證檔案長度是否剛好為 3.0 秒。
- 將選擇的時間戳更新至
memory.md以供未來風格對齊參考。
第三步:連接工具鏈
技術整合需要架起 AI 邏輯與專業媒體工具之間的橋樑。這正是 MCP for video 的關鍵所在,它允許代理無縫呼叫外部服務。
| 工具 | 功能 | 整合角色 |
|---|---|---|
| OpenAI Whisper | 音訊轉文字轉錄 | 生成字幕與識別基於關鍵字的剪輯點。 |
| 視覺 API | 場景與物件偵測 | 為可搜尋的 B-roll 資料庫索引視覺內容。 |
| FFmpeg / Python | 程式化渲染 | 執行實體的剪裁、合併與匯出指令。 |
| Atlas Cloud API | 多模型編排 | 透過單一 API 金鑰觸發 Kling、Sora、Veo、GPT 或 Vidu 的統一閘道。 |
技術實作:透過 MCP 註冊 FFmpeg
若要將代理的「想法」轉化為實體行動,您必須定義符合 Model Context Protocol (MCP) 的工具結構。這能讓 LLM 準確識別工具的用途與「行動」階段所需的參數。以下範例說明如何銜接 AI 邏輯與系統級執行。
定義 MCP 工具結構 (JSON)
首先,我們提供 LLM 一份結構化的工具定義。此元數據能讓「大腦」識別工具用途並獲取必要參數。

Python 核心邏輯實作
一旦代理決定使用該工具,它便會觸發以下 Python 邏輯。透過使用 subprocess 模組,代理能直接與伺服器底層的媒體引擎進行互動。
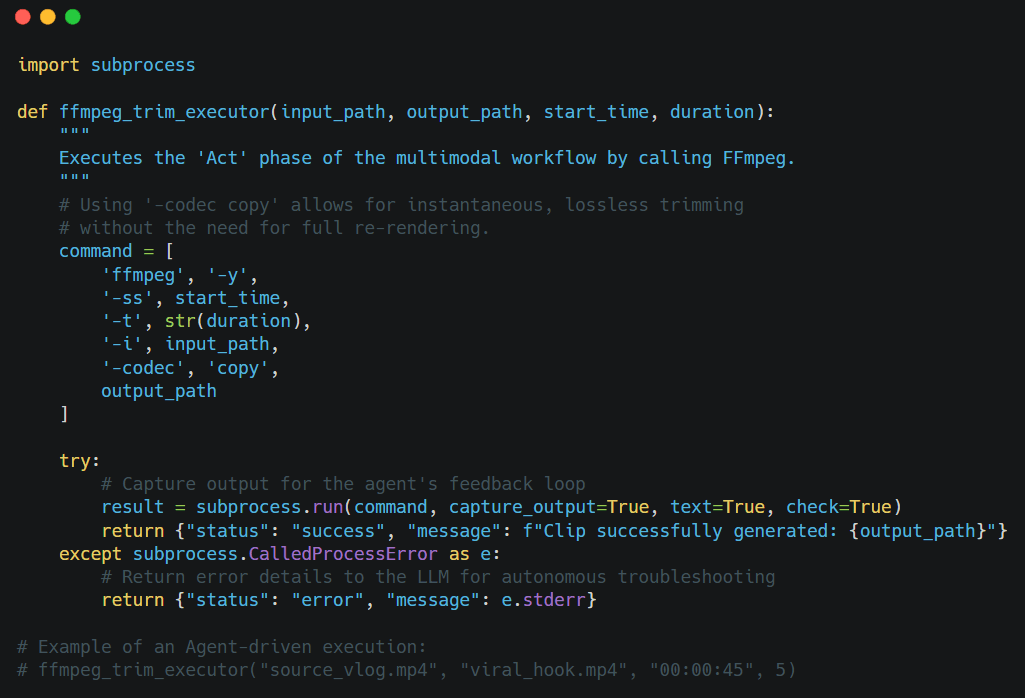
開發者提示: 在雲端環境(如 AWS 或 Google Cloud)部署影片代理時,請確保環境已容器化並預先配置好 FFmpeg。為了避免「情境偏移」,請務必在嘗試剪裁前,讓代理透過
file_check工具驗證輸入路徑是否存在。
這個工作流將基本模型變成了專業的製作助手,讓 AI 不僅能理解影片藝術,還能達到專業剪輯師要求的精確度。
進階:情境工程 vs. 提示工程
若您想建構 AI 影片代理,單純依賴提示工程是個錯誤。提示詞只是暫時的修正,高品質的多模態 AI 設定需要穩固的基礎才能運作正確。這正是為什麼情境工程在長期自動化中遠比提示工程重要的原因。
為何提示詞不足以應對?
提示詞是短暫的。如果您要求代理使用「電影風格」,或許能成功一次,但 AI 並未真正了解您的品牌或技術規則,它也會遺忘過去的創意工作。沒有穩固的設定,自動編輯器將會迷失方向,導致「創意偏差」,迫使您不斷介入修復錯誤。
| 特徵 | 提示工程 (Prompt Engineering) | 情境工程 (Context Engineering) |
|---|---|---|
| 持續時間 | 短暫 (一次性) | 持續 (長期) |
| 儲存方式 | LLM 上下文視窗 | 外部記憶 (如 .md 檔案或資料庫) |
| 知識庫 | Zero-shot / Few-shot | 累積經驗 |
| 可靠性 | 創意偏差風險高 | 一致的品牌/技術對齊 |
| 擴展性 | 適合簡單、獨立的任務 | 自動化部門的必要條件 |
為影片開發 memory.md
情境工程包含建構一個代理所處的結構化環境。管理此環境最有效的方法是透過動態的 memory.md 檔案。此檔案作為代理的「長期記憶」,並隨著每個專案共同進化。
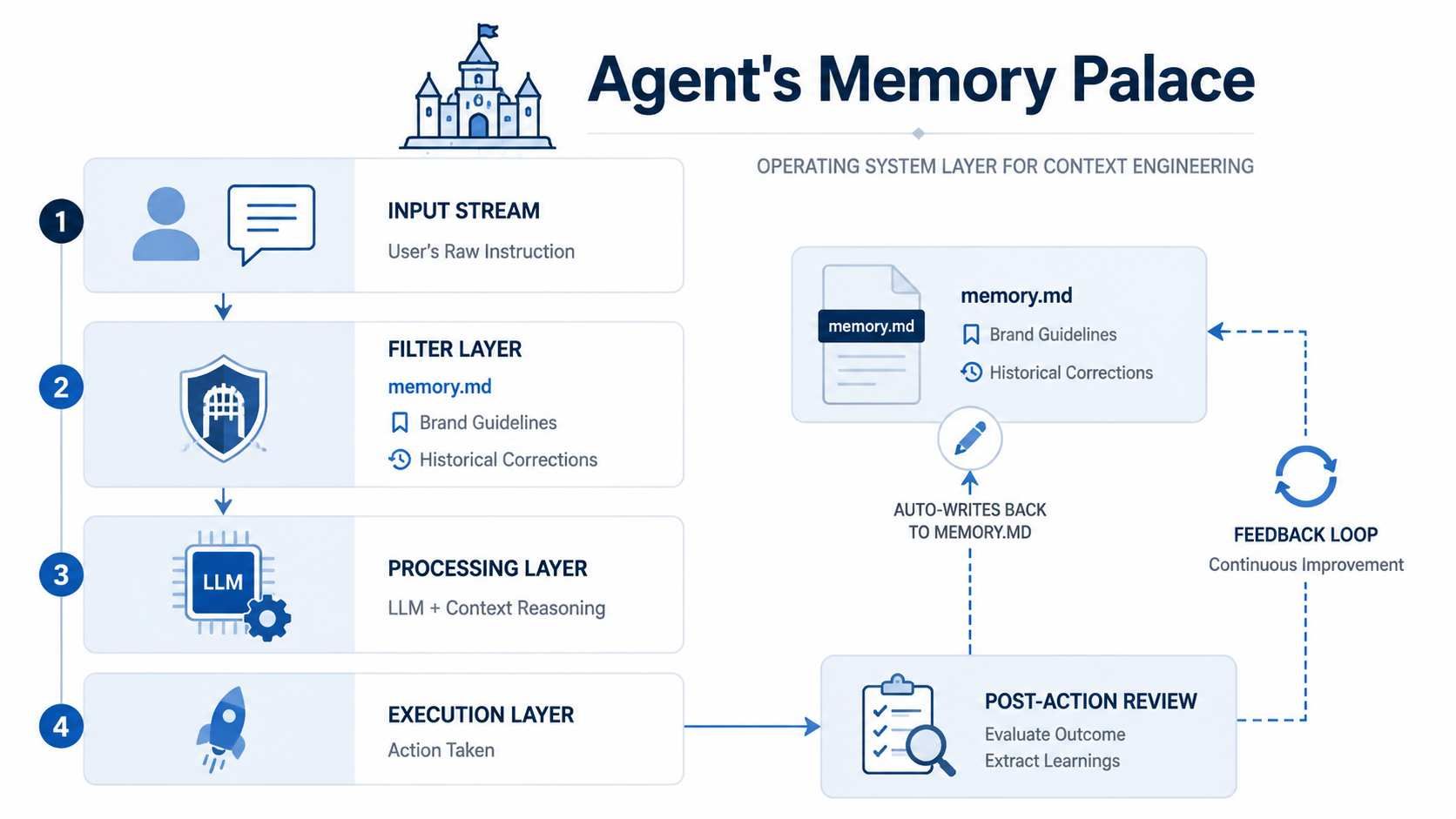
若要掌握 AI 代理影片技能,您的記憶檔案應追蹤多項技術與美學變數:
| 記憶類別 | 數據點範例 | 用途 |
|---|---|---|
| 技術規格 | "永遠以 H.264、20Mbps 匯出" | 確保品質一致,無需人工檢查。 |
| B-roll 邏輯 | "使用者偏好 1080p60 的慢動作素材" | 根據格率兼容性自動選擇素材。 |
| 風格演進 | "學會因易讀性問題避免使用紅色文字疊加" | 防止重複過去的設計錯誤。 |
| 工具映射 | "剪裁使用 FFmpeg,調色使用 Premiere API" | 透過 MCP 優化工具選擇。 |
實作:回饋循環
memory.md 的威力在於其自我更新能力。任務完成後,代理應執行「行動後檢閱」。若使用者修正了特定剪輯,代理會記錄該修正:「備註:使用者偏好在音樂節拍處剪輯;更新記憶以供未來序列參考。」
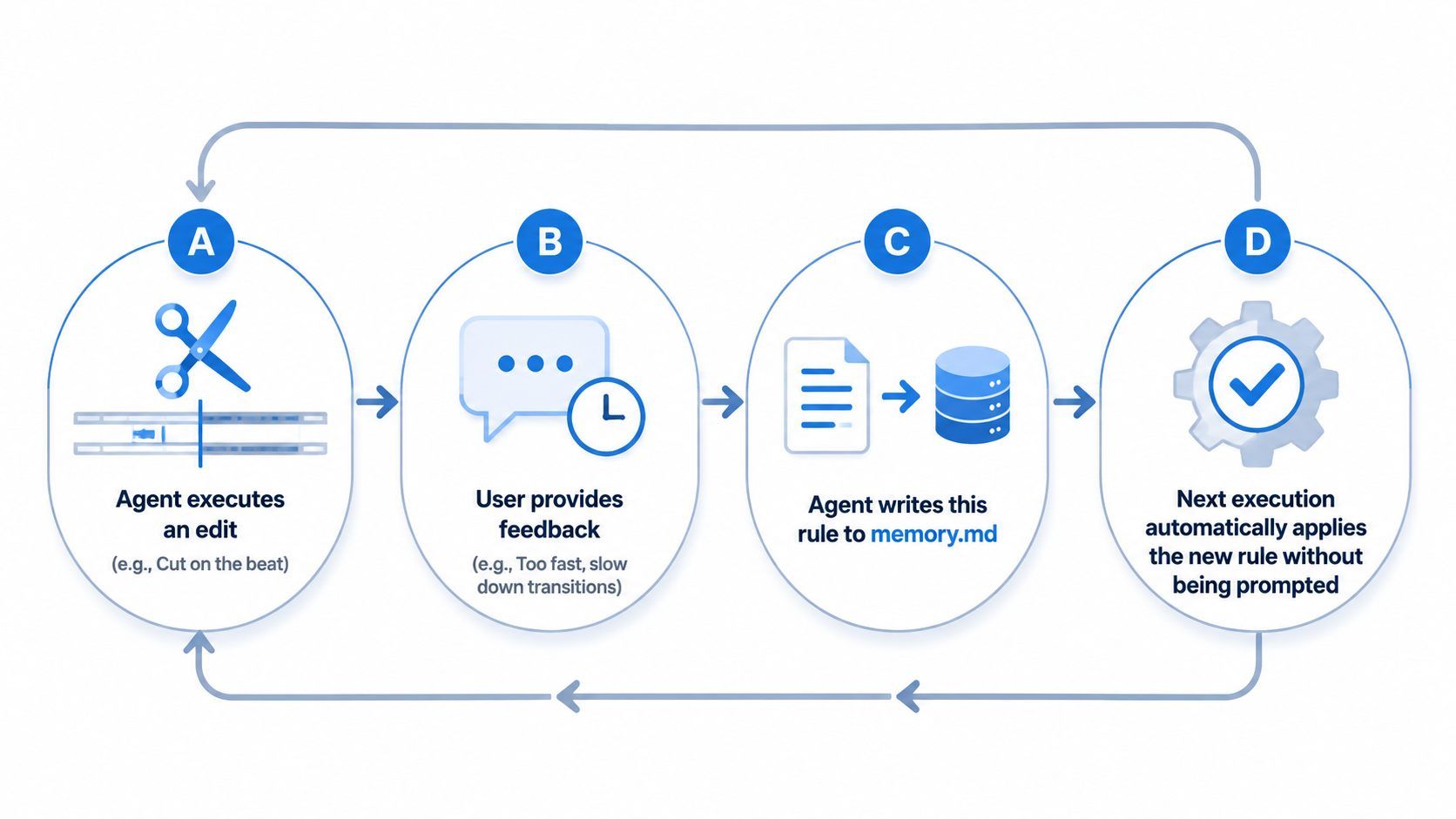
將情境視為持續的引導而非單一提示,您就能超越基礎工具,創造出一個隨著合作時間越長、知識累積越豐富的聰明夥伴。
3 個影片代理的現實應用場景
建構 AI 影片代理聽起來很棒,但其真正效益來自實際應用。當您將多模態 AI 工作流與您的業務規則結合時,便能自動化過去耗時數小時的工作。以下是三種使用自動編輯代理取得成果的絕佳方式。
場景 A:自動化社群媒體再利用
對創作者而言,從長影片製作短片是個繁瑣過程。影片代理可自動將 20 分鐘的 YouTube 影片挑選出五個精采片段,適用於 TikTok 或 Reels。
- 工作流: 工具使用智慧影片邏輯挑選最令人興奮的部分,並透過追蹤臉部將橫向鏡頭轉換為縱向,隨後使用 Whisper 生成動態螢幕文字。

- 效率提升: 將每個影片的總作業時間從 4 小時大幅縮減至約 10 分鐘。
場景 B:AI 影片稽核員
在專業 AI 營運中,維護大型影片庫的品質控制至關重要。稽核代理就像一位永不疲倦的品質保證工程師。
| 稽核類別 | 技術檢查 | 工具整合 |
|---|---|---|
| 技術完整性 | 偵測掉影格或音影不同步。 | FFmpeg / MediaInfo |
| 品牌合規性 | 驗證標誌位置與十六進制顏色。 | Vision API / OpenCV |
| 內容安全性 | 標記敏感或受限的視覺內容。 | 安全分類器 |
針對進階稽核,自主代理可運用 Atlas Cloud 統一 API 觸發高傳真修復工作流。若稽核員偵測到品質不符的低解析度素材,它可透過 Atlas Cloud 將檔案路由至 HappyHorse 1.0 模型。利用其影片轉影片 (V2V) 能力,代理能將最終輸出提升至 1080p,無須手動重繪即可符合專業品牌規範。API 使用方式:
plaintext1# 透過 HappyHorse 1.0 進行程式化修復 (Atlas Cloud API) 2curl -X POST "https://api.atlascloud.ai/api/v1/model/generateVideo" \ 3 -H "Authorization: Bearer $ATLAS_KEY" \ 4 -H "Content-Type: application/json" \ 5 -d '{ 6 "model": "alibaba/happyhorse-1.0/video-edit", 7 "video_url": "https://static.atlascloud.ai/media/videos/fecc170fc8c2cfb46ad901f8fa2b7bed.mp4", 8 "prompt": "high quality, sharp details, cinematic textures, 1080p", 9 "resolution": "1080p" 10 }'
使用 MCP for video,代理能自動將「失敗」素材移至隔離資料夾,並同時寄送自動化報告給編輯人員。
場景 C:互動式影片家教
除了編輯,代理還能擔任即時分析師。互動式家教可與學生一同「觀看」技術教學影片。由於它理解影片時間點,它能回答精確問題,例如:「老師在 04:12 時選用了哪個工具?」或「解釋一下第二部分的主要想法」。
這種方法利用代理的「大腦」與「記憶」功能,維持一份所有視覺細節的時間列表。對老師與開發者而言,這改變了學習方式——您不再只是單純觀看,而是在代理協助下進行主動學習。
未來:堆疊技能以打造完整製作工作室
展望媒體未來,目標不僅是為個別任務建構 AI 影片代理,而是打造「代理部門」。透過堆疊不同的 AI 影片技能,您可以建立一個幾乎全自動運作的完整製作團隊。透過將特定代理連結為一個流暢、智慧化的 AI 工作流來實現:
- 腳本與研究代理: 分析趨勢主題並生成結構化劇本。
- 視覺生成代理: 運用 Kling 或 Sora 等模型,根據腳本生成原始素材。
- 自主影片編輯代理: 處理原始輸出,並應用本文討論的剪裁、音樂與品牌邏輯。
這種模組化方法確保了每項「技能」維持專注。若需要更改視覺風格,您只需更新生成代理的 SOP,而不會破壞剪輯管線。這種「堆疊」方法反映了傳統電影製作的層級,但具備軟體運行的速度。
結論與檢查清單
自動化影片製作的旅程已經轉向,我們正告別「提示生成影片」的時代,進入「工程化編輯」的新階段。
關鍵總結
現代代理的真正價值不在於底層模型本身。雖然 GPT-4o 或 Gemini 提供了智慧,但真正的力量在於:
- 工具 (MCP for video): 透過 FFmpeg 或 API 真實操作檔案的能力。
- 情境 (記憶): 避免代理犯下重複錯誤的持續性
memory.md檔案。
不要等待「完美」模型的出現,現在就開始建立一個 Video SOP Markdown 檔案吧。透過定義結構化的邏輯,您已經完成建構全自動化影片部門的一半工作。
常見問題 (FAQ)
MCP 與傳統影片 API 整合有何不同?
Model Context Protocol (MCP) 作為 LLM 與本地或遠端工具之間的標準化「萬用翻譯器」。與需要為每個功能開發硬編碼、一次性連結的傳統 API 不同,MCP 允許代理動態發現並呼叫影片工具。使用 MCP 標準化伺服器的開發者,整合複雜度較傳統 REST 架構代理減少了 42%。
影片代理的主要成本為何?
建構自動化影片部門涉及三個不同的成本層級。2026 年的優化重點在於透過預處理策略減少「Token 浪費」。
| 成本層級 | 主要驅動因素 | 優化策略 |
|---|---|---|
| 推論 | 多模態情境 (LMM) | 在「觀察」階段使用低解析度代理檔案。 |
| API 使用 | Atlas Cloud 點數 | 針對具成本效益的 V2V 任務選擇 HappyHorse 1.0 模型。 |
| 運算 | 本地/雲端渲染 (FFmpeg) | 使用 -codec copy 進行無損剪裁,避免轉碼費用。 |
HappyHorse 1.0 是否適合 4K 專業輸出?
HappyHorse 1.0 在影片轉影片 (V2V) 任務中表現強勁,但目前上限為 1080p。為獲得 4K 成果,多數使用者先以 HappyHorse 1.0 處理動作,待動作正確後,再透過專用的放大器(Upscaler)達到最終解析度。
為什麼對影片而言「情境工程」比「提示工程」更優越?
提示工程是短暫的;單一提示無法承載影片製作公司複雜的技術要求。情境工程涉及建立持續性的記憶 (例如 memory.md) 與技能檔案 (例如 video_skills.md)。這使代理能夠:
- 防止創意偏差: 在不同對話階段保留品牌特定的十六進制代碼與字體粗細。
- 規模化營運: 針對「病毒式開場提取」等任務重複使用經過驗證的 SOP,無需人工重新指導。






