OpenAI LLM Models
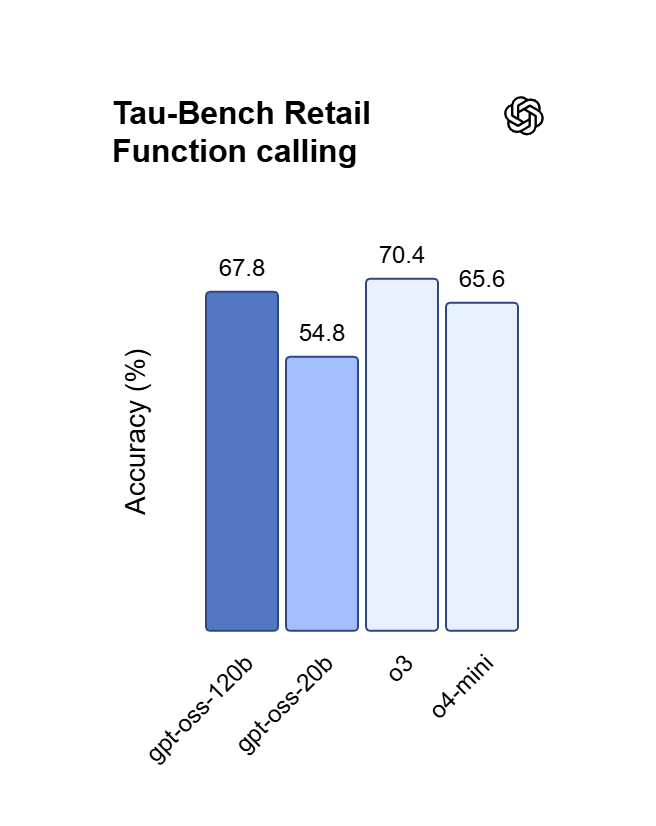
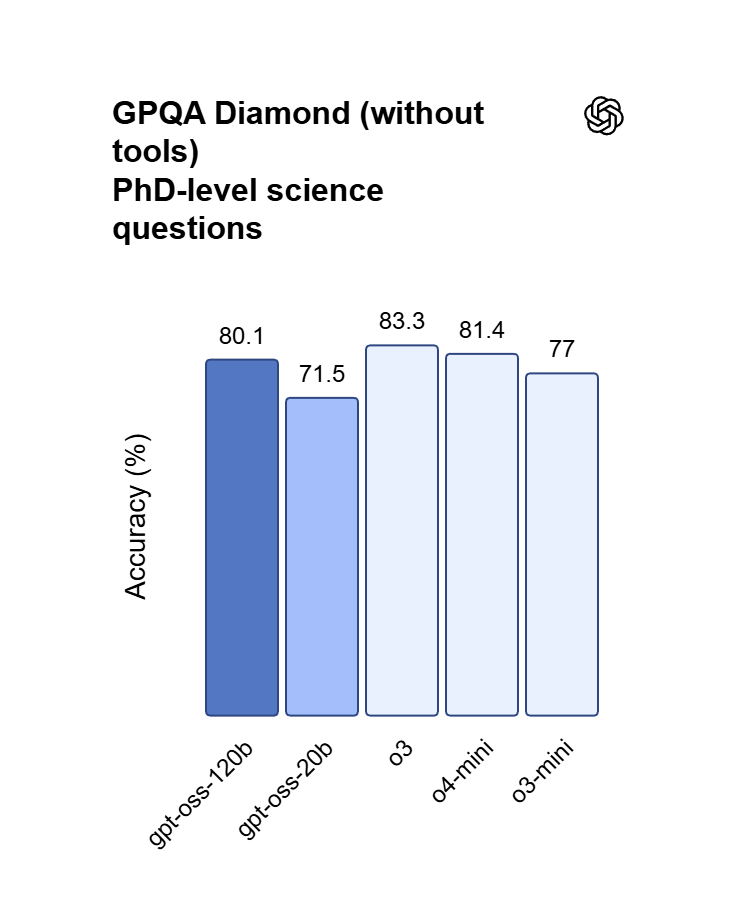
OpenAI’s premier GPT model family leads the industry, highlighted by the GPT OSS 120B which achieves near-parity with OpenAI o4-mini on core reasoning benchmarks while running efficiently on a single 80GB GPU. Perfectly optimized for vibecoding and complex logic operations, this model balances top-tier intelligence with hardware accessibility for modern developers and AI-driven web development.
Modelli in arrivo
Stiamo dando gli ultimi ritocchi a questa collezione — nel frattempo, esplora le collezioni simili qui sotto.
Explore More Families
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
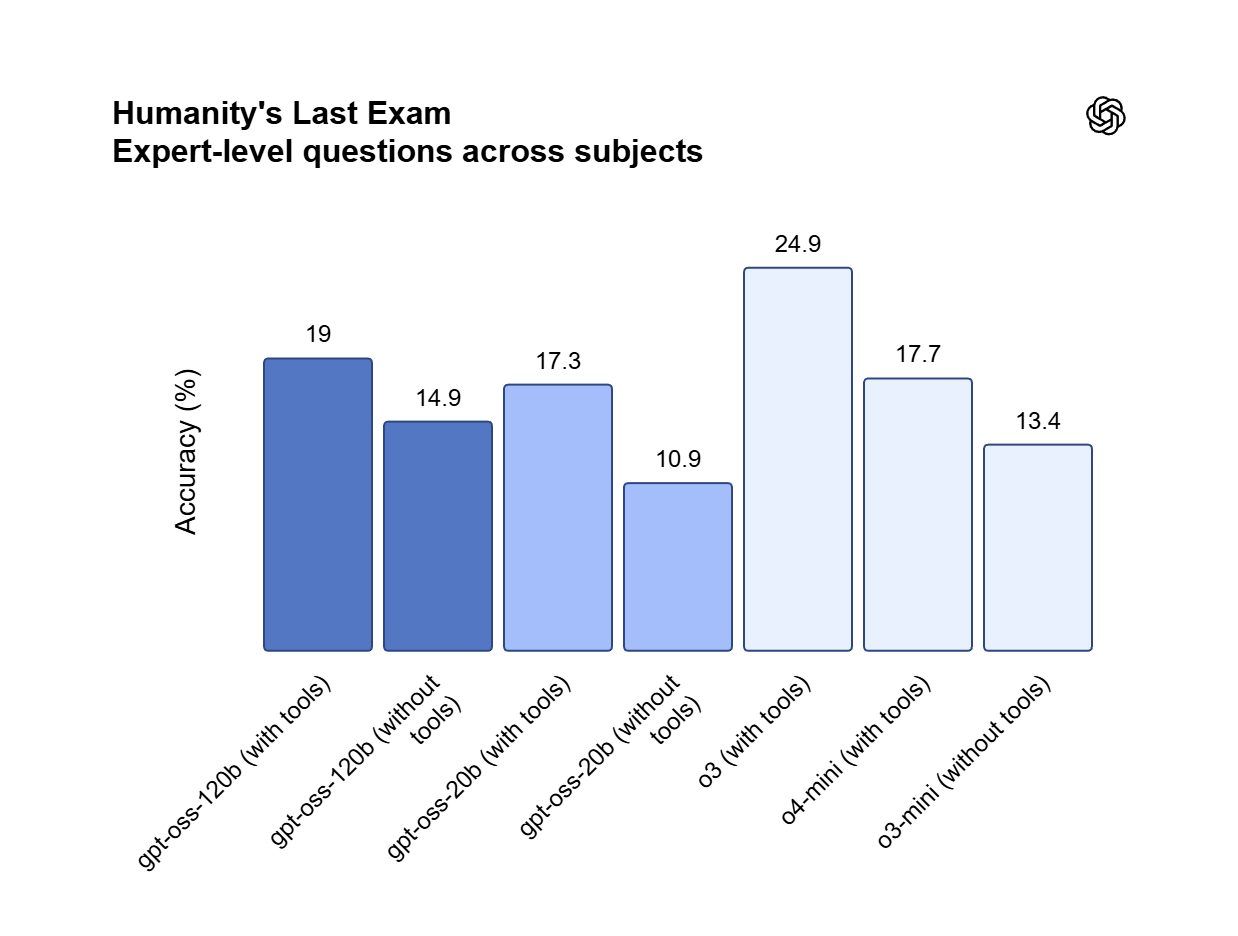
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Cosa Rende Speciale OpenAI LLM Models
Atlas Cloud ti fornisce i più recenti modelli creativi leader del settore.

Frontier Research
Cutting-edge models that set global benchmarks in reasoning, multimodality, and AI safety.

Cost-Efficient Performance
Optimized families like GPT-4.1 mini and GPT-5 nano balance accuracy, speed, and cost.

Developer Ecosystem
APIs powering millions of daily requests across diverse platforms and industries.

Flexible Model Sizes
Choice of flagship, mini, and nano models for every workload and budget.

Enterprise Reliability
SLAs, monitoring, and compliance-ready logging trusted by Fortune 500 companies.

Open Model Options
Access to open-source models (gpt-oss-20b, gpt-oss-120b) for transparency and customization.
Velocità di punta
Costo più basso
| Modello | Descrizione |
|---|---|
| GPT OSS 120B | GPT OSS 120B è un LLM ad alte prestazioni incentrato sul ragionamento, che integra un'architettura ottimizzata con robuste capacità di elaborazione del contesto di 131.07K; raggiungendo quasi la parità con OpenAI o4-mini su una singola GPU da 80 GB, funge da motore per lo sviluppo iterativo rapido, incluso il vibecoding e l'esecuzione di flussi di lavoro complessi guidati dalla logica. |
Nuove funzionalità di OpenAI LLM Models + Showcase
La combinazione di modelli avanzati con la piattaforma accelerata da GPU di Atlas Cloud offre velocità, scalabilità e controllo creativo senza pari per la generazione di immagini e video.
Rispetto preciso delle istruzioni tramite GPT OSS 120B
GPT OSS 120B mostra un'eccezionale manovrabilità, aderendo rigorosamente a prompt di sistema complessi per garantire un'assoluta affidabilità dell'output. Sfruttando la sua architettura di allineamento perfezionata (fine-tuned), gli utenti possono imporre formati specifici, vincoli e sfumature stilistiche con zero deriva dei caratteri. È la scelta definitiva per agenti autonomi, estrazione di dati strutturati e ambienti di produzione mission-critical.
Sovranità commerciale sotto licenza Apache 2.0
GPT OSS 120B è distribuito sotto licenza Apache 2.0, consentendo un utilizzo commerciale illimitato e un fine-tuning privato senza costi per token. A differenza delle API closed-source, permette l'hosting locale su una singola GPU da 80 GB per mantenere i dati proprietari sensibili interamente on-premise. Questo framework fornisce la libertà legale e tecnica per costruire, modificare e scalare stack software guidati dall'IA.
Logica ad alta efficienza e Vibecoding con GPT OSS 120B
Raggiungendo quasi la parità con OpenAI o4-mini, questo modello da 120B di parametri eccelle nella gestione di sintesi di codice complessa e dimostrazioni matematiche. Gli sviluppatori possono sfruttare il suo motore di ragionamento per il "vibe coding", traducendo idee in linguaggio naturale direttamente in applicazioni web funzionali attraverso prompting iterativo. È una soluzione ad alta velocità per il debug di logica annidata e l'orchestrazione di flussi di lavoro sofisticati di pianificazione delle attività.
Cosa Puoi Fare con OpenAI LLM Models
Scopri casi d'uso pratici e workflow che puoi costruire con questa famiglia di modelli — dalla creazione di contenuti e automazione alle applicazioni di livello produzione.
Debugging della logica profonda e prototipazione con GPT OSS 120B
Il GPT OSS 120B consente agli ingegneri di risolvere le sfide del "vibecoding" traducendo idee architettoniche di alto livello in componenti Python o React pronti per la produzione. Il suo motore di ragionamento gestisce le dipendenze nidificate e i casi limite che spesso mettono in difficoltà i mini-modelli, garantendo che la sintesi del codice in più passaggi rimanga funzionale. Supportando prove algoritmiche e la pianificazione di attività complesse, è lo strumento perfetto per costruire MVP tecnici, script QA automatizzati e applicazioni web ad alta intensità di dati.
Strumentazione proprietaria offline utilizzando GPT OSS 120B
Sotto la licenza Apache 2.0, i team possono ospitare GPT OSS 120B su una singola GPU da 80 GB per elaborare dati interni sensibili senza rischi di fuga nel cloud. Questa configurazione consente il fine-tuning locale permanente su codebase interne di nicchia o registri medici senza costi API ricorrenti per token. Ideale per strumenti interni ad alta sicurezza e assistenza IA offline, il modello offre la piena sovranità dei pesi, supportando sistemi RAG privati e stack software proprietari personalizzati.
Estrazione dati a schema perfetto con GPT OSS 120B
Il GPT OSS 120B consente agli sviluppatori di convertire documenti disordinati e non strutturati in JSON o Markdown rigorosamente formattati senza "deriva delle istruzioni". Ancorando la finestra di contesto di 131.07K con rigide regole di sistema, il modello garantisce che i campi non vengano mai allucinati o saltati durante l'elaborazione di testi lunghi. Ideale per l'automazione CRM e l'etichettatura automatizzata dei contenuti, mantiene barriere logiche su enormi set di dati, supportando integrazioni API affidabili e il popolamento dei database.
Confronto Modelli
Scopri come si confrontano i modelli di diversi provider — confronta prestazioni, prezzi e punti di forza unici per una decisione informata.
| Modello | Contesto | Output massimo | Input | Posizionamento |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Testo | LLM di ragionamento ad alta efficienza |
| GLM-5 | 202.75K | 202.75K | Testo | Modello di fondazione di punta |
| DeepSeek V3.2 | 163.84K | 163.84K | Testo | Generale di punta |
| MiniMax-M2.5 | 204.8K | 196.6K | Testo | Programmazione agentica SOTA |
How to Use OpenAI LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Why Use OpenAI LLM Models on Atlas Cloud
Combining the advanced OpenAI LLM Models models with Atlas Cloud's GPU-accelerated platform provides unmatched performance, scalability, and developer experience.
Performance & flexibility
Low Latency:
GPU-optimized inference for real-time reasoning.
Unified API:
Run OpenAI LLM Models, GPT, Gemini, and DeepSeek with one integration.
Transparent Pricing:
Predictable per-token billing with serverless options.
Enterprise & Scale
Developer Experience:
SDKs, analytics, fine-tuning tools, and templates.
Reliability:
99.99% uptime, RBAC, and compliance-ready logging.
Security & Compliance:
SOC 2 Type II, HIPAA alignment, data sovereignty in US.
Domande Frequenti su OpenAI LLM Models
Raggiunge una quasi parità con OpenAI o4-mini nei benchmark di ragionamento di base e matematica. Mentre o4-mini è un'API chiusa, OSS 120B offre una profondità logica comparabile con il vantaggio aggiunto dell'accesso completo ai pesi del modello.
Il modello è ottimizzato per una singola GPU da 80 GB, evitando la complessità del multi-nodo. Tuttavia, per una scalabilità immediata e zero manutenzione, consigliamo di accedervi tramite API su Atlas Cloud.
Sì. È rilasciato sotto licenza Apache 2.0, che consente l'uso commerciale, la modifica e la distribuzione illimitati senza costi di licenza per token o vendor lock-in.
La finestra di contesto da 131.07K è progettata per una precisione di recupero tipo "ago nel pagliaio". Può acquisire intere directory di progetto o manuali tecnici di oltre 100 pagine mantenendo la coerenza logica in tutto l'input.
Estremamente. Il suo motore di ragionamento è perfezionato per la sintesi iterativa del codice. Gestisce componenti React nidificati e backend Python complessi in modo più affidabile rispetto ai modelli standard della classe 70B, rendendolo ideale per i flussi di lavoro da linguaggio naturale ad app.


