DeepSeek-V4 预览版发布:支持 100 万 token 上下文、Agent 能力升级及权重开源
今日(4 月 24 日),DeepSeek 正式发布并开源了全新模型系列 DeepSeek-V4 的预览版本。
DeepSeek-V4 支持高达 100 万 token 的上下文窗口,在智能体(Agent)能力、世界知识和推理能力方面,均处于国产及开源模型中的领先水平。该系列包含两个尺寸版本:
- DeepSeek-V4-Pro — 旗舰模型,是一个拥有 1.6 万亿总参数的超大规模 MoE(混合专家)模型,但每次前向传播仅激活 490 亿参数,这是其高效性能的关键。
- DeepSeek-V4-Flash — 更快速、更高性价比的选择。它采用了与 Pro 版本相同的 MoE 设计,但规模更小(总参数 2840 亿 / 激活 130 亿),能够实现更低延迟和更低成本的推理。
- 两款模型均支持 100 万 token 上下文窗口,并提供完全开源的权重及 API 服务。
| 模型 | 总参数 | 激活参数 | 预训练数据 | 上下文长度 | 开源 | API 服务 | Web/App 访问模式 |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 33T | 1M | ✓ | ✓ | Expert Mode |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✓ | ✓ | Fast Mode |
即日起,您可以通过 chat.deepseek.com 或官方 App 与 DeepSeek-V4 对话。其 API 也已同步上线,只需将 model_name 设置为 deepseek-v4-pro 或 deepseek-v4-flash 即可开始使用。
此前我们已分享过相关猜测与预发布分析(参阅我们的 DeepSeek V4 2026 预期指南 和 技术深度解析),现在我们为您带来官方一手确认的详细信息。下文将梳理本次发布的实际更新,以及对于当前开发者和模型评估者的意义。
DeepSeek-V4-Pro:比肩顶级闭源模型
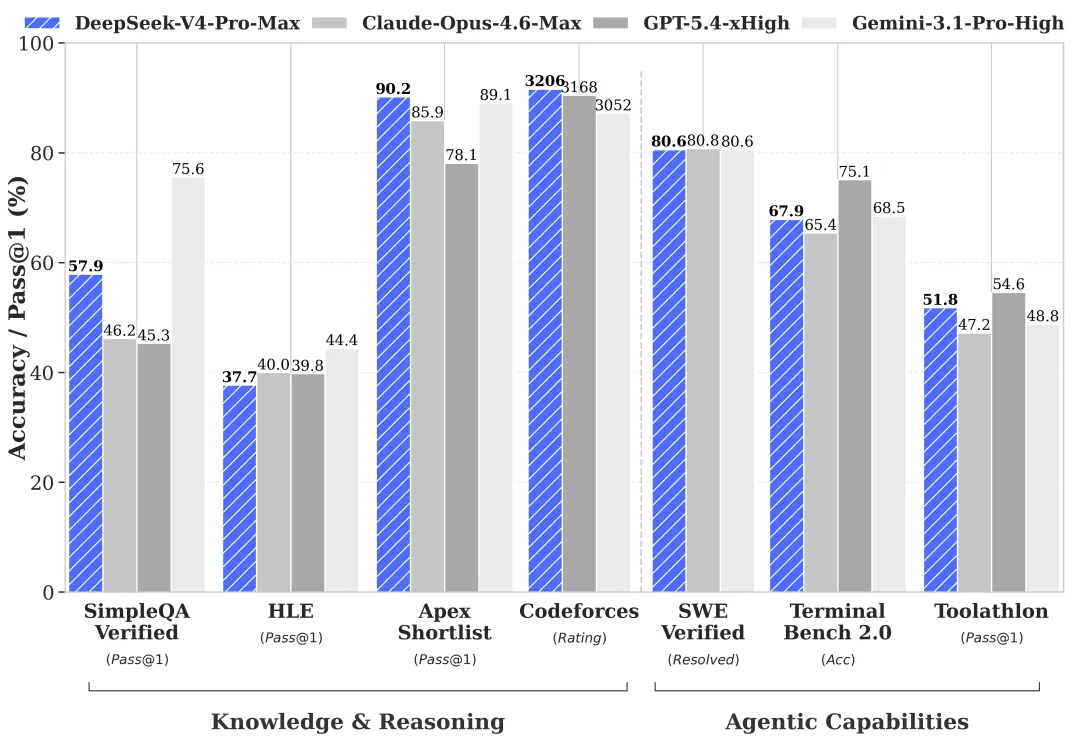
显著增强的智能体(Agent)能力。 与前代产品相比,DeepSeek-V4-Pro 在智能体任务方面表现出巨大的飞跃。在智能体代码编写基准测试中,V4-Pro 现已领先于所有开源模型。DeepSeek 内部已将 V4-Pro 作为首选编程助手,员工反馈显示其体验超过了 Claude Sonnet 4.5,非思维模式(non-thinking mode)下的输出质量接近 Claude Opus 4.6,虽在思维模式(thinking mode)上仍落后于 Opus 4.6,但差距正在缩小。
丰富的世界知识。 DeepSeek-V4-Pro 在世界知识基准测试中明显优于其他开源模型,仅略逊于顶级闭源模型 Gemini Pro 3.1。
世界级的推理能力。 在数学、STEM 和竞争性编程评估中,DeepSeek-V4-Pro 超越了此前所有基准测试中的开源模型,并达到了全球领先闭源模型的表现水平。
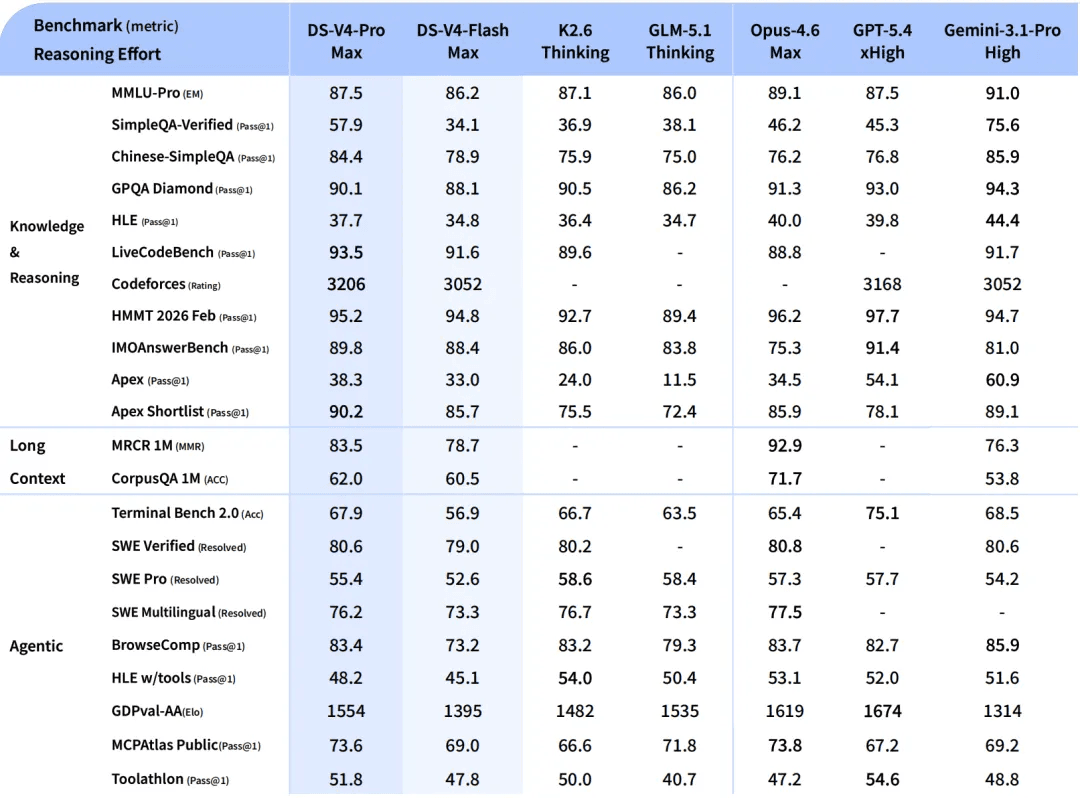
DeepSeek-V4-Flash:兼顾速度与成本
与 V4-Pro 相比,DeepSeek-V4-Flash 在世界知识方面稍逊一筹,但在推理性能上表现相当。凭借较小的参数规模和更低的激活成本,V4-Flash 提供了更快的响应速度和更经济的 API 定价。
在智能体基准测试中,V4-Flash 在简单任务上与 V4-Pro 持平,但在复杂任务上仍存在一定差距。
架构创新与极致的上下文效率
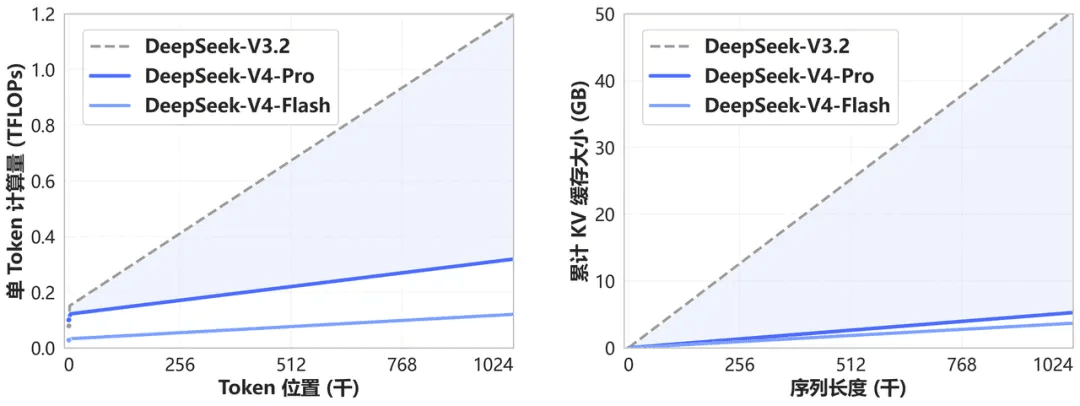
DeepSeek-V4 引入了一种全新的注意力机制,能够在 token 维度进行压缩。结合 DSA (DeepSeek Sparse Attention) 技术,该设计在实现世界领先的长上下文性能的同时,相比传统方法大幅降低了计算和内存需求。
未来,100 万 token 上下文将成为所有 DeepSeek 官方服务的标配。
针对智能体(Agent)场景的专门优化
DeepSeek-V4 已针对 Claude Code、OpenClaw、OpenCode 和 CodeBuddy 等主流智能体产品进行了微调和优化。在代码生成、文档编写以及其他由智能体驱动的任务中,性能均有显著提升。
这种针对框架的特定调优在实际应用中比听起来更重要。一个孤立表现良好但在结构化智能体循环中行为不一致的模型,很难被可靠地部署。将主流智能体框架视为首要优化目标,反映了生产环境 AI 使用方式的演变。
DeepSeek-V4 API 访问
V4-Pro 和 V4-Flash 现已通过 DeepSeek API 提供,支持 OpenAI ChatCompletions 接口和 Anthropic 接口,这意味着现有的集成只需微小的代码修改即可切换至 V4 模型。base_url 保持不变,只需更新模型参数为 deepseek-v4-pro 或 deepseek-v4-flash。
两款模型均支持最大 100 万 token 的上下文长度,并提供 非思维(non-thinking) 和 思维(thinking) 模式。在思维模式下,可设置 reasoning_effort 参数为 high 或 max。对于复杂的智能体工作流,建议使用开启 max 强度的思维模式。API 文档:https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
⚠️ 弃用通知: 旧版模型名称
deepseek-chat和deepseek-reasoner将在 三个月后(2026 年 7 月 24 日) 正式下线。过渡期间,它们将分别映射到deepseek-v4-flash的非思维和思维模式。如果您在生产环境中使用这些名称,请尽早规划迁移。
开源权重与本地部署
- 模型权重:Hugging Face | ModelScope
- 技术报告:DeepSeek-V4 PDF
对于考虑本地或私有化部署的团队,需要注意的是,该参数规模的模型(特别是 1.6T 总参数的 V4-Pro)对硬件要求极高。开源的可用性为企业合规和定制化场景带来了显著优势,但对大多数团队而言,云端 API 访问仍是更切实际的起点。
DeepSeek-V4 发布的实际意义
本次发布有三个关键点值得关注。
首先,100 万 token 上下文的承诺比表面看起来更有分量。DeepSeek 并没有将其作为高级会员权益,而是将其作为所有官方服务的底线标准。这释放了一个关于开源前沿方向的信号,并对其他服务提供商构成了无形的压力。
其次,以 Agent 为优先的优化工作(特别是针对 Claude Code、OpenCode 等的适配)反映了 DeepSeek 在部署策略上的成熟度。基准测试成绩只是入门门槛,在生产环境中,模型在开发者实际使用的工具链中的表现才是核心。
第三,对标 Claude Opus 4.6 的诚恳态度非常值得称道。DeepSeek 没有声称全方位碾压,而是给出了分层的评估:优于 Sonnet 4.5,非思维模式接近 Opus 4.6,思维模式仍落后于 Opus 4.6。这种精准的定位使得其评估结果更具公信力。
对于正在评估智能体工作流、长文档处理或复杂推理任务的开发者来说,DeepSeek-V4-Pro 现已成为极具竞争力的开源选择。而对于成本敏感或对延迟要求较高的管线,V4-Flash 则提供了极具性价比的轻量替代方案。
在 Atlas Cloud 上体验 DeepSeek-V4
Atlas Cloud 是一家生产级的 AI 平台,专为希望在无需管理基础设施的情况下,获得稳定、高性价比、顶级 AI 模型访问权的开发者和团队而设计。通过统一的 API、透明的定价以及企业级合规性(符合 SOC 2 标准,可满足 HIPAA 要求),Atlas Cloud 让您可以专注于开发而非运维。
在 Atlas Cloud 使用 DeepSeek。 我们目前已支持 DeepSeek 模型全系,包括 DeepSeek V3.2、V3.2 Fast、V3.2 Speciale 和 V3.2 Exp,现可通过单一 API 端点以极具竞争力的价格获取。Atlas Cloud 上的 DeepSeek 模型已针对长上下文工作负载和智能体管线进行了优化,支持完整的上下文窗口且无量化损失。除 DeepSeek 外, Atlas Cloud 还提供 LLM 领域 300+ 模型 的访问权限。
DeepSeek-V4 即将登陆 Atlas Cloud。 我们正在积极集成 DeepSeek-V4-Pro 和 V4-Flash,请关注我们的上线公告,在此之前,欢迎探索平台上现有的所有模型资源。






