
Wan2.5 Video Models
Wan 2.5 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. It delivers realistic motion, natural lighting, and strong prompt alignment across 480p to 1080p outputs—ideal for creative and production-grade workflows.
Explore the Leading Wan2.5 Video Models
Wan-2.5 Text-to-video Fast
Convert prompts into cinematic video clips with synchronized sound. Wan 2.5 generates 480p/720p/1080p outputs with stable motion, native audio sync, and prompt-faithful visual storytelling.
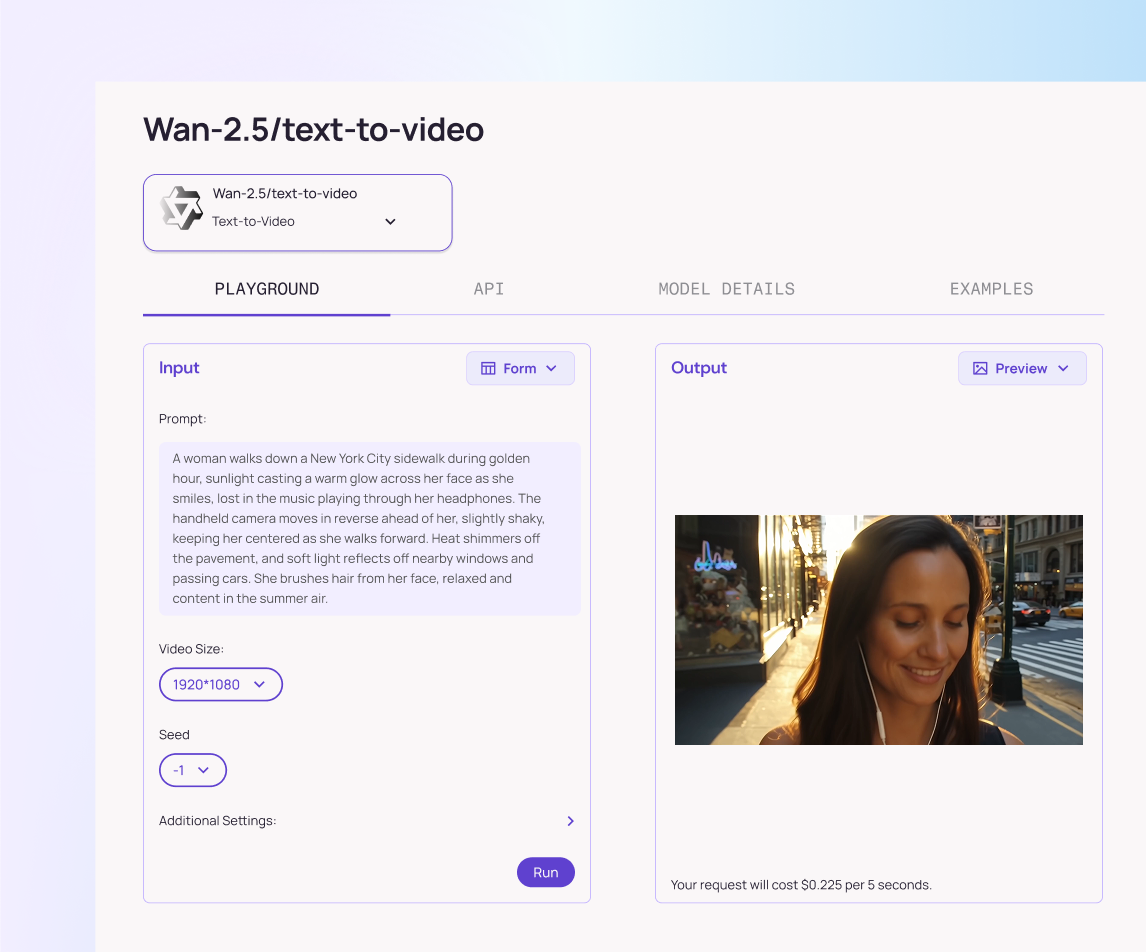
Wan-2.5 Text-to-video
A speed-optimized text-to-video option that prioritizes lower latency while retaining strong visual fidelity. Ideal for iteration, batch generation, and prompt testing.
Wan-2.5 Image-to-video
Bring static images to life with dynamic motion, lighting consistency, and synchronized audio. This variant smoothly animates reference visuals into short video sequences.
Wan-2.5 Image-to-video Fast
Get animated visuals from your images faster without major quality sacrifice. Perfect for preview workflows, previews at scale, or mass production of animated assets.

What Makes Wan2.5 Video Models Stand Out

Native A/V Sync
Generates perfectly aligned visuals and sound without extra editing.

Unified Multimodal Core
Handles text, image, video, and audio in one seamless model.

Extended Clip Duration
Creates up to 10-second videos for richer storytelling.

Flexible Prompt Inputs
Works from text or images to generate or animate content.

Flexible Prompt Inputs
Understands Chinese, English, and other languages natively.

Cinematic Control
Direct camera motion, pacing, and composition right from your prompt.
What You Can Do with Wan2.5 Video Models
Generate cinematic clips between 5 to 10 seconds length at 480p, 720p, or 1080p resolutions.
Sync visuals and audio in one pass — lip-sync, dialogue, sound effects and background music come together automatically.
Animate any image by turning still visuals into dynamic motion with matching audio cues.
Localize with multilingual prompts: Chinese, English, and more are supported natively.
Preview ideas rapidly with a fast-iteration variant of models to test concepts before full render.

Why Use Wan2.5 Video Models on Atlas Cloud
Combining the advanced Wan2.5 Video Models models with Atlas Cloud's GPU-accelerated platform provides unmatched performance, scalability, and developer experience.
Reality in motion. Powered by Atlas Cloud, Wan 2.5 brings life, light, and emotion into every frame with natural precision.
Performance & flexibility
Low Latency:
GPU-optimized inference for real-time reasoning.
Unified API:
Run Wan2.5 Video Models, GPT, Gemini, and DeepSeek with one integration.
Transparent Pricing:
Predictable per-token billing with serverless options.
Enterprise & Scale
Developer Experience:
SDKs, analytics, fine-tuning tools, and templates.
Reliability:
99.99% uptime, RBAC, and compliance-ready logging.
Security & Compliance:
SOC 2 Type II, HIPAA alignment, data sovereignty in US.
Explore More Families
Hailuo Video Models
MiniMax Hailuo video models deliver text-to-video and image-to-video at native 1080p (Pro) and 768p (Standard), with strong instruction following and realistic, physics-aware motion.
Wan2.5 Video Models
Wan 2.5 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. It delivers realistic motion, natural lighting, and strong prompt alignment across 480p to 1080p outputs—ideal for creative and production-grade workflows.
Sora-2 Video Models
The Sora-2 family from OpenAI is the next-generation video + audio generation model, enabling both text-to-video and image-to-video outputs with synchronized dialogue, sound effect, improved physical realism, and fine-grained control.
Kling Video Models
Kling is Kuaishou’s cutting-edge generative video engine that transforms text or images into cinematic, high-fidelity clips. It offers multiple quality tiers for flexible creation, from fast drafts to studio-grade output.
Imagen Image Models
Imagen is Google’s diffusion-based image generation family, designed for photorealism, creativity, and scalable content workflows. With options from fast inference to ultra-high fidelity, Imagen balances speed, detail, and enterprise reliability.
Veo Video Models
Veo is Google’s generative video model family, designed to produce cinematic-quality clips with natural motion, creative styles, and integrated audio. With options from fast, iterative variants to high-fidelity production outputs, Veo enables seamless text-to-video and image-to-video creation.
Seedance Video Models
Seedance is ByteDance’s family of video generation models, built for speed, realism, and scale. Available in Lite and Pro versions across 480p, 720p, and 1080p, Seedance transforms text and images into smooth, cinematic video on Atlas Cloud.
Wan2.2 Media Models
Wan 2.2 introduces a Mixture-of-Experts (MoE) architecture that enables greater capacity and finer motion control without higher inference cost, supporting both text-to-video and image-to-video generation with high visual fidelity, smooth motion, and cinematic realism optimized for real-world GPU deployment.
DeepSeek LLM Models
The DeepSeek LLM family delivers state-of-the-art performance, rivaling top proprietary models through a uniquely efficient architecture that drastically lowers costs. As a fully open-source suite, it provides superior transparency and adaptability compared to closed-source alternatives, making advanced AI more accessible.
Anthropic Claude LLM Models
Anthropic’s Claude models are built with a strong focus on reliability, safety, and advanced reasoning. From lightning-fast lightweight models to frontier-level intelligence, Claude powers real-world use cases with options for instant responses or extended, step-by-step thinking.
OpenAI LLM Models
OpenAI’s leading family of LLMs, engineered for high performance, cost-efficient reasoning, and real-world enterprise applications. With models optimized for text, code, and multimodal tasks, OpenAI delivers production-ready AI trusted by developers, researchers, and enterprises globally.
Gemini LLM Models
Gemini is Google’s multimodal LLM family, combining speed, reasoning, and image generation in one unified system. From Flash variants for low-latency inference to Pro models with advanced reasoning and Nano Banana image generation, Gemini covers the full spectrum of workloads.

Only at Atlas Cloud.