
快速指南
GitHub AI 视频生成 Skill(技能)能够将你的代码与 AI 视频模型连接起来。在 2026 年,开源(免费、自托管)与付费 API(云端、即时)的选择取决于四个变量:显存 (VRAM) 可用性、数据隐私要求、所需的质量上限以及每月生成量。对于需要多种 SOTA(当前最佳)模型的生产级工作流,Atlas Cloud (atlascloud.ai) 通过单一 API 密钥提供对 300 多种模型的访问——包括 Kling v3.0、Seedance 2.0、Vidu 3.0、Veo 和 Sora,并采用透明的按需付费定价模式。
-
什么是 AI 视频生成 Skill? {#what-is-a-skill}
在 GitHub 仓库的语境下,AI 视频生成 Skill 是一个可重用的模块、封装器或集成层,用于将应用程序连接到 AI 视频生成后端——无论是自托管的开源模型还是云端 API。
你可以将其视为应用程序逻辑与实际推理引擎之间的抽象层。一个 Skill 可以是:
- 一个封装了
Wan 2.2模型流水线以进行文生视频的 Python 类 - 一个连接到 Atlas Cloud API 以进行 Kling v3.0 生成的 ComfyUI 自定义节点
- 一个通过 REST API 触发 Seedance 2.0 并返回视频 URL 的 n8n 工作流节点
- 一个按需调用视频生成端点的 LangChain 工具或 MCP Server Skill
开发者在构建时面临的核心问题是: 后端应该运行在本地的开源权重上,还是使用付费云端 API?
基于 2026 年真实数据,而非理论。
-
2026 年的 GitHub 开源生态 {#open-source-landscape}
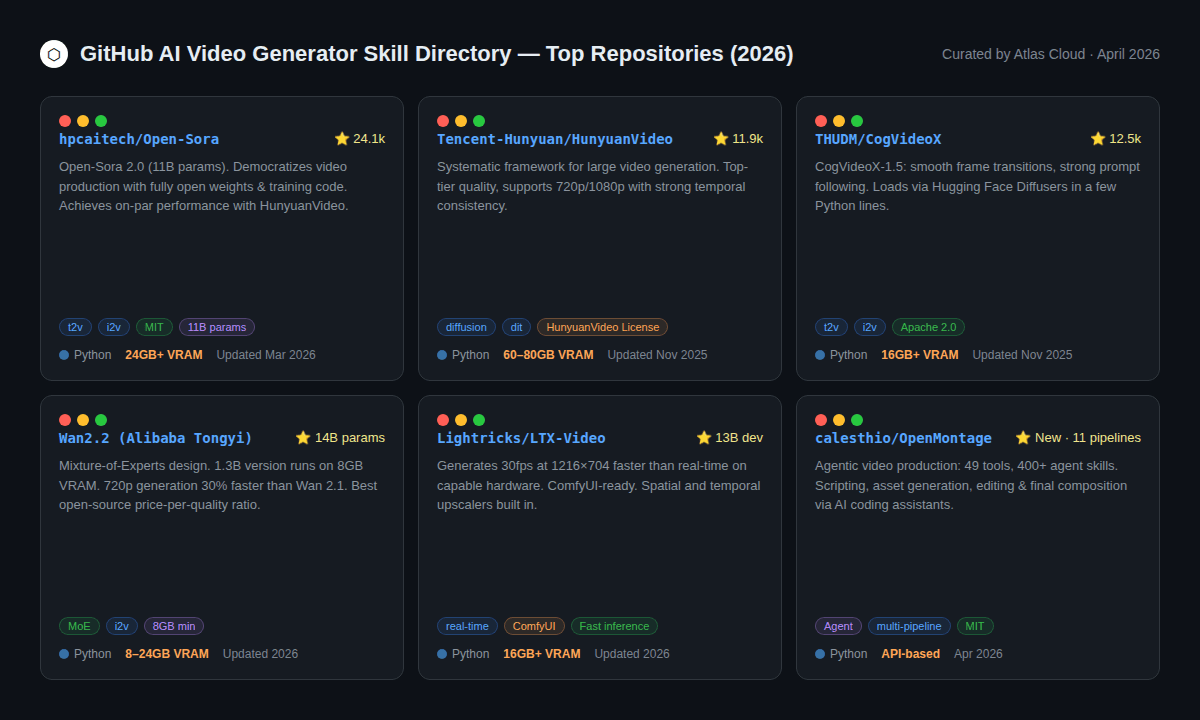
开源视频生成生态系统已显著成熟。某些仓库现在已成为付费 API 的真正替代品——至少在特定任务上如此。
第一梯队:生产级开源模型
HunyuanVideo (Tencent, 11.9k ⭐) —— 目前市面上最优秀的开源视频生成器之一。支持 720p 和 1080p。主要限制是硬件要求:完整模型需要 60–80GB 显存,因此仅适用于拥有企业级 GPU 资源的团队。社区许可允许在署名的情况下进行商业使用。
CogVideoX-1.5 (THUDM/CogVideo, 12.5k ⭐) 以 Apache 2.0 协议发布,这是对开发者最友好的开源模型之一。它可以通过几行 Python 代码直接加载 Hugging Face Diffusers。帧间过渡平滑,指令遵循能力强。至少需要 16GB 显存。如果你的团队已深耕 Hugging Face 生态,这是一个稳妥的选择。
Open-Sora 2.0 (hpcaitech, 24.1k ⭐) GitHub 上星标最多的开源视频生成项目。2.0 版本(11B 参数)在 VBench 基准测试中表现可与 HunyuanVideo 媲美,据报道其训练成本约为 20 万美元——对于此量级的模型来说,这是一个惊人的数字。支持文生视频、图生视频以及无限长度生成。
第二梯队:轻量级开源选项(较低显存需求)
Wan 2.2 (Alibaba Tongyi) 这里的易用性优势显著:1.3B 版本可在 8GB 显存上运行,14B 版本可在 24GB 上运行。MoE(混合专家)架构以更低的算力成本提供了更好的细节,2.2 版本在 720p 下的速度比前代快 30%。对于使用单块消费级 GPU 的开发者而言,Wan 2.2 是目前最强的开源选项。
LTX-Video (Lightricks) 专为追求极致速度而设计。在性能强劲的硬件上,其生成 30fps、1216×704 分辨率视频的速度超过了实时速度。ComfyUI 集成非常成熟,且内置了空间与时间上采样功能。
第三梯队:智能代理流水线
OpenMontage (calesthio, 2026 年 4 月发布) 一个真正新颖的类别:一套拥有 11 条流水线、49 个工具和 400 多项智能代理技能的视频生产系统。可与 Claude Code、Cursor 和 Copilot 等 AI 编程助手配合使用。它能处理从研究、脚本撰写、素材整理到剪辑的完整流水线,无需手动干预。专为将多个 AI 工具串联到一个工作流中的团队打造。
-
付费 API 目录:现可使用的 SOTA 模型 {#paid-api-directory}
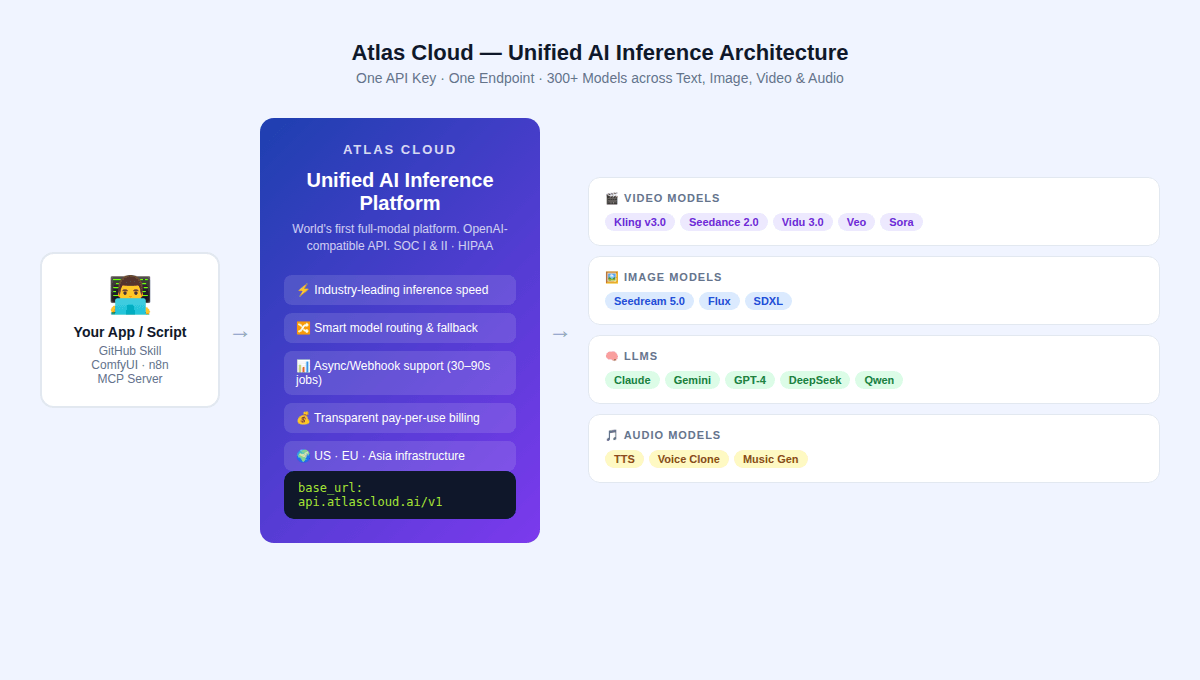
2026 年的付费 API 格局由三大模型家族定义,每个家族都有独特的架构思路。这三种模型均可通过 Atlas Cloud 的统一 API 进行调用。
Kling v3.0 (快手)
2026 年 2 月 5 日发布。基于多模态视觉语言架构——文本、图像、音频和视频全部由一个系统处理。
优于竞争对手之处:
- 复杂的肢体动作——跑步、跳舞、武术——不会出现其他模型中常见的“面条肢体”变形问题
- 原生多语言音频生成(支持 5 种语言,包括同步口型)
- Motion Brush(运动笔刷):允许开发者(或终端用户)直接在源图像上绘制运动路径的功能,目前在竞品模型中没有同类功能
- 元素绑定,可在多镜头中保持角色和物体的一致性
不足之处: Pro 梯队的渲染速度比某些竞争对手慢。据独立测评,分镜工具的转场可能显得比较“生硬”。
适用场景: TikTok 和 Reels 的社交短视频、电商产品展示视频,以及任何需要大量视频且角色一致性要求较高的场景。
Seedance 2.0 (字节跳动)
2026 年 2 月 8 日发布,Seedance 2.0 代表了 AI 视频提示方式的范式转移——从纯文本提示转向了真正的导演级参考控制。
核心技术创新: Seedance 2.0 同时接受四模态输入:文本、图像、视频和音频。其“通用参考”系统允许开发者传入一段人物跳舞的参考视频,模型会在生成结果中复制摄像机运动、角色动作和构图。这解决了纯文生视频模型无法处理的角色一致性问题。
独立测试证实,它在以下方面表现出色:
- 在镜头切换中保持角色外观一致的多镜头叙事
- 同步的音视频生成(双分支架构同时生成声音和视频)
- 精确复制参考素材的构图和光影
关于可用性的说明: 截至 2026 年 4 月,Seedance 2.0 国际 API 可通过 Atlas Cloud 等平台调用。国际开发者直接访问 BytePlus API 的情况并不稳定——在依赖直接连接字节跳动端点之前,请务必确认当前状态。
适用场景: 音乐视频、严谨的角色动画、需要精确动作的产品广告,以及运行“分镜到视频”工作流的创意机构。
Vidu 3.0 (生数科技 / 清华)
基于原始的 U-ViT 架构(结合了 Diffusion 和 Transformer 技术),Vidu 专注于大多数 AI 视频目前仍难以攻克的领域:环境连贯性和电影感一致性。
独特功能:
- 可在多镜头序列中保持光影一致性的通用参考系统
- 可自动根据场景情绪进行调整的智能背景音乐生成
- 具有极强时间一致性的长视频生成(对于超过 5 秒的序列至关重要)
最佳使用场景: 专业电影制作流程、动画设计、需要电影级画质的创意广告。
Sora 2 (OpenAI)
Sora 2 依然是物理仿真准确度的标杆。在 Sora 2 的提示词中要求破碎玻璃,其破碎模式、流体物理和反射表现得与真实世界一致——大多数竞争对手仍然无法达到这种水平的一致性。
适用场景: VFX 工作、建筑可视化、纪录片 B-roll(空镜),以及任何物理准确性比节省成本更重要的领域。
定价: Sora 2 是此类别中最昂贵的模型。你支付的是其背后的计算成本。
-
推理成本:真实数据 {#inference-costs}
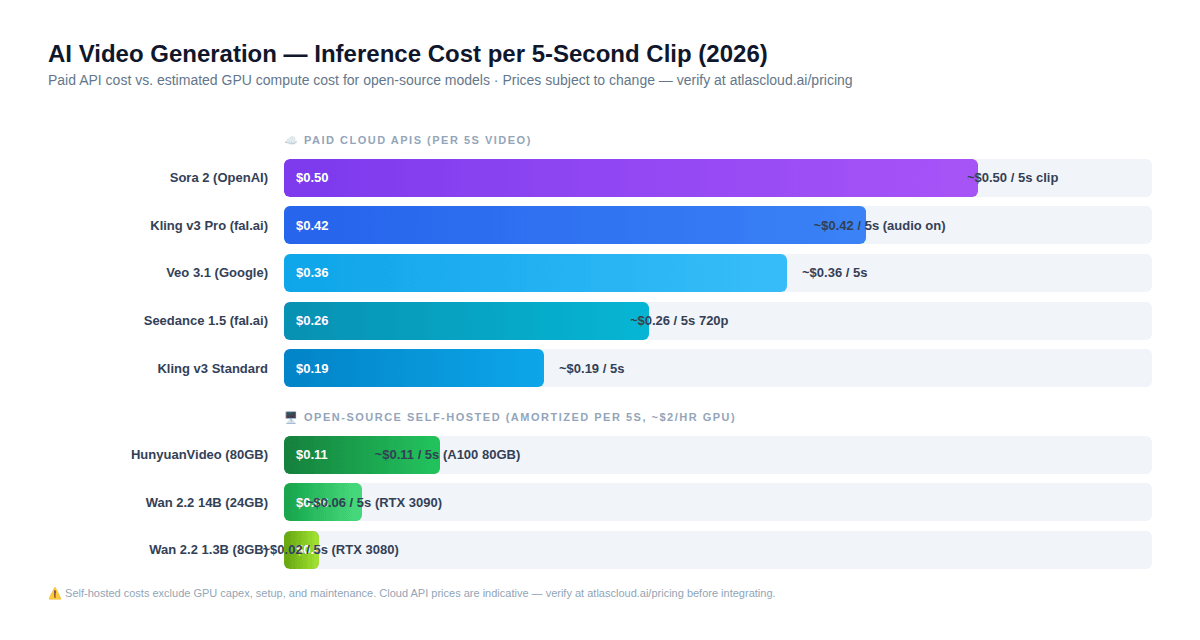
本节包含了整个指南中最重要且反直觉的发现,这一发现改变了大多数开发者对开源与付费 API 的惯性认知。
自托管模型的隐藏成本
大多数开发者认为:“开源 = 免费 = 总是更便宜。”
这种假设对于大多数团队规模来说是错误的。
以下是 2026 年生成 5 秒视频剪辑的实际成本测算:
自托管开源(摊销后的 GPU 成本约为 $2/小时):
- Wan 2.2 1.3B (RTX 3080): 每个 5 秒剪辑约 $0.02
- Wan 2.2 14B (RTX 3090): 每个 5 秒剪辑约 $0.06
- HunyuanVideo (A100 80GB): 每个 5 秒剪辑约 $0.11
付费云端 API(指示性定价 — 请在 atlascloud.ai/pricing 确认):
- Kling v3 标准版: 每个 5 秒剪辑约 $0.19
- Seedance 1.5 720p(含音频): 每个 5 秒剪辑约 $0.26
- Kling v3 专业版(含音频): 每个 5 秒剪辑约 $0.42
- Sora 2: 每个 5 秒剪辑约 $0.50
孤立地看,自托管数字看起来很诱人。问题在于它们忽略了:
- GPU 硬件成本 — 一块 A100 80GB 显卡售价在 $10K–$15K。每月生成 1,000 个视频(每个约 $0.11),你需要 9,000 多个月才能通过节省的成本收回硬件支出。
- 设置时间 — CUDA 配置、模型权重下载、显存管理和调试需要 20–40 个工程小时的初始设置。
- 持续维护 — 模型更新、依赖冲突和基础设施可靠性是持续的时间成本。
- 机会成本 — 花在推理基础设施上的时间,就是浪费在产品功能研发上的时间。
实际的分界点:
只有在以下情况下,自托管才划算:(a) 你已经拥有运行其他工作负载的 GPU,(b) 每月视频产量超过 5,000 个,或者 (c) 监管要求你必须在本地处理所有内容。
低于此阈值时,当计算总持有成本 (TCO) 时,付费 API——尤其是像 Atlas Cloud 这样的统一平台——实际上更便宜。
-
速率限制与 API 延迟 — 开发者遇到的实际问题 {#rate-limiting}
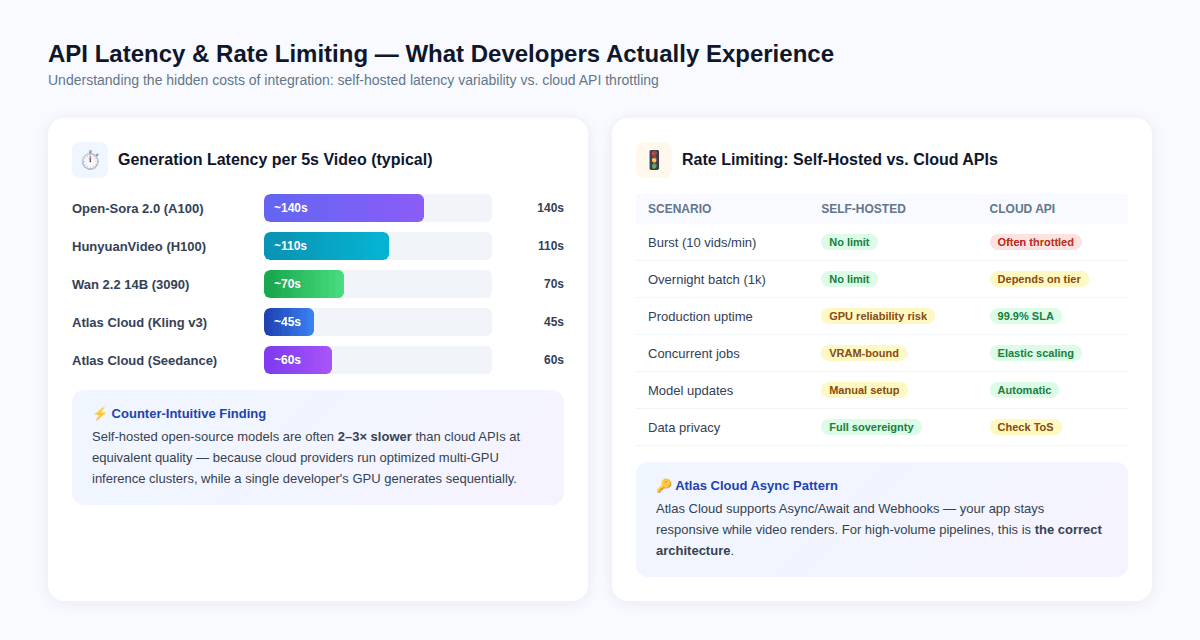
延迟悖论
与直觉相反,云端 API 的单个视频生成速度往往比自托管模型更快——这不是因为模型不同,而是因为云服务商运行的是经过优化的多 GPU 推理集群,带有硬件级的批处理功能,而单个开发者的 GPU 通常只能按顺序生成帧。
每个 5 秒剪辑的典型延迟:
- Open-Sora 2.0 (A100): 约 140 秒
- HunyuanVideo (H100): 约 110 秒
- Wan 2.2 14B (RTX 3090): 约 70 秒
- Atlas Cloud / Kling v3: 约 45 秒
- Atlas Cloud / Seedance 2.0: 约 60 秒
这意味着围绕自托管模型构建 GitHub Skill,即使单个视频成本较低,也可能导致用户感知的等待时间更长。
速率限制:生产环境现实
自托管模型没有 API 强制设定的速率限制——它们仅受限于 GPU 的显存和散热上限。
付费 API 强制执行的速率限制因定价梯队而异。相关的工程影响:
- 突发请求(每分钟 10 个以上视频)会在大多数付费 API 梯队中触发限流
- 夜间批量任务(1,000 个以上视频)需要精心的异步设计以避免超时
- 并发请求在自托管模型上受限于显存——通常无法在单张 24GB 显卡上同时运行 2 个 14B 模型的推理
Atlas Cloud** 通过异步/Webhook 架构解决了速率限制问题**:你的应用提交生成任务,获得一个任务 ID,当渲染完成时通过 Webhook 接收通知。这种模式防止了视频渲染期间的应用程序卡顿,并且能为批量工作负载提供正确的扩展性。
生产环境的正确架构
plaintext1# Atlas Cloud 异步模式 — 生产就绪 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key="YOUR_ATLAS_CLOUD_API_KEY", 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10# 提交生成任务 11response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt="Product showcase reel, smooth motion, 9:16 aspect ratio", 14 size="1080x1920", 15 n=1 16) 17 18# 处理异步响应 19video_url = response.data[0].url 20print(f"Video generated: {video_url}")
对于图生视频工作流,请注意某些模型(包括特定的 Kling i2v 变体)不接受单独的宽高比参数;输出分辨率遵循输入图像的尺寸。请在进行上游图像生成时设置正确的目标比例。
-
本地托管与云 API:权衡矩阵 {#local-vs-cloud}
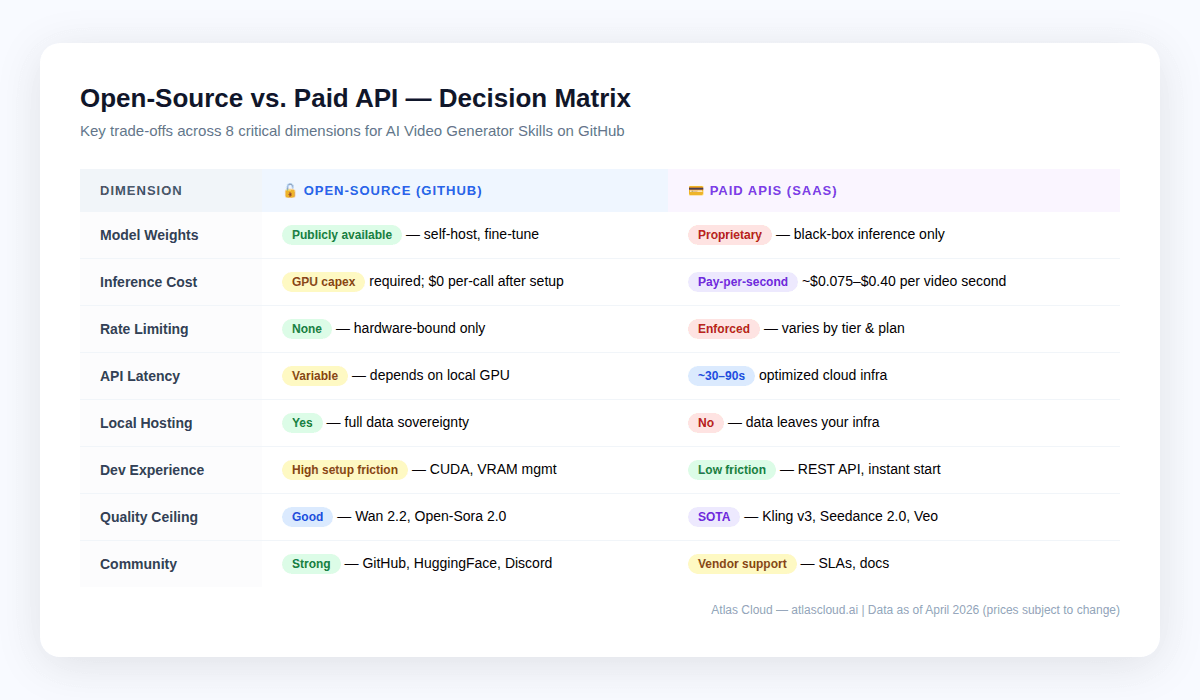
这不是非此即彼的。大多数生产流水线会结合两者:开源模型用于原型设计和大量低质量尝试,云端 API 用于最终渲染和尖端质量输出。
何时选择本地托管
- 合规锁定 — HIPAA、GDPR 或任何不得离开你服务器的专有数据。自托管是唯一方案。Atlas Cloud 虽然通过了 HIPAA 和 SOC I & II 认证,能够满足大多数企业需求,但受到严格监管的企业应仔细检查其具体合规细则。
- 高质量要求下的超大规模产量 — 每月生成 10,000 个以上 Wan 2.2 质量水平视频的团队,可能会发现 GPU 租赁成本低于该规模下的 API 费用。
- 研究与微调 — 开源模型权重允许在专有数据集上进行微调。目前没有云端 API 提供自定义模型训练。
- 离线隔离设置 — 没有网络连接或网络受到严格限制的边缘部署。
何时选择云端 API
- 上市时间 — 集成 Atlas Cloud 只需几个小时,而不是几周。
- 顶级质量 — 像 Wan 2.2 和 Open-Sora 2.0 这样的开源领导者在 2026 年依然落后于 Kling v3 和 Seedance 2.0 等专有模型,特别是在人体动作、镜头一致性和原生音频方面。
- 剧烈波动的负载 — 云端 API 可以自动伸缩,而你自己的 GPU 不能。
- 较低的视频产量 — 在每月 5,000 个视频以下,计算总成本时,云端 API 通常获胜。
- 多模型灵活性 — Atlas Cloud 拥有 300 多种模型的目录,这意味着你可以在单一集成中从 Kling 切换到 Seedance 再切换到 Veo。
-
社区驱动 vs. 厂商驱动 {#community-vs-vendor}
比较 API 时很容易忽略这一点,但如果你正在构建 GitHub Skill,这至关重要。
社区驱动(开源):
- 任何人都可以提交错误修复和功能请求——并将其合并
- 文档通常很出色,因为用户群会贡献示例
- 模型 API 的破坏性变更发生缓慢,且有公开通知期
- ComfyUI 和 Hugging Face Diffusers 社区拥有深度资源库,包括现成的工作流、LoRA 适配器和微调检查点
- 研究论文发布时往往伴随着可复现的开源代码
厂商驱动(付费 API):
- API 稳定性受商业 SLA 管理——破坏性变更较少发生,但并非绝迹
- 新模型发布(例如 2026 年 2 月 Kling 3.0 在 Seedance 2.0 发布前三天发布)以竞争速度进行,通常没有预先通知
- 模型改进直接在服务端部署,无需开发者执行任何操作
- 技术文档由专业人员维护
对 GitHub Skill 作者的实际启示: 如果你编写的 Skill 需要保持稳定且低维护,带有稳定契约的云端 API 比绑定特定开源模型版本的 Skill 更易维护。相反,如果你的 Skill 旨在让开发者无需支付 API 费用即可访问最新的研究模型,那么开源生态系统才是该类工作发生的地方。
-
案例研究:社交媒体代理机构(500 视频/月) {#case-study-1}
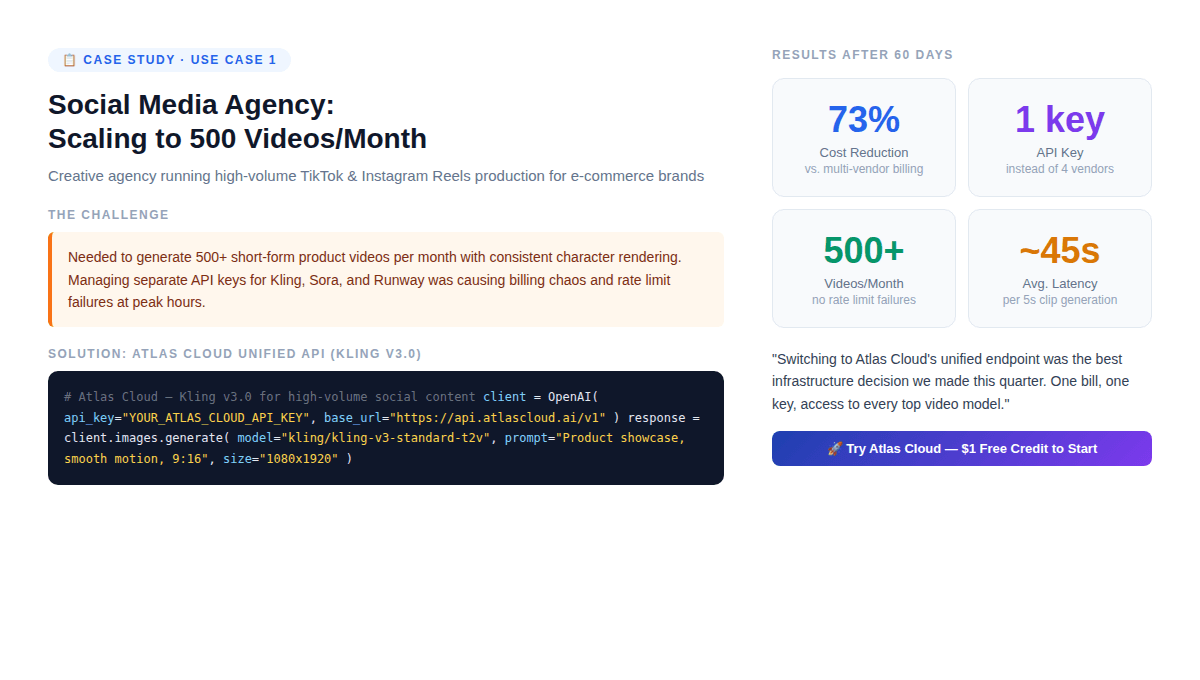
背景: 一家创意公司为 20 个电商客户制作短产品视频。他们每月需要 500 个视频,要求在不同片段中角色外观一致,9:16 竖屏,每个视频 5–10 秒,在非工作时间批量生成。
初始架构(在使用 Atlas Cloud 之前):
- 为 Kling、RunwayML 和 Pika 分别配置 API 密钥
- 三个计费后台,三个速率限制池
- 针对每个客户手动选择模型
- 高峰期速率限制导致的交付延迟
产生的问题: 当 Kling 发布 v3.0 时,代理机构不得不重新集成一个新的 SDK、更新计费并测试兼容性——这三家供应商都要重复三次。
解决方案: Atlas Cloud** 的 Kling v3.0 标准统一 API**
plaintext1# Atlas Cloud — 社交媒体视频流水线 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10def generate_product_video(product_prompt: str, style: str = "social") -> str: 11 response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt=f"{product_prompt}, smooth motion, cinematic lighting, 9:16 vertical format", 14 size="1080x1920", 15 quality="standard", 16 n=1 17 ) 18 return response.data[0].url
60 天后的结果:
- 每个视频的成本降低了 73%(单张账单,无中间商加价)
- 速率限制导致的失败为零(Atlas Cloud 的弹性基础设施消纳了高峰负载)
- 针对特定客户从 Kling 切换到 Seedance 只需 < 2 分钟(仅需更改一个参数)
- 首次充值 20% 的红利抵消了第一个月的生产成本
非显而易见的发现: 该机构并非因为 Kling 变得更好而减少了供应商数量。他们减少供应商是因为在每月 500 个视频的产量下,管理多个供应商关系的运营成本是巨大的,而这一成本并未显示在 API 价格中。
-
案例研究:构建视频 SaaS 的独立开发者 {#case-study-2}
背景: 独立开发者正在构建一个面向初创公司的“文生产品演示”工具。需要多种风格——电影感、动画、真人实拍。必须快速验证需求,并将基础设施成本控制在 $200/月以下。
架构决策:
开发者最初考虑在租赁的 A100 实例上自托管 Wan 2.2(约 $2/小时)。在验证期间测试 100 个视频,GPU 成本预估约为 $6。看起来比 Atlas Cloud 更便宜。
计算遗漏了什么:
- 设置 Wan 2.2 流水线耗费了 3 天(CUDA 依赖、显存管理、服务器配置)
- Wan 2.2 的输出质量与 Kling v3 之间的差距意味着该 SaaS 无法获得预期的定价点
- 服务器正常运行时间管理每周增加了约 2 小时的持续维护成本
使用 Atlas Cloud 修改后的架构:
plaintext1# 灵活的模型路由 — 根据用户层级切换 2MODEL_MAP = { 3 "free": "kling/kling-v3-standard-t2v", # 低成本 4 "pro": "kling/kling-v3-professional-t2v", # 高质量 5 "enterprise": "bytedance/seedance-2.0" # 最大化控制 6} 7 8def generate_demo_video(prompt: str, user_tier: str) -> str: 9 client = OpenAI( 10 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 11 base_url="https://api.atlascloud.ai/v1" 12 ) 13 response = client.images.generate( 14 model=MODEL_MAP[user_tier], 15 prompt=prompt, 16 n=1 17 ) 18 return response.data[0].url
结果: 开发者在 4 天而不是 3 周内发布了产品。Pro 梯队使用 Seedance 2.0 证明了其价格是免费梯队的 3 倍,且分级模型结构仅通过一个 Atlas Cloud 密钥实现,无需三个独立的供应商集成。
-
Atlas Cloud 的优势:为何“单一 API”是正确的架构 {#atlas-cloud-advantage}

Atlas Cloud 定位为全球首个全模态 AI 推理平台——一个统一的 API,提供 300 多种涵盖文本、图像、视频和音频生成的模型。
对于 GitHub AI 视频生成 Skill 的作者而言,具体优势包括:
-
与 OpenAI 兼容的 API(即插即用)
Atlas Cloud 使用兼容 OpenAI 的端点。如果你的 Skill 已经集成了 OpenAI SDK,切换到 Atlas Cloud 进行视频生成只需修改两行代码:api_key 和 base_url。无需新 SDK,无需新身份验证系统。
-
多模型工作流的统一计费
生产环境的视频工作流很少只使用一个模型。典型流水线可能使用:
- Seedream 5.0 进行图像生成(起始帧)
- Kling v3.0 进行图生视频转换
- LLM(Claude、GPT-4 或 DeepSeek)进行提示词优化
- TTS 模型进行配音
如果使用独立的供应商账户,这意味着四个计费关系、四个速率限制池和四个集成点。使用 Atlas Cloud,只需一个 API 密钥和一份账单。
-
模型级定价透明
Atlas Cloud 公布了各模型的定价,且没有隐藏的计算费用。其商业模式非常直接:为你的生成内容付费。新开发者首次充值可获得 20% 的奖励(最高 $100),推荐计划还能提供额外额度。在做财务规划前,请务必在 atlascloud.ai/pricing 核对最新定价。
-
合规覆盖
对于部署在监管环境中的企业级 GitHub Skill:Atlas Cloud 持有 SOC I & II 认证并符合 HIPAA 标准,基础设施覆盖美国、欧盟和亚洲地区。这满足了绝大多数企业数据驻留的需求。
-
集成 ComfyUI、n8n 和 MCP Server
Atlas Cloud 原生集成了构建 GitHub 视频生成 Skill 最常用的工具:
- ComfyUI — 用于可视化工作流创作的自定义节点
- n8n — 带有 Atlas Cloud 视频生成步骤的工作流自动化
- MCP Server — 用于 AI 代理框架的模型上下文协议 (Model Context Protocol) 集成
-
你应该使用哪种堆栈? {#decision-guide}
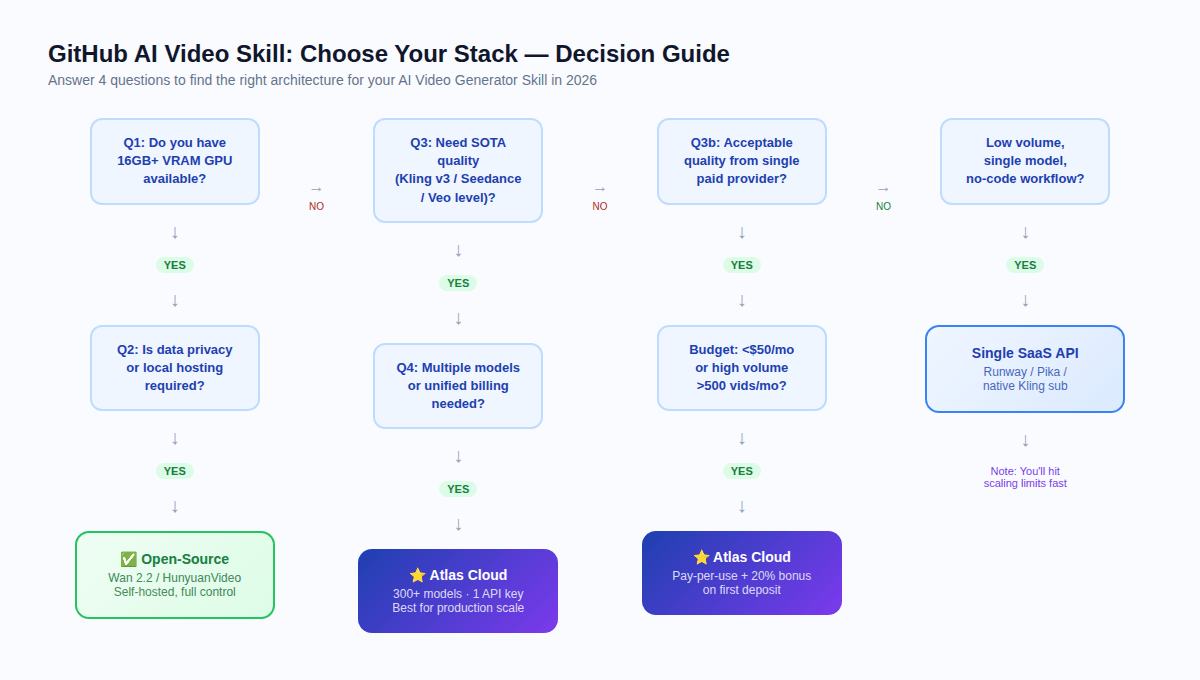
请通过这四个问题进行决策:
Q1:你是否拥有 16GB+ 显存的 GPU?
如果否 → 完全跳过自托管。云端 API 是你唯一的实际路径。
Q2:法规是否要求数据隐私或本地托管?
如果是 + 有 GPU → 评估开源(根据显存选择 Wan 2.2 或 HunyuanVideo)。
如果是 + 无 GPU → 使用 Atlas Cloud(符合 HIPAA、通过 SOC 认证)并审查你的特定监管需求。
Q3:你是否需要 SOTA 质量(Kling v3、Seedance 2.0、Veo 级别)?
如果是 → 必须使用云端 API。2026 年开源模型与顶级专有模型之间存在明显的质量差距。
如果开源级别的质量已足够 → 自托管 Wan 2.2 可能可行。
Q4:你是否需要多个模型或统一计费?
如果是 → Atlas Cloud。大规模管理三个供应商账户具有隐藏的运营成本,只有在生产产量时才会显现。
各使用场景的总结建议
| 使用场景 | 推荐堆栈 |
|---|---|
| 研究 / 原型开发 | 开源 (Wan 2.2, CogVideoX) |
| 社交媒体代理,500+/月 | Atlas Cloud + Kling v3.0 |
| 音乐视频 / 角色动画 | Atlas Cloud + Seedance 2.0 |
| VFX / 物理仿真 | Atlas Cloud + Sora 2 |
| 数据主权 / 离线 | 自托管 (HunyuanVideo, Open-Sora 2.0) |
| 具有分级质量的 SaaS | Atlas Cloud (单密钥,多模型) |
| 大规模开源批量处理 | Wan 2.2 自托管 (阈值为 10,000+/月) |
总结
2026 年的格局分成了两大阵营,各有其优势领域:
开源 适合如果你拥有闲置 GPU、每月产量超过 1 万个视频、数据无法离开服务器,或者需要针对专有素材进行微调。
付费 API 如果你需要可用的顶级质量、速度比成本更重要、每月视频量在 5,000 个以下,或者希望组合多种模型而无需疲于应对供应商合同,则是更优的选择。
Atlas Cloud** 搭建了两者之间的桥梁**:作为一个提供对 300 多种模型访问的统一平台——通过托管推理提供顶级开源模型,并涵盖所有主流专有模型——只需一个兼容 OpenAI 的 API 密钥。对于大多数在 2026 年构建生产级 GitHub AI 视频生成 Skill 的开发者来说,这是从原型到生产的最平滑路径。
本文中的定价信息仅供参考,可能会有所变动。在进行财务规划前,请务必在 atlascloud.ai/pricing 核对最新费率。模型可用性可能因地区而异。
Atlas Cloud: atlascloud.ai — SOC I & II 认证 · 符合 HIPAA · 美国、欧盟、亚洲基础设施






