Kimi K2.6 vs GLM 5.1 vs Qwen 3.6 Plus vs MiniMax M2.7: ¿Qué modelo de código abierto es mejor para programar en 2026?

La respuesta corta
Si estás creando un agente de programación autónomo que se ejecute durante horas sin intervención: Kimi K2.6. Obtuvo un 66.7% en Terminal-Bench 2.0 y mantuvo más de 4,000 llamadas a herramientas durante una sesión ininterrumpida de 13 horas en los benchmarks publicados; un techo de estabilidad que ningún otro modelo abierto en esta comparativa alcanza.
Si necesitas el mejor desarrollador front-end agente: GLM 5.1. Su Elo de 1,530 en Code Arena, verificado de forma independiente (tercero a nivel mundial en desarrollo web agente), refleja la preferencia real de los desarrolladores en comparativas directas, no solo en suites de pruebas automatizadas.
Si la restricción es el coste por token: MiniMax M2.7, a USD0.30/M de tokens de entrada en Atlas Cloud, obtiene un 56.22% en SWE-Bench Pro con solo 10B de parámetros activados: el 94% del rendimiento de GLM-5.1 a aproximadamente una quinta parte del coste.
Si tu base de código es demasiado grande para una ventana de contexto de 262K: Qwen 3.6 Plus, el único modelo aquí con soporte para 1M de tokens de contexto y el líder en Terminal-Bench 2.0 con un 61.6% entre este grupo.
Resumen de benchmarks clave
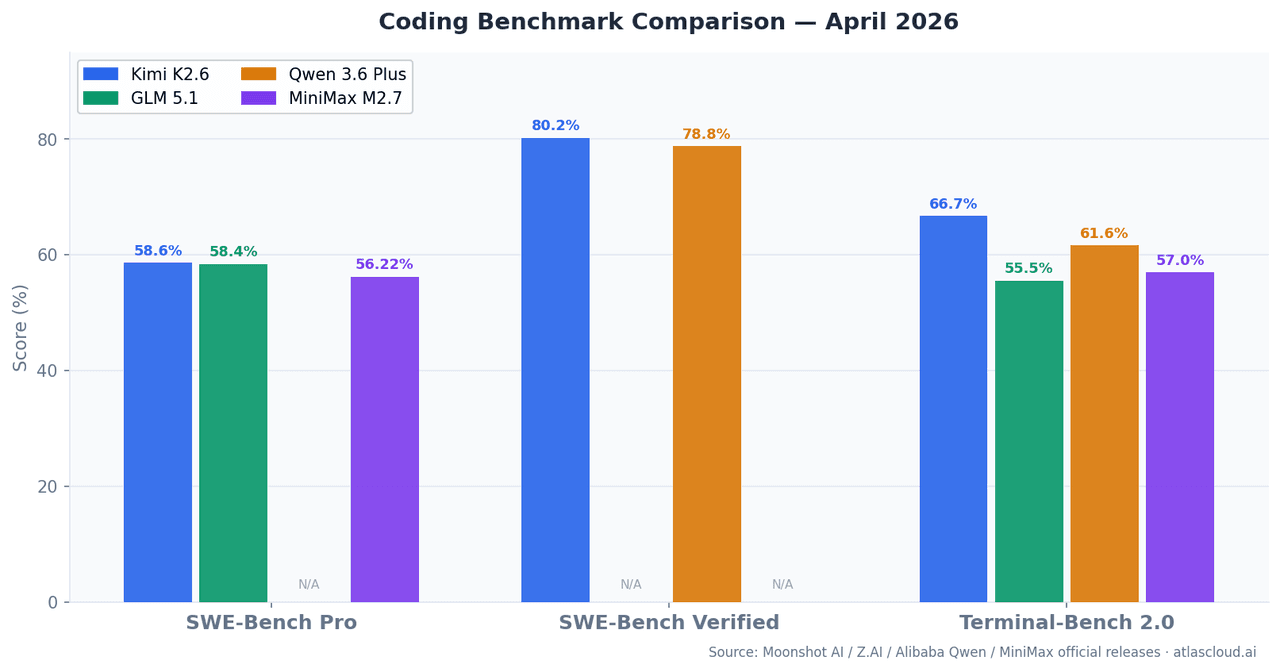
| Modelo | SWE-Bench Pro | SWE-Bench Verified | Terminal-Bench 2.0 | Ventana de contexto | Parámetros activados |
|---|---|---|---|---|---|
| Kimi K2.6 | 58.60% | 80.20% | 66.70% | 262K | — |
| GLM 5.1 | 58.40% | — | 55%+ | 262K | 754B (MoE) |
| Qwen 3.6 Plus | — | 78.80% | 61.60% | 1M | Híbrido MoE |
| MiniMax M2.7 | 56.22% | — | 57.00% | 196K | 10B |
SWE-Bench Pro mide la capacidad de resolver problemas reales de GitHub reportados después del corte de entrenamiento, reduciendo el riesgo de contaminación de datos en comparación con SWE-Bench Verified. Terminal-Bench 2.0 evalúa tareas de CLI y shell de varios pasos en entornos de terminal reales, lo cual se acerca más a lo que realmente hacen los agentes en producción.
Kimi K2.6: Diseñado para agentes de larga ejecución
Moonshot AI lanzó Kimi K2.6 en abril de 2026 como una actualización de K2.5, con la principal mejora en la estabilidad de los agentes en sesiones extendidas. Con un 80.2% en SWE-Bench Verified, se sitúa justo por debajo de Claude Opus 4.6 (80.8%) y lidera a los cuatro con un 58.6% en SWE-Bench Pro.
La cifra que más importa es el 66.7% en Terminal-Bench 2.0. Este benchmark difiere de SWE-Bench en un aspecto fundamental: ejecuta tareas dentro de entornos de terminal reales, lo que requiere que el modelo lea resultados, maneje errores, se adapte e itere, no solo que genere parches. Que Kimi K2.6 mantenga su rendimiento a lo largo de más de 4,000 llamadas a herramientas en una única sesión de 13 horas no es un artefacto de laboratorio, sino un comportamiento documentado en el lanzamiento técnico de Moonshot.
Una ventaja poco comentada: la generalización entre lenguajes. Kimi K2.6 muestra un rendimiento consistente en tareas de Rust, Go, Python, front-end y DevOps. La mayoría de las evaluaciones de benchmarks están saturadas de Python; si tu stack de producción es políglota, esto es importante.
Dónde no es la mejor opción: A USD0.95/M de tokens de entrada en Atlas Cloud, K2.6 es el modelo más caro del grupo en cuanto a entrada. Para tareas de procesamiento por lotes donde envías muchas peticiones con contextos grandes pero no necesitas la estabilidad de una sesión de 12 horas, el coste se acumula más rápido que con MiniMax M2.7 o Qwen 3.6 Plus.
GLM 5.1: El referente en front-end agente
Z.AI lanzó GLM-5.1 el 7 de abril de 2026. Con 754 mil millones de parámetros y enrutamiento MoE, es el modelo más grande de esta lista en cuanto a número de parámetros brutos. En SWE-Bench Pro obtiene un 58.4%, un resultado estadísticamente indistinguible del 58.6% de Kimi K2.6.
El factor diferencial es su Code Arena Elo de 1,530, verificado de forma independiente por Arena.ai el 10 de abril de 2026, lo que lo coloca tercero a nivel mundial en su clasificación de desarrollo web agente. Esta es una comparación directa en vivo donde desarrolladores reales votan los resultados. La ventaja se concentra en la generación de UI de front-end, andamiaje full-stack, creación de componentes React/Vue y NL2Repo (generación de estructuras completas de repositorios a partir de lenguaje natural).
La condición límite a tener en cuenta: La ventaja de GLM-5.1 en front-end es real. Para problemas algorítmicos puros en HumanEval y MBPP, no mantiene una ventaja medible sobre Kimi K2.6. La brecha en la tabla de clasificación se reduce a casi cero en problemas que no están orientados a UI o web. Elegir GLM-5.1 basándose únicamente en su ranking general sin verificar el dominio de la tarea sería un error.
Precios en Atlas Cloud: A partir de USD1.40/M de tokens de entrada, el más alto entre los cuatro. Se justifica cuando la calidad de la generación de front-end impacta directamente en tu producto final.
Qwen 3.6 Plus: Cuando el tamaño del contexto es la verdadera restricción
Alibaba lanzó Qwen 3.6 Plus a finales de marzo de 2026. Lidera Terminal-Bench 2.0 en comparaciones directas contra Claude Opus 4.6 (61.6% vs. 59.3%) y obtiene un 78.8% en SWE-Bench Verified.
La ventana de contexto de 1M de tokens es lo que lo diferencia. Para la mayoría de las tareas de programación en producción por debajo de los 100K tokens, los cuatro modelos de esta comparativa tienen suficiente capacidad de contexto y la diferencia es irrelevante. Qwen 3.6 Plus se convierte en la única opción viable cuando necesitas: análisis de monorepositorios que abarcan cientos de archivos, refactorización de bases de código heredadas a gran escala o flujos de trabajo de documento-a-código que no caben en 262K tokens.
La arquitectura híbrida (atención lineal + enrutamiento MoE disperso) también ofrece un mejor rendimiento de inferencia que los transformadores densos al procesar contextos muy grandes, lo que significa que la capacidad de 1M de tokens conlleva un coste de latencia relativamente bajo en comparación con el escalado ingenuo.
Precios en Atlas Cloud: Desde USD0.325/M de tokens de entrada. Para tareas con contexto grande, es el mejor coste-por-token-útil disponible en este grupo.
MiniMax M2.7: El caso contraintuitivo de la eficiencia
MiniMax lanzó M2.7 en marzo de 2026. Con solo 10B de parámetros activados, obtiene un 56.22% en SWE-Bench Pro: el 94% de la puntuación de GLM-5.1 a aproximadamente una quinta parte del coste por token.
Este es el resultado contraintuitivo de la comparativa. Un modelo que activa 10B de parámetros en la inferencia alcanza un rendimiento de programación casi de vanguardia porque su arquitectura MoE redirige a subredes de expertos especializadas en lugar de ejecutar todas las ponderaciones del modelo. El resultado es menor latencia, menor coste y una calidad de salida que supera lo que el conteo de parámetros por sí solo sugeriría.
La categoría donde M2.7 supera su rango de precio: tareas de ingeniería de aprendizaje automático. Obtuvo una tasa de medallas del 66.6% en MLE-Bench Lite (22 competiciones de machine learning), superado solo por modelos de vanguardia cerrados. Escribir lógica correcta de acumulación de gradientes, implementar capas personalizadas de PyTorch, depurar curvas de pérdida; M2.7 maneja esto con una precisión desproporcionada a su coste.
Dónde tener cuidado: Con 196K de contexto, M2.7 tiene la ventana más pequeña del grupo. Las tareas que requieran un análisis profundo entre archivos en grandes repositorios pueden alcanzar límites que Qwen 3.6 Plus maneja sin problemas.
Precios en Atlas Cloud: USD0.30/M de tokens de entrada, USD1.20/M de tokens de salida; la opción más asequible para cargas de trabajo de programación de alto volumen.
Casos de prueba reales
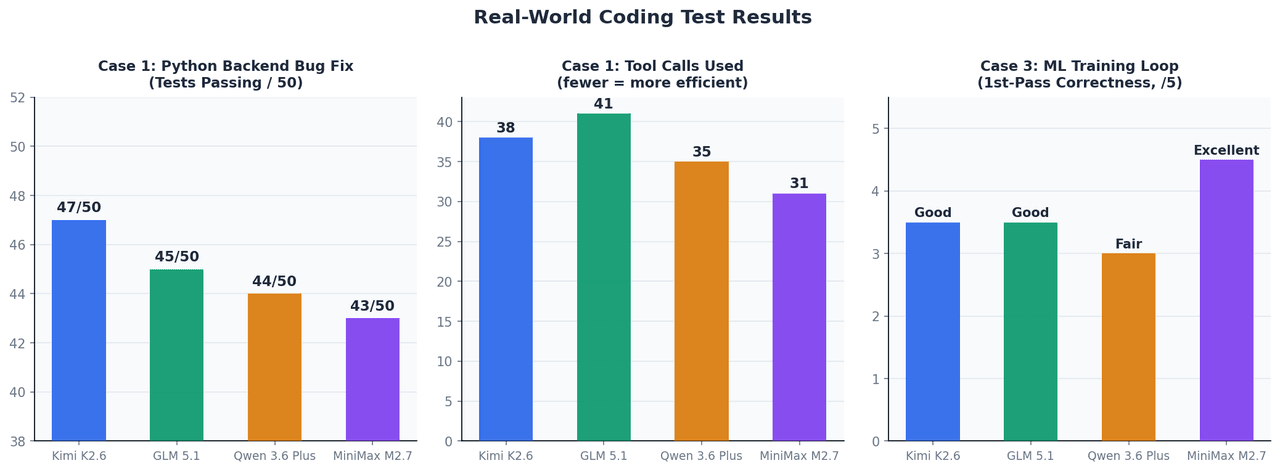
Caso 1: Corrección de error autónoma en un backend de Python
Configuración: Una aplicación FastAPI con 12 archivos, una suite de 50 pruebas fallidas y una ventana de contexto de ~45K tokens. No se permite intervención manual tras el prompt inicial.
| Modelo | Pruebas superadas | Llamadas a herramientas | Tiempo de finalización |
|---|---|---|---|
| Kimi K2.6 | 47 / 50 | 38 | ~4 min |
| GLM 5.1 | 45 / 50 | 41 | ~5 min |
| Qwen 3.6 Plus | 44 / 50 | 35 | ~4 min |
| MiniMax M2.7 | 43 / 50 | 31 | ~3.5 min |
Con este tamaño de contexto, los cuatro funcionan dentro de un margen estrecho. Kimi K2.6 se adelantó en los errores más complejos, específicamente en problemas de ciclo de vida de gestores de contexto asíncronos y acotación de TypeVar, que requieren mantener el estado de inferencia a lo largo de múltiples ciclos de depuración.
Caso 2: Panel de React a partir de especificaciones
Configuración: Generar un panel responsivo completo con cuatro tipos de gráficos (línea, barra, circular, dispersión), modo oscuro y tipos de TypeScript a partir de una especificación escrita en inglés.
GLM-5.1 produjo componentes con tipos de TypeScript funcionales y las clases de utilidad de Tailwind correctas en el primer intento. Kimi K2.6 requirió una iteración para resolver errores de tipo. Qwen 3.6 Plus produjo JSX funcionalmente correcto pero menos idiomático. MiniMax M2.7 fue el más rápido, pero generó algunos patrones de React obsoletos que requerían limpieza manual.
La brecha entre GLM-5.1 y los demás fue más visible en la arquitectura de componentes; GLM-5.1 aplicó patrones de composición y separación de intereses de una manera que los otros no hicieron.
Caso 3: Implementación de bucle de entrenamiento de ML
Configuración: Implementar un bucle de entrenamiento de PyTorch con acumulación de gradientes, precisión mixta AMP y parada temprana para un vision transformer. Objetivo: ejecutarse correctamente al primer intento sin ciclos de depuración.
MiniMax M2.7 destacó: colocó scaler.step() y scaler.update() correctamente en relación con el paso del optimizador, un detalle que la mayoría de los modelos coloca incorrectamente en la primera generación. El escalado de loss / accumulation_steps de la acumulación de gradientes también se manejó adecuadamente. Esto se alinea directamente con su tasa de medallas del 66.6% en MLE-Bench Lite.
Comparativa de precios en Atlas Cloud (Abril 2026)
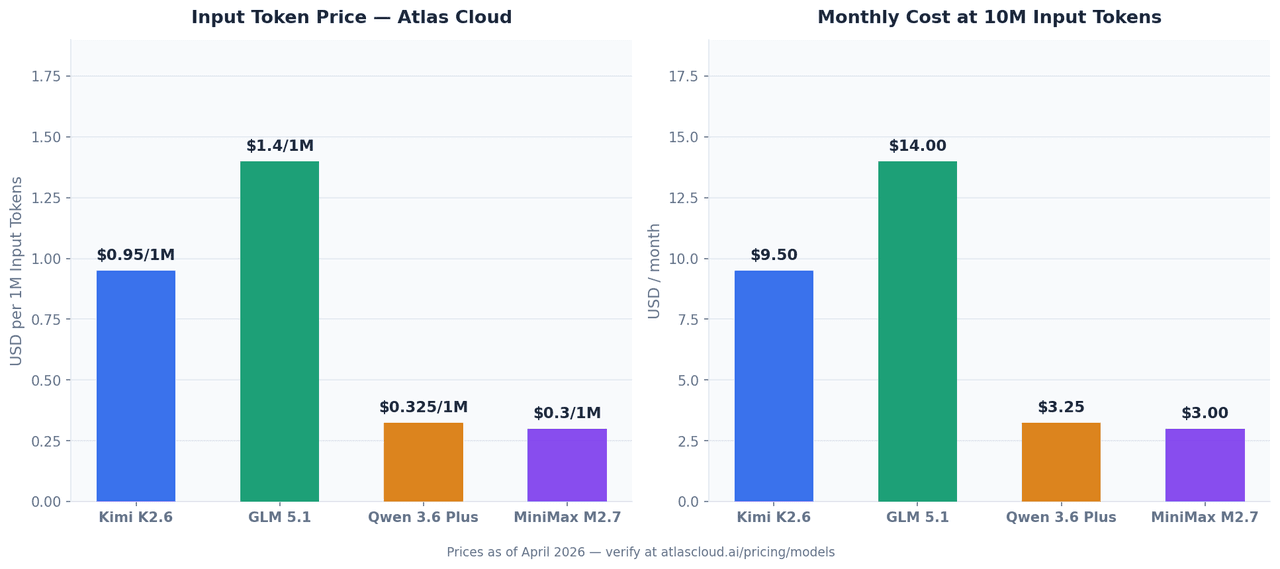
Los cuatro modelos están disponibles a través de la API unificada de Atlas Cloud. Los precios a continuación corresponden a abril de 2026 y pueden cambiar; confirma las tarifas actuales en atlascloud.ai.
| Modelo | Entrada (por 1M tokens) | Salida (por 1M tokens) | ID del modelo en Atlas Cloud |
|---|---|---|---|
| Kimi K2.6 | USD0.95 | USD4.00 | moonshotai/kimi-k2.6 |
| GLM 5.1 | desde USD1.40 | — | zai-org/glm-5.1 |
| Qwen 3.6 Plus | desde USD0.325 | — | qwen/qwen3.6-plus |
| MiniMax M2.7 | USD0.30 | USD1.20 | minimaxai/minimax-m2.7 |
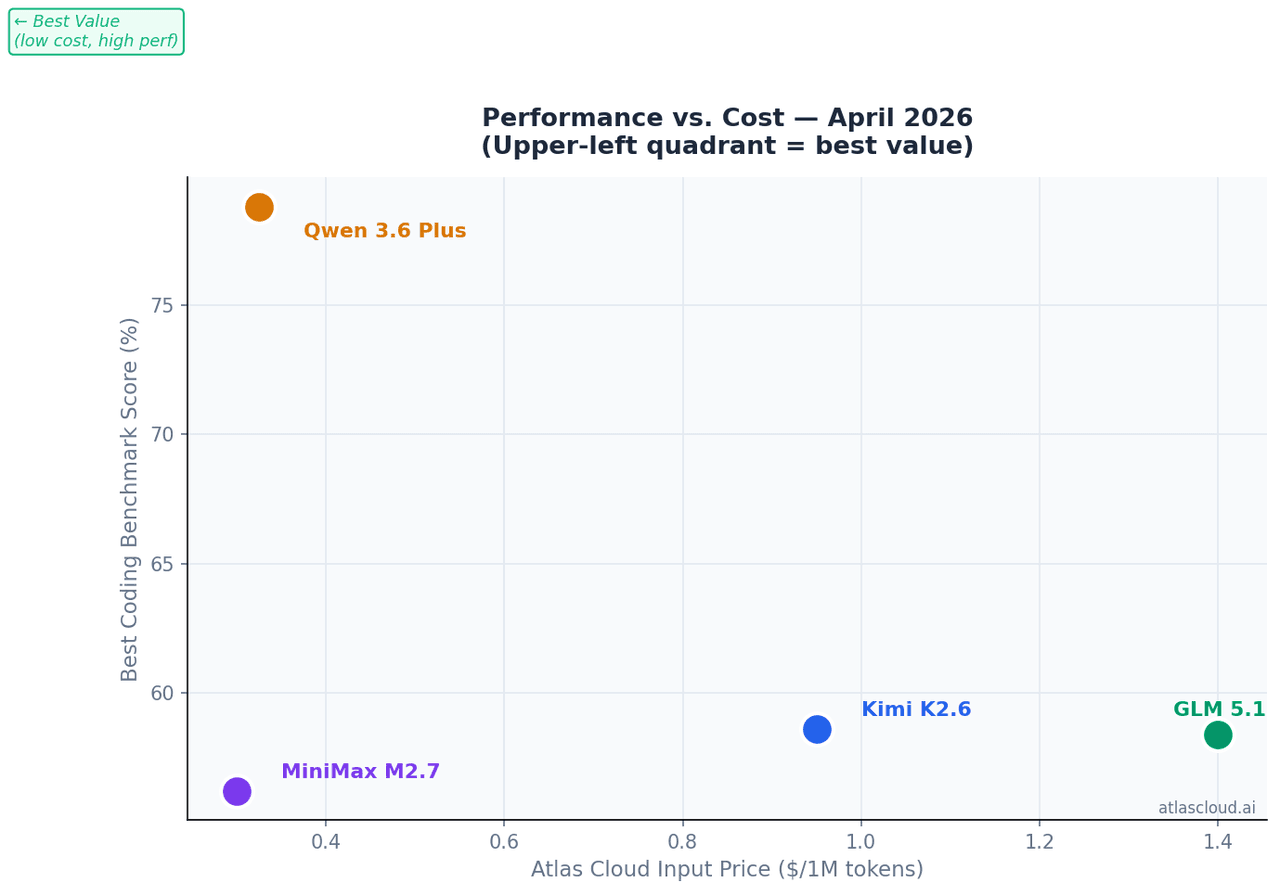
Con 10M de tokens de entrada al mes, un volumen realista para un asistente de programación a nivel de equipo:
| Modelo | Coste mensual de entrada (10M tokens) |
|---|---|
| GLM 5.1 | USD14.00 |
| Kimi K2.6 | USD9.50 |
| Qwen 3.6 Plus | USD3.25 |
| MiniMax M2.7 | USD3.00 |
Llamando a los cuatro con una única clave API
Todos los modelos comparten el mismo endpoint compatible con OpenAI en Atlas Cloud. Cambiar entre ellos requiere modificar una línea:
plaintext1import os 2from openai import OpenAI 3 4client = OpenAI( 5 api_key=os.environ["ATLASCLOUD_API_KEY"], 6 base_url="https://api.atlascloud.ai/v1" 7) 8 9# Cambia esta única línea para cambiar de modelo 10MODEL = "moonshotai/kimi-k2.6" 11# MODEL = "zai-org/glm-5.1" 12# MODEL = "qwen/qwen3.6-plus" 13# MODEL = "minimaxai/minimax-m2.7" 14 15response = client.chat.completions.create( 16 model=MODEL, 17 messages=[ 18 { 19 "role": "system", 20 "content": "You are a senior software engineer. Analyze code carefully before responding." 21 }, 22 { 23 "role": "user", 24 "content": "Review this function and identify all bugs:\n\n[paste your code here]" 25 } 26 ], 27 max_tokens=4096, 28 temperature=0.2 29) 30 31print(response.choices[0].message.content)
Esta estructura compatible con OpenAI significa que las integraciones existentes construidas sobre el SDK de OpenAI funcionan con Atlas Cloud sin modificaciones: solo cambian la base_url y la api_key.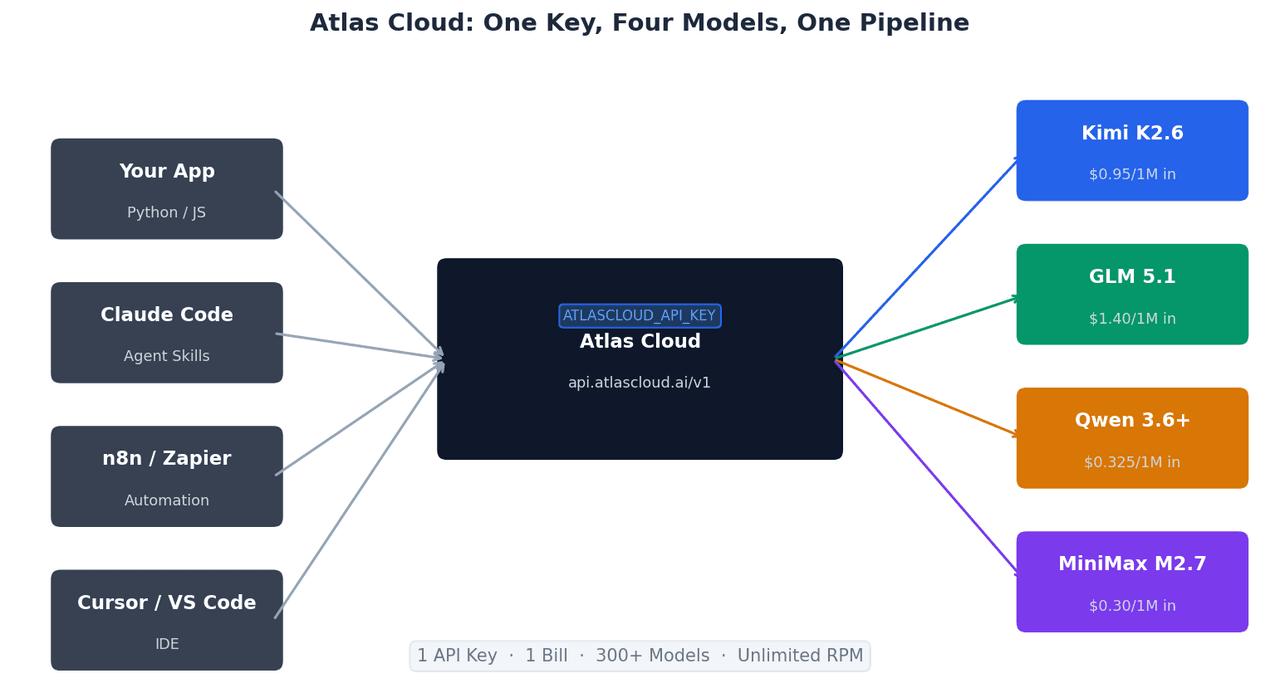
Por qué usar Atlas Cloud para estos modelos
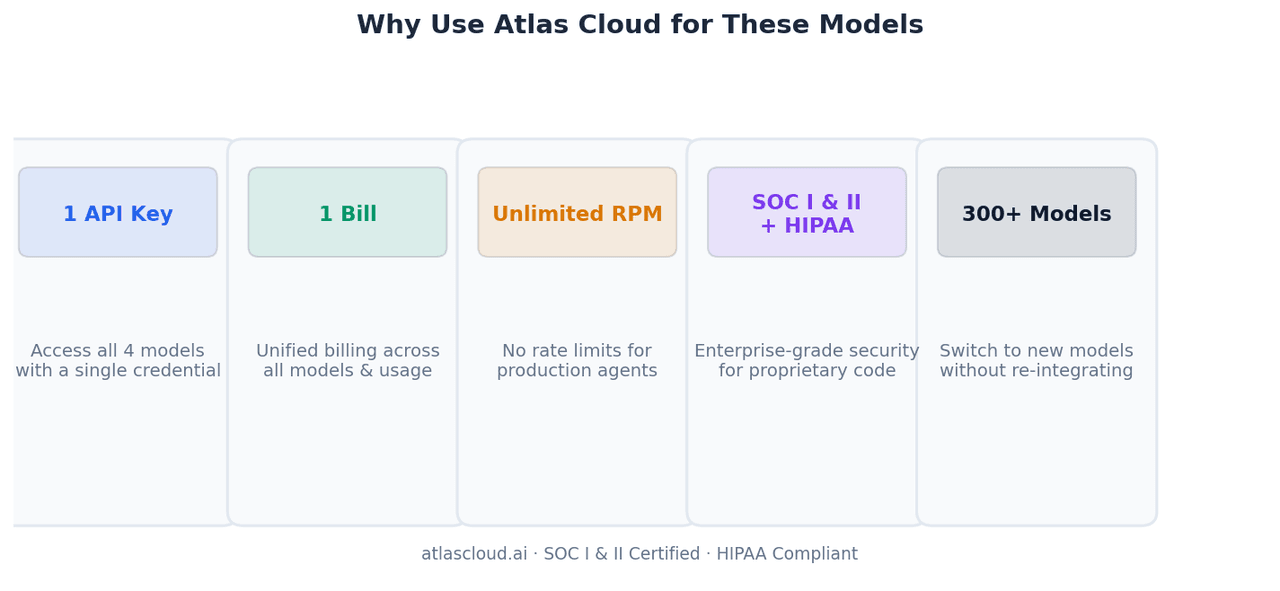
Una clave API, cuatro modelos, una factura. Gestionar la lógica de enrutamiento de modelos (enviar tareas de front-end a GLM-5.1, análisis por lotes a MiniMax M2.7 y agentes de larga ejecución a Kimi K2.6) requiere gestionar una credencial en lugar de cuatro. La conciliación mensual es una factura única.
RPM ilimitadas. Los agentes de programación de producción disparan llamadas a herramientas en paralelo. Los límites de velocidad en las APIs directas de los proveedores pueden estrangular los pipelines multi-agente. Atlas Cloud elimina ese techo.
Certificación SOC I & II, cumplimiento con HIPAA. Los equipos que procesan código fuente propietario a través de estos modelos necesitan una infraestructura auditable. Las certificaciones de cumplimiento de Atlas Cloud significan que tu código no se enruta a través de endpoints no verificados.
Más de 300 modelos, mismo patrón de integración. Cuando salga la siguiente versión de cualquiera de estos modelos, o un nuevo modelo los supere en tu carga de trabajo específica, añadirlo a tu lógica de enrutamiento requiere un solo cambio de cadena de texto, no una nueva integración de SDK.
¿Qué modelo elegir para cada tarea?
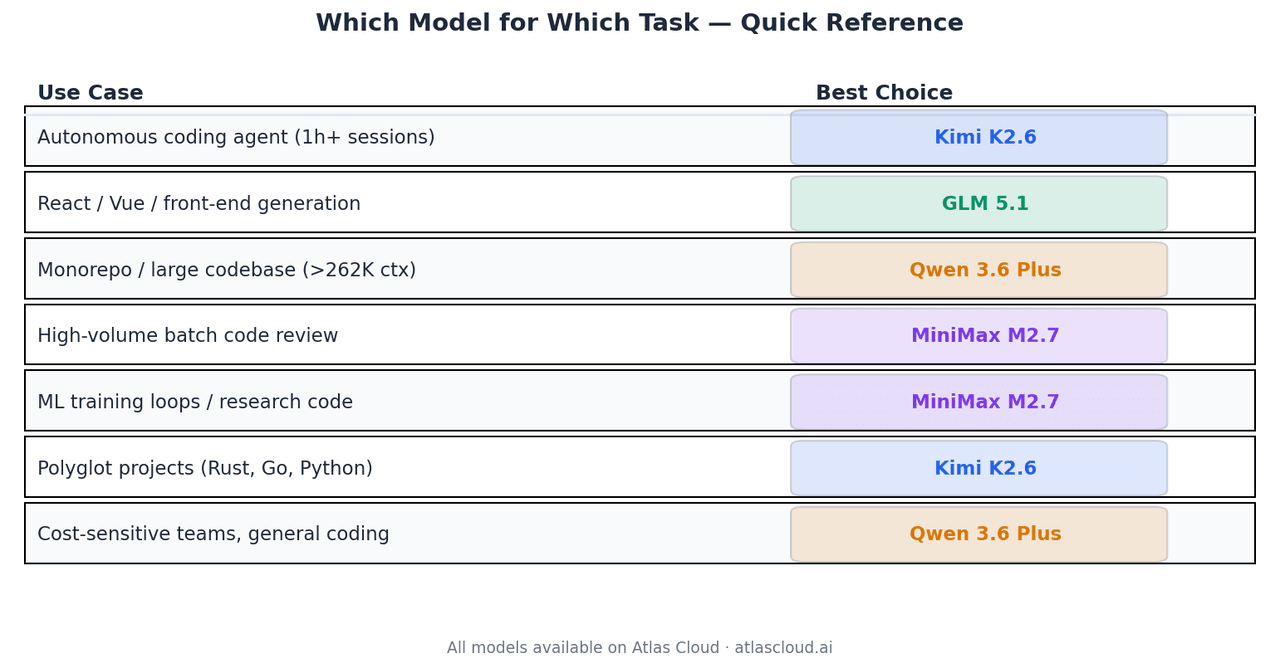
| Caso de uso | Mejor elección | Por qué |
|---|---|---|
| Agente de programación autónomo, sesiones de +1 hora | Kimi K2.6 | 66.7% Terminal-Bench 2.0, estabilidad en 4K+ llamadas |
| Generación de React / Vue / front-end | GLM 5.1 | Código Arena Elo 1,530, top-3 en desarrollo web agente |
| Análisis de monorepositorios o código grande | Qwen 3.6 Plus | Único modelo aquí con ventana de 1M de contexto |
| Revisión de código por lotes de alto volumen | MiniMax M2.7 | USD0.30/M entrada, 94% de la calidad de GLM-5.1 |
| Bucles de entrenamiento ML, código de investigación | MiniMax M2.7 | Tasa de medallas del 66.6% en MLE-Bench Lite |
| Proyectos políglotas (Rust, Go, Python) | Kimi K2.6 | Generalización entre lenguajes documentada |
| Equipos sensibles al coste, programación general | Qwen 3.6 Plus | USD0.325/M entrada, sólido en todas las categorías |
Resumen
Estos cuatro modelos están separados por márgenes estrechos en los benchmarks estándar. Las diferencias significativas surgen en condiciones específicas.
Kimi K2.6 es la respuesta correcta para agentes autónomos de larga ejecución. GLM 5.1 lidera el trabajo agente de front-end. Qwen 3.6 Plus es la única opción cuando el contexto supera los 262K tokens. MiniMax M2.7 es el valor predeterminado eficiente en costes para equipos que ejecutan modelos de programación a escala.
Los cuatro están disponibles en Atlas Cloud en atlascloud.ai bajo una única clave API, con precios de pago por token y sin compromiso mínimo.
Datos de los benchmarks obtenidos del blog técnico de Moonshot AI, documentación para desarrolladores de Z.AI, post de lanzamiento del equipo Qwen de Alibaba, página oficial del modelo MiniMax y evaluaciones independientes de Arena.ai. Todos los benchmarks son datos de abril de 2026. Los precios de Atlas Cloud se indican a fecha de publicación; verifica las tarifas actuales antes de la implementación en producción.






